基于文档嵌入的长文本案件罚金范围分类预测方法及装置与流程
本发明涉及文本分类领域,更具体地,涉及基于文档嵌入的长文本案件罚金范围分类预测方法装置。
背景技术:
在大型诉讼和非诉案件中,成箱甚至是成车的资料需要律师事务所安排人员阅读,并据此开具天文数字的小时账单给客户,而这类工作实际生成的,无非就是给资深律师和合伙人们提供一份类似于“阅卷总结”一样的文件,以供最终的实质性法律判断。但是现在,预测性编程和利用机器学习算法的软件完全可以在短时间内完成这一工作,可以大幅降低成本、提升效率。
随着人工智能技术的发展以及司法大数据应用的广泛开展,业务人员希望通过机器阅读大量的案件事实,自动给出该案件中责任人所处罚金的范围,以提高办案效率。同时,也有利于公民根据相关案情事实快速了解可能面临的处罚。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供基于文档嵌入的长文本案件罚金范围分类预测方法及装置。
本发明旨在至少在一定程度上解决上述技术问题。
本发明的首要目的是利用大量公开的案件数据,让机器阅读大量的案件事实,学习隐藏在数据背后的法律专业经验,自动给出该案件中负责人所处罚金的范围,以提高办案效率。
为解决上述技术问题,本发明的技术方案如下:
一种基于文档嵌入的长文本案件罚金范围分类预测方法,包括以下步骤:
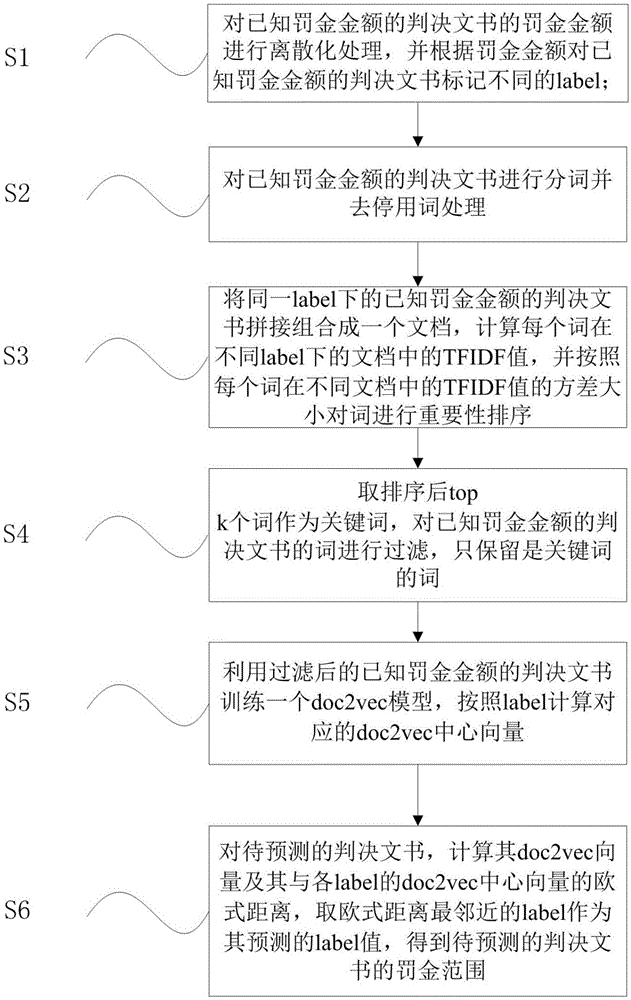
s1:对已知罚金金额的判决文书的罚金金额进行离散化处理,并根据罚金金额对已知罚金金额的判决文书标记不同的label;
s2:对已知罚金金额的判决文书进行分词并去停用词处理;
s3:将同一label下的已知罚金金额的判决文书拼接组合成一个文档,计算每个词在不同label下的文档中的tfidf值,并按照每个词在不同文档中的tfidf值的方差大小对词进行重要性排序;
s4:取排序后topk个词作为关键词,对已知罚金金额的判决文书的词进行过滤,只保留是关键词的词;
s5:利用过滤后的已知罚金金额的判决文书训练一个doc2vec模型,按照label计算对应的doc2vec中心向量;
s6:对待预测的判决文书,计算其doc2vec向量及其与各label的doc2vec中心向量的欧式距离,取欧式距离最邻近的label作为其预测的label值,得到待预测的判决文书的罚金范围。
利用公开的已知罚金金额的判决文书先根据罚金金额进行分类、分词,再进行doc2vec模型的训练,得到训练好的doc2vec模型,在对待预测的判决文书进行预判并给出预判的罚金金额,减少大量的人力物力,快速实现案件判罚判定,加速案件审理过程。
优选地,步骤s1将已知罚金金额的判决文书的罚金金额进行离散化处理具体为:
将罚金金额分为(0,2000]、(2000,3000]、(3000,4000]、(4000,5000]、(5000,6000]、(6000,10000]、(10000,500000]以及500000+八个范围,分别用1至8标记其label。
优选地,步骤s2中对已知罚金金额的判决文书进行分词并去停用词处理的具体步骤为:
使用分词工具对已知罚金金额的判决文书进行中文分词,在分词后使用中文停用词表对出现的停用词进行过滤。
优选地,步骤s3中计算每个词在不同label下的文档中的tfidf值的具体步骤如下:
s3.1:计算词w的词频(tf),计算方式如下:
式中,tf(w,d)表示词w在label为d分类下的文档中的词频(tf),count(w|d)表示词w在label为d分类下的文档中出现的次数,count(d)表示在label为d分类下的文档中出现的词数;
s3.2:计算词w的逆向文档频率(idf),计算方式如下:
式中,idf(w,d)表示词w在整个文档集合d中的逆向文档频率,n表示文档数,nw表示出现过词w的文档数;
