基于模糊Borda法的国际木质林产品竞争力评价方法与流程
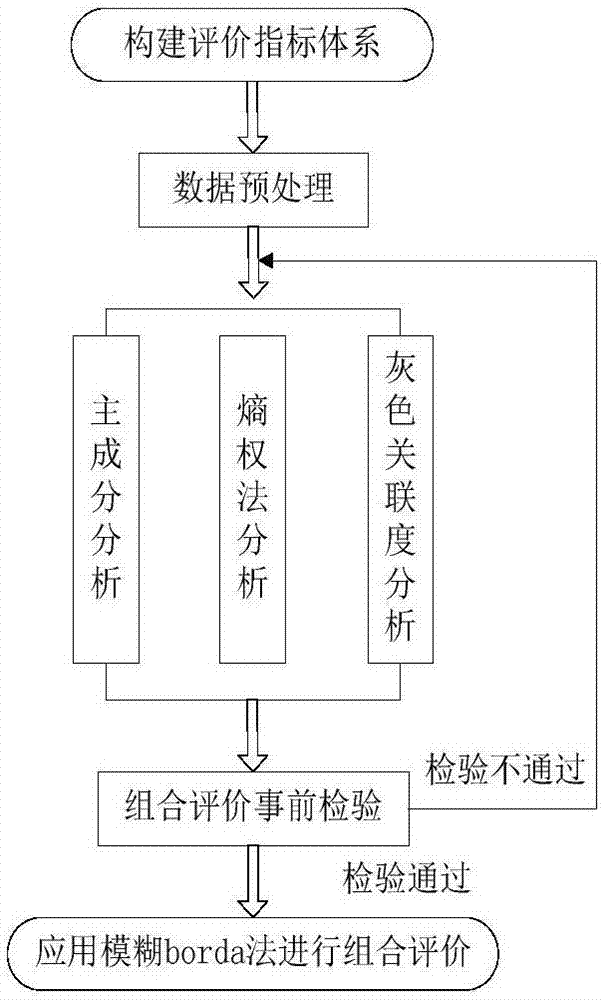
本发明属于产品指标综合评价领域,具体是涉及一种基于模糊borda法的国际木质林产品竞争力评价方法。
背景技术:
木质林产品是具有经济和生态多重效益的重要资源,自1995年wto成立以来,全球市场一体化进程不断加快,木质林产品的贸易规模也在不断扩大。据联合国粮食及农业组织(foodandagricultureorganization,简称fao)发布的最新《林产品年鉴2015》数据统计,世界范围内木质林产品贸易总额从1995年到2015年间增长了1641亿美元。经济贸易全球化的趋势促使国际贸易竞争日益加剧,因此,分析各国木质林产品国际竞争力对国际贸易长远发展具有重要意义。
目前,对木质林产品国际竞争力的研究成果不多,从研究文献使用的评价方法来看,主要为国际竞争力评价中最常用的包含关键指标和多指标综合的指标评价法。其中关键指标评价法如贸易竞争力指数、显示性优势指数、劳伦斯指数等,操作和实现程度较高,但在综合体现国际竞争力的状况方面有所欠缺;多指标综合评价方法如主成分分析法、熵权法、数据包络分析法等,能实现对国际竞争力全方位、多层次、多角度的分析,但需要构建复杂的指标体系,且鲜有考虑到不同评价方法的偏好和不一致性问题。而木质林产品国际竞争力因受供需结构、世界经济、国家间政治博弈等因素影响,呈现出动态演化的特征,因此,采用各类单一指标评价法存在评价效果不一致的缺陷。
公告号为cn105719048a的中国专利“一种基于主成分分析法及熵权法的中压配电网运行状态模糊综合评价方法”公开了一种综合评价方法,该方法利用主成分分析法对原有指标进行降维,利用熵权法对生成非主成分进行客观赋权,再应用模糊综合评价法实现配电网运行方式的综合评价,得到的评价结果更加科学合理,且具有可扩展性。所述方法包括采集数据计算指标值,利用主成分分析法根据特征值原则确定主成分含量,利用熵权法计算出各个主成分指标的客观权重,利用模糊综合评价法应用客观权重计算出不同中压配电网运行状态的模糊综合评价向量,最后根据最大隶属度原则得到评价结果。该方法虽然使用的不同的评价方法进行综合评价,但是仅使用了主成分分析法和熵权,并且没有对两种方法的一致性进行检验,不能确定这两种方法的结果是否具有一致性就将两种方法结合来进行综合评价,可能会因为两种方法的评价效果差别较大而导致最终的综合评价结果不够客观。
技术实现要素:
发明目的:为了解决多种动态评价方法评价结论的非一致性问题,提出了基于模糊borda法的国际竞争力组合评价法,兼顾各单项方法得分差异和排序中位次差异的优势,引入主成分分析、熵权法分析和灰色关联度的评价方法,对其结果进行兼容度差异度的检验和组合评价前的kendall-w协和系数一致性检验,最后运用综合模糊borda的组合评价方法将上述单项评价方法的结果进行融合,有效解决了不同分析方法得到的国际竞争力评分结果的不一致的问题。
技术方案:为实现上述目的,本发明提供一种基于模糊borda法的国际竞争力组合评价方法,包括以下步骤:(a)构建指标体系,确定研究对象和评价指标,并获取原始数据;(b)数据预处理,对原始数据进行同趋势化和无量纲化处理:(c)主成分分析,用主成分分析法得到每个研究对象综合各评价指标的主成分分析法评分及排名;(d)熵权法分析,用熵权法计算出每个研究对象综合各评价指标的熵权法评分及排名;(e)灰色关联度分析,用灰色关联度分析法计算出每个研究对象综合各评价指标的灰色关联度评分及排名;(f)综合评价前检验,用兼容度与差异度及kendall-w协调系数法对主成分分析法评分、熵权法评分和灰色关联度评分进行一致性检验,选出用于模糊borda法综合评价的评价方法;(g)用模糊borda法进行综合评价,得到各个研究对象的模糊borda综合评价值。
进一步的,步骤(b)中同趋势化采用倒数正向化法或阈值法进行同趋势化处理,采用标准化、阈值法或理想值化法进行无量纲化处理。
