一种基于稀疏线性方法的云服务个性推荐系统及方法与流程
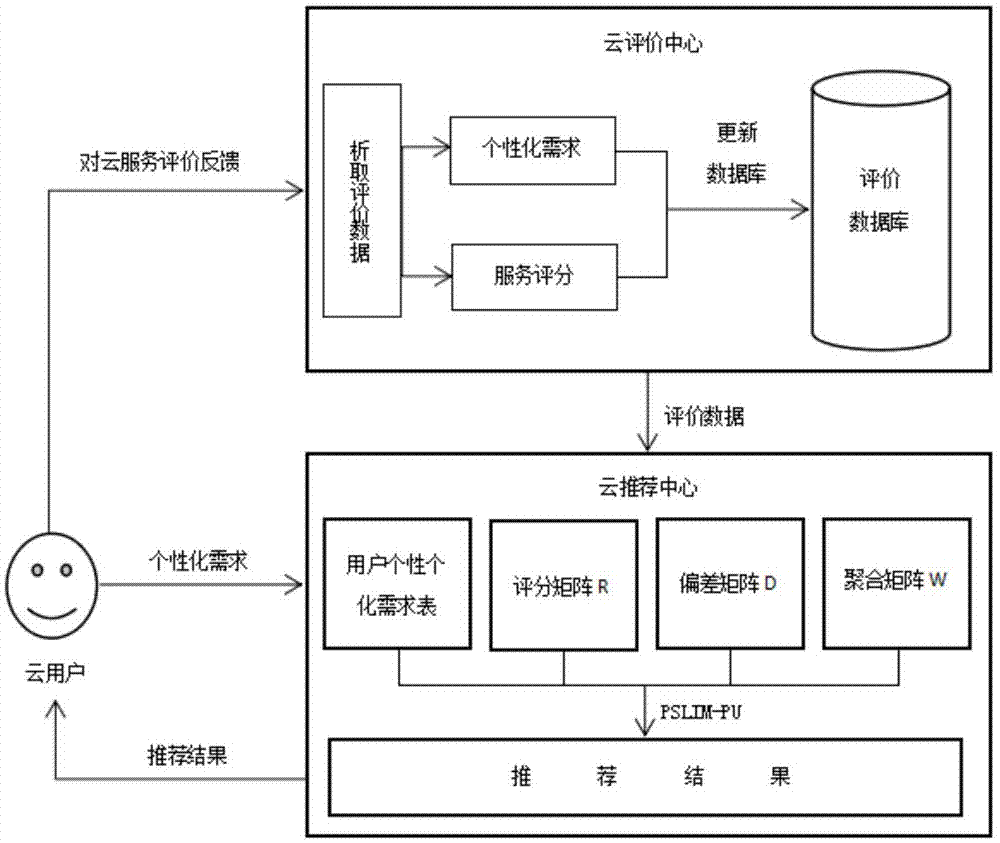
本发明属于云计算
技术领域:
,提供了一种基于稀疏线性方法的云服务个性推荐系统及方法。
背景技术:
:自2006年google提出“云计算”概念以来,云计算以其易于扩展、按需存储、弹性计算等优点在全球迅速发展。近年来,阿里,百度、google等相继提出云服务,随着各大运营商不断地将各种计算资源和存储能力等以基础设施即服务(infrastructure-as-a-service,iaas)、平台即服务(platform-as-a-service,paas)和软件即服务(software-as-a-service,saas)等形式发布到网络中,网络中出现越来越多的云服务,带来信息超载问题。面对众多功能性属性相同而非功能性属性各异的云服务,用户难以快速地选择出满足自己个性化需求的云服务[1],因此,如何在复杂的云计算环境下,在海量的云服务之中,为用户快速的推荐满足用户个性化需求的云服务是一个值得深入研究的问题。近年来,关于云服务推荐的算法提出了很多,常见的几种推荐算法有:①协同过滤推荐算法,这是使用最为广泛的一种推荐方法。这类方法分为基于用户/项目的协同过滤法和基于模型的协同过滤。基于用户/项目的协同过滤方法是利用用户对项目的使用经验计算来发现相似的用户/项目,再利用相似用户/项目进行推荐,如出了一种基于比率相似值的计算方法,通过比较用户当前使用的服务和相似服务的属性值来推荐,如一种基于用户偏好的协同过滤算法,这类方法一般推荐速度很好但准确率不够;基于模型的协同过滤是利用机器学习和统计方法从已有的评分中学习得到模型,再利用此模型对项目评分进行预测,由此得到项目推荐,这类方法性能相对较好,但是其常见的问题时难以理解或者有些潜在因素不能很好地解释;②基于内容的推荐方法,其思路是:利用项目本质特征的描述和用户的历史记录,为用户推荐其未使用的项目中与历史记录项目相似程度最高的项目。此种方法缺点在于对云服务属性的抽取、分析、量化、表达耗费较多的资源。③基于关联规则的推荐方法。关联规则推荐算法不需要领域知识,能发现新兴趣点,但是该方法规则抽取难、个性化程度低。技术实现要素:本发明实施例提供一种基于稀疏线性方法的云服务个性推荐方法,旨在提供一种解释灵活,且推荐结果较为精准的云服务个性化推荐方法。为了实现上述目的,本发明提供了一种基于稀疏线性方法的云服务个性推荐系统,该系统包括:云客户端,云评价中心,及云推荐中心;云客户端与云评价中心、以及云推荐中心通讯,其中,云客户端:用于向云推荐中心提交个性化需求、及基于使用过的云服务向云评价中心反馈云服评价;云评价中心:对云用户反馈的云服务评价进行解析,获取云服器在个性化需求下的评分,并将上述数据更新至评价数据库;云推荐中心,针对云用户的提交的个性化需求,基于评价数据库内的评价数据向云用户推荐云服务。为了实现上述目的,本发明提供了一种基于稀疏线性方法的云服务个性推荐方法,所述方法包括如下步骤:s1、接收用云用户ui提交的个性化需求pk,即选择若干最为看重的属性;s2、基于云用户ui在评价数据库中的历史评价数据,预测云用户在个性化需求pk下针对各云服务j的评分;s3、向云用户ui推荐评分最高的云服务。进一步的,所述步骤s2具体包括如下步骤:s21、计算云用户ui针对已评分云服务jh在个性化需求pk下与无个性需求下的评分偏差来计算评分偏差矩阵d;s22、基于评分偏差矩阵d及稀疏聚合矩阵w,来预测云用户ui在个性化需求pk下对云服务j的评分,所述云服务j的评分包括:已评分云服务jh的评分及未评分云服务jw的评分。