一种基于深度学习的车牌定位和识别方法与流程
本发明涉及车牌识别
技术领域:
,具体为一种基于深度学习的车牌定位和识别方法。
背景技术:
:车牌识别系统(vehiclelicenseplaterecognition,vlpr)是指能够检测到受监控路面的车辆并自动提取车辆牌照信息(含汉字字符、英文字母、阿拉伯数字及号牌颜色)进行处理的技术。车牌识别是现代智能交通系统中的重要组成部分之一,应用十分广泛。它以数字图像处理、模式识别、计算机视觉等技术为基础,对摄像机所拍摄的车辆图像或者视频序列进行分析,得到每一辆汽车唯一的车牌号码,从而完成识别过程。通过一些后续处理手段可以实现停车场收费管理,交通流量控制指标测量,车辆定位,汽车防盗,高速公路超速自动化监管、闯红灯电子警察、公路收费站等等功能。对于维护交通安全和城市治安,防止交通堵塞,实现交通自动化管理有着现实的意义。汽车牌照号码是车辆的唯一“身份”标识,牌照自动识别技术可以在汽车不作任何改动的情况下实现汽车“身份”的自动登记及验证,这项技术已经应用于公路收费、停车管理、称重系统、交通诱导、交通执法、公路稽查、车辆调度、车辆检测等各种场合。现有的基于车牌字符分割的车牌识别方法,绝大多数实验是在理想的环境下进行的。一旦遇到诸如车牌模糊,受光照影响大,车牌倾斜等情况,车牌识别的准确率将会大大地降低。除此之外,车牌字符无法正确分割也将直接影响了车牌字符识别的效果。技术实现要素:本发明的目的在于提供一种基于深度学习的车牌定位和识别方法,以解决上述
背景技术:
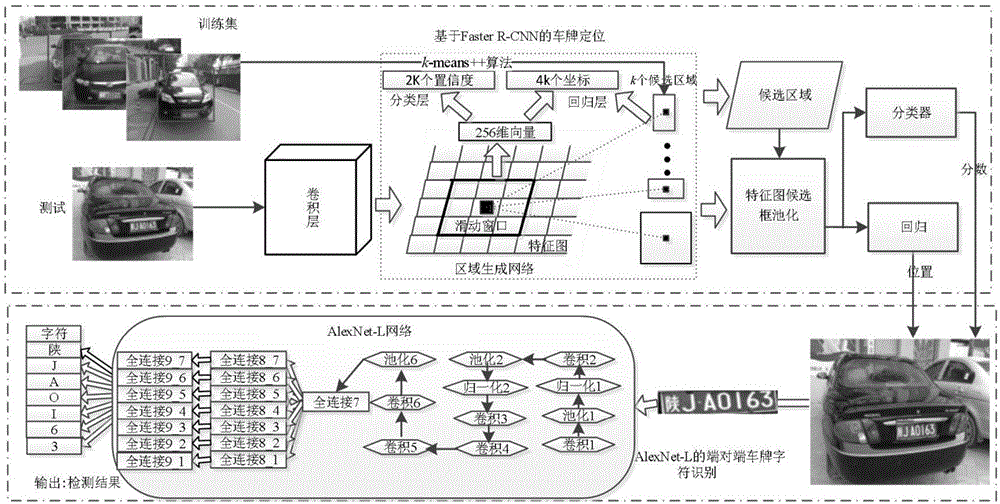
中提出的问题,本发明利用k-means++算法来选择最佳车牌区域尺寸,结合fasterr-cnn来进行车牌定位,且对alexnet网络模型进行了改进,设计出基于alexnet-l的端与端的车牌字符识别方法。为实现上述目的,本发明提供如下技术方案:一种基于深度学习的车牌定位和识别方法,包括两个方面:基于fasterr-cnn模型的车牌定位和基于alexnet-l网络模型的端对端的车牌字符识别;步骤1,对训练集的车牌区域尺寸应用k-means++算法处理,选择最佳的候选尺寸,结合到fasterr-cnn;步骤2,利用fasterr-cnn训练图片,得到模型;步骤3,输入一张包含车牌的图片,经过卷积处理之后,得到特征图;步骤4,将所得的特征图经过全卷积神经网络rpn处理后,得到候选框,将获取的特征图和候选框一起经过roipooling处理后进行分类,输出车牌位置和分数;步骤5,将车牌区域从原图中截取下来;步骤6,截取的车牌区域通过alexnet-l网络模型的端对端的卷积神经网络,最终输出车牌上的各个字符。进一步的,由于中国的车牌区域比例为440cm*140cm,近似为3∶1,为了确切地反映各种图片中车牌区域的大小,采用k-means++算法来选定3个比例的长宽比;k-means++算法需要采用模型预测的候选框和标记的候选框的交叠率(iou)为指标,iou的计算方式为:其中,sgroundtruth表示真实的候选框,sanchorbox表示预测的候选框;k-means++算法得到初始候选框的算法包括以下步骤:s1:k-means++算法的输入为车牌的长度和宽度c={d1(x1,y1),d2(x2,y2),…,dn(xn,yn)},以及k个候选框的长宽比;s2:从c中随机选取一个样本为c1(c1∈c);s3:对于c中每一个样本,计算每个样本到c1的距离:d(bi,c1)=1-iou(bi,c1)(2)其中i∈(1,2,3,…,n);s4:计算每个样本选为下一个质心的概率:s5:定义si:s6:生成一个0到1之间的随机数r,判断r属于区域{si-1,si},则bi(xi,yi)是第二个质心:s7:重复步骤s3~s6,直到得到k个质心。进一步的,所述fasterr-cnn模型中的rpn网络,其本质上是在卷积神经网络cnn的基础上增加了全卷基层cls和reg层,其中cls层是用来判断候选框是前景还是背景,而reg层是用来微调候选框;fasterr-cnn的损失函数为:其中,i表示anchor的一个索引,pi是第i个anchor的预测概率,anchor若为正,的值为1,反之,的值为0,ti表示预测边界框的4个参数坐标,表示与正anchor对应的groud-truthbox的坐标向量,分类损失lcls是2个类别(目标与非目标)的对数损失。