进一步的,在主成分分析和灰色关联度分析中,采用倒数正向化法对逆指标进行同趋势化处理,在熵权法分析中采用阈值法对逆指标进行同趋势化处理;在主成分分析中标准化法对数据进行无量纲化处理,在熵权法分析中采用阈值法进行无量纲化处理,在灰色关联度分析中采用理想值化法进行无量纲化处理。
进一步的,所述步骤(c)中,主成分分析的具体方法为:假设研究对象为n个,评价指标为p个(n>p),则可得到原始数据矩阵为:
其中,x=(x1,x2,...,xp),xi=(x1i,x2i,...,xni)t,i=1,2,...p;
对x进行线性变换,可以形成新的综合变量,用y表示,即
由于这种变换有无数种,为取得最好的效果,uij由下列原则决定:
(1)yi与yj,(i≠j,i,j=1,2,...,p)不相关,即cov(yi,yj)=0
(2)y1是x1,x2,...,xp的一切线性组合中方差最大的,即
其中,y1为第一个主成分,ci=(c1,c2,...,cp),ci是线性组合的系数;
y2是与y1不相关的x1,x2,...,xp一切线性组合中方差最大的,y3是与y1、y2不相关的x1,x2,...,xp一切线性组合中的最大方差,相似的yp是与y1,y2,...,yp-1都不相关的x1,x2,...,xp的一切线性组合中的最大方差,满足以上预设的综合变量y1,y2,...,yp就是主成分,其各变量在总方差中所占比重依次递减。
进一步的,所述步骤(d)中,熵权法分析的具体方法为:在一个包含m个研究对象和n个评价指标的评估体系中,研究对象关于评价指标的矩阵设为
其中,hj为第i个指标的熵,pij为第j个评价指标下第i个研究对象对应的状态出现的概率;pij的计算公式如下:
其中,rij代表每个研究对象在相应评价指标中经标准化处理后的数据,
假设当pij=0时,pijlnpij=0,基于熵的基础,第j个指标的熵权定义为:
其中,wj为第j个指标的熵权,hj为第i个指标的熵。
进一步的,所述步骤(e)中,灰色关联度分析的具体方法为:假设研究对象的个数为n,评价指标的个数为l,得到一个n×l的矩阵a=(x1,x2,x3,...xj...xl),xi代表第j个评价指标下各个研究对象的值组成的n×1的列向量,x0代表参考数列,求矩阵a每一列和x0的灰色关联度,其计算公式为:
式中:y(x0,xj)代表xj和x0的灰色关联度.xj∈a,j=1,2,3,...,l;|x0(k)-xj(k)|是(x0(k),xj(k))两列在第k个研究对象处的绝对差;δmin=minmin|x0(k)-xj(k)|为两级最小差,第一级最小差min|x0(k)-xj(k)|表示在x0与xj对应点的最小差,第二级最小差minmin|x0(k)-xj(k)|表示为所有第一级最小差中的最小值;△max=maxmax|x0(k)-xj(k)|的意义与△min相同;分辨系数ζ∈[0,1]用来减小极值对计算的影响,以提高分辨率,ζ可调节y(x0,xj)的大小和变化区间。
进一步的,步骤(f)中兼容度和差异度的计算方法为:用m+1表示方法数,n表示研究对象数。第i,j种评价方法{ak(i)},{ak(j)}之间的相关程度计算公式为:
其中,rij代表第i种评价方法和第j种评价方法之间的相关程度,{ak(i)},{ak(j)}分别表示第k个研究对象在第i,j种评价方法中的排名,
某种评价方法{yk}与其他m种评价方法的兼容度ry的计算公式为:
其中,ry代表评价方法{yk}与其他m种评价方法的兼容度,wj为第j个评价方法的权数,ryj为某y种方法和第j中方法的相关程度;
定义前p名为观测排名范围,即以第p名为区分点,则在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度:
其中,dk(i|j)代表在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度,ak(i/j)表示第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的排名;
则第i种方法与第j种方法的差异度为:
其中,dij代表第i种方法与第j种方法的差异度,dk(i|j)代表在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度;
相对于其他m种方法,第i种方法的差异度为:
其中,di代表第i种方法相对于其他m种方法的差异度,dij代表第i种方法与第j种方法的差异度。
进一步的,所述步骤(f)中,算出三种方法的兼容度和差异度后,选出差异度较小的方法,然后验证这几种方法评价结果的一致性程度,进行kendall-w协调系数检验,当这几种评价方法的结果具有一致性时,则可采用组合评价。
进一步的,所述步骤(g)中,基于模糊borda法的动态组合评价方法的步骤如下:
记yi(j)为第j(1≤j≤m)种评价方法对第i(1≤i≤n)个研究对象的评价得分,计算每一种评价方法对于研究对象i的得分的“隶属优度”ui(j),模糊borda法采用极差变换公式为:
其中,ui(j)代表第j种评价方法对于研究对象i的得分的“隶属优度”,yi(j)为第j(1≤j≤m)种评价方法对第i(1≤i≤n)个研究对象的评价得分;
计算第i个研究对象处于第h(1≤h≤n)位的模糊频数fih及模糊频率wih公式为:
其中,fih为第i个研究对象处于第h(1≤h≤n)位的模糊频数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,
计算研究对象的名次转换分,公式为:
其中,n为研究对象个数,h为该研究对象的排名,qh为排名为第h名的研究对象的名次转换分,
计算每个研究对象的名次转换分,可构成转换分向量q=(q1q2...qn)t,
计算第i个研究对象的模糊borda分数,最后根据模糊borda分数的大小进行排序,模糊borda分数的计算公式为:
其中,fbi为第i个研究对象的模糊borda分数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,qh为第i个研究对象的名次转换分。
有益效果:
本发明与现有技术比较,具有的优点是:
1、本发明的方法在采用主成分分析法、熵权法和灰色关联度分析法进行单项评价的基础上,运用模糊borda法对其进行组合评价,克服了采用各类单一指标评价法评价效果不一致的缺陷;
2、本发明的方法同时考虑了综合评价值和排序结果,有效解决了木质林产品国际竞争力结果的不一致问题,对客观评价主要国家木质林产品国际竞争力有重要的借鉴意义;
3、本发明的方法在进行评分之前,根据不同的评价方法的特点,用不同的数据预处理方法对原始数据进行了同趋势化和无量纲化,便于后续的计算并且确保了不同的评价指标在计算中的一致性;
4、本发明的方法在进行了主成分分析法、熵权法和灰色关联度分析法的各个单项评价后,计算了各个方法之间的兼容度和差异度,选择了差异度较小的方法来进行组合评价,从而确保组合评价的准确性;
5、本发明的方法在选出差异度较小的评价方法后,又对这些方法进行kendall-w协调系数检验,来验证这些方法评价结果的一致性程度,只有当这些方法具有一致性时才进行组合评价,进一步的确保了组合评价结果的可靠性;
6、本发明的方法在运用模糊borda法进行组合评价时,计算了各个研究对象的模糊频率,再根据模糊频率和研究对象在各个单项评价方法中的排名来计算模糊borda分数并确定最终的排名,从而能够更好的体现各个研究对象的竞争力水平。
附图说明
图1是;本发明的方法流程图;
图2是:实施例十中的模糊borda组合评价结果排名折线图。
具体实施方式
下面结合附图和实施例对本发明作更进一步的说明。
实施例一
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,包括以下步骤:(a)构建指标体系,确定研究对象和评价指标,并获取原始数据;(b)数据预处理,对原始数据进行同趋势化和无量纲化处理:(c)主成分分析,用主成分分析法得到每个研究对象综合各评价指标的主成分分析法评分及排名;(d)熵权法分析,用熵权法计算出每个研究对象综合各评价指标的熵权法评分及排名;(e)灰色关联度分析,用灰色关联度分析法计算出每个研究对象综合各评价指标的灰色关联度评分及排名;(f)综合评价前检验,用兼容度与差异度及kendall-w协调系数法对主成分分析法评分、熵权法评分和灰色关联度评分进行一致性检验,选出用于模糊borda法综合评价的评价方法;(g)用模糊borda法进行综合评价,得到各个研究对象的模糊borda综合评价值。