进一步的,若步骤s221中的云用户ui在无个性化需求下针对多个云服务jh进行评分,则采用多个所述云服务jh评分的平均值作为云用户ui在无个性化需求下评分ri,h。进一步的,在步骤s221中,若不存在云用户ui在无个性化需求下对已评分云服务jh的评分,采用云用户ui在所有个性化需求下对已评分云服务jh的评分平均值,作为ui在无个性化需求下对已评分云服务jh的评分ri,h。进一步的,基于公式(1)及公式(2)来计算用户ui在个性化需求pk下对第j个云服务jj的评分公式(1)及公式(2)具体如下:其中,ri,n为云用户ui在无个性化需求下针对云服务jn的评分,di.k为云用户ui在个性化需求pk下针的评分与无个性化需求下的评分偏差,k为个性化偏差的种类数,n为云服务的个数,pk为用户个性化需求向量,wn,j为云服务jn与云服务jj间的聚合系数。本发明提供的基于稀疏线性方法的云服务个性化推荐方法具有如下有益技术效果:1.可以精准且灵活地定义个性化需求;2.通过学习的相关历史数据来获取云用户在各个性化需求下与无个性需求下的偏差,基于偏差来进行预测,使得推荐结果更为精准。附图说明图1为本发明实施例提供的云服务个性化推荐系统结构示意图;图2为本发明实施例提供的基于稀疏线性方法的云服务个性推荐方法流程图;图3为本发明实施例提供的在音乐数据集上的map仿真实验图;图4为本发明实施例提供的在电影数据集上的map仿真实验图;图5为本发明实施例提供的在餐馆数据集上的map仿真实验图;图6为本发明实施例提供的在音乐数据集上的recall仿真实验图;图7为本发明实施例提供的在电影数据集上的recall仿真实验图;图8为本发明实施例提供的在餐馆数据集上的recall仿真实验图;图9为本发明实施例提供的在音乐数据集上的precision仿真实验图;图10为本发明实施例提供的在电影数据集上的precision仿真实验图;图11为本发明实施例提供的在餐馆数据集上的precision仿真实验图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本专利涉及的一些专业名词的相关解释:1)个性化推荐:个性化推荐是根据用户的兴趣偏好来进行推荐,而云用户在挑选云服务时,通常首先考虑的是云服务的功能属性,云用户的个性化需求也就是对云服务功能属性的要求,因此发明给出云服务的至少5个功能属性,5个功能属性为:①可靠性r(reliability):在规定时间内无故障运行以及发生故障后在规定时间内恢复服务的能力;②可用性a(availability):在规定环境下持续提供特定功能的能力;③安全性s(security):提供数据保密性和完整性的能力;④实时性e(real-time):在规定时间内响应请求的能力;⑤可维护性m(maintainability):易于修改和完善的能力;本专利将云用户的个性化需求定义为云用户在使用云服务时最关心的若干云服务属性,这若干云服务属性有重要度之分,以两个云服务属性组成个性化需求类例进行说明,比如:①安全性②及时性是一种个性化需求,而①及时性②安全性是另一种个性化需求,之所以用这样组合的方式是因为考虑到更多的云用户的看重。图1为本发明实施例提供的云服务个性化推荐系统结构示意图,为了便于说明,仅示出于本发明实施例先关的部分。