进一步的,所述alexnet-l网络模型是在alexnet网络模型基础上的一个改进,alexnet-l网络模型有九层结构,第一、二层均包含了卷积,池化层和归一化;与alexnet网络模型不同的是,alexnet-l网络模型的第一层中池化层和归一化操作的顺序不一样;alexnet-l网络模型的第三层到第五层用了三个相同的卷积操作;第六层使用了卷积层和池化层,第七层是一个全连接层,第八和第九层采用并列的七个全连接层,分别用来对车牌的各个字符进行识别。进一步的,所述alexnet-l网络模型在alexnet网络模型基础上进行如下几个方面的改进:①第一层和第二层的改进:将alexnet中第一层和第二层中归一化和池化层相互调换顺序,即将alexnet中归一化1,池化层1以及归一化2,池化层2调换顺序;②增加卷积层来提高分类效果:在alexnet的卷积层3,卷积层4的后面增加一个同样的卷积层;③全连接层的改进:车牌的端对端的字符识别为7个字符,将alexnet的第七层全连接层更改为7个并列的全连接层,分别获取7个字符的特征向量;④输出层的改进:由于中国的车牌字符有7个字符,最终的输出应该是7个标签,将alexnet网络的第八个全连接层更改为并列的7个全连接层,并与前一层7个并列的全连接层分别相连,对于最后一个全连接层,每个类别对应的标签数并不唯一。进一步的,所述alexnet-l网络模型的输出层采用softmax回归函数分类,soffmax公式为:g代表分类数,d是g的训练函数;alexnet-l网络模型中卷积操作的计算过程为:o=(i+2×p-k)/s+1(7)其中,o为输出数据的大小(图片的长度或宽度),i为输入数据的大小(图片的长度或宽度),p为pad,表示是否需要在宽度和高度两边填充像素,k为kernel_size,表示卷积和的大小,s为stride,表示步长;池化层的操作计算过程为:o=(i-k)/s+1(8)其中,各参数的含义跟公式(7)中一样;alexnet-l网络中,与每个卷积层相连的激活函数选择用relu:relu(x)=max(x,0)(9)与现有技术相比,本发明的有益效果是:本发明采用基于fasterr-cnn的方法进行车牌定位,利用k-means++算法来选取最佳车牌区域,结合fasterr-cnn进行车牌定位,来提高车牌定位的准确率,采用基于alexnet改进的alexnet-l的端对端的车牌字符识别方法,一方面可以减少现有的基于车牌字符分割的车牌识别方法中的车牌字符分割结果对车牌字符识别影响;另一方面,还可以提高车牌识别的准确率。附图说明图1为本发明基于深度学习的车牌定位和识别框架图;图2为本发明fasterr-cnn模型图;图3为本发明k-means++算法结合车牌获取anchors过程图;图4为本发明9个anchors尺寸图;图5为本发明alexnet网络模型结构图;图6为本发明基于alexnet-l的车牌字符识别框架图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明技术方案,并不限于本发明。本发明提供一种技术方案:一种基于深度学习的车牌定位和识别方法,包括两个方面:基于fasterr-cnn模型的车牌定位和基于alexnet-l网络模型的端对端的车牌字符识别,整体算法框架如图1所示;步骤1,对训练集的车牌区域尺寸应用k-means++算法处理,选择最佳的候选尺寸,结合到fasterr-cnn;步骤2,利用fasterr-cnn训练图片,得到模型;步骤3,输入一张包含车牌的图片,经过卷积处理之后,得到特征图;步骤4,将所得的特征图经过全卷积神经网络rpn处理后,得到候选框,将获取的特征图和候选框一起经过roipooling处理后进行分类,输出车牌位置和分数;步骤5,将车牌区域从原图中截取下来;步骤6,截取的车牌区域通过alexnet-l网络模型的端对端的卷积神经网络,最终输出车牌上的各个字符。现有的fasterr-cnn模型并没有涉及到车牌的相关应用,为此首先从数据集中标定车牌区域,然后将fasterr-cnn应用于获取到的车牌区域数据集之中,最终得到每张车牌图片的候选区域。