主机白名单机制下一种快速实现文件鉴别的方法与流程
本发明属于计算机安全技术领域,尤其涉及主机白名单机制下一种快速实现文件鉴别的方法。
背景技术:
目前,主机应用白名单技术是一种主机应用层安全防御常见技术,其区别于黑名单技术,用以对特定用途的计算机实现更加精准和相对固化的安全防御效果。既有的主机应用白名单技术,常见采用的文件检测和识别技术是通过hash算法和数字签名机制,对待加载目标文件进行校验。全文hash方法:文件加载前,将文件全文读入内存,计算hash,然后在已有的hash库中查询,根据查询结果和白名单策略,决定是否拒绝加载文件签名机制:作为纯hash方法的补充,采用dsa签名算法,对待加载文件进行计算,并根据厂商签名,验证是否存在于白名单库中,进而决定加载动作。由于签名算法为非对称算法,签名易于验证但难以伪造,相对于hash算法,签名机制能够防护hash库/表被篡改的情形。但是,在白名单实际应用过程中,这两种方案都面临一个问题。随着系统架构由32位升级64位,操作系统的升级和补丁增加,文件过多、过大、文件频繁地被加载都会由于文件的实时检测导致效率降低,进程加载速度和运行速度都会变慢,严重影响用户体验。
由于windows可执行文件有时候会非常大,典型见于一些音频/视频软件、游戏软件、图形图像专业处理软件。针对这类文件,windows在加载可执行文件的时候会根据文件的大小建立磁盘pe文件与内存虚拟地址之间的映射关系,而不是一次性读取完整的可执行文件。在进程启动时,windows会锁定可执行文件以保证进程退出前,再次读取文件时,文件不会发生变化导致错误,并读取pe文件头,将pe文件映射在内存空间中,实际却并不一定一次性完整读取整个pe文件。即使读取完整,由于每个进程有虚拟的2g用户态空间,有几十个进程或服务在同时运行,而实际上系统内存并没有这么多,所以操作系统的内存管理需要采用内存分页机制,将暂时不用的内存分片交换出去,需要执行的分片再从缓存或者硬盘上加载回来。也就是说,在进程执行期间,可能需要多次去读取硬盘,读取可执行文件的一部分。经观测,不同的环境中这个读取频率差异较大,有时这个频率很高,经常有每秒钟读取几十次甚至几百次的现象,个别情况下可超过每秒一千次。而针对文件建立的白名单库,其中只包含完整文件的hash和签名。对目标文件的校验过程是将目标文件视为一个普通文件,完整读取并计算一遍hash,这个过程由白名单软件独立完成,有别于windows的pe文件加载过程。如果在主机白名单中采用全文hash,在pe文件很大的时候,windows频繁读取pe文件的某一分片,就会导致校验程序频繁全文读取一遍可执行文件,这会明显拖慢进程启动和运行速度。校验程序还需要对这些大文件执行hash计算,消耗了大量的cpu。
一、现有技术方案之一:
目前的白名单机制,每当需要读取可执行文件分片时,都会引起白名单校验需要,在设备内存不足的情况下,会频繁发生读写磁盘io的操作。白名单校验加载机制需要完整校验整个可执行文件。也就会造成重新读取整个文件并计算的动作。其结果是数倍地放大了磁盘读写操作。严重拖慢了系统速度。
现有技术方案一的缺点是:
1.消耗了大量cpu在重复的计算上,加载时间过长,用户体验差。
2.部分情况下会造成多任务抢占,系统死锁,反应严重变慢,用户体验更差。
二、现有的技术方案之二是,只在第一次加载文件的时候,完整读取文件并进行校验。现有技术二的缺点是:不会在计算机读取文件和计算hash上浪费太多资源。但是这样的实现方式,安全性得不到保证。恶意软件能够设法在白名单校验过后,替换可执行文件的文件体,导致白名单校验的失效;
三、现有的技术方案之三是,校验文件发布厂商的数字签名。
现有技术三的缺点是:
1.不是所有可执行文件都有厂商的数字签名,这是现有技术三的最大问题,只有一些大的软件厂商对自己发布的文件进行了签名。有些厂商只对特定时间后发布的新版本文件采用了数字签名技术,而对之前发布的合法文件无法追溯。据统计,即使把微软自带的文件计算在内,一台计算机上的有签名的文件通常也不超过20%。
2.由于厂商签名不能随意修改,部分白名单厂商采用重新签名的方式代替hash算法
3.厂商签名的方法与hash算法具有同样的弱点,由于是对文件全文作签名,这个技术实现也会严重拖慢系统反应速度。
本发明的缩略语和关键术语定义如下:
技术实现要素:
本发明的目的在于提供能够克服上述技术问题的主机白名单机制下一种快速实现文件鉴别的方法,本发明所述方法包括以下步骤:
步骤1、分片算法一:按照固定大小依次分片并依次计算hash值并记录在数据库:
步骤1.1、预备阶段,根据操作系统版本和位数、文件系统确定分片大小,默认为4096字节;
步骤1.2、建立和学习白名单阶段:读取目标pe文件,按照4096字节为单位,将完整文件分割成为若干个段;
步骤1.3、对每一个段计算其hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤1.4、对尾部不足4096字节的数据,采用预设字符填充至4096字节,计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤1.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤1.6、重复以上步骤,直至学习白名单阶段结束,固化白名单;
