一种基于深度神经网络的高置信度的多选择学习方法与流程
本发明属于机器学习技术领域,具体涉及一种基于深度神经网络的高置信度的多选择学习方法。
背景技术:
在许多应用场景中如计算机视觉领域,语言理解和推荐系统等,人工智能的任务通常伴随着模糊性。人类通过各种类型的信息与世界交互。有时很难从数据的一面做出正确的认知。由于这种模糊性的存在,我们不能期望从一个模型中获得对于所有数据准确的预测。因此,研究人员建议生成多种合理的输出。这对于交互式智能系统,如图像分类和去噪和机器翻译等非常重要。生成多个合理的预测同时促进了解决方案的多样性。
要生成多种不同的预测,有两种类型方法。一个是训练模型并生成推理过程中的多重预测。通常,这类方法使用图模型生成结构化的输出。通过优化不同之间的差异解决方案,这些方法可以找到一组m-best配置。另一个是训练多个模型和聚合他们的预测产生最终输出。这样的方法专注于学习过程的设计。在第二种方法中,有些方法集成许多独立模型并收集它们的预测到一个候选集中。这些方法包括贝叶斯平均,boosting和bagging,经常比使用单个模型得到更好的结果,尤其是分类任务。集成学习方法通常独立训练所有嵌入式模型,因此它们的产出可能会获得较低的多样性。因此,多选择学习(mcl)建议在训练所有嵌入式模型时建立合作来克服这一缺陷,经过训练以后,每个模型成为一个特定数据子集的专家。并提出了oracle损失概念,其重点是一个为每个样本提供最准确预测的模型。
最近,(lee等人,2016)采用了将深度神经网络应用于mcl并提出随机多选择学习(smcl)训练各种深度集成模型。通过直接最小化oracle损失,smcl的性能优于许多现有基准方法。但是,smcl经常无法做出令人满意的最终决策,因为每个网络在其自己的预测中往往过于自信。因此,简单地通过平均来集成这些预测或投票将导致糟糕的最终预测。为了解决过度自信问题,(lee等人.2017)提出采用置信mcl(cmcl)算法并提出一个新的损失函数,名为confidentoracle损失。confidentoracle损失在smcl之后增加了一个oracle的损失最小化非专家模型的预测分布和均匀分之间的kullback-leibler距离。虽然cmcl提升了smcl的集成结果的准确性,它在oracle错误率指标上表现不佳。这意味着cmcl的预测的多样性不如smcl。
技术实现要素:
针对以上现有技术中的问题,本发明的目的在于提出一种预测准确率高的基于深度神经网络的高置信度的多选择学习方法。
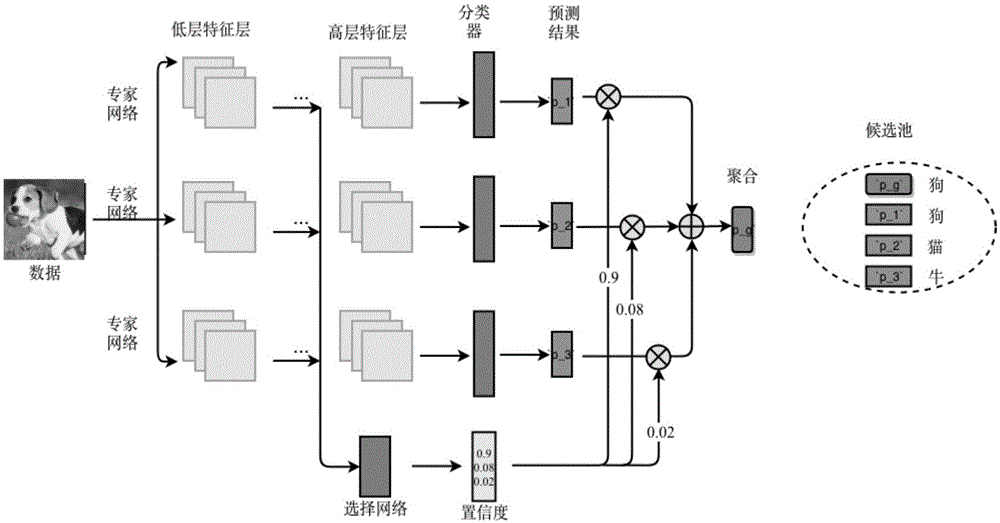
本发明提出的基于深度神经网络的高置信度的多选择学习方法,是一种新的mcl方法,称为多功能方法mcl(versatilemultiplechoicelearning,简称vmcl),该方法保存现有的mcl方法的优势,同时克服它们的缺点。具体而言,vmcl旨在维护预测结果的高度多样化,同时抑制过度自信问题。vmcl的要点:(1)提出了一个置信合页损失来解决专家网络(expertnetwork)过度自信的问题,可以防止非专家模型以高可信度进行不准确的预测。(2)采用选择网络(choicenetwork)来学习每个专家网络的可信度,使得最终可以从多样性的预测结果这聚合一个更可靠的决策预测。
