一种SparkSQL应用程序的自动化测试方法和装置与流程
本发明涉及信息技术领域。
背景技术:
spark作为hadoop生态系统中的分布式计算框架之一,以其计算速度快、功能丰富的特点,成为了大数据应用程序开发的主流框架。其中sparksql作为spark的结构化数据处理模块,更是应用广泛。sparksql应用程序的主要特点是通过sql的执行,实现海量数据分析处理的功能,极大的简化了大数据业务处理程序的编码难度。
传统针对sparksql应用程序的测试方法主要是黑盒测试。测试人员只能根据需求文档和从程序员口中了解到的功能实现情况说明,构造测试数据,在大数据集群环境中执行待测程序,对程序执行结果进行判断。这种方式存在以下问题:
(1)测试难度大。一般在实现大数据业务处理功能的sparksql应用程序中,涉及的sql、表的数量都是巨大且复杂的,这就导致测试数据的构造难度比较大,预期结果也很难准确的给出了;
(2)测试效率低。在迭代测试当中,由于在每轮测试当中都需要构造大量复杂的测试数据并进行结果校验,每轮的测试周期都会很长;
(3)测试覆盖率低。因为对程序内部的业务逻辑和业务sql不了解,构造的测试数据很难覆盖所有测试点。
针对现有技术的不足,本发明基于sql语句回放,实现sparksql应用程序的自动化测试,解决了传统黑盒测试方法测试难度大、效率低、覆盖率低的问题。
共有技术:
mock方法是单元测试中常见的一种技术,它的主要作用是模拟一些在应用中不容易构造或者比较复杂的对象,从而把测试与测试边界以外的对象隔离开。mock对象有助于从测试中消除依赖项,使测试更单元化。
jmockit是一款java类/接口/对象的mock工具,目前广泛应用于java应用程序的单元测试中。
maven是一个项目管理和综合工具。maven提供了开发人员构建一个完整的生命周期框架。开发团队可以自动完成项目的基础工具建设,maven使用标准的目录结构和默认构建生命周期。
hadoop是一个由apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
hdfs
hadoop分布式文件系统(hdfs)被设计成适合运行在通用硬件(commodityhardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。hdfs是一个高度容错性的系统,适合部署在廉价的机器上。hdfs能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。hdfs放宽了一部分posix约束,来实现流式读取文件系统数据的目的。hdfs在最开始是作为apachenutch搜索引擎项目的基础架构而开发的。hdfs是apachehadoopcore项目的一部分;
hdfs有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。hdfs放宽了(relax)posix的要求(requirements)这样可以实现流的形式访问(streamingaccess)文件系统中的数据。
spark
apachespark是专为大规模数据处理而设计的快速通用的计算引擎。spark是ucberkeleyamplab(加州大学伯克利分校的amp实验室)所开源的类hadoopmapreduce的通用并行框架,spark,拥有hadoopmapreduce所具有的优点;但不同于mapreduce的是--job中间输出结果可以保存在内存中,从而不再需要读写hdfs,因此spark能更好地适用于数据挖掘与机器学习等需要迭代的mapreduce的算法;
spark是一种与hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使spark在某些工作负载方面表现得更加优越,换句话说,spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载;
spark是在scala语言中实现的,它将scala用作其应用程序框架。与hadoop不同,spark和scala能够紧密集成,其中的scala可以像操作本地集合对象一样轻松地操作分布式数据集;
尽管创建spark是为了支持分布式数据集上的迭代作业,但是实际上它是对hadoop的补充,可以在hadoop文件系统中并行运行。通过名为mesos的第三方集群框架可以支持此行为。spark由加州大学伯克利分校amp实验室(algorithms,machines,andpeoplelab)开发,可用来构建大型的、低延迟的数据分析应用程序。
hive
hive是建立在hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(etl),这是一种可以存储、查询和分析存储在hadoop中的大规模数据的机制。hive定义了简单的类sql查询语言,称为hql,它允许熟悉sql的用户查询数据。同时,这个语言也允许熟悉mapreduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作;
hive没有专门的数据格式。hive可以很好的工作在thrift之上,控制分隔符,也允许用户指定数据格式。
技术实现要素:
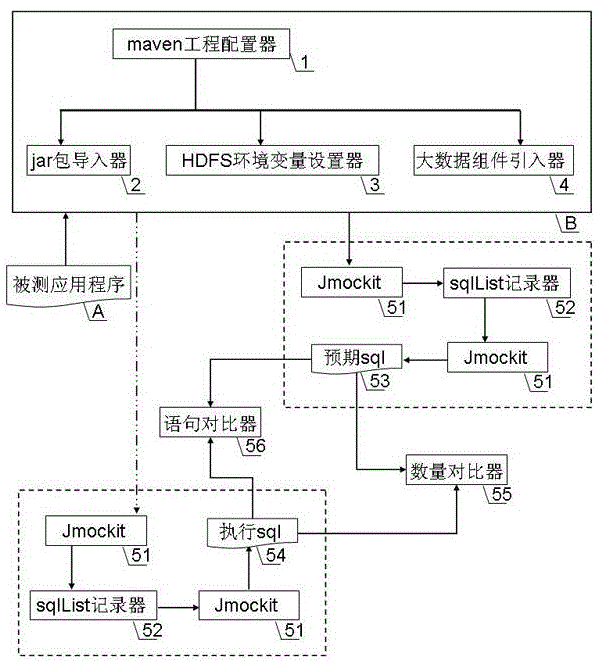
实现本发明的一种sparksql应用程序的自动化测试装置的必要组成模块包括:测试环境、jmockit、sqllist记录器、数量对比器、语句对比器;测试环境由maven工程配置器、jar包导入器、hdfs环境变量设置器、大数据组件引入器组成;
实现一种sparksql应用程序的自动化测试装置的主要步骤包括:
1)部署测试环境
