一种基于机器阅读到序列模型的迁移学习方法与流程
本发明属于自然语言处理技术领域,尤其是涉及一种基于机器阅读到序列模型的迁移学习方法。
背景技术:
机器阅读是自然语言处理中最为热门和棘手的问题之一,它要求模型理解自然语言并能够运用现存的知识。目前最热门的任务一般会给定一篇文章和一个问题,我们需要根据问题从文章中寻找答案。随着近年来几个高质量数据集的发布,以神经网络为基础的模型在机器阅读上的表现越来越好,甚至在一些数据集上超过了人类。一个高效的机器阅读模型可以在以语义理解为基础的众多领域得到广泛应用,如对话机器人,问答系统和搜索引擎等。
附带注意力机制的序列模型主要由一个编码器和一个解码器组成,在编码器将输入的序列编码后由解码器依次输出并生成序列。这样的结构在自然语言生成任务如机器翻译,文本摘要和对话系统中取得了巨大的成功。然而,在训练这样的编码器-解码器时,我们只是通过将输出的结果对比固定的参考样本来进行优化,很难深入理解文本中蕴含的潜在语义信息。
迁移学习,指将多种领域的知识或特征结合来建立新的模型和概率分布。在自然语言处理领域,迁移学习得到了广泛的应用。比如2011年发表在国际顶级机器学习理论期刊journalofmachinelearningresearch上的《naturallanguageprocessing(almost)fromscratch》公布了一种统一的神经网络结构并能够将无监督学习运用到众多自然语言处理任务如词性标注,实体命名识别中;2017年发表在国际顶级计算神经理论会议annualconferenceonneuralinformationprocessingsystems上的《learnedintranslation:contextualizedwordvectors》公布了一种将机器翻译的编码器预训练后迁移到文本分类任务和问答系统中,作为一种新的词向量来提升原有词向量的丰富度;2018年发表在国际顶级自然语言处理会议proceedingsofthe56thannualmeetingoftheassociationforcomputationallinguistics上的《discoursemarkeraugmentednetworkwithreinforcementlearningfornaturallanguageinference》公布了一种基于连词的训练方法,首先在连词预测任务中训练一个编码器,然后将这个编码器嵌入一个自然语言推理模型中来提高模型的逻辑能力。
然而,现有的自然语言处理迁移学习方法很少有将多层神经网络转移到其他任务上,仅仅将编码层迁移会损失大量原有预训练模型的信息。
技术实现要素:
本发明提供了一种基于机器阅读到序列模型的迁移学习方法,能够更加深入地挖掘文本蕴含信息,提升生成文本序列的质量。
本发明采用的技术方案如下:
一种基于机器阅读到序列模型的迁移学习方法,包括以下步骤:
(1)预训练一个机器阅读模型,所述机器阅读模型包含基于循环神经网络的编码层和模型层;
(2)建立一个序列模型,所述序列模型包含基于循环神经网络的编码器、解码器和注意力机制;
(3)提取训练好的机器阅读模型中编码层和模型层的参数,迁移到待训练的序列模型中,作为训练序列模型的部分初始化参数;
(4)训练序列模型,直到模型收敛;
(5)使用训练好的序列模型进行文本序列预测任务。
本发明首先预训练一个包含编码层和模型层的机器阅读模型作为迁移来源,然后将其编码层和模型层嵌入到序列模型中与已有的编码结果融合,最终输出标签的概率分布。该方法能够帮助序列模型更加深入地理解文本蕴意并生成更加自然的文本。
步骤(1)中,所述的编码层中的循环神经网络为双向长短时记忆网络,所述的模型层中的循环神经网络为单向长短时记忆网络。
步骤(1)中,预训练机器模型的具体步骤为:
(1-1)选择训练数据,使用词向量glove对输入文本做词嵌入,之后送入编码层的双向长短时记忆网络中;