进一步的,本发明分析了车牌区域的大小,为了提高训练时收敛速度和车牌定位的准确率,将车牌区域大小结合到fasterr-cnn中,由于中国的车牌区域比例为440cm*140cm,近似为3∶1,为了确切地反映各种图片中车牌区域的大小,采用k-means++算法来选定3个比例的长宽比;k-means++算法需要采用模型预测的候选框和标记的候选框的交叠率(iou)为指标,iou的计算方式为:其中,sgroundtruth表示真实的候选框,sanchorbox表示预测的候选框;k-means++算法结合车牌的处理的过程如图3所示。k-means++算法得到初始候选框的算法包括以下步骤:s1:k-means++算法的输入为车牌的长度和宽度c={d1(x1,y1),d2(x2,y2),…,dn(xn,yn)},以及k个候选框的长宽比;s2:从c中随机选取一个样本为c1(c1∈c);s3:对于c中每一个样本,计算每个样本到c1的距离:d(bi,c1)=1-iou(bi,c1)(2)其中i∈(1,2,3,…,n);s4:计算每个样本选为下一个质心的概率:s5:定义si:s6:生成一个0到1之间的随机数r,判断r属于区域{si-1,si},则bi(xi,yi)是第二个质心:s7:重复步骤s3~s6,直到得到k个质心。通过实验,选定k为3,利用k-means++算法选取车牌区域的大小,得到三个不同的长宽比(2.2,3.2,4.6),取整后的长宽比为(2,3,5),设置基准的anchor大小为8*8,采用的尺度为[16,24,40],每个滑动窗口产生的9个anchors,如图4所示。fasterr-cnn的优势不仅在于把候选框提取部分放到gpu上运行,还把区域候选框的提取部分从网络外嵌入到网络里面,经过卷积后的特征图可以用来获取区域候选框。进一步的,所述fasterr-cnn模型中的rpn网络,其本质上是在卷积神经网络cnn的基础上增加了全卷基层cls和reg层,其中cls层是用来判断候选框是前景还是背景,而reg层是用来微调候选框;fasterr-cnn模型如图2所示。fasterr-cnn的损失函数为:其中,i表示anchor的一个索引,pi是第i个anchor的预测概率,anchor若为正,的值为1,反之,的值为0,ti表示预测边界框的4个参数坐标,表示与正anchor对应的groud-truthbox的坐标向量,分类损失lcls是2个类别(目标与非目标)的对数损失。alexnet是krizhevsky等人提出的基于分类的卷积神经网络模型,并获得了2012年imagenet比赛的冠军。alexnet结构如图5所示。alexnet有八层结构,第1,2层均使用了卷积层(conv),池化层(pool)和归一化操作(norm);第3,4层一样,均包含了卷积层;第5层采用卷积层和池化层;第6-8层应用了全连接层(fc)。虽然alexnet网络在目标分类上效果显著,然而它并不应用于车牌字符识别之中,并没有带有特定含义的模型设计;本发明在alexnet网络模型的基础上进行改进和重新构建,提出了一种增强的专门用于车牌字符识别的卷积神经网络模型alexnet-l。进一步的,所述alexnet-l网络模型是在alexnet网络模型基础上的一个改进,有利于提高车牌字符的识别的准确性;alexnet-l网络模型有九层结构,第一、二层均包含了卷积,池化层和归一化;与alexnet网络模型不同的是,alexnet-l网络模型的第一层中池化层和归一化操作的顺序不一样;alexnet-l网络模型的第三层到第五层用了三个相同的卷积操作;第六层使用了卷积层和池化层,第七层是一个全连接层,第八和第九层采用并列的七个全连接层,分别用来对车牌的各个字符进行识别,其总体框架如图6所示。