①由maven工程配置器读取被测应用程序,并判断被测应用程序所需的测试环境的配置类型;
②当被测应用程序存在jar包时,通过jar包导入器完成测试环境配置,jar包导入器通过pom.xml的依赖包引入;
③当被测应用程序运行于hdfs分布式文件系统时,通过hdfs环境变量设置器完成测试环境配置,hdfs环境变量设置器自动从hadoop官网下载与被测应用程序版本一致的hadoop包,并根据本机的操作系统类型设置hadoop.home.dir属性;
④当被测应用程序运行于spark和hive的大数据环境时,通过大数据组件引入器完成测试环境配置,大数据组件引入器通过添加pom.xml依赖包来完成测试环境配置;
2)对sparksession.sql(stringsqltext)模拟
①使用单元测试当中的mock工具jmockit,对sparksqlapi中执行sql语句的方法sparksession.sql(stringsqltext)进行模拟,使sparksql在被测应用程序内部调用sparksession.sql(stringsqltext)执行sql的同时,返回执行的具体sql语句;
②使用sqllist记录器接收并保存被测应用程序执行的sql语句,sqllist记录器使用sqllist变量接收被测应用程序执行的sql语句;
3)sql语句录制
sql语句录制是指获取被测应用程序的saprksql应用程序运行过程中顺序执行的sql,生成预期sql;
①变量模拟
对sqllist记录器中的sql语句相关的变量,采用jmockit工具进行模拟,使变量的取值固定,保证在不同时间和不同应用场景下,被测应用程序的sparksql应用程序执行是同样的sql语句;
②运行被测应用程序,在sparksession.sql(stringsqltext)模拟和变量模拟的前提下,获取程序运行中顺序执行的sql语句,将顺序执行的sql语句保存到文件生成预期sql;
4)sql语句回放
①获取执行sql
运行被测应用程序,在sparksession.sql(stringsqltext)模拟和变量模拟的前提下,获取程序运行中顺序执行的sql语句,将顺序执行的sql语句保存到文件生成执行sql;
②sql数量对比
数量对比器读取预期sql和执行sql,对比预期sql的数量和执行sql的数量,当预期sql的数量和执行sql的数量不一致,测试结果为不通过,结束sql对比;当预期sql的数量和执行sql的数量一致,进行sql语句对比;
③sql语句对比
语句对比器读取预期sql和执行sql,去除语句中的标点符号、空格、回车、换行及非语义的内容,将预期sql和执行sql转换成预期sql字符串和执行sql字符串,对比预期sql字符串和执行sql字符串,当预期sql字符串和执行sql字符串不同时,测试结果为不通过;当预期sql字符串和执行sql字符串相同时,测试结果为通过。
有益效果
(1)降低了测试难度
不需要构造复杂的测试数据,根据sparksql应用程序的特点,将对比预期结果数据,转换为对比预期sql语句,降低了测试难度和测试效率。
(2)提高了测试效率
虽然第一轮测试中的sql语句录制阶段需要进行代码走读并获取预期sql语句,但第二轮开始的迭代测试可以通过sql语句回放来自动验证程序的正确性,极大的提高了测试效率。
(3)提高了测试覆盖率
第一轮的代码走读和sql查看可以覆盖整个业务逻辑,后期迭代测试根据sql语句回放,可以准确找到程序业务逻辑更改的地方,保证回归测试的覆盖率。
附图说明
图1是本发明的组织结构流程图。
具体实施方式
参看图1实现本发明的一种sparksql应用程序的自动化测试装置,其组成模块包括:测试环境b、jmockit51、sqllist记录器52、数量对比器55、语句对比器56;测试环境b由maven工程配置器1、jar包导入器2、hdfs环境变量设置器3、大数据组件引入器4组成;
实现一种sparksql应用程序的自动化测试装置的主要步骤包括:
1)部署测试环境
①由maven工程配置器1读取被测应用程序a,并判断被测应用程序a所需的测试环境b的配置类型;
②当被测应用程序b存在jar包时,通过jar包导入器1完成测试环境配置,jar包导入器1通过pom.xml的依赖包引入;
例如:
<dependency>
<groupid>com.act</groupid>
<artifactid>test</artifactid>
<version>1.0.0</version>
<scope>system</scope>
<systempath>d:\\test.jar</systempath>
</dependency>
③当被测应用程序a运行于hdfs分布式文件系统时,通过hdfs环境变量设置器3完成测试环境配置,hdfs环境变量设置器3自动从hadoop官网下载与被测应用程序版本一致的hadoop包,并根据本机的操作系统类型设置hadoop.home.dir属性;
例如:
system.setproperty("hadoop.home.dir","d:\\javaprojects\\hadoop");
system.setproperty("os.name","windows7");
④当被测应用程序a运行于spark和hive的大数据环境时,通过大数据组件引入器4完成测试环境配置,大数据组件引入器4通过添加pom.xml依赖包来完成测试环境配置;
例如:
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-core_2.11</artifactid>
<version>2.1.0</version>
</dependency>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-sql_2.11</artifactid>