s3.3:将词w的词频(tf)乘以逆向文档频率(idf)得到在label为d分类下的文档中词w的tfidf值。
优选地,步骤s5中利用过滤后的已知罚金金额的判决文书训练一个doc2vec模型的具体步骤如下:
s5.1:对每一过滤后的已知罚金金额的判决文书新增一paragraphid,并将其映射成一个向量,即paragraphvector,在训练过程中,paragraphid保持不变,共享着同一个paragraphvector,相当于每次在预测单词的概率时,都利用了整个判决文书的语义;
s5.2:将每一个词映射成一个向量,即wordvector,paragraphvector与wordvector的维数一样,来自于两个不同的向量空间;
s5.3:将paragraphvector和wordvector累加或连接起来,作为输出层softmax的输入;
s5.4:输出该过滤后的已知罚金金额的判决文书的paragraphvector。
优选地,步骤s5中按照label计算对应的doc2vec中心向量的具体步骤如下:
s5.5:对于每个label下的过滤后的已知罚金金额的判决文书,将该label下所有paragraphvector作为该label的doc2vec中心向量。
优选地,步骤s6中对待预测的判决文书,计算其doc2vec向量及其与各label的doc2vec中心向量的欧式距离,取欧式距离最邻近的label作为其预测的label值的具体步骤如下:
s6.1:给待预测的判决文书新分配一个paragraphid,wordvector和输出层softmax的参数保持训练阶段得到的参数不变,利用梯度下降训练待预测的判决文书,待收敛后,即得到待预测句子的doc2vec向量;
s6.2:计算待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,计算方式如下:
式中,d(x,y)表示待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,x为待预测的判决文书的doc2vec向量的分量,y为各label中心向量的分量,i=1,2...n,n为待预测的判决文书的doc2vec向量与各label中心向量的维数;
s6.3:欧式距离最小的对应簇类的label值作为待预测文书的预测label值,得到该文书罚金范围。
一种基于文档嵌入的长文本案件罚金范围分类预测装置,包括:
标记模块;
预处理模块;
计算重要性模块,包括词频计算模块,逆向文档频率计算模块,tfidf值计算模块;
关键词过滤模块;
模型处理模块,包括文书处理模块,词处理模块,输入模块,输出模块,计算平均向量模块;
预测模块,包括计算待预测的doc2vec向量模块,欧式距离计算模块,获取罚金模块;
上述装置用于完成上述所诉的一种基于文档嵌入的长文本案件罚金范围分类预测方法。
与现有技术相比,本发明技术方案的有益效果是:
本发明通过机器学习方法,利用大量公开的案件数据,让机器阅读大量的案件事实,学习隐藏在数据背后的法律专业经验,自动给出该案件中负责人所处罚金的范围,以提高办案效率,节约大量人力物力。同时,普通的公民也可以根据其所涉及的案情事实较快了解到会面临的处罚范围。
附图说明
图1为本发明提供的基于文档嵌入的长文本案件罚金范围分类预测方法流程图。
图2为本发明提供的基于文档嵌入的长文本案件罚金范围分类预测方法步骤s3流程图。
图3为本发明提供的基于文档嵌入的长文本案件罚金范围分类预测方法步骤s5流程图。
图4为本发明提供的基于文档嵌入的长文本案件罚金范围分类预测方法步骤s6流程图。
图5为本发明提供的doc2vecc-bow训练模型图。
图6为实施例1中对词tfidf值方差进行排序结果示意图。
