结合深度学习和逻辑规则的企业新闻数据风险分类方法与流程
本发明属于数据处理技术领域,具体涉及一种结合深度学习和逻辑规则的企业新闻数据风险分类方法。
背景技术:
目前,最新技术有大量的文本分类模型和情感分析模型,其算法都相对较为成熟。现有的文本分类模型和情感分析模型为相互独立的算法。其中文本分类模型采用的主流算法有bi-lstm算法和cnn、fasttext算法,都可以是基于字符、基于词的针对整篇新闻作为训练语料数据,由于其针对全文作为训练语料,那么对于特定的一篇新闻文章只有一个分类,但是当新闻中出现多个公司主体时,在事实上对于不同的公司主体来说可能具有不同的分类。例如,某篇新闻内容描述了公司a的负面信息和公司b的正面信息,如果针对全文进行分类,始终只能得出一个类别,该分类可能针对公司a的类别是对的,但是在公司a和公司b的类别不一样的情况下(公司a为负面类别,公司b为正面类别),现有分类思路始终无法满足在同一篇新闻中针对不同主体打标分类。而情感分析较多采用bi-lstm算法,情感分析通常只输出整篇文章情感倾向,包括正面概率,负面概率;没有更加具体的情感类别区分。因此,完全依赖一个模型预测,其准确度高度依赖于新闻语料数据的准备,鉴于新闻样式繁多,同样的新闻出自不同的撰写人可能风格完全不同,因此具有局限性。
技术实现要素:
为了解决现有技术存在的上述问题,本发明目的在于提供一种可针对某一特定主体进行分类的结合深度学习和逻辑规则的企业新闻数据风险分类方法。
本发明所采用的技术方案为:
一种结合深度学习和逻辑规则的企业新闻数据风险分类方法,包括如下步骤:
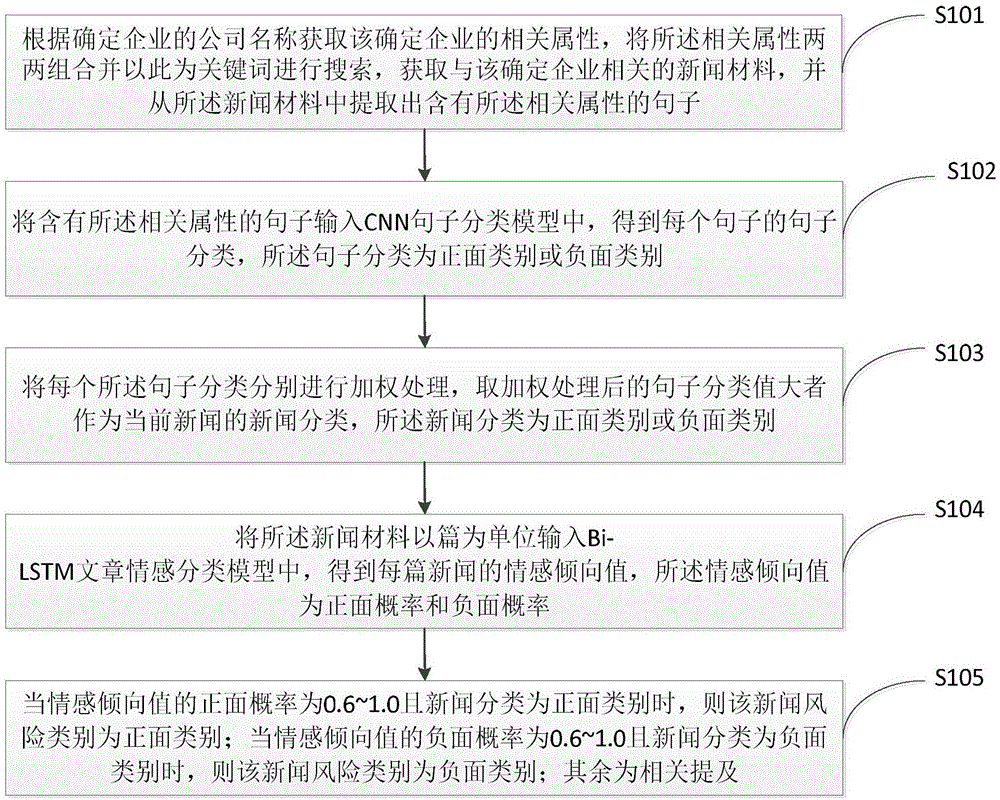
根据确定企业的公司名称获取该确定企业的相关属性,将所述相关属性两两组合并以此为关键词进行搜索,获取与该确定企业相关的新闻材料,并从所述新闻材料中提取出含有所述相关属性的句子;
将含有所述相关属性的句子输入cnn句子分类模型中,得到每个句子的句子分类,所述句子分类为正面类别或负面类别;
将每个所述句子分类分别进行加权处理,取加权处理后的句子分类值大者作为当前新闻的新闻分类,所述新闻分类为正面类别或负面类别;
将所述新闻材料以篇为单位输入bi-lstm文章情感分类模型中,得到每篇新闻的情感倾向值,所述情感倾向值为正面概率和负面概率;
当情感倾向值的正面概率为0.6~1.0且新闻分类为正面类别时,则该新闻风险类别为正面类别;当情感倾向值的负面概率为0.6~1.0且新闻分类为负面类别时,则该新闻风险类别为负面类别;其余为相关提及。
进一步,所述相关属性包括但不限于法人名、高管名、公司简称、股票简称、公司历史名和产品名。
更进一步,所述cnn句子分类模型是采用cnn算法训练而成的企业新闻分类模型。
更进一步,所述bi-lstm文章情感分类模型采用bi-lstm算法训练而成。
更进一步,所述cnn句子分类模型采用如下方法训练而成:
准备训练语料数据;
将训练语料数据中的句子输入cnn句子分类训练模型中,训练得到cnn句子分类模型。