本发明在同一个任务上训练多个神经网络,将每个神经网络模型训练成为整个任务的一个小任务的专家,这种学习方法称为多选择学习。多选择学习能够为同一个输入数据给出多个输出结果,这些结果具有多样性,往往有一个或多个预测是准确的。这对于机器学习中的某些问题具有很大的意义,例如对于分类问题,图像分割,图像去燥等,如果能够给出多个候选结果,能够较大提升最终的预测的准确率。为了从多个候选结果这选择一个最好的,本发明提出一个专家选择网络,用于从多个专家中选择一个预测最准确的。
本发明提出的基于深度神经网络的高置信度的多选择学习方法,以分类任务为例,具体描述如下:假设已知有n个独立同分布的数据集d,其属于c个类别;每个样本xi有一个标签yi,假设有m个专家网络,第m个网络对第i个样本给出的预测结果为
其中,l(·)为交叉熵损失函数,
所述模型的结构分为两个部分:多个专家网络(expertnetworks),选择网络(choicenetwork);其中:
(1)专家网络(expertnetwork):由多层神经网络组成(可以为全连接网络,卷积神经网络或循环神经网络),其输入是原始数据本身如图像、文本等,主要功能是在指定任务上对数据进行预测。这些任务包括但不限于图像分类,图像分割等等;
(2)选择网络(choicenetwork):由多层神经网络组成(可以为全连接网络,卷积神经网络),其输入是原始数据或各个专家网络的高层语义特征,输出为一个one-hot的向量,该向量的长度就是专家网络的数量。如果该向量的某个位置为1,其他位置为0,那么说明对于给定的样本数据,选择网络认为该位置对应的专家网络是最准确的。
具体而言,对于每个样本,它只用于优化对它预测最准确的那个模型。随着训练的迭代进行,每个网络逐渐成为某些数据子集上的专家(在这些数据上预测的准确率很高)。
本发明方法,通过在多个专家网络的高维特征层上构建一个选择网络(choicenetwork),使得对于某些只需要一个准确预测的任务,多选择学习能够从多样性较大的几个候选结果中选择一个最准确的;同时通过置信合页损失(confidenthingeloss)的帮助,能够防止每个模型对不属于它的领域内的样本给出过高的预测值。
其中,优化目标的实现依赖于损失函数的设计,本发明的损失函数总共分为三个部分:
(1)oracle损失函数,旨在最大限度地减少损失最准确的模型;
(2)选择网络的损失函数,通过学习每个专家的可信度,能够生成准确预测的损失。该选择网络抑制非专家网络给出过高的预测值(这里我们只考虑一位专家每个例子)。它看起来像混合专家模型(moe)方法(masoudniaandebrahimpour2014)。他们都提供一种决定依赖哪种模式的方法。主要区别在于本发明方法有明确的目标标签用于选择网络,而moe不提供门控神经网络的真实标签,因为它不需要知道哪个模型专家对一个具体的样本是最好的。moe只考虑聚合输出的正确性,因此不能提供多种多样化的输出;
(3)置信合页损失函数,旨在解决专家网络过度自信问题。合页损失是为聚合预测概率设置一个间距,使得预测的概率分布在正确类别上比错误类别具有更高的概率。
整个模型的算法具体步骤如下:
步骤1:设计专家网络的网络结构和选择网络的网络结构,并进行参数随机初始化。以图像分类任务为例,专家网络可以采用目前较先进的resnet、vggnet等;选择网络则是加在这些专家网络的倒数第二个卷积层上;选择网络的前两层为卷积层,后面为全连接层,最后一层为softmax层,其中输出层的维度为专家网络的个数。所有网络的参数,包括卷积层和全连接层的参数,都采用xavier初始化方法;