进一步的,所述alexnet-l网络模型在alexnet网络模型基础上进行如下几个方面的改进:①第一层和第二层的改进:将alexnet中第一层和第二层中归一化和池化层相互调换顺序,可以提高识别精度,同时也使得归一化操作减少了计算时间和内存,因此将alexnet中归一化1,池化层1以及归一化2,池化层2调换顺序;②增加卷积层来提高分类效果:为了提高最后车牌字符识别的分类效果,在alexnet的卷积层3,卷积层4上增加一层相同的卷积层;由于卷积层3,卷积层4在分类方面好于其它层,在卷积层3,卷积层4的后面增加一个同样的卷积层,从而找到更多车牌特征的表达;③全连接层的改进:车牌的端对端的字符识别为7个字符,将alexnet的第七层全连接层更改为7个并列的全连接层,分别获取7个字符的特征向量;因为车牌字符中的汉字,字母和数字特征完全不一样,这样处理相当于将各个字符的特征分开处理,有利于提高车牌字符识别的准确率;④输出层的改进:由于中国的车牌字符有7个字符,最终的输出应该是7个标签,将alexnet网络的第八个全连接层更改为并列的7个全连接层,并与前一层7个并列的全连接层分别相连,对于最后一个全连接层,每个类别对应的标签数并不唯一。为了验证alexnet-l网络模型中每个改进对车牌字符识别的有效性,针对alexnet-l的每一次改进均做了相应的控制变量法分析,分别做以下几组实验:第一组实验:将alexnet改进中的④作为一组实验;第二组实验:将alexnet改进中的第①④结合在一起作为一组实验;第三组实验:将alexnet改进中的第②④结合在一起作为一组实验;第四组实验:将alexnet改进中的第③④结合在一起作为一组实验;第五组实验:将①②③④结合在一起作为一组实验,本组实验也即为alexnet-l网络。实验结果如表1所示,汉字代表车牌的第1个字符,字母代表车牌的第2个字符,字母+数字代表车牌剩余的字符,准确率=正确个数/测试个数。表1针对alexnet网络改进的几组对比实验从表1中可以看出,第二组至第四组实验中对于alexnet网络的改进,对车牌字符识别的结果均好于第一组实验结果,说明对alexnet网络模型的改进均对车牌字符识别的准确率有所提高;第五组实验结果的准确率明显好于其它四组实验,说明alexnet-l网络模型对alexnet的改进有利于提高车牌字符识别的准确率。本发明车牌识别主要基于中国车牌(内陆和台湾),alexnet-l最后两层均采用7个并列的全连接层,分别对应内陆车牌的第1-7个字符,而不是将车牌的第1-7个字符采用同一个全连接层,这样可以提高单个类别字符的识别准确率。本发明还在公共数据集roadpatrol(rp)上做了对比实验。因为rp数据集收集的是中国台湾的车牌,中国台湾车牌共有6个字符,其中车牌的前4个字符均为数字,最后两个字符为字母,所以alexnet-l网络的最后两层均改为并列的6个全连接层。进一步的,所述alexnet-l网络模型的输出层采用softmax回归函数分类,soffmax函数可以解决多分类的问题,而经典的sigmoid回归函数只能解决二分类的问题,soffmax公式为:g代表分类数,d是g的训练函数;alexnet-l网络模型中卷积操作的计算过程为:o=(i+2×p-k)/s+1(7)其中,o为输出数据的大小(图片的长度或宽度),i为输入数据的大小(图片的长度或宽度),p为pad,表示是否需要在宽度和高度两边填充像素,k为kemel_size,表示卷积和的大小,s为stride,表示步长;池化层的操作计算过程为:o=(i-k)/s+1(8)其中,各参数的含义跟公式(7)中一样;alexnet-l网络中,与每个卷积层相连的激活函数选择用relu,由于sigmoid和tanh激活函数在梯度下降过程中存在速度慢,迭代次数多的问题,采用relu函数作为激活函数可以提高速度和效率,并使得周期大大缩短,relu函数为:relu(x)=max(x,0)(9)对于alexnet-l网络的输入数据大小为227×227×3,经过第1层卷积核个数:96,尺寸:11,步长:4,卷积后的特征图的大小为55×55×96,经过relu激活操作后,数据大小不变,再经过卷积核大小:3,步长:2,获取的特征图的大小为27×27×96,经过归一化处理,特征图的大小不变,所以最终的输入数据大小为27×27×96。alexnet-l的第2层与第1层类似,256个5×5的卷积核的输入为27×27×96个特征图,进一步提取特征,因为第2层卷积在宽度和高度两边都填充了2个像素,所以卷积后的特征图的大小为27×27×256,经过relu激活操作后,数据大小不变,再经过卷集核尺寸:3,步长:2,获取的特征图的大小为13×13×256,经过归一化处理,特征图的大小不变,所以最终的输入数据大小为13×13×256。