基于注意力机制与联结时间分类损失的文字识别方法与流程
本发明属于光学字符识别领域,具体涉及一种基于注意力机制与联结主义时间分类的文字识别方法。
背景技术:
随着智能化和移动终端的大力普及,自然场景图像的语义信息在自动驾驶,智能交通,视觉辅助等领域发挥越来越重要的作用。
为解决自然场景文本图像识问题,strokelets通过对图像块聚类来获取文本中的笔画特征,利用hog特征检测字符并结合随机森林分类器对字符进行分类。而photoocr系统利用hog特征分类器对分割得到的候选结果进行打分,再结合n元语言模型的beamsearch算法得到候选字符集合,最后利用语言模型和形状模型对候选字符组合进行重新排序。jaderbergm等提出的算法结合文本/非文本分类器、字符分类器和二元语言模型分类器,对图像进行密集滑动窗口扫描,并利用固定词典对图片中的单词进行分析,从而达到对文本语义分割和识别的目的。上述方法仍存在以下问题:1)识别的特征依赖人工定义,而人工定义的特征难以捕获图片的深层语义,制作耗时且通用性不高。2)基于单个字符的识别会脱离上下文环境,易导致歧义。3)文本结构复杂、语义多变,需要对字符进行分割预处理,而强行分割会破坏字符结构。4)过度依赖分类字典。分类字典的选取直接影响识别结果,导致识别模型泛化能力差。
技术实现要素:
为解决上述问题,本发明提出了一种基于注意力机制和联结时间分类损失的端到端自然场景文本识别算法。该算法由多尺度特征提取层,长短使其记忆网络编码层,基于注意力机制和联结时间分类损失的解码层组成。输入为自然场景文本图像,输出为解码后的文本,实现了从图像到文本的端到端识别机制。在提升识别率的同时改善了神经网络在文本识别方向的适用性。
为实现上述目的,本发明的技术方案为一种基于注意力机制与联结时间分类损失的文字识别方法,包括如下步骤:
s1:采集数据集:采集各种自然场景下的文本,并将这些文本合并;将数据集划分为训练数据集,验证数据集,测试数据集三部分;先将原始的数据集打乱,然后按比例进行切分,切分比例为7:2:1;训练数据集作为优化模型参数使用,验证数据集作为模型选择使用,测试数据集作为模型最终评估使用;
将挑选的数据集记作t={(x1,y1),(x2,y2),…,(xn,yn)},其中xi表示第i张图片,yi表示第i个图片对应的标签,n表示样本的总数;
s2:对图片样本进行尺度缩放,灰度转换和像素归一化等预处理;
s3:对样本的标签序列进行处理,包括填补,编码和词嵌入;
s4:构建卷积神经网络,对经过s3处理后的文本图像进行特征提取;
s5:使用堆叠式双向循环神经网络对s4提取的特征进行编码,得到编码特征;
s6:将s5得到的编码特征输入到联结时间分类模型中计算预测概率;
s7:使用注意力机制计算不同编码特征的权重,得到编码后的语义向量。
进一步的,所述步骤s2具体包括如下步骤:
s2.1:选取b个样本作为一个批次的训练数据β,其中β={x1,x2,…,xb};b个样本可能有不同的高和宽,样本维度为
shape={(h1,w1,3),(h2,w2,3),…,(hb,wb,3)};
将样本集β中每个样本进行等比例缩放,其中高固定为32个像素,得到新数据样本集,此时新样本的维度为
shape={(32,w′1,3),(32,w′2,3),…,(32,w′b,3)};
获取新样本集中文本图片的最大宽度值wmax=max(w′1,w′2,…,w′b),其中max(·)表示其中元素的最大值;通过填补,镜像或者缩放等方法将新样本集中的宽度变换到最大的宽度,高固定为32,获得新的样本数据集β′,新样本集的维度为shape={(32,wmax,3),(32,wmax,3),…,(32,wmax,3)};
s2.2:对β′中每一个样本进行灰度转换和像素归一化处理,步骤如下:
s2.2.1:对训练集t′中每张彩色图像进行灰度转换,变化公式如下:
x′gray=xr*0.299+xg*0.587+xb*0.114
其中,x为彩色图片样本,xr,xg,xb分别为样本的红色,绿色,蓝色通道的数值,xgray为变换后的灰色样本的像素值;
s2.2.2:对灰度转换后样本进行像素归一化,即将[0,255]的像素值转换到[-0.5,0.5];
其中,xgray为s3.1转换后得到的灰色图像,xnorm为像素归一化后的数值。
进一步的,所述步骤s3具体包括如下步骤:
s3.1:b个样本对应的标签为y={y1,y2,…,yb},第i个样本对应的标签为yi={s1,s2,…,sm},m为组成第i个标签的序列的长度,sj为第j个标签的序列的第j个字符;每个标签的序列长度为len={m1,m2,…,mb};获得最大的长度值lmax=max(m1,m2,…,mb),并将所有的序列填补成相同的长度;
s3.2:对s3.1得到的标签进行编码和和词嵌入,得到词嵌入后的向量;具体步骤如下:
s3.2.1:创建编码字典,将标签中出现的字符或字符串转换为对应的数字编码;
s3.2.2:构建词嵌入模型,将编码后的标签输入到词嵌入模型中,将离散的数字映射到连续区域,最终每个标签得到固定的长度的词向量。
进一步的,所述步骤s4具体包括如下步骤:
s4.1:构建inceptionv2结构的卷积神经网络提取文本特征,inceptionv2的结构为1x1,3x3,5x5的卷积层和3x3的pooling层并行堆叠在一起,并在每一层前都使用上一层1x1的卷积层作为特征降维;
s4.2:每一层inception结构后堆叠批标准化层(bn),批标准化变换公式为
其中,β为一个训练批次的样本集,表示为β={x1,x2,…,xb},i表示样本集β中的第i个样本,μβ表示样本集β的样本均值,
s4.3:重复堆叠inception和bn层,经过构建后的网络使得特征图输出维度为shape=[b,1,w,c],其中b为一个批次的样本数量,1为经过卷积网络后特征的高,w为特征图的宽度,c为特征图的通道数量。
进一步的,所述步骤s5具体包括如下步骤:
s5.1:构建循环神经网络使用堆叠式双向循环神经网络对s4.1提取的特征进行编码,得到编码特征序列;循环神经网络由三部分组成:首先是一个全连接网络层用来嵌入经过编码后的特征,然后将特征输入至lstm(长短时期记忆网络)的双向循环神经网络,进行两层双向lstm堆叠,具体操作步骤如下:
s5.1.1:构建第一层双向循环神经网络,双向循环神经网络为两个单向其方向相反的循环神经网络,前向网络和反向网络的结合,在每一个时刻t,网络的输出由这两个方向相反的单向循环神经网络共同决定,设置nin=512,nstep=w,nnums=256,其中nin为lstm的双向循环神经网络的输入层神经元数目,nstep代表循环神经网络的循环次数,此处为特征图的宽度,nnums表示为lstm隐藏层神经元的数目;
s5.1.2:构建第二层双向循环神经网络,设置nin=256,nstep=w,nnums=256,其中nin为循环神经网络的输入,此处为第一层循环神经网络的输出,nstep代表循环神经网络的循环次数,nnums表示为lstm隐藏层神经元个数;双向循环神经网络的输出为h=[h1,h2,…,hw],即编码后的特征序列。
进一步的,所述步骤s6具体包括如下步骤:
s6.1:构建输出层的全连接网络:将lstm的隐含层输出作为全连接的输入,设置nin=512,nout=65;nin为全连接层的输入,维度与s5提取的编码特征一致;nout为全连接的输出,与最终识别的字符个数相同;
s6.2:将s5得到的特征序列依次输入到堆叠式双向循环神经网络中,最终得到的输出特征向量为o=[o1,o2,…,ow],oi为第i个特征序列对应的输出,