实施例二
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例一,在进行评价前需对原始数据进行预处理,同趋势化采用倒数正向化法或阈值法进行同趋势化处理,采用标准化、阈值法或理想值化法进行无量纲化处理。
具体为,在主成分分析和灰色关联度分析中,采用倒数正向化法对逆指标进行同趋势化处理,在熵权法分析中采用阈值法对逆指标进行同趋势化处理;在主成分分析中标准化法对数据进行无量纲化处理,在熵权法分析中采用阈值法进行无量纲化处理,在灰色关联度分析中采用理想值化法进行无量纲化处理。
实施例三
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例二,倒数正向化的计算公式为:
x′i=1/xi(13)
其中,xi代表原始数据中一个研究对象在一个评价指标中的数值;
阈值法的计算公式为:
其中,xi代表原始数据中一个研究对象在一个评价指标中的数值;
理想值化法的计算公式为:
其中,xi代表原始数据中一个研究对象在一个评价指标中的数值;
实施例四
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例三,主成分分析的具体方法为:假设研究对象为n个,评价指标为p个(n>p),则可得到原始数据矩阵为:
其中,x=(x1,x2,...,xp),xi=(x1i,x2i,...,xni)t,i=1,2,...p;
对x进行线性变换,可以形成新的综合变量,用y表示,即
由于这种变换有无数种,为取得最好的效果,uij由下列原则决定:
(1)yi与yj,(i≠j,i,j=1,2,...,p)不相关,即cov(yi,yj)=0
(2)y1是x1,x2,...,xp的一切线性组合中方差最大的,即
其中,y1为第一个主成分,ci=(c1,c2,...,cp),ci是线性组合的系数;
y2是与y1不相关的x1,x2,...,xp一切线性组合中方差最大的,y3是与y1、y2不相关的x1,x2,...,xp一切线性组合中的最大方差,相似的yp是与y1,y2,...,yp-1都不相关的x1,x2,...,xp的一切线性组合中的最大方差,满足以上预设的综合变量y1,y2,...,yp就是主成分,其各变量在总方差中所占比重依次递减。
实施例五
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例四,熵权法分析的具体方法为:在一个包含m个研究对象和n个评价指标的评估体系中,研究对象关于评价指标的矩阵设为
其中,hj为第i个指标的熵,pij为每种状态对应出现的概率,即第j个评价指标下第i个研究对象对应的状态出现的概率;pij的计算公式如下:
其中,rij代表每个研究对象在相应评价指标中经标准化处理后的数据,
假设当pij=0时,pijlnpij=0,基于熵的基础,第j个指标的熵权定义为:
其中,wj为第j个指标的熵权,hj为第i个指标的熵。
实施例六
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例五,灰色关联度分析的具体方法为:假设研究对象的个数为n,评价指标的个数为l,得到一个n×l的矩阵a=(x1,x2,x3,...xj...xl),xi代表第j个评价指标下各个研究对象的值组成的n×1的列向量,x0代表参考数列,做关联分析先要指定参考数列,参考数列常记为x0,本例中的参考数列是最优值即最大值,求矩阵a每一列和x0的灰色关联度,其计算公式为:
