一种处理器核心结构及数据访存方法与流程
本发明涉及对处理器核心结构的改进,以及基于上述结构实现数据访存的方法。
背景技术:
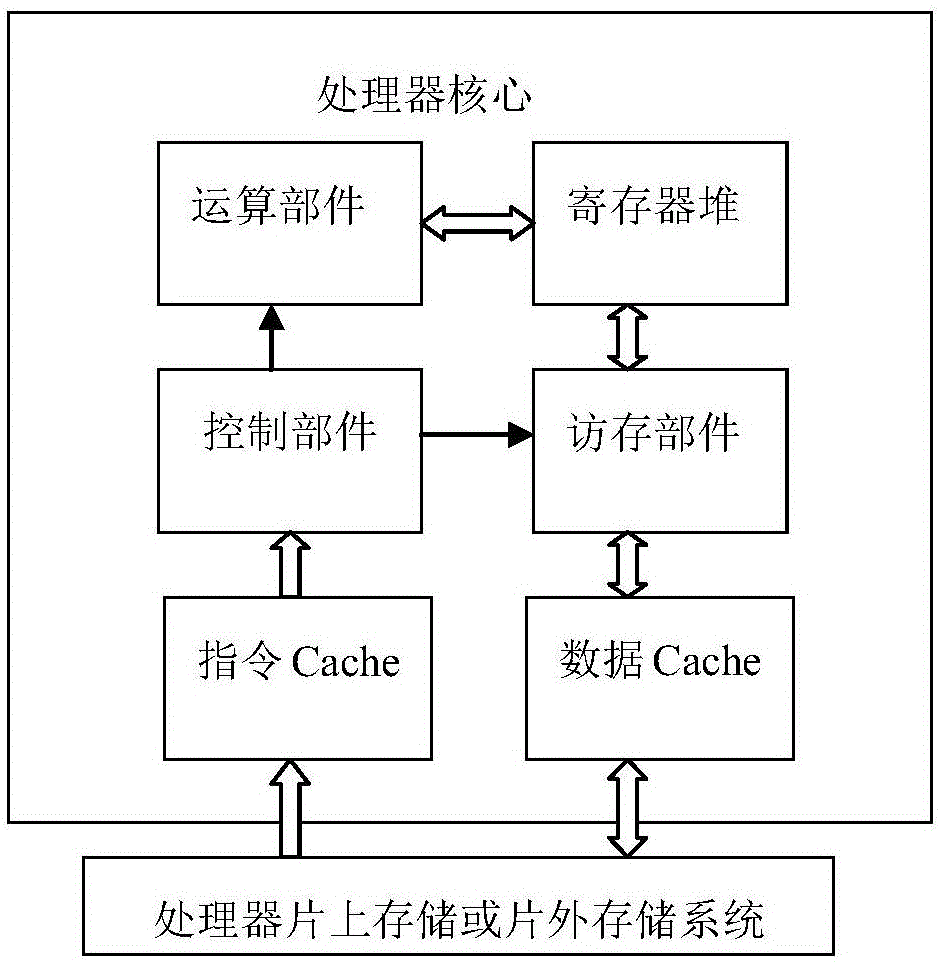
:处理器核心(cpucore),是处理器中最重要的组成部分。在处理器中所有的计算、访存命令、数据处理均是由处理器核心来完成。不同处理器核心之间在结构上可能略有差异,然而它们大致上拥有相似的体系结构,如图1a所示,包括:控制部件、运算部件、访存部件、寄存器堆、指令cache和数据cache(即缓存)。参考图1a,在处理器片上存储或片外存储中储存有控制指令、以及数据,指令cache从片上或片外存储中缓存控制指令,并提供给控制部件,由控制部件基于相应的控制指令来控制运算部件实施运算操作、以及控制访存部件实现在数据cache、以及寄存器堆之间的数据交换,由运算部件直接读取寄存器堆中寄存器内的数据以进行运算。所述访存部件是处理器设计领域公知的概念,在英文文献中一般称为loadstoreunit(lsu),有时也描述为addressgenerationunit(agu),与运算部件一样属于功能部件(functionunit)或执行部件(executionunit)的一种。运算部件负责定点或者浮点运算,访存部件负责从存储系统读写数据。这里寄存器堆指的是多个寄存器的集合,寄存器为处理器核心临时存放数据的空间,其位宽和存储容量非常有限,相比之下,数据cache则具有更大的存储容量,可以缓存处理器核心需要频繁访问的数据。由于寄存器堆与数据cache在结构、地址上存在差异,因而需要通过访存部件在数据cache和寄存器堆间搬移数据,为寄存器堆中寄存器提供新的数据,或者将寄存器的数据写回到数据cache。对于现有的通用处理器(cpu)或通用图形处理器(gpgpu)而言,在一个处理器核心中有一个或多个寄存器堆,一个或多个访存部件。访存部件一次读写的最大数据宽度和寄存器堆中的寄存器字长是一致的。每个访存部件可以只连接指定的寄存器堆,也可以连接所有的寄存器堆,然而任何时候,一个访存部件一次只能访问一个寄存器堆。例如,如图1b所示,通用处理器为了满足运算部件、访存部件之间快速低延迟的数据交换,采用由2~4个运算部件和1~2个访存部件共享一个寄存器堆,而非共享多个寄存器堆。这是由于功能部件之间的数据交换需要在单个周期内完成,即a功能部件写入寄存器堆的数据,下个周期b功能部件就可以读取。而在共享多个寄存器堆的情况下,为了实现单周期的数据交换,寄存器堆和功能部件的设计会变得非常复杂,以至于在硬件上难以实现。因而,尽管通用处理器中的访存部件可以被设计为同时连接至定点寄存器堆和浮点寄存器堆,然而同一时刻该访存部件只能访问一个寄存器堆。又例如,如图1c所示,通用图形处理器主要面向图形渲染,其相关计算主要采用多路(或多线程)数据并行计算,各路数据计算的操作基本一致。参考图1c,为了提高计算并行度,其采用多访存部件多寄存器堆的结构,数据cache与n个部件组(包括访存部件、寄存器堆、以及运算单元)相连,在每个部件组中访存部件、寄存器堆以及运算单元一一对应,相互之间不通过寄存器堆共享数据。随着深度学习、5g通信等技术的发展,上述传统的通用处理器、通用图形处理器往往难以有针对性地对大规模的数据进行并行计算。