第3-5层一样,经过卷积和relu激活操作,第六层在经过卷积核和relu激活操作后,加入了池化层,经过第3-6,输出的数据大小为6×6×256,再经过第7-8层的并列的7个全连接层,最后输出层每个标签从前往后的卷积核个数依次为31,26,36,36,36,36,36。本发明实验中,测试的数据集是自收集的数据集和公共数据集rp,自收集的数据集都是中国内陆车牌。为了验证fasterr-cnn结合vgg网络的有效性,本发明针对fasterr-cnn结合vgg和zf网络分别做车牌定位的对比实验。在fasterr-cnn训练过程当中,迭代次数设置为200000。在前160000迭中,学习率参数设置为0.001,40000次迭代中,学习率为0.0001,momentum参数设置为0.9,权重衰减参数设置为0.0005。在测试集为2440张图片进行实验,所得的结果如表2所示。其中,召回率含义为算法判定为车牌而且判定正确的车牌个数占测试集总图片数的比率,准确率含义为算法判定为车牌而且判定正确的车牌个数占算法判定为车牌个数的比率,时间是平均测试一张图片中车牌字符所花的时间。表2基于fasterr-cnn的车牌定位对比实验算法召回率准确率时间(/s)vgg0.99090.98870.0321zf0.97620.97780.0143从表2中可以看出,虽然fasterr-cnn结合vgg网络测试每秒所花的时间比fasterr-cnn结合zf网络所花的时间长,但是fasterr-cnn结合vgg网络在车牌定位方面的准确率远高于fasterr-cnn结合zf网络,所以本发明采用基于fasterr-cnn结合vgg网络的车牌定位方法。表3是不同算法在自收集的数据集和rp数据集上车牌定位准确率的对比实验。表3不同数据集上车牌定位准确率对比(%)从表3中可以看出,本发明算法在不同数据集上的车牌定位准确率均高于其他算法。综上,在各种自然场景与不同数据集上进行车牌定,本发明算法在车牌定位效果和准确率上均明显优于其他几种算法,整体性能优越。在alexnet-l网络模型实验中,网络参数设置如下,最大迭代次数为200000,初始学习率为0.001。然后每当迭代20000次的时候,学习率更改为上一次学习率的0.1倍,momentum参数设置为0.9,权重衰减参数设置为0.0005。除此之外,本发明还对比了车牌字符分割结合ann神经网络训练车牌字符的实验,车牌字符分割加模板匹配的车牌字符识别算法,车牌字符分割加svm的车牌字符识别算法。这几种算法分别在自收集的测试集和rp数据集进行了测试,实验结果如表4和表5所示。表4中,汉字代表车牌的第1个字符,字母代表车牌的第2个字符,字母+数字代表车牌剩余的字符。准确率=正确个数/测试个数,总字符指的是车牌包含的所有字符均被正确识别的结果。时间表示平均单个车牌测试的平均时间。表5中,总字符代表rp数据集中6个字符均识别正确的结果。表4自收集数据集上的准确率对比(%)算法汉字字母字母+数字总字符时间(s)本发明0.95290.97380.96920.95080.0192人工神经网络0.89180.92700.93200.87620.0378字符模板匹配0.91430.94470.93690.90940.0296svm0.95000.96640.95530.94600.0643表5rp数据集上的准确率比较(%)算法总字符时间(s)本发明0.97740.0136人工神经网络0.95160.0289字符模板匹配0.95830.0187svm0.96510.0421从表4和表5中可以看出,本发明算法的车牌总体识别准确率以及车牌的单个字符识别准确率均高于其他对比算法。除此之外,本发明算法的平均车牌字符识别所需测试时间均少于其他对比算法。表明本发明所提出的端对端的alexnet-l的车牌字符识别算法在其相关的应用中具有优越性。以上所述仅表达了本发明的优选实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形、改进及替代,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1