oi=f(whi+b)
其中,w为全连接层的网络权重,b为网络的偏置;h为s5得到的编码特征序列;w的维度为512×65,b的维度为65,o的维度65,f为relu函数
s6.3:构建softmax层,将o作为softmax的输入,将数值归一化到0到1之间,作为概率输出,归一化公式如下
其中,i为预测的第i个字符,o为全连接的输出,p为归一化后的概率值,y为预测输出的字符;
s6.4:构建连接时间分类损失模型,具体操作步骤如下:
s6.4.1:计算对齐概率:
其中t为解码的第t步,x为s7得到的特征序列,w为特征序列长度,p为已知特征序列x,解码出路径π的概率;y为由softmax归一化后的概率;
s6.4.2:构建多到一的映射β,将预测相同的路径合并为一条路径,如β(a-ab-)=β(-aa--abb)=aab;
s6.4.3:计算所有的路径的概率和,计算公式如下:
其中x为输入的特征序列,π为某一条路径,β为路径合并映射方法;l为输出的标签集合,p(l|x)表示为已知输入特征x,得到标签的l概率;
s6.4.5:最终输出给定输入序列下的最可能的标记输出
进一步的,所述步骤s7具体包括如下步骤:
s7.1:计算每一步解码时输入特征序列的权重,具体操做步骤如下:
s7.1.1:计算输入特征和解码特征之间的匹配分数,计算公式如下:
其中,t为解码的第t时刻,i为s5编码得到的第i个输入特征序列,h为输入的特征序列,v和w为可训练的参数;
s7.1.2:使用softmax函数对分数进行归一化,作为每个输入特征的权重,计算公式如下:
其中ait为t时刻编码网络的第i个特征向量的权重;
s7.1.3:对输入特征进行加权平均得到解码时输入的中间语义向量c,计算公式如下:
s7.2:使用堆叠式双向循环神经网络进行解码,将s7得到的预测概率,s8处理后得到的中间语义和s6处理后的词向量标签作为解码网络的输入;此时输入为:
x′t=[octc;xt;ct-1]
其中,t为解码的t时刻,xt为当前的s3得到的标签的词嵌入向量,ct-1为t-1时刻通过s7.1计算出的中间语义向量,octc为s6计算的预测概率;输出的隐含层的输出为h=[h1,h2,…,hl],其中l为标签的长度;
s7.3:将s7.2计算得到的输出的向量经过全连接层和softmax层,得到预测的输出。
本发明的有益效果是:
1、本发明使用了两层基于lstm的双向循环神经网络,第一层lstm可以对获取文本图像特征的双向依赖关系,为解码网络提供更加丰富的信息,第二层lstm可以获得字符之间的依赖关系,隐式的学习了高级的语义模型。
2、本发明融合了注意力机制和连接时间分类损失,该网络在解码时使用注意力机制获得全局的特征,但连接时间分类损失可以对解码网络进行约束,使其对局部的特征分配更大的权重,更符合文本图像的特点。
附图说明
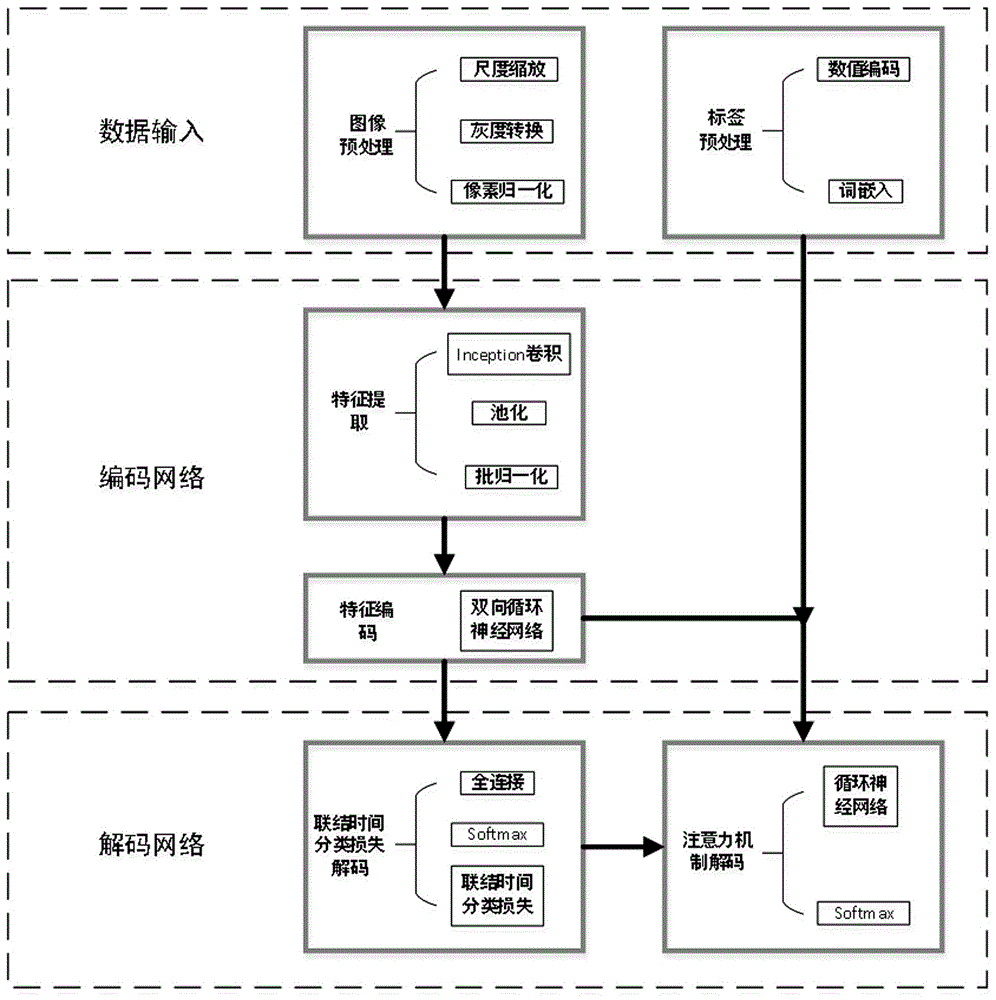
图1为本发明基于注意力机制和联结时间分类损失的自然场景文本识别的步骤流程图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,本发明的基于注意力机制与联结时间分类损失的文字识别方法,具体实施步骤如下:
s1:采集数据集。采集各种自然场景下的文本,并将这些文本合并。将数据集划分为训练数据集,验证数据集,测试数据集三部分。为保证训练集,验证集和测试集有相同的样本分布,先将原始的数据集打乱,然后按比例进行切分,切分比例为7:2:1。训练数据集作为优化模型参数使用,验证数据集作为模型选择使用,测试数据集作为模型最终评估使用。将挑选的数据集记作t={(x1,y1),(x2,y2),…,(xn,yn)},其中xi表示第i张图片,yi表示第i个图片对应的标签,n表示样本的总数。