式中:y(x0,xj)代表xj和x0的灰色关联度.xj∈a,j=1,2,3,...,l;|x0(k)-xj(k)|是(x0(k),xj(k))两列在第k个研究对象处的绝对差;δmin=minmin|x0(k)-xj(k)|为两级最小差,第一级最小差min|x0(k)-xj(k)|表示在x0与xj对应点的最小差,第二级最小差minmin|x0(k)-xj(k)|表示为所有第一级最小差中的最小值;δmax=maxmax|x0(k)-xj(k)|的意义与δmin相同;分辨系数ζ∈[0,1]用来减小极值对计算的影响,以提高分辨率,ζ可调节y(x0,xj)的大小和变化区间。
实施例七
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例六,步骤(f)中兼容度和差异度的计算方法为:用m+1表示方法数,n表示研究对象数。第i,j种评价方法{ak(i)},{ak(j)}之间的相关程度计算公式为:
其中,rij代表第i种评价方法和第j种评价方法之间的相关程度,{ak(i)},{ak(j)}分别表示第k个研究对象在第i,j种评价方法中的排名,
某种评价方法{yk}与其他m种评价方法的兼容度ry的计算公式为:
其中,ry代表评价方法{yk}与其他m种评价方法的兼容度,wj为第j个评价方法的权数,通常在对各个评价方法没有特殊偏好时取1/m,ryj为某y种方法和第j中方法的相关程度;
定义前p名为观测排名范围,即以第p名为区分点,则在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度:
其中,dk(i|j)代表在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度,ak(i/j)表示第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的排名;
则第i种方法与第j种方法的差异度为:
其中,dij代表第i种方法与第j种方法的差异度,dk(i|j)代表在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度;
相对于其他m种方法,第i种方法的差异度为:
其中,di代表第i种方法相对于其他m种方法的差异度,dij代表第i种方法与第j种方法的差异度。
实施例八
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例七,算出三种方法的兼容度和差异度后,选出差异度较小的方法,然后验证这几种方法评价结果的一致性程度,进行kendall-w协调系数检验,当这几种评价方法的结果具有一致性时,则可采用组合评价。
实施例九
本实施例的一种基于模糊borda法的国际竞争力组合评价方法,基于实施例八,基于模糊borda法的动态组合评价方法的步骤如下:
记yi(j)为第j(1≤j≤m)种评价方法对第i(1≤i≤n)个研究对象的评价得分,计算每一种评价方法对于研究对象i的得分的“隶属优度”ui(j),模糊borda法采用极差变换公式为:
其中,ui(j)代表第j种评价方法对于研究对象i的得分的“隶属优度”,yi(j)为第j(1≤j≤m)种评价方法对第i(1≤i≤n)个研究对象的评价得分;
计算第i个研究对象处于第h(1≤h≤n)位的模糊频数fih及模糊频率wih公式为:
其中,fih为第i个研究对象处于第h(1≤h≤n)位的模糊频数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,
计算研究对象的名次转换分,公式为:
其中,n为研究对象个数,h为该研究对象的排名,qh为排名为第h名的研究对象的名次转换分,
计算每个研究对象的名次转换分,可构成转换分向量q=(q1q2...qn)t,
计算第i个研究对象的模糊borda分数,最后根据模糊borda分数的大小进行排序,模糊borda分数的计算公式为:
其中,fbi为第i个研究对象的模糊borda分数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,qh为第i个研究对象的名次转换分。