步骤1.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤1.8、获取windows欲读取的偏移量和长度,同步获取所加载的文件buffer,扩展读取到分片长度单位4096字节;
步骤1.9、在hash列表中查找完全覆盖所述buffer的hash块,读取hash值;
步骤1.10、逐片计算分片的hash值,并与数据库中已存储的值作比较;
步骤1.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤2、分片算法二,按照固定大小分片,将相邻的若干分片组合并计算hash值,记录在数据库,允许分组有重叠以实现多重校验并减少hash数据总条数:
步骤2.1、预备阶段,根据操作系统版本和位数、文件系统,确定分片大小,默认为4096字节;
步骤2.2、建立和学习白名单阶段:读取目标pe文件,按照4096字节为单位,将完整文件分割成为若干个段;
步骤2.3、对前面若干个分片,独立计算其hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤2.4.1、对中部部分分片,将相邻分片联合计算hash值,将文件名,序号,偏移位置,数据长度,hash值存储入结构化数据库
步骤2.4.2、将相邻4个分片或8个分片联合计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库,相邻分片的选取算法根据pe文件结构决定,互相有重叠以减少计算量、加快速度和减少存储;根据步骤8中的记录对算法进行优化和更新;
步骤2.4.3、对尾部不足4096字节的数据采用预设字符填充至4096字节,计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤2.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤2.6、重复上述过程,直至学习白名单阶段结束,固化白名单;
步骤2.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤2.8、获取windows欲读取的偏移量和长度,同步获取所加载的文件buffer,扩展读取到分片长度单位4096字节,记录buffer位移和长度;
步骤2.9、在hash列表中查找完全覆盖所述buffer的hash块,读取hash值;
步骤2.10、逐片计算分片的hash值,并与数据库中已存储的值作比较;
步骤2.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤3、分片算法三:按照pe的section进行分片并将section的属性字段与section数据体部分联合起来,作为基本白名单校验单元,计算hash值并记录和校验:
步骤3.1、建立和学习白名单阶段:读取目标pe文件,根据pe文件头,分析pe文件的段结构,按段结构将完整文件分割成为若干个分片;
步骤3.2、正常pe文件有4个section,例如.text、.data、.rdata,针对文件分段名分段有异常的情况,例如section过少、命名奇特的情况,可能是病毒或加壳的文件,从白名单中移除,由用户最终判定;
步骤3.3、对所有分片,独立计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤3.4、对完整文件仍然计算hash值,存储入结构化数据库;
步骤3.5、重复上述步骤,直至学习白名单阶段结束,固化白名单;
步骤3.6、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤3.7、获取windows欲读取的分片位置,同步获取所加载的文件section;
步骤3.8、在hash列表中查找对应的hash值;
步骤3.9、逐片计算每个section的hash值,并与数据库中已存储的值作比较;
步骤3.10、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤4、分片算法四,按照pe的section进行分片并将section的属性字段与section数据体部分联合起来,并将相邻分片联合作为校验单元,计算hash并记录和校验:
步骤4.1、建立和学习白名单阶段:读取目标pe文件,根据pe文件头分析pe文件的段结构,按段结构将完整文件分割成为若干个分片;
步骤4.2、针对异常的文件分段名、分段情况,是否从白名单中移除,由用户最终判定;
步骤4.3、对所有分片,独立计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤4.4、对相邻分片联合计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤4.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤4.6、重复上述步骤,直至学习白名单阶段结束,固化白名单;