<version>2.1.0</version>
</dependency>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-hive_2.11</artifactid>
<version>2.1.0</version>
</dependency>
2)对sparksession.sql(stringsqltext)模拟
①使用单元测试当中的mock工具jmockit51,对sparksqlapi中执行sql语句的方法sparksession.sql(stringsqltext)进行模拟,使sparksql在被测应用程序内部调用sparksession.sql(stringsqltext)执行sql的同时,返回执行的具体sql语句;
②使用sqllist记录器52接收并保存被测应用程序a执行的sql语句,sqllist记录器52使用sqllist变量接收被测应用程序执行的sql语句;
sqllist变量如下
publicstaticvoidsparksessionmockup(finallist<sqlbean>sqllist){
newmockup<sparksession>(sparksession.class){
@mock
publicdataset<row>sql(invocationinvocation,stringsqltext){
sqllist.add(newsqlbean(sqltext));
system.out.println(sqltext+";");
returninvocation.proceed(sqltext);
};
};
}
3)sql语句录制
sql语句录制是指获取被测应用程序a的saprksql应用程序运行过程中顺序执行的sql,生成预期sql53;
①变量模拟
对sqllist记录器52中的sql语句相关的变量,采用jmockit工具进行模拟,使变量的取值固定,保证在不同时间和不同应用场景下,被测应用程序a的sparksql应用程序执行是同样的sql语句;
例如,假设在被测应用程序a的sparksql应用程序中有一个要执行的sql是查询hive分区表中当前分区的所有数据,则分区是一个变量,在实际的运行当中,每天分区的取值都不同,这样不利于我们录制sql;因此我们可以对分区变量进行模拟,使应用程序在任何时间执行该sql语句,分区的取值都是同一个;
②运行被测应用程序a,在sparksession.sql(stringsqltext)模拟和变量模拟的前提下,获取程序运行中顺序执行的sql语句,将顺序执行的sql语句保存到文件生成预期sql53;
4)sql语句回放
①获取执行sql
运行被测应用程序a,在sparksession.sql(stringsqltext)模拟和变量模拟的前提下,获取程序运行中顺序执行的sql语句,将顺序执行的sql语句保存到文件生成执行sql54;
②sql数量对比
数量对比器55读取预期sql53和执行sql54,对比预期sql53的数量和执行sql54的数量,当预期sql53的数量和执行sql54的数量不一致,测试结果为不通过,结束sql对比;当预期sql53的数量和执行sql54的数量一致,进行sql语句对比;
③sql语句对比
语句对比器56读取预期sql53和执行sql54,去除语句中的标点符号、空格、回车、换行及非语义的内容,将预期sql53和执行sql54转换成预期sql字符串和执行sql字符串,对比预期sql字符串和执行sql字符串,当预期sql字符串和执行sql字符串不同时,测试结果为不通过;当预期sql字符串和执行sql字符串相同时,测试结果为通过。
示例测试类代码:
publicclassmergetasktest{
@test(dataprovider="dp")
publicvoidtest(class<问号>cls,list<sqlbean>expectsql){
//创建用于接收执行sql的变量
list<sqlbean>sqllist=newarraylist<sqlbean>();
//调用步骤2中模拟sql方法的公共方法
methodmockup.sparksessionmockup(sqllist);
//调用(1)中模拟变量的公共方法
methodmockup.variablemockup();
//调用被测程序中某个任务
methodmain=cls.getdeclaredmethod("main",string[].class);
main.invoke(null,newstring[]{null});
//sql回放,断言对比执行sql跟预期sql是否相同
assertmethod.sqllistassert(sqllist,expectsql);
}
//添加测试用例
@dataprovider(name="dp")
publicobject[][]dp(){
stringexpectsqlpath=this.getclass().getresource("/expectsql").getpath();
returnnewobject[][]{
newobject[]{housemerge.class,genarateexpectdata.createexpectsql(expectsqlpath+"/housemerge.sql")},
newobject[]{gatewaymerge.class,genarateexpectdata.createexpectsql(expectsqlpath+"/gatewaymerge.sql")},
};
}
}
- 还没有人留言评论。精彩留言会获得点赞!