步骤2:从训练集中随机采样出一批样本记为s,对每个专家网络,将s作为输入进行前向传播;
步骤3:对于s中的每一个样本si,根据多个专家网络给出的预测,计算它们与真实标签的损失,然后选择预测损失最小的那个网络对应的损失累加到当前损失(如果第m个专家网络对si的损失最小,则
步骤4:计算
步骤5:重复步骤2,步骤3和步骤4,直到训练收敛。
本发明,多选择学习方法能够为同一个输入数据给出多个输出结果,这些结果具有多样性,往往有一个或多个预测是准确的。这对于机器学习中的某些问题具有很大的意义,例如对于分类问题,图像分割,图像去燥等,如果能够给出多个候选结果,能够较大提升最终的预测的准确率。为了从多个候选结果这选择一个最好的,本发明提出一个专家选择网络,用于从多个专家中选择一个预测最准确的。
本发明方法框架简单、使用方便、可扩展性强、可解释性强,并在图像分类和图像语义分割的任务上进行了实验,并达到或超过现有最好方法的水平。本发明能够为计算机视觉、数据挖掘等领域,提供基础框架和算法的支持。
附图说明
图1为多选择学习的框架图。
图2实验所用小网络的结构图。
图3为本发明vmcl与其他方法的预测的专业性对比。其中(a)为经典集成方法的结果,(b)为smcl的结果,(c)为cmcl的结果,(d)为本方面的方法的结果。每一列代表一个模型对于10个类别的分类的准确度,越稀疏且集中越好。
图4大网络结构resnet20在3个数据集上各方法的性能对比。其中(a)为在3个数据集上oracle指标的对比,(b)为在3个数据集上top1错误率的对比,(c)为考虑每个样本用来优化预测最准确的k个模型的情况下,各个方法的性能对比。
具体实施方式
下面给出本发明方法的具体实现设置,并给出本发明方法的性能测试与分析,以对本发明方法的实施过程进行更具体的描述。
本发明是一种高置信度的多选择学习方法,能够对给定任务训练多个专家网络,这些专家网络在一部分数据子集上的预测结果比单独在整个数据集上训练一个网络更加准确。针对不同的任务,需要的数据也不同,但是数据输入和训练单个模型的要求是一样的。例如做分类任务只需要样本和类别标签。
本发明方法的具体步骤如下:
步骤1:设计专家网络的网络结构和选择网络的网络结构,并进行参数随机初始化;
步骤2:从训练数据中随机采样出一部分记为s.对每个专家网络,将s作为输入进行前向传播;
步骤3:对于s中的每一个样本,根据多个专家网络给出的预测,计算它们与真实标签的损失,同时计算置信合页损失,然后选择预测损失最小的那个网络的损失与置信合页损失累加到一起进行梯度计算和反向传播。其他网络不进行;
步骤4:重复步骤2和3,直到训练收敛。
性能测试与分析
1、对于分类任务选用了3个图像数据集:cifar-10,cifar-100和svhn。对于图像分割任务选用了1个图像数据集icoseg。cifar-10是一个图像大小为32*32像素的数据集共10个类别,训练样本5万张,测试样本1万张。cifar-100与cifar-10类似,但是具有100个类别。svhn是google构建的街景门牌号数据集,共10个类别,训练集73267个样本,测试集26032个样本。icoseg数据集有38个类别,每个图片有像素级别的前后背景标签标注。
2、训练设置及超参数设置