步骤4.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤4.8、获取windows欲读取的分片位置,同步获取所加载的文件section;
步骤4.9、在hash列表中查找对应的hash值,如果windows同时加载了多个section,则直接读取对应的联合分片的hash值;
步骤4.10、计算每个section或联合section的hash值,并与数据库中已存储的值作比较;
步骤4.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
需要说明的是,在步骤3或步骤4中,在白名单扫描和学习阶段,要解析pe结构,将所有分片独立计算hash值并记录;在启动白名单保护后将某一分片从磁盘读入内存的时候检索hash记录并计算分片的hash值并校验hash值。在步骤2中,要根据pe文件和操作系统智能动态调整分片方式以保证存储数据尽量少的情况下达到速度上的最佳优化效果。本发明所述方法是根据文件系统的分区大小和操作系统的配置情况将可执行文件进行分片并将每一分片分别预先计算hash值来作为白名单的实现基础。
本发明的有益效果是:解决了白名单软件导致的进程加载或运行速度变慢的问题,通过设计多重校验提高了白名单软件的鉴别能力,进而提高了安全性,能够为白名单判别机制提供有效的补充判别依据。本发明所述方法采用空间换时间的技术构思并通过更细粒度的预先计算的hash表和结构化存储好的hash库以减少实际运行过程中文件加载过程中产生的过度的不必要的磁盘io读写,同时减少不必要的大量重复的hash值计算,从磁盘和cpu两个角度节约运行资源,从而大大提高运行速度。解决了目前白名单软件造成的系统卡顿问题,通过预先计算构造一个设计合理、可用、能快速检索的hash库对每个可执行文件,需要存储若干个hash值;本发明所述方法的分页控制通过windows的内核编程从而实现了对可执行文件的内存分页控制并在分页交换的时快速校验分页的hash值;在可执行文件加载之前将所有分片的hash全部读入缓存以保证校验速度。
附图说明
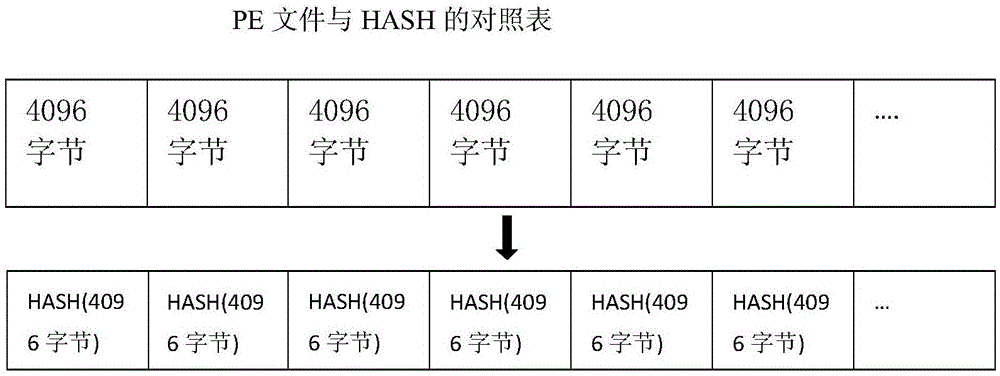
图1是本发明所述方法的基本分片算法的示意图;
图2是本发明所述方法的联合分片算法的示意图;
图3是本发明所述方法的依据pesection的分片算法的示意图;
图4是本发明所述方法的依据pesection的联合分片算法的示意图。
具体实施方式
下面结合附图对本发明的实施方式进行详细描述。本发明所述方法包括以下步骤:
步骤1、分片算法一:按照固定大小依次分片并依次计算hash值并记录在数据库,如图1所示:
步骤1.1、预备阶段,根据操作系统版本和位数、文件系统确定分片大小,默认为4096字节;
步骤1.2、建立和学习白名单阶段:读取目标pe文件,按照4096字节为单位,将完整文件分割成为若干个段;
步骤1.3、对每一个段计算其hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤1.4、对尾部不足4096字节的数据,采用预设字符填充至4096字节,计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤1.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤1.6、重复以上步骤,直至学习白名单阶段结束,固化白名单;
步骤1.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤1.8、获取windows欲读取的偏移量和长度,同步获取所加载的文件buffer,扩展读取到分片长度单位4096字节;
步骤1.9、在hash列表中查找完全覆盖所述buffer的hash块,读取hash值;
步骤1.10、逐片计算分片的hash值,并与数据库中已存储的值作比较;
步骤1.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤2、分片算法二,按照固定大小分片,将相邻的若干分片组合并计算hash值,记录在数据库,允许分组有重叠以实现多重校验并减少hash数据总条数,如图2所示:
步骤2.1、预备阶段,根据操作系统版本和位数、文件系统,确定分片大小,默认为4096字节;
步骤2.2、建立和学习白名单阶段:读取目标pe文件,按照4096字节为单位,将完整文件分割成为若干个段;
步骤2.3、对前面若干个分片,独立计算其hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤2.4.1、对中部部分分片,将相邻分片联合计算hash值,将文件名,序号,偏移位置,数据长度,hash值存储入结构化数据库
步骤2.4.2、将相邻4个分片或8个分片联合计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库,相邻分片的选取算法根据pe文件结构决定,互相有重叠以减少计算量、加快速度和减少存储;根据步骤8中的记录对算法进行优化和更新;
步骤2.4.3、对尾部不足4096字节的数据采用预设字符填充至4096字节,计算hash值,将文件名、序号、偏移位置、数据长度、hash值存储入结构化数据库;