更进一步,所述bi-lstm文章情感分类模型采用如下方法训练而成:
准备训练语料数据;
将训练语料数据以篇为单位输入bi-lstm文章情感分类训练模型中,训练得到bi-lstm文章情感分类模型。
更进一步,所述准备训练语料数据包括如下步骤:
使用网络爬虫在新闻数据来源中抓取企业类新闻材料,并将该企业类新闻材料以文本的形式存储在数据库中;
根据企业关注的新闻焦点,总结统计所需新闻类别;
针对不同的新闻类别自定义一系列的强规则;
根据所述自定义的强规则,在数据库中筛选出与该强规则相匹配的新闻材料作为备用语料数据;
采用人工对强规则筛出来的备用语料数据进行核对,筛选出第一训练语料数据;
采用人工从各大网站获取不同新闻类别的数据,作为第二训练语料数据;
将第一语料数据和第二语料数据融合,得到训练语料数据。
本发明的有益效果为:
本发明通过结合cnn句子分类模型与bi-lstm文章情感分类模型对新闻数据风险类别进行预测,可更加准确地预测新闻中企业主体的风险信息,准确性更高。
附图说明
图1为本发明流程图。
图2为本发明中准备训练语料数据的流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步阐述。以下实施例仅用于更加清楚地说明本发明的产品,因此只是作为示例,而不能以此来限制本发明的保护范围。
实施例:
本发明实施例提供的一种结合深度学习和逻辑规则的企业新闻数据风险分类方法,如图1所示,包括如下步骤:
s101、根据确定企业的公司名称获取该确定企业的相关属性,将所述相关属性两两组合并以此为关键词进行搜索,获取与该确定企业相关的新闻材料,并从所述新闻材料中提取出含有所述相关属性的句子。
确定企业为需要进行新闻数据风险分析的企业,根据该确定企业的公司名称获取该确定企业的相关属性,相关属性包括但不限于法人名、高管名、公司简称、股票简称、公司历史名和产品名。
两两组合的意思为两个相关属性是and的关系。以两两组合的相关属性为关键词进行新闻材料的搜索,其准确性更高,可防止因不同公司相同属性值的出现而搜索到与该确定企业不相关的新闻材料,影响后续计算。例如,重庆誉存大数据科技有限公司和北京誉存大数据科技有限公司的公司简称均有可能为誉存大数据,如果仅以单个的相关属性进行搜索,则无法准确定位搜索结果中的新闻材料是关于重庆誉存大数据科技有限公司还是北京誉存大数据科技有限公司。
将确定企业的相关属性两两组合,并以此为关键词在互联网上进行搜索,获取与该确定企业相关的新闻材料,并从该新闻材料中提取出含有该确定企业相关属性(关键词)的句子。
s102、将含有所述相关属性的句子输入cnn句子分类模型中,得到每个句子的句子分类,所述句子分类为正面类别或负面类别。
cnn句子分类模型是采用cnn算法训练而成的企业新闻分类模型,该模型可采用现有文本分类模型训练方法训练而成。通过cnn句子分类模型对每个句子类别进行预测,得到每个句子的分类,该分类为正面类别或负面类别。由于每个句子含有确定企业的相关属性,因此,该句子分类的预测是针对该确定企业进行的预测。