处理器核心需要频繁地在数据cache和寄存器堆之间交换数据,然而若是一个访存部件在一个时刻只能访问一个寄存器堆意味着要提高数据的交换速率,就需要更多的访存部件或者更大的数据宽度来增加一次读写的数据总量。更多的访存部件会增加数据cache的读写端口数量,而数据cache设计复杂度随读写端口的数量增加超线性增长;更大的数据宽度会降低运算的灵活度,一是增加编程和编译器调度的难度,二是因为使用率不足带来资源浪费,降低处理器的能效比,三是共享的多端口寄存器堆的设计复杂度也是超线性增长。因而,需要开发出一种新的处理器核心结构,以平衡需要增加访存部件数量以及需要采用大数据宽度之间的矛盾。技术实现要素:因此,本发明的目的在于克服上述现有技术的缺陷,提供一种处理器核心,包括:一个数据缓存,用于缓存数据;n个寄存器堆,用于向运算部件提供数据的访问,n是大于1的整数;一个访存部件,其与所述数据缓存以及所述n个寄存器堆连接,用于在所述数据缓存以及所述n个寄存器堆之间的数据交换。优选地,根据所述处理器核心,其中所述访存部件用于将来自所述n个寄存器堆的数据合并在一起写入所述数据缓存,以及对来自所述数据缓存的数据进行分解并写入相应寄存器堆的寄存器中。优选地,根据所述处理器核心,其中所述访存部件包括:缓冲器,用于暂时存放将要写入所述数据缓存的数据以及来自所述数据缓存的数据;分解电路,其与所述缓存器连接,用于分解来自所述缓冲器的数据以提供给相应的寄存器堆;组合电路,其与所述n个寄存器堆连接,用于对来自寄存器堆的数据进行组合以提供给所述缓冲器。优选地,根据所述处理器核心,其中,所述访存部件还包括:用于分别与每个所述寄存器堆连接的n个寄存器堆接口;所述缓冲器包括用于暂时存放将要写入所述数据缓存的数据的n个输出缓冲器以及用于暂时存放来自所述数据缓存的数据的n个输入缓冲器;所述分解电路包括分别与每个所述寄存器堆接口连接的n个第一多路选择器;所述组合电路包括:分别与每个所述寄存器堆接口连接的n个第二多路选择器;并且,所述访存部件还包括:译码组合电路,用于提供针对所述第一多路选择器、所述第二多路选择器的控制信号。优选地,根据所述处理器核心,所述访存部件还用于接收用于其实现在所述数据缓存与所述n个寄存器堆之间进行数据交换的访存指令。优选地,根据所述处理器核心,所述访存指令包括以下字段:指令码,用于表示执行读或写的操作;访存地址,用于指定所述数据缓存中的地址;寄存器堆掩码,用于指定参与读或写的寄存器堆的编号。优选地,根据所述处理器核心,所述寄存器堆掩码具有n个比特位,每个比特位与所述n个寄存器堆中的一个对应,所述比特位的取值用于表示所对应寄存器堆是否需要被访问。优选地,根据所述处理器核心,所述访存指令中还包括:寄存器编号,用于指定参与读或写的寄存器的编号。优选地,根据所述处理器核心,所述寄存器编号具有n个比特位,n的取值为可以采用二进制数表示在一个寄存器堆中全部寄存器的编号的最小位数。一种处理器,包括:上述任意一项所述的处理器核心。优选地,根据所述处理器,其还包括:处于所述处理器核心之外且存储有用于所述访存单元实现在所述数据缓存与所述n个寄存器堆之间进行数据交换的访存指令的存储器。一种基于所述处理器结构而实现的数据访存方法,包括:1)所述访存部件接收访存指令;2)所述访存部件根据所述访存指令,将所述数据缓存的指定地址处的数据分别写入到指定寄存器堆的寄存器中,或者从指定寄存器堆的寄存器中读取数据并将聚合在一起的数据写入到所述数据缓存的指定地址。