实施例十
样本选取和数据来源
本研究参考了fao分类和《海关统计年鉴》、《中国林业发展报告》、《中国林业统计年鉴》等权威渠道,将木质林产品分为原木、锯材、人造板、木浆、回收纸、其他纤维浆和纸与纸制品。文中涉及数据均来源于wdi数据库,ilo数据库,《国际经济统计年鉴》,联合国粮农组织网站和联合国统计署的comtrade数据库等整理。本研究选取占世界木质林产品贸易总额的70%以上的中国、美国、日本、瑞典、加拿大、芬兰、德国、荷兰、法国、俄罗斯等15个世界木质林产品贸易大国作为研究对象,代表性的反映了主要国家木质林产品的国际竞争力。
指标体系的构建
衡量不同国家木质林产品国际竞争力的指标选取工作是复杂而困难的,国内外研究成果有限,主要分为能反映其国际竞争力现状的状态指标和从根本上揭示其国际竞争力形成原因的因素指标。其中顾晓燕、聂影(2009)从国际市场占有率、贸易竞争指数、显示性比较优势指数等状态指标方面进行研究论述。庞新生、廖红蕾、宋维明(2016)借鉴波特钻石模型理论,从生产要素、需求条件、企业战略结构和市场竞争、相关与支持产业以及政府等方面设置指标,从因素指标方面来论述不同国家木质林产品的国际竞争力。考虑到单一木质林产品独特优劣势带来的理解偏差,笔者选取的是后一种方法,在分析不同国家木质林产品国际竞争力时,充分考虑不同国家共同指标的涵义和差异性以及指标数据的可得性,最终选取的指标为:森林面积、森林资源覆盖率、森林立木蓄积、劳动适龄人口比重、人均gdp、城市化率、工业增加值、人文发展指数、技术研发水平和出口周转天数。指标体系见表1。
表1评价指标体系
数据预处理
为了使分析的结果科学准确,使用上述方法进行综合评价之前,需要对原始数据进行同趋势化和无量纲化的预处理,见表2。
表2数据预处理
上述分析中选取的指标,只有正逆指标(不存在0值)两种,不存在适度指标,故除熵权法外,其他方法均可采用倒数正向化方法进行同趋势化处理,通过标准化实现指标无量纲化。具体公式如下:
倒数正向化x′i=1/xi
其中,xi代表原始数据中一个研究对象在一个评价指标中的数值;
阈值法
其中,xi代表原始数据中一个研究对象在一个评价指标中的数值;
(1)基于主成分分析法的综合计算
在本文选取的10个指标中,正逆指标同时存在,在对原始数据进行预处理之后,通过计算相关矩阵r可以看出各个变量之间存在相关关系。使用spss进行主成分分析,得到特征值、方差贡献率。结果如表3所示:
表3特征值和方差贡献率
经计算可以看出,前3个主成分解释了全部方差的78.2%,即包含原始数据的信息总量达到了78.2%。设3个主成分分别用f1、f2、f3来表示,第i个主成分的系数等于因子载荷矩阵的第i列元素与第i个特征根的平方根的比值,因子载荷矩阵如表4所示:
表4因子载荷矩阵
前3个主成分的主成分系数表如表5所示:
表5主成分系数表
其中,zxi表示各指标原始数据预处理后的数值。
根据各指标原始数据预处理后的数值以及主成分系数矩阵,得到各主成分的表达式计算出各主成分的得分。各主成分的表达式如下:
f1=-0.193zx1+0.097zx2-0.164zx3-0.062zx4+0.475zx5+0390zx6-0.032zx7+0.454zx8+0.403zx9+0.420zx10
f2=0.558zx1+0.262zx2+0.588zx3+0.391zx4+0.030zx5+0.321zx6+0.084zx7+0.089zx8+0.031zx9+0.031zx10
f3=0.029zx1-0.536zx2-0.036zx3+0311zx4+0.084zx5-0.150zx6+0.735zx7-0.014zx8+0.114zx9+0.175zx10
其中。zxi表示各指标原始数据预处理后的数值,f1、f2、f3分别表示三个主成分的得分。
以每个主成分的方差贡献率占累计方差贡献率的比重作为权数,便能够计算得到各木质林产品国际竞争力的综合得分及排名。综合得分的计算公式如下:
f=0.531f1+0.285f2+0.183f3.