s2:对图片样本进行尺度缩放,灰度转换和像素归一化等预处理,具体操作有:
s2.1:选取b个样本作为一个批次的训练数据β,其中β={x1,x2,…,xb}。b个样本可能有不同的高和宽,样本维度为shape={(h1,w1,3),(h2,w2,3),…,(hb,wb,3)};
将样本集β中每个样本进行等比例缩放,其中高固定为32个像素,得到新数据样本集,此时新样本的维度为shape={(32,w′1,3),(32,w′2,3),…,(32,w′b,3)}。获取新样本集中文本图片的最大宽度值wmax=max(w′1,w′2,…,w′b),其中max(·)表示其中元素的最大值。通过填补,镜像或者缩放等方法将新样本集中的宽度变换到最大的宽度,高固定为32,获得新的样本数据集β′,新样本集的维度为shape={(32,wmax,3),(32,wmax,3),…,(32,wmax,3)}
s2.2:对β′中每一个样本进行灰度转换和像素归一化处理,步骤如下:
s2.2.1:对训练集t′中每张彩色图像进行灰度转换,变化公式如下:
x′gray=xr*0.299+xg*0.587+xb*0.114
其中,x为彩色图片样本,xr,xg,xb分别为样本的红色,绿色,蓝色通道的数值,xgray为变换后的灰色样本的像素值。
s2.2.2:对灰度转换后样本进行像素归一化,即将[0,255]的像素值转换到[-0.5,0.5]。
其中,xgray为s3.1转换后得到的灰色图像,xnorm为像素归一化后的数值。
s3:对样本的标签序列进行处理,包括填补,编码和词嵌入,具体操作有:
s3.1:b个样本对应的标签为y={y1,y2,…,yb},第i个样本对应的标签为yi={s1,s2,…,sm},m为组成第i个标签的序列的长度,sj为第j个标签的序列的第j个字符。此时每个标签的序列长度为len={m1,m2,…,mb}。获得最大的长度值lmax=max(m1,m2,…,mb),并将所有的序列填补成相同的长度。
s3.2:对s3.1得到的标签进行编码和和词嵌入,得到词嵌入后的向量。具体步骤如下:
s3.2.1:创建编码字典,将标签中出现的字符或字符串转换为对应的数字编码。
s3.2.2:构建词嵌入模型,将编码后的标签输入到词嵌入模型中,将离散的数字映射到连续区域,最终每个标签得到固定的长度的词向量。
s4:构建卷积神经网络,对经过s3处理后的文本图像进行特征提取。具体操作步骤如下:
s4.1:构建inceptionv2结构的卷积神经网络提取文本特征,inceptionv2的结构为1x1,3x3,5x5的卷积层和3x3的pooling层并行堆叠在一起,并在每一层前都使用上一层1x1的卷积层作为特征降维。
s4.2:每一层inception结构后堆叠批标准化层(bn),批标准化变换公式为
其中,β为一个训练批次的样本集,表示为β={x1,x2,…,xb},i表示样本集β中的第i个样本,μβ表示样本集β的样本均值,
s4.3:重复堆叠inception和bn层,经过构建后的网络使得特征图输出维度为shape=[b,1,w,c],其中b为一个批次的样本数量,1为经过卷积网络后特征的高,w为特征图的宽度,c为特征图的通道数量。
s5:使用堆叠式双向循环神经网络对s4提取的特征进行编码,得到编码特征,具体操作步骤如下:
s5.1:构建循环神经网络使用堆叠式双向循环神经网络对s4.1提取的特征进行编码,得到编码特征序列。循环神经网络由三部分组成:首先是一个全连接网络层用来嵌入经过编码后的特征,然后将特征输入至lstm(长短时期记忆网络)的双向循环神经网络,进行两层双向lstm堆叠,具体操作步骤如下:
s5.1.1:构建第一层双向循环神经网络,双向循环神经网络为两个单向其方向相反的循环神经网络(前向网络和反向网络)的结合,在每一个时刻t,网络的输出由这两个方向相反的单向循环神经网络共同决定,设置nin=512,nstep=w,nnums=256,其中nin为lstm的双向循环神经网络的输入层神经元数目,nstep代表循环神经网络的循环次数,此处为特征图的宽度,nnums表示为lstm隐藏层神经元的数目。
s5.1.2:构建第二层双向循环神经网络,设置nin=256,nstep=w,nnums=256,其中nin为循环神经网络的输入,此处为第一层循环神经网络的输出,nstep代表循环神经网络的循环次数,nnums表示为lstm隐藏层神经元个数。双向循环神经网络的输出为h=[h1,h2,…,hw],即编码后的特征序列。
s6:将s5得到的编码特征输入到联结时间分类模型中计算预测概率。具体步骤为:
s6.1:构建输出层的全连接网络。将lstm的隐含层输出作为全连接的输入,设置nin=512,nout=65。nin为全连接层的输入,维度与s5提取的编码特征一致。nout为全连接的输出,与最终识别的字符个数相同(52个大小写字符,10个数字,3个特殊的标识符)。
s6.2:将s5得到的特征序列依次输入到堆叠式双向循环神经网络中,最终得到的输出特征向量为o=[o1,o2,…,ow],oi为第i个特征序列对应的输出,
oi=f(whi+b)
其中,w为全连接层的网络权重,b为网络的偏置。h为s5得到的编码特征序列。w的维度为512×65,b的维度为65,o的维度65,f为relu函数
s6.3:构建softmax层,将o作为softmax的输入,将数值归一化到0到1之间,作为概率输出,归一化公式如下
其中,i为预测的第i个字符,o为全连接的输出,p为归一化后的概率值,y为预测输出的字符。
s6.4:构建连接时间分类损失模型,具体操作步骤如下:
s6.4.1:计算对齐概率:
其中t为解码的第t步,x为s7得到的特征序列,w为特征序列长度,p为已知特征序列x,解码出路径π的概率。y为由softmax归一化后的概率。
s6.4.2:构建多到一的映射β,将预测相同的路径合并为一条路径,如β(a-ab-)=β(-aa--abb)=aab
s6.4.3:计算所有的路径的概率和,计算公式如下:
其中x为输入的特征序列,π为某一条路径,β为路径合并映射方法。l为输出的标签集合,p(l|x)表示为已知输入特征x,得到标签的l概率
s6.4.5:最终输出给定输入序列下的最可能的标记输出
s7:使用注意力机制计算不同编码特征的权重,得到编码后的语义向量。具体操作步骤如下:
s7.1:计算每一步解码时输入特征序列的权重,具体操做步骤如下:
s7.1.1:计算输入特征和解码特征之间的匹配分数,计算公式如下:
其中,t为解码的第t时刻,i为s5编码得到的第i个输入特征序列,h为输入的特征序列,v和w为可训练的参数。
s7.1.2:使用softmax函数对分数进行归一化,作为每个输入特征的权重,计算公式如下:
其中ait为t时刻编码网络的第i个特征向量的权重。
s7.1.3:对输入特征进行加权平均得到解码时输入的中间语义向量c,计算公式如下:
s7.2:使用堆叠式双向循环神经网络进行解码,将s7得到的预测概率,s8处理后得到的中间语义和s6处理后的词向量标签作为解码网络的输入。此时输入为:
x′t=[octc;xt;ct-1]
其中,t为解码的t时刻,xt为当前的s3得到的标签的词嵌入向量,ct-1为t-1时刻通过s7.1计算出的中间语义向量,octc为s6计算的预测概率。输出的隐含层的输出为h=[h1,h2,…,hl],其中l为标签的长度。
s7.3:将s7.2计算得到的输出的向量经过全连接层和softmax层,得到预测的输出。
- 还没有人留言评论。精彩留言会获得点赞!