优选地,根据所述方法,其中步骤2)包括:2-1)识别所述访存指令中的相应字段,确定要执行的读或写的操作;2-2)根据所述访存指令中的相应字段,确定针对所述数据缓存的指定地址、以及指定的寄存器堆的寄存器;2-3)根据所确定的读或写的操作、所述数据缓存的指定地址、以及指定的寄存器堆的寄存器,在所述数据缓存与所述n个寄存器堆之间进行数据交换。与现有技术相比,本发明的优点在于:提供了一种结合通用处理器和通用图形处理器两者的优点、规避两者的缺点的处理器核心结构。基于该结构,可以减少所使用的访存部件数量,与该访存部件对于的数据cache的读写端口也相对较少,从而大大降低了设计与之匹配的数据cache的难度、集成电路的面积和访问延迟。本发明使用的寄存器堆多,可以同时支持多个运算部件,同时每个寄存器堆的读写端口少,可大幅降低寄存器堆的设计难度和访问延迟。采用新的访存指令来控制访存部件,可以在不大幅增加软硬件的复杂度的情况下,实现在一个数据缓存以及k个寄存器堆之间的数据交换。发明人通过研究后发现,本发明的方案尤其适用于计算密集时数据计算的并行度和规则性都很强,但不同计算阶段计算形式变化也比较多样的应用。附图说明以下参照附图对本发明实施例作进一步说明,其中:图1a是现有技术中处理器核心的结构示意图;图1b示出了现有的通用处理器中一个寄存器堆被多个访存部件共享;图1c示出了现有的通用图形处理器中一个数据cache与多个访存部件连接,每个访存部件同与其对应的唯一寄存器堆连接;图2a是根据本发明的一个实施例的处理器核心中访存部件和寄存器堆及数据cache的连接关系示意图;图2b是根据本发明的一个实施例的访存部件的结构示意图;图3是根据本发明的一个实施例的访存指令的执行过程的流程图。具体实施方式下面结合附图和具体实施方式对本发明作详细说明。如
背景技术:
中所分析地,增加访存部件的数量与增加传输数据宽度之间存在矛盾,因而发明人提出可以整合这两种方式的优点并规避它们的不足,基本设计思路为:在不增加访存部件数量的情况下,将访存部件访问数据cache的最大数据宽度由寄存器字长的1倍提升为k倍,由此在不增加数据cache的设计复杂度的情况下,提升了在访存部件与数据cache之间的数据交换速率;同时,使得一个访存部件与k个寄存器堆相连接,并且同时可以对全部k个寄存器堆进行读/写操作,多个寄存器堆对应于一个或多个运算部件,这样既增加访存部件和寄存器堆的数据交换速率,也简化了寄存器堆的设计,避免出现单一共享的复杂寄存器堆设计。图2a为根据本发明的一个实施例的处理器核心中的部分结构,示出了访存部件、寄存器堆及数据cache之间的连接关系。如图2a所示,访存部件同时连接4个寄存器堆,每个寄存器堆中寄存器的字长为64位,该访存部件与数据cache之间的数据宽度为64×4位。在该处理器核心的其他部件之间的连接关系与图1a保持一致。图2b示出了根据本发明的一个实施例的访存部件的结构,其中在访存部件与寄存器堆的接口处增加了数据聚合和分配的电路,如图2b所示。其中,rf0~rf3是不同的寄存器堆,rfintf0~rfintf3是访存部件与对应寄存器堆的接口。