(1-2)将每个隐藏单元并排连接在一起组成该方向整个句子的表达,并将两个方向的句子表达合并作为输入序列的最终表达;
(1-3)将文章序列的最终表达和问题序列的最终表达结合送入到模型的注意力机制中,输出注意力矩阵;
(1-4)将注意力矩阵输入到模型层的单向长短时记忆网络中,使用该网络的隐藏单元进行规则化,输出预测的概率分布;
(1-5)重复上述步骤,直到机器阅读模型收敛。
步骤(2)中,序列模型主要由一个编码器和一个解码器组成,为了与迁移来源的参数保持统一,同样采用长短时记忆网络作为序列模型的主要参数组成部分,所述的编码器中的循环神经网络为双向长短时记忆网络。
步骤(3)中,提取的编码层和模型层参数为编码层和模型层中的循环神经网络。将编码层的网络和模型层的网络分别提取出来,迁移到待训练的序列模型中,作为训练序列模型的部分初始化参数。
步骤(4)的具体步骤为:
(4-1)将输入的词序列同时送入序列模型的编码器和迁移来的机器阅读模型的编码层中,得到编码后的合并向量;
(4-2)将合并向量送入一个单向长短时记忆进行整合,得到对输入文本序列整合后的编码向量;
(4-3)将整合后的编码向量作为解码器的初始化向量,并将解码器的隐藏单元和整合向量的单元进行注意力交互,得到注意力向量at,其中t是解码的第t个单词;
(4-4)将注意力向量at输入到迁移来的机器阅读模型层中,然后将模型层的输出向量rt与注意力向量at用线性函数整合并送入softmax函数中得到预测序列的概率分布;所述的softmax函数的公式为:
p(yt|y<t,x)=softmax(wpat+wqrt+bp)
其中,wp、wq和bp都是待训练的参数,yt是解码器输出的第t个单词。
(4-5)重复上述步骤,直到模型收敛。
本发明具有以下有益效果:
1、本发明使用迁移学习将其他问答系统中所学的知识转移到了文本生成任务当中,提升了编码器-解码器结构的准确率,整个模型简洁直观。
2、本发明充分利用了现有机器阅读模型的高性能,迁移的参数含有多层神经网络,将训练好的机器阅读模型参数替代序列模型参数随机初始化,能够帮助序列模型更加深入地挖掘文本蕴含的信息,使得内容更有深度,提升生成文本序列的质量。
附图说明
图1为本发明一种基于机器阅读到序列模型的迁移学习方法的流程示意图;
图2为本发明中机器阅读模型和序列模型的整体结构示意图。
具体实施方式
为了使本发明的目的、技术方案和有益技术效果更加清晰明白,以下结合附图进一步详细描述本发明的技术内容和具体实施方式。应当理解的是,本说明书中描述的具体实施方式仅仅是为了解释本发明,并不是为了限定本发明。
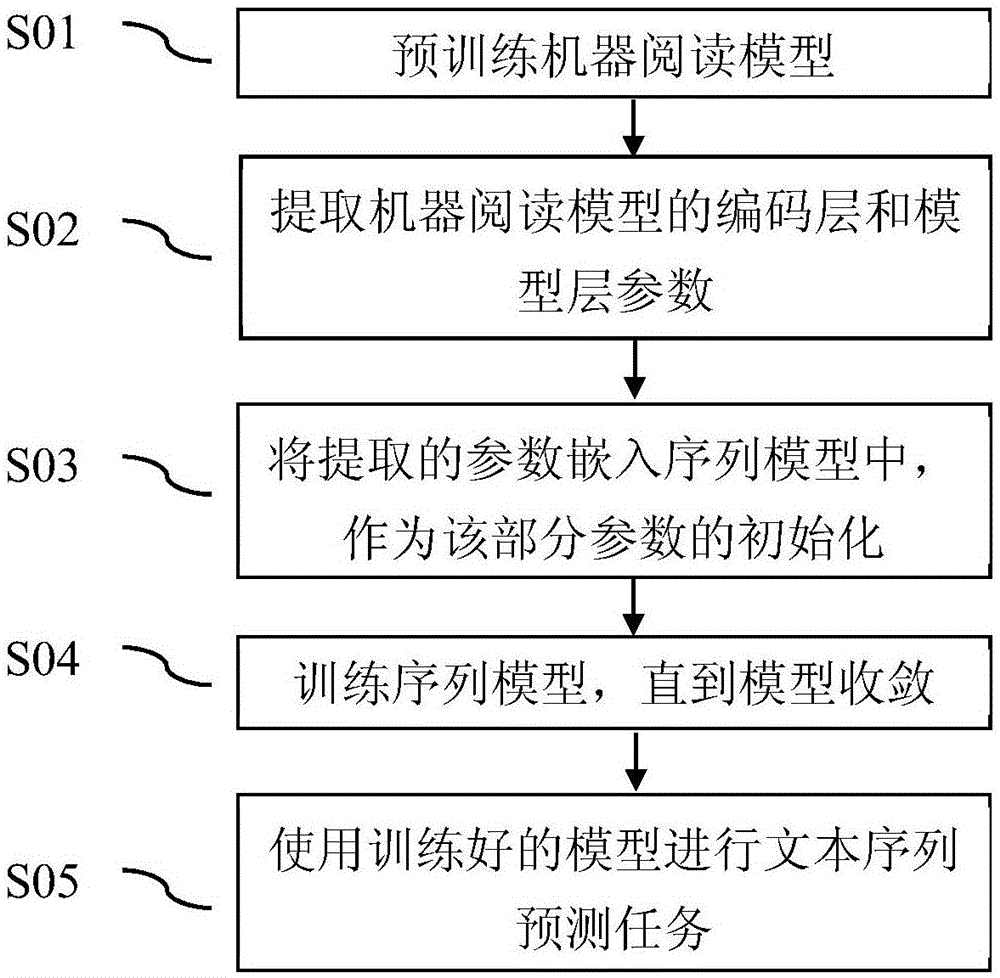
如图1所示,一种基于机器阅读到序列模型的迁移学习方法,包括以下步骤:
s01,预训练一个机器阅读模型。
我们使用斯坦福问答数据集squad这个大规模高质量语料库作为训练集,我们的任务是给定一篇文章和一个问题来预测答案,该答案是文章中的一个连续字段。
机器阅读模型的结构参见图2,我们用现有的词向量glove来对输入文本做词嵌入,之后送入编码层(encodinglayer)的双向长短时记忆网络(bilstm)中。我们把每个隐藏单元都并排连在一起组成该方向整个句子的表达,并将两个方向的句子表达合并在一起作为输入序列的最终表达。随后,我们将文章序列的表达和问题序列的表达结合送入到注意力机制(attentionmechanism)中。注意力机制是一系列正则化线性运算和逻辑运算组成的函数,具体可参照2017年发表在国际顶级学习表征会议internationalconferenceonlearningrepresentations上的《bi-directionalattentionflowformachinecomprehension》中第3页到第4页的内容。我们的注意力机制的输出为一个文章单词数量的注意力向量组成的矩阵。最终,我们将注意力矩阵输入到一个模型层(modelinglayer)的单向长短时记忆网络(lstm)中,并使用该网络的隐藏单元进行规则化并使用softmax函数来输出预测的概率分布。