f为该国的综合得分,f1、f2、f3分别表示三个主成分的得分。
根据以下公式:
其中,研究对象为n个,评价指标为p个,x为原始数据矩阵,x=(x1,x2,...,xp),xi=(x1i,x2i,...,xni)t,i=1,2,...p;
对x进行线性变换,可以形成新的综合变量,用y表示,即
由于这种变换有无数种,为取得最好的效果,uij由下列原则决定:
(1)yi与yj,(i≠j,i,j=1,2,...,p)不相关,即cov(yi,yj)=0
(2)y1是x1,x2,...,xp的一切线性组合(满足公式2)中方差最大的,即
其中,ci=(c1,c2,...,cp),ci是线性组合的系数。y2是与y1不相关的x1,x2,...,xp一切线性组合中方差最大的,y3是与y1、y2不相关的x1,x2,...,xp一切线性组合中的最大方差,相似的yp是与y1,y2,...,yp-1都不相关的x1,x2,...,xp的一切线性组合中的最大方差。满足以上预设的综合变量y1,y2,...,yp就是主成分,其各变量在总方差中所占比重依次递减。
最终得出各个国家的具体排名情况见表6:
表6基于主成分分析的综合得分排名
(2)基于熵权法的综合计算
对于熵权法,阀值法是一种较好的数据预处理方法。阀值法是进行无量纲化处理一种有效方式,该方法通过对正、逆指标分别采取两种相互对应的无量纲化公式,在无量纲化的同时也实现了指标的同趋势化。采用熵权法分析,根据以下公式:
预设一个有n个可能结果x的随机试验,其中每个结果出现的概率均为p=(p1,p2,..,pn),满足0≤pi≤1(i=1,2,...n)且
式中,k为系统状态数,k≥0;若某个pi=0则规定0ln0=0。
本例中在一个包含m个研究对象和n个评价指标的评估体系中,研究对象关于评价指标的矩阵设为
其中,hj为第i个指标的熵,pij为每种状态对应出现的概率,即第j个评价指标下第i个研究对象对应的状态出现的概率;pij的计算公式如下:
假设当pij=0时,pijlnpij=0。基于熵的基础,第j个指标的熵权定义为:
其中,wj为第j个指标的熵权,hj为第i个指标的熵。
熵在信息论中为不确定性的量度,指标的信息熵和该指标提供的信息量成反比。指标的信息熵越小,该指标包含的信息量越大,权重越高,在综合评价中所起的作用也应当越大,熵权法正是依据此原理得到每个评价指标的权值。
最终得到木质林产品国际竞争力的综合得分和排名,见表7。
表7基于熵权法分析的综合得分排名
(3)基于灰色关联度的综合计算
使用基于灰色系统理论的方法进行综合评价时,同样需要对原始数据进行同趋势化处理和无量纲化处理。同趋势化处理的方法与前面一样,用倒数化方法转化逆指标为正指标,然后选定各指标的最大值为理想值,构建参考序列,并依据灰色关联系数计算公式,得到各国不同指标对应的灰色关联系数。
根据灰色关联系数可计算灰色绝对关联度或灰色加权关联度,计算灰色加权关联度需要事先给定各指标的权重,其分析的结果除了受到方法本身的影响外,还会受到赋权方法的影响。为了便于比较方法本身对评价结果的影响,此处选用灰色绝对关联度分析法来进行比较分析,根据以下公式:
式中:xj∈a,j=1,2,3,...,l;a=(x1,x2,x3,...xj...xl),xi代表第j个评价指标下各个研究对象的值组成的n×1的列向量,x0代表参考数列,做关联分析先要指定参考数列,参考数列常记为x0,本例中的参考数列是最优值即最大值;|x0(k)-xj(k)|是(x0(k),xj(k))两列在第k个研究对象处的绝对差;△min=minmin|x0(k)-xj(k)|为两级最小差,第一级最小差min|x0(k)-xj(k)|表示在x0与xj对应点的最小差,第二级最小差minmin|x0(k)-xj(k)|表示为所有第一级最小差中的最小值;△max=maxmax|x0(k)-xj(k)|的意义与△min相同;分辨ζ∈[0,1]系数用来减小极值对计算的影响,以提高分辨率,ζ可调节关联y(x0,xj)的大小和变化区间。
最终得到各国家的评价结果见表8。
表8基于灰色关联度分析的综合得分排名
兼容度与差异度及kendall-w协调系数法的一致性检验
通常情况下,可以采用兼容度和差异度来实现方法的优选。用m+1表示方法数,n表示研究对象数。第i,j种评价方法{ak(i)},{ak(j)}之间的相关程度计算公式为:
其中,{ak(i)},{ak(j)}分别表示第k个研究对象在第i,j种评价方法中的排名。
某种评价方法{yk}与其他m种评价方法的兼容度ry的计算公式为:
其中,ry代表评价方法{yk}与其他m种评价方法的兼容度,wj为第j个评价方法的权数,通常在对各个评价方法没有特殊偏好时取1/m,ryj为某y种方法和第j中方法的相关程度;
某种评价方法的差异度定义为以该方法的排名为基准时,位于某一排名范围内的研究对象,在其余各评价方法中,超出规定排名范围的研究对象个数的平均值。定义前p名为观测排名范围,即以第p名为区分点,则在第i中评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度:
其中,ak(i/j)表示第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的排名。则第i种方法与第j种方法的差异度为:
其中,dij代表第i种方法与第j种方法的差异度,dk(i|j)代表在第i种评价方法中居前p位的第k个研究对象在第j种评价方法中的差异度;
相对于其他m种方法,第i种方法的差异度为:
其中,di代表第i种方法相对于其他m种方法的差异度,dij代表第i种方法与第j种方法的差异度。
上述方法的评价效果可采用兼容度和差异度来比较,考虑到各国经济发展状况和资源禀赋,应考虑能够较好地区分中等以下水平之外的国家来建立规则,计算差异度区分点选为10较为适中。根据公式(15-19)推算出上述三种方法的兼容度和差异度见表所示。在兼容度上,熵权法和绝对关联度法的评价效果较优,主成分法的评价效果较次。在差异度上,主成分法的差异度远远大于另外两种方法,对不同研究对象的区分度较次。比较结果可验证,熵权法和绝对关联度分析法的效果较好,在评价结果上优于主成分分析法,见表9。
表9上述三种方法的兼容度和差异度
为验证这两种方法评价结果的一致性程度,可用spss软件进行kendall-w协调系数检验,结果见表10。
表10两种方法的kendall协调系数检验
协调系数w=0.805,p=0.000≤0.05,拒绝原假设,认为这两种方法的评价结果是一致的。当上述两种评价方法的结果具有一致性时,则可采用组合评价。
基于模糊borda方法的评价
根据公式
计算三种评价方法中两种评价对各国木质林产品国际竞争力的得分隶属优度,其中,ui(j)代表第j种评价方法对于研究对象i的得分的“隶属优度”,yi(j)为第j(1≤j≤m)种评价方法对第i(1≤i≤n)个研究对象的评价得分;
结果见表11所示:
表11隶属优度
根据以下公式:
其中,fih为第i个研究对象处于第h(1≤h≤n)位的模糊频数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,
计算各国的模糊频数和模糊频率,结果如表12所示:
表12模糊频率
计算研究对象的名次转换分,公式为:
其中,n为研究对象个数,h为该研究对象的排名,qh为排名为第h名的研究对象的名次转换分,
可构成转换分向量q=(q1q2...qn)t,实际上向量是一个确定的序列.
计算第i研究对象的模糊borda分数,最后根据borda分数的大小进行排序。borda分数的公式为:
其中,fbi为第i个研究对象的模糊borda分数,wih为第i个研究对象处于第h(1≤h≤n)位的模糊频率,qh为第i个研究对象的名次转换分。
最终得到各国的模糊borda综合评价值及排序如表13所示。
表13模糊borda综合评价值及排序
为了直观显示各国木质林产品国际竞争力的现状排名,将模糊borda组合评价的得分结果用下图表示。从图2的评价结果来看,模糊borda组合评价的结果融合了两种方法的结果排名,与熵权法分析和灰色关联度分析的结果大体相一致,并未出现较大的反差。结果显示,由于天然的资源优势状况和国家发展程度的差异,无论采用哪种方法,美国、俄罗斯和巴西均在排名前五名以内,代表其木质林产品国际竞争力较强,美国几乎稳定在第一名;印度、印度尼西亚、波兰和荷兰则稳定在后五名之间,在所选取国家中竞争力较弱,印度保持稳定在最后一名;其他国家在国际竞争力中游左右浮动,而我国木质林产品的国际竞争排名大致在中上游。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!