步骤2.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤2.6、重复上述过程,直至学习白名单阶段结束,固化白名单;
步骤2.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤2.8、获取windows欲读取的偏移量和长度,同步获取所加载的文件buffer,扩展读取到分片长度单位4096字节,记录buffer位移和长度;
步骤2.9、在hash列表中查找完全覆盖所述buffer的hash块,读取hash值;
步骤2.10、逐片计算分片的hash值,并与数据库中已存储的值作比较;
步骤2.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤3、分片算法三:按照pe的section进行分片并将section的属性字段与section数据体部分联合起来,作为基本白名单校验单元,计算hash值并记录和校验,如图3所示:
步骤3.1、建立和学习白名单阶段:读取目标pe文件,根据pe文件头,分析pe文件的段结构,按段结构将完整文件分割成为若干个分片;
步骤3.2、正常pe文件有4个section,例如.text、.data、.rdata,针对文件分段名分段有异常的情况,例如section过少、命名奇特的情况,可能是病毒或加壳的文件,从白名单中移除,由用户最终判定;
步骤3.3、对所有分片,独立计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤3.4、对完整文件仍然计算hash值,存储入结构化数据库;
步骤3.5、重复上述步骤,直至学习白名单阶段结束,固化白名单;
步骤3.6、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤3.7、获取windows欲读取的分片位置,同步获取所加载的文件section;
步骤3.8、在hash列表中查找对应的hash值;
步骤3.9、逐片计算每个section的hash值,并与数据库中已存储的值作比较;
步骤3.10、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
步骤4、分片算法四,按照pe的section进行分片并将section的属性字段与section数据体部分联合起来,并将相邻分片联合作为校验单元,计算hash并记录和校验,如图4所示:
步骤4.1、建立和学习白名单阶段:读取目标pe文件,根据pe文件头分析pe文件的段结构,按段结构将完整文件分割成为若干个分片;
步骤4.2、针对异常的文件分段名、分段情况,是否从白名单中移除,由用户最终判定;
步骤4.3、对所有分片,独立计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤4.4、对相邻分片联合计算其hash值,将文件名、section名字、偏移位置、数据长度、hash值存储入结构化数据库;
步骤4.5、对完整文件仍然计算hash值,存储入结构化数据库;
步骤4.6、重复上述步骤,直至学习白名单阶段结束,固化白名单;
步骤4.7、进入白名单校验阶段,启动白名单报警模式或防护模式,通过安装文件驱动hook住操作系统每一次对pe文件的读取操作;
步骤4.8、获取windows欲读取的分片位置,同步获取所加载的文件section;
步骤4.9、在hash列表中查找对应的hash值,如果windows同时加载了多个section,则直接读取对应的联合分片的hash值;
步骤4.10、计算每个section或联合section的hash值,并与数据库中已存储的值作比较;
步骤4.11、比较结果为相同,继续进行下一步,如果比较结果不同,则触发报警或防护操作。
需要说明的是,在步骤3或步骤4中,在白名单扫描和学习阶段,要解析pe结构,将所有分片独立计算hash值并记录;在启动白名单保护后将某一分片从磁盘读入内存的时候检索hash记录并计算分片的hash值并校验hash值。在步骤2中,要根据pe文件和操作系统智能动态调整分片方式以保证存储数据尽量少的情况下达到速度上的最佳优化效果。本发明所述方法是根据文件系统的分区大小和操作系统的配置情况将可执行文件进行分片并将每一分片分别预先计算hash值来作为白名单的实现基础。
本发明所述方法经实验测算,如果采用步骤1的算法,每个分片分别计算hash值,hash算法选用传统的md5,则存储量约需所有目标可执行文件的1/256,在实际实现中,由于需要建立索引和部分不完整的分片,每1g文件需要增加8~10m的存储空间,存储浪费并不明显,但显著效果是:部分实验环境下,加载及运行速度能够提高1000倍以上,采用合并分片的方法,存储量能够控制在低的水平,例如原始数据的1/1024,加载速度也能够提高几十倍。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的范围内,能够轻易想到的变化或替换,都应涵盖在本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!