访存部件写往寄存器堆的数据先送入一个数据缓冲inbuffer,inbuffer中的不同字段(in0,in1,in2,in3)的数据经过多路选择器mux分配到各个寄存器堆的接口;同样,从各寄存器堆接口读入的数据经过多路选择器后写入数据缓冲outbuffer的各个字段(out0,out1,out2,out3),聚合为访存部件的输出数据。基于上述结构,数据cache与寄存器中寄存器进行数据交换时,需要区分读/写操作针对的是哪一个或哪几个寄存器堆中的寄存器,这一点可以通过软件控制或硬件实现,例如,通过产生合适的输入信号给图2b中的译码组合电路,就可以利用上述电路进行数据的聚合和分配。优选地,本发明设计了一种新的访存指令来控制同宽度的数据的读/写以及数据的聚合和分解,仅需要在访存指令中增加少量的字段,不会额外增加控制部件、指令cache以及片上或片外存储的压力,也不会大幅地增加访存部件的复杂度。根据本发明的一个实施例,在处理器核心以外的存储器中存储新的访存指令,以在需要在寄存器堆及数据cache之间进行数据读写时通过指令cache控制器将该访存指令提供给访存部件。表1示出了所述新的访存指令的格式,包括:指令码、访存地址、寄存器编号、寄存器堆掩码。这四个域在指令编码中的位置排列可以是任意的。表1指令码访存地址寄存器编号寄存器堆掩码其中,寄存器堆掩码共k位,k是寄存器堆数量,是大于1的整数。掩码中的每一位对应于一个寄存器堆,利用掩码的取值来表示相应寄存器堆是否参与读写。例如,掩码为1表示对应寄存器堆中对应寄存器编号的寄存器要参与读写,掩码0表示不读写;也可以是0表示读写,1表示不读写。对于上述四个寄存器堆的例子,掩码为四位的二进制数,分别对应四个寄存器堆,如1111表示四个寄存器堆对应的寄存器都被读写,1010表示第1个寄存器和第3个寄存器堆被读写。寄存器编号采用二进制数,比如采用四位二进制数,来表示0~15共16个寄存器。寄存器编号可以是对单个寄存器堆中的全部寄存器进行编号,也可以是对所有寄存器堆中的全部寄存器进行编号,在对全部所有寄存器堆中的全部寄存器进行编号时,无需在上述访存指令中设置寄存器堆掩码的字段。对于针对单个寄存器堆中的全部寄存器进行编号、并且每个寄存器堆中寄存器数量相等的情况,可以利用访存指令使得全部寄存器堆共用一个寄存器编号,例如,寄存器编号为0001,寄存器堆掩码为1100,则表示对第1个寄存器堆中的第一个寄存器和第2个寄存器堆中的第一个寄存器进行读写。在这种情况下所有寄存器堆读写的寄存器编号一样,可以缩短指令中寄存器编号字段的长度。指令码主要区别读/写操作以及数据宽度,读操作(load)表示根据访存地址从数据cache读取数据,写入寄存器堆的寄存器中,写操作(store)表示从寄存器堆的寄存器读取数据,根据访存地址写入数据cache中。访存地址可以是一个二进制地址,也可以是基址寄存器编号和二进制偏移的组合。上述访存指令经过译码后提取的指令类型(读或写)、数据宽度(字节、半字、字、双字等)、寄存器堆掩码(rfmask)等信号输入如图2b所示出的译码组合电路中,该译码组合电路根据这些输入信号产生多路选择器的选择信号sel和缓冲器的使能信号enable,其中,sel信号根据数据宽度信号和rfmask信号产生,enable信号根据指令类型信号和rfmask信号产生。图2b中的sel信号和enable信号只是示意,实际电路中不同选择器的sel信号是不同的,不同缓冲器的enable信号也是不同的。