s103、将每个所述句子分类分别进行加权处理,取加权处理后的句子分类值大者作为当前新闻的新闻分类,所述新闻分类为正面类别或负面类别。
本实施例中,将新闻标题权重赋予3,其余均权重赋予1,因为新闻标题往往更多的代表作者的情感倾向。将新闻材料中每个句子类别分别加权处理后相加,取值大者作为该新闻材料的新闻分类。即将正面类别的句子和负面类别的句子分别加权处理后相加,若正面类别的值大,则该新闻分类为正面类别,若负面类别的值大,则该新闻分类为负面类别。
本发明根据企业主体进行句子提取,通过对句子分类进行预测,进而实现针对于该主体的新闻材料的类别预测。由于每个句子均包含确定企业的相关属性,因此预测结果必然是针对于该确定企业的。若同一篇新闻材料中涉及多个企业主体,采用本发明方法,可根据不同主体提取出不同的句子,得到针对于不同企业主体的新闻分类,其分类更加准确。
为了进一步提高新闻风险分类的准确性,本发明还包括如下步骤:
s104、将新闻材料以篇为单位输入bi-lstm文章情感分类模型中,得到每篇新闻的情感倾向值,所述情感倾向值为正面概率和负面概率。
bi-lstm文章情感分类模型采用bi-lstm算法训练而成。将每篇新闻材料输入bi-lstm文章情感分类模型中进行预测,得到每篇新闻的情感倾向值,情感倾向值为正面概率和负面概率。如某篇新闻材料预测结果为:正面概率为0.75,负面概率为0.25,同一篇新闻材料,其正面概率与负面概率之和为1.0。
s105、当情感倾向值的正面概率为0.6~1.0且新闻分类为正面类别时,则该新闻风险类别为正面类别;当情感倾向值的负面概率为0.6~1.0且新闻分类为负面类别时,则该新闻风险类别为负面类别;其余为相关提及。
在具体实施例中,新闻风险类别为相关提及有如下几种情况:
第一种:情感倾向值的正面概率在0.6~1.0之间,且新闻分类为负面类别。
第二种:情感倾向值的负面概率在0.6~1.0之间,且新闻分类为正面类别。
第三种:情感倾向值的正面概率和负面概率均为0.5,且新闻分类为正面类别。
第四种:情感倾向值的正面概率和负面概率均为0.5,且新闻分类为负面类别。
本发明仅针对企业类新闻(如新闻的财经板块、公司板块等)进行预测,通过结合cnn句子分类模型与bi-lstm文章情感分类模型对新闻数据风险类别进行预测,可更加准确地预测新闻中企业主体的风险信息,准确性更高。
训练cnn句子分类模型和bi-lstm文章情感分类模型离不开训练语料,参见图2:本发明中,训练语料数据准备方法包括如下步骤:
s201、使用网络爬虫在新闻数据来源中抓取尽可能多的企业类新闻材料,并将该企业类新闻材料以文本的形式存储在数据库中。
新闻数据来源包括全国各大门户网站的公司新闻和财经新闻板块以及与财经、企业等相关的各个中小型网站。
s202、根据企业关注的新闻焦点,总结统计所需新闻类别。