为了测试算法的稳定性,在分类任务上,采用了小网络结构和大网络结构,小网络结构见附图2;大网络结构为resnet20;在实验过程中,对于分类任务,每个专家网络共享前面几个卷积层,使得低层的特征提取更加多样化;
在图像分割数据集上,采用了全卷积神经网络,参考fcn;
实验中所有任务的专家网络使用了5个。所有模型使用随机梯度下降进行优化,初始学习率为0.1,并线性衰减,使用nesterov动量,并设置为0.9。同时使用权重衰减为5e-4,批大小为128;所有实验均采用单张12g显存的nvidiatitanx(pascal),神经网络通过pytorch框架实现。
3、对比方法
为了比较本发明的方法性能,选择传统的独立训练的ensemble(ie),随机多选择学习(smcl)和置信多选择学习(cmcl)。
4、性能测试结果
评价指标:本实验采用top-1错误率和oracle错误率作为算法性能的评价指标。其中oracle错误率定义如下:
表1在cifar-10,cifar-100和svhn数据集上的性能对比
在小网络上四种方法的性能如上表所示,在cifar-10上,vmcl有最低的oracle错误率,比smcl低近43%。在top-1个错误率中,vmcl相对于比cmcl效果好12.95%。
在svhn数据集上vmcl仍然比smcl和cmcl有更低的top-1错误率和oracle的错误率。在oracle错误率方面,改善率高达27.05%。对于cifar-100,其类别数量相对较多,vmcl仍然可以实现更低的oracle错误率令人惊讶的是,smcl的改进率提高了约20%。
附图3中给出了四种集成方法在cifar-10的测试集上的经验分类精度结果。对于这些方法中的每个模型,不同类别的准确度分布表明它的专业度。分布越均匀,说明该模型对这些类别不太专业。我们可以看到ie缺乏多样性因为每个模型表现相似并且几乎一致分配。smcl和vmcl比cmcl模型更高的专注度,因为smcl和vmcl每个模型专注于较少的类别,并且精度很高。
由于ie缺乏多样性,它的在oracle错误率指标上比mcl的方法差。smcl中的每个网络都经过精心设计专注于某些数据子集,然而由于overconfident问题使其在top-1错误率指标上表现不佳。虽然cmcl显著改善了top-1错误速率,它无法减少oracle错误率。这是因为其confidentoracle损失影响了它的专家网络,通过最小化其在非专业数据上的预测分布和均匀分布之间的kl差异。而vmcl提出的新的损失函数,具有稀疏性特点,在oracle错误率指标上甚至比smcl更好。
附图4中给出在大网络结构如resnet20,在三个数据集上的各种方法的实验对比。可以看出本发明的方法在oracle指标和top-1指标上均比cmcl方法优异,同时在oracle指标上大部分实验结果显示本发明的方法超过smcl方法。
本发明提出了一种基于深度神经网络的高置信度的多选择学习方法。主要解决了现有方法存在的两个问题,过度置信问题和候选预测聚合问题。本发明提出了置信合页损失,使得每个非专家网络给出的置信度不再过高,同时引入选择网络用于学习每个专家网络的可信度。在图像分类和图像分割任务上的实验进行性能评估,结果显示本发明的方法无论是在聚合结果的准确率上还是预测候选集的多样性指标上均优于目前最好的方法。
- 还没有人留言评论。精彩留言会获得点赞!