图7为本发明提供的基于文档嵌入的长文本案件罚金范围分类预测装置示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
一种基于文档嵌入的长文本案件罚金范围分类预测方法,如图1,包括以下步骤:
s1:对已知罚金金额的判决文书的罚金金额进行离散化处理,并根据罚金金额对已知罚金金额的判决文书标记不同的label,将罚金金额分为(0,2000]、(2000,3000]、(3000,4000]、(4000,5000]、(5000,6000]、(6000,10000]、(10000,500000]以及500000+八个范围,分别用1至8标记其label;
s2:使用分词工具对已知罚金金额的判决文书进行中文分词,在分词后使用中文停用词表对出现的停用词进行过滤;
s3:将同一label下的已知罚金金额的判决文书拼接组合成一个文档,计算每个词在不同label下的文档中的tfidf值,如图3,并按照每个词在不同文档中的tfidf值的方差大小对词进行重要性排序,具体如下:
s3.1:计算词w的词频(tf),计算方式如下:
式中,tf(w,d)表示词w在label为d分类下的文档中的词频(tf),count(w|d)表示词w在label为d分类下的文档中出现的次数,count(d)表示在label为d分类下的文档中出现的词数;
s3.2:计算词w的逆向文档频率(idf),计算方式如下:
式中,idf(w,d)表示词w在整个文档集合d中的逆向文档频率,n表示文档数,nw表示出现过词w的文档数;
s3.3:将词w的词频(tf)乘以逆向文档频率(idf)得到在label为d分类下的文档中词w的tfidf值。;
s4:取排序后topk个词作为关键词,对已知罚金金额的判决文书的词进行过滤,只保留是关键词的词;
s5:利用过滤后的已知罚金金额的判决文书训练一个doc2vec模型,按照label计算对应的doc2vec中心向量,如图2,具体步骤为:
s5.1:对每一过滤后的已知罚金金额的判决文书新增一paragraphid,并将其映射成一个向量,即paragraphvector,在训练过程中,paragraphid保持不变,共享着同一个paragraphvector,相当于每次在预测单词的概率时,都利用了整个判决文书的语义;
s5.2:将每一个词映射成一个向量,即wordvector,paragraphvector与wordvector的维数一样,来自于两个不同的向量空间;
s5.3:将paragraphvector和wordvector累加或连接起来,作为输出层softmax的输入;
s5.4:输出该过滤后的已知罚金金额的判决文书的paragraphvector。
s5.5:对于每个label下的过滤后的已知罚金金额的判决文书,将该label下所有paragraphvector作为该label的doc2vec中心向量;
s6:对待预测的判决文书,计算其doc2vec向量及其与各label的doc2vec中心向量的欧式距离,取欧式距离最邻近的label作为其预测的label值,得到待预测的判决文书的罚金范围,具体步骤如下:
s6.1:给待预测的判决文书新分配一个paragraphid,wordvector和输出层softmax的参数保持训练阶段得到的参数不变,利用梯度下降训练待预测的判决文书,待收敛后,即得到待预测句子的doc2vec向量;
s6.2:计算待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,计算方式如下:
式中,d(x,y)表示待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,x为待预测的判决文书的doc2vec向量的分量,y为各label中心向量的分量,i=1,2...n,n为待预测的判决文书的doc2vec向量与各label中心向量的维数;
s6.3:欧式距离最小的对应簇类的label值作为待预测文书的预测label值,得到该文书罚金范围。
实施例2
一种基于文档嵌入的长文本案件罚金范围分类预测装置,包括:
标记模块;
预处理模块;
计算重要性模块,包括词频计算模块,逆向文档频率计算模块,tfidf值计算模块;
关键词过滤模块;
模型处理模块,包括文书处理模块,词处理模块,输入模块,输出模块,计算平均向量模块;
预测模块,包括计算待预测的doc2vec向量模块,欧式距离计算模块,获取罚金模块;
上述装置用于完成上述所诉的一种基于文档嵌入的长文本案件罚金范围分类预测方法。
在具体的实施过程中,标记模块对已知罚金金额的判决文书的罚金金额进行离散化处理,并根据罚金金额对已知罚金金额的判决文书标记不同的label,预处理模块对对已知罚金金额的判决文书进行分词并去停用词处理,词频计算模块计算词w的词频(tf),计算方式如下:
式中,tf(w,d)表示词w在label为d分类下的文档中的词频(tf),count(w|d)表示词w在label为d分类下的文档中出现的次数,count(d)表示在label为d分类下的文档中出现的词数;
逆向文档频率计算模块计算词w的逆向文档频率(idf),计算方式如下:
式中,idf(w,d)表示词w在整个文档集合d中的逆向文档频率,n表示文档数,nw表示出现过词w的文档数;
tfidf值计算模块将词w的词频(tf)乘以逆向文档频率(idf)得到在label为d分类下的文档中词w的tfidf值;
计算重要性模块还能按照每个词在不同文档中的tfidf值的方差大小对词进行重要性排序;
关键词过滤模块取排序后topk个词作为关键词,对已知罚金金额的判决文书的词进行过滤,只保留是关键词的词;
文书处理模块对每一过滤后的已知罚金金额的判决文书新增一paragraphid1,并将其映射成一个paragraphvector向量,在训练过程中,paragraphid1保持不变,共享着同一个paragraphvector;
词处理模块将每一个词映射成一个wordvector向量,paragraphvector与wordvector的维数一样,来自于两个不同的向量空间;
输入模块将paragraphvector和wordvector累加或连接起来,作为输入;
输出模块输出该过滤后的已知罚金金额的判决文书的paragraphvector;
计算平均向量模块对于每个label下的过滤后的已知罚金金额的判决文书,将该label下所有paragraphvector的平均向量作为该label的doc2vec中心向量;
计算待预测的doc2vec向量模块给待预测的判决文书新分配一个paragraphid2,wordvector和输出的参数保持训练阶段得到的参数不变,利用梯度下降训练待预测的判决文书,待收敛后,即得到待预测句子的doc2vec向量;
欧式距离计算模块计算待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,计算方式如下:
式中,d(x,y)表示待预测的判决文书的doc2vec向量与各label中心向量的欧式距离,x为待预测的判决文书的doc2vec向量的分量,y为各label中心向量的分量,i=1,2...n,n为待预测的判决文书的doc2vec向量与各label中心向量的维数;
获取罚金模块对欧式距离最小的对应簇类的label值作为待预测文书的预测label值,得到该文书罚金范围。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!