同样,inbuffer和outbuffer的字段大小、数量以及多路选择器和缓冲器的数量和数据宽度也是示意,实际电路中根据可操作的最小数据宽度,会有更多的选择器和缓冲器。图3示出了根据本发明的一个实施例的访存指令的执行过程,包括:步骤1.计算核心通过指令cache从片上或片外的存储器中获取访存指令,并通过控制部件将该访存指令提供给访存部件。步骤2.访存部件根据访存指令中的指令码识别需要执行读取还是写入操作以及需要访存的数据宽度。步骤3.访存部件根据访存指令中的访存地址,计算出对应在数据cache中的地址。步骤4.访存部件根据访存指令中的寄存器编号和寄存器对掩码,确定参与读与写操作的寄存器堆以及相应寄存器堆中的寄存器。步骤5.访存部件根据判断需要执行读取还是写入操作,对于读取操作继续步骤6,否则继续步骤7。基于本发明的处理器核心结构,能够一次性在访存部件与数据cache之间传输非常多的数据,该数据量远大于一个寄存器、甚至是一组寄存器堆的数据宽度。因而,在从数据cache中读取数据时,需要对数据进行分解,并写入到指定的一个或多个寄存器堆的寄存器中,相反地,在将数据写入数据cache时,可以将多个寄存器的数据聚合在一起并写入数据cache的指定地址中。这样的方式,与寄存器存储容量相对较低、而数据cache的存储容量高于寄存器存储容量的特点是吻合的。步骤6.按照访存指令所指定的地址从数据cache的相应位置处读取与数据宽度匹配的数据,分别写入相应寄存器堆的寄存器中。步骤7.从访存指令所指定的寄存器堆的寄存器中读取与数据宽度匹配的数据,将这些数据进行聚合后,按照访存指令所指定的地址写入数据cache的相应位置。表2-1~表2-3,分别示出了根据本发明的处理器核心中访存部件、寄存器堆和数据cache与现有技术的通用处理器及通用图形处理器的比较结果。通用处理器的访存部件为了应对各种访问模式,具有大量的队列及复杂的电路。相比之下,本发明的访存部件和通用图形处理器的访存部件都是应对较为规则的访问,设计要相对简单。本发明比通用图形处理器的访存部件仅增加一个数据聚合和分配电路,因而对复杂度的影响基本可以忽略。本发明的数据宽度大,但通用图形处理器的访存部件多,总体面积开销基本相当。本发明的聚合分配电路可能会使访存操作增加一拍的延迟。通用处理器的寄存器以及通用图形处理器的数据cache因为是多端口的共享设计,因而复杂度都比较高。表2-1表2-2表2-3通过上述实施例,本发明提供了一种结合通用处理器和通用图形处理器两者的优点、规避两者的缺点的处理器核心结构。基于该结构,可以减少所使用的访存部件数量,与该访存部件对应的数据cache的读写端口也相对较少,这使得大大降低了设计与之匹配的数据cache的难度、集成电路的面积和访问延迟。采用新的访存指令来控制访存部件,可以在不大幅增加软硬件的复杂度的情况下,实现在一个数据缓存以及k个寄存器堆之间的数据交换。发明人通过研究后发现,本发明的方案尤其适用于计算密集时数据计算的并行度和规则性都很强,但不同计算阶段计算形式变化也比较多样的应用。需要说明的是,上述实施例中介绍的各个步骤并非都是必须的,本领域技术人员可以根据实际需要进行适当的取舍、替换、修改等。最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管上文参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1