s02,提取机器阅读模型的编码层和模型层参数。在步骤s01中,我们提到了长短时记忆网络,这个是循环神经网络的一种,也是我们将要提取的参数。我们将编码层的网络和模型层的网络分别提取出来,准备作为下一个任务的初始化参数。
s03,将步骤s02中提取的参数嵌入序列模型中,作为该部分参数的初始化。
序列模型的结构参见图2,序列模型主要由一个编码器(encoder)和一个解码器(decoder)组成,为了与迁移来源的参数保持统一,我们同样采用长短时记忆网络作为序列模型的主要参数组成部分。我们首先将输入的词序列同时送入到序列模型的编码器和迁移来的机器阅读模型的编码器中,得到编码后的合并向量;然后将合并向量送入一个单向长短时记忆网络进行整合,得到两种不同来源的编码器对输入文本序列整合后的编码向量。我们将整合后的编码向量作为解码器的初始化向量,并将解码器的隐藏单元和整合向量的单元进行注意力交互,得到注意力向量at,其中t是解码的第t个单词。对于一般的序列模型来说,注意力向量最终会被送到一个softmax函数中进行规则化并生成预测的概率分布:
p(yt|y<t,x)=softmax(wpat+bp)
其中wp和bp都是待训练的参数,yt是解码器输出的第t个单词。然而,在本发明的方法中,我们先将注意力向量输入到迁移来的机器阅读模型层中,然后将模型层的输出向量rt与原来的注意力向量用线性函数整合并送入softmax函数中得到预测序列的概率分布:
p(yt|y<t,x)=softmax(wpat+wqrt+bp)
其中,wq是待训练的参数。
s04,以训练好的迁移参数为初始化,其他参数为随机初始化开始训练序列模型模型,直到收敛。
s05,使用训练好的模型进行文本序列预测任务,如机器翻译,文本摘要等。
为了证明本发明方法的有效性,在神经机器翻译和生成式文本摘要这两个任务上进行了对比实验。在机器翻译任务上,我们采用了wmt2014和wmt2015英语到德语的语料库;在进行文本摘要任务上,我们采用了cnn/dailymail和gigaword这两个数据集。其中cnn/dailymail经预处理后含有287k个训练数据对,gigaword经预处理后含有3.8m个训练数据对。
机器翻译任务的对比实验结果如表1所示。表1中,第一栏为基础模型,中间栏为本方法的各个细节的逐个加入,最后一栏为本方法。可以看出,在机器翻译任务上,本发明的方法(macnet)对比基础模型(baseline)有明显提升,并在各个细节上都进行了对比试验证明其有效性。
表1
文本摘要任务的对比实验结果如表2所示。本实验在文本摘要测试集上与当前效果最好的已发表方法进行了比较。总体来说本发明的方法(pointer-generator+macnet)相比于其他方法具有更高的准确率,并且在两个数据集上的大部分指标上都达到了目前的最好效果。
表2
除此之外,我们还具体展示了几个例子证明在加入本发明方法前后对生成文本摘要的直观影响,如表3所示。
表3
上表中,pg是基础模型pointergenerator的简称,reference是数据集中给的参考答案,pg+macnet为加入本发明方法的模型。可以看出,在原文中出现不常见的单词时,原有的基础模型难以总结出较好的主谓宾语;而在原文较长且结构复杂时,原有的基础模型甚至出现了语病。然而加上了本发明的方法后,最终生成的文本摘要语句通顺自然,所表达的主体大意也基本到位。
本说明书实施例所述的内容仅仅是对发明的解释说明,并不是对本发明进行限制,本发明的保护范围不应当被视为仅限于实施例所述的具体内容,在本发明的精神和原则之内所作的任何修改、替换和改变等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!