新闻类别包括但不限于“偷税漏税”、“政策监管”、“失信风险”、“违法犯罪”、“事故信息”、“股权变动”、“产品问题”、“合作共赢”、“业务变动”、“抄袭侵权”、“法务纠纷”、“违反规定”、“工资拖欠”、“产品升级”、“高管离职”、“投资融资”、“运营风险”、“畏罪潜逃”、“贪污贿赂”、“欺诈骗局”、“成果奖项”、“裁员降薪”、“上市失利”、“股票利好”、“破产倒闭”、“战略风险”、“披露有误”、“公告公示”、“抵押质押”、“停业整改”、“股票利空”、“债务信息”、“业绩亏损”、“财务风险”、“业务欠款”、“其他”、“合作风险”。
多数新闻类别为风险性类别,比如偷税漏税,直观体现了新闻描述了主体公司的负面信息,使得用户对主体企业有一个基本的认识。
s203、针对不同的新闻类别自定义一系列的强规则。
强规则根据实际情况进行设置,例如针对成果奖项,设定规则为:'赞.*成果|(年度|福布斯).*(榜|人物|集体|经理人)|(获得|荣获|授予|入选).*(单位"|单位”|企业"|企业”|公司”|公司"|专利|奖(?!金)|称号|荣誉|”学位|博士|人物|经理人|集体)|(年?!报|中国|企业|全球|世界).*(强?<!强|榜单|名?!公司|最佳|纳税排行)|(进入|跻身).*(世界|中国|地区).*强|(人力资源|强).*排行榜|”蝉联|获.*最佳|入围.*(强|榜)|跃.*首位|价值榜.*发布|入.*榜|全球.*最大.*平台|发布.*独角兽名单|卖地.*第一|荣膺年度|财富.*改变世界的公司|’超过.*登顶|净利润.*行业榜首|身家暴涨.*登首富|亮点突出|媒.*评.*最美|成功.*最大|获.*(季军|冠军|亚军)|保持.*稳健.*扩张|大赛.*奖金|赢得.*好评|'创.*项第一'。
s204、根据步骤s203自定义的强规则,在数据库中筛选出与该强规则相匹配的新闻材料作为备用语料数据。
s205、采用人工对强规则筛出来的备用语料数据进行核对,筛选出第一训练语料数据。
在具体实施例中,人工根据需要对指定强规则筛选出来的备用语料数据进行核对,以确定筛选出来的备用语料是否属于所指定的新闻类别,防止强规则出错。因为新闻型式变化万千,受撰写人的影响相当大,有时候强规则筛选出的数据并不完全都是我们想要拿到的数据。增加人工核对的步骤,使训练语料数据更加准确,从而保证训练的模型准确率更高。
s206、采用人工从各大网站获取不同新闻类别的数据,作为第二训练语料数据。
s207、将第一语料数据和第二语料数据融合,得到训练语料数据。
训练语料数据中,每个新闻类别的训练语料数据不少于5000条。
第一训练语料数据和第二训练语料数据按1:1比例准备。并且第一训练语料数据与第二训练语料数据不重复。
将训练语料中的句子输入cnn句子分类训练模型中,采用开源cnn算法,训练得到cnn句子分类模型。
将句子所对应的新闻文本输入bi-lstm文章情感分类训练模型中,采用开源bi-lstm算法,训练得到bi-lstm文章情感分类模型。
本发明不局限于上述可选实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是落入本发明权利要求界定范围内的技术方案,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!