该云服务个性化推荐系统包括:云客户端,云评价中心,及云推荐中心;云客户端与云评价中心、以及云推荐中心通讯,其中,云客户端用于向云推荐中心提交个性化需求、及基于使用过的云服务向云评价中心反馈云服评价;云评价中心:对云用户反馈的云服务评价进行解析,获取云服器在该个性化需求下的评分,并将上述数据更新至评价数据库;数据库内存储有云用户针对各云服务的历史评分,该历史评分包括:在无个性化需求下的历史评分及在各个性化需求下的历史评分,并基于云用户当前在某个性化需求下针对某云服务的最新评分来更新该云用户在相同个性化需求下针对相同云服务的历史评分。云推荐中心,针对云用户的提交的个性化需求,基于评价数据库内的评价数据向云用户推荐云服务;云推荐中心用于基于云用户递交的个性化需求,在数据库内获取该云用户的历史评分。图2为本发明实施例提供的基于稀疏线性方法的云服务个性推荐方法流程图,云推荐中心的云服务个性推荐方法具体包括如下步骤:s1、接收用云用户ui提交的个性化需求pk,即选择若干最为看重的属性;s2、基于云用户ui在评价数据库中的历史评价数据,获取云用户在个性化需求pk下针对各云服务j的评分;s3、向云用户ui推荐评分最高的云服务。在本发明实施例中,步骤s2具体包括如下步骤:s21、计算云用户ui针对已评分云服务jh在个性化需求pk下与无个性需求下的评分偏差来计算评分偏差矩阵d;由于云用户评价的数据集是比较稀疏的,即不能保证同一个云用户在相同的个性化需求下对其他的云服务都做出了评分,这样就没有办法获得云用户在相同个性化需求下对其他云服务的评分,为了解决这个问题,引入个性化评分偏差。个性化评分偏差的意思是云用户对云服务在无个性化需求情况下和有个性化需求情况下评分之间的偏差,也就是认为对于每一对<云用户,个性化需求>和云用户在无个性化需求下的评分都存在偏差。如表1所示,某用户在无个性化需求的情况下对某云服务的评分是4,但是当在下面两种个性化需求下对这个云服务的评分分别为3和5,这说明用户在没有个性化需求情况下和在有个性化需求情况下的评分之间存在偏差。表1有无个性化需求下用户评分示例用户云服务评分个性化需求u1c14无u1c13①实时性②可靠性u1c15①安全性②实时性评分偏差矩阵d为一个n×k二维矩阵,用于表示个性化评分偏差,评分偏差矩阵d中每一行代表一个云用户在不同个性化需求下的评分与无个性化需求下的评分偏差,每一列代表所有用户在这种个性化需求下的评分与无个性化需求下的评分偏差,如表2所示;表2个性化评分偏差矩阵d在本发明实施例中,若数据库中不存在云用户un在个性化需求pm下历史数据,即云用户un在个性化需求pk下没有对任何云服务进行评分,则向用户随机推荐各云服务;在本发明实施例中,若步骤s221中的云用户ui在无个性化需求下对已评分云服务的jh的评分为多个,则采用多个评分的平均值作为云用户ui在无个性化需求下评分ri,h;若不存在云用户ui在无个性化需求下对已评分云服务的jh的评分,采用云用户ui在所有个性化需求下对已评分云服务jh的评分平均值,作为ui在无个性化需求下对已评分云服务jh的评分ri,h。s22、基于评分偏差矩阵d及稀疏聚合矩阵w,来预测云用户ui在个性化需求pk下对云服务j的评分,所述云服务j的评分包括:已评分云服务jh的评分及未评分云服务jw的评分。稀疏聚合矩阵w是n*n的非负矩阵,表示云服务之间的聚合系数,类似于项目之间的相似性矩阵,稀疏聚合矩阵中的每一行及每一列代表云服务间的聚合系数。基于公式(1)及公式(2)来计算用户ui在个性化需求pk下对第j个云服务jj的评分公式(1)及公式(2)具体如下:其中,ri,n为云用户ui在无个性化需求下针对云服务jn的评分,di.k为云用户ui在个性化需求pk下的评分与无个性化需求下的评分偏差,k为个性化偏差的种类数,n为云服务的个数,pk为用户个性化需求向量,wn,j为云服务jn与云服务jj间的聚合系数,为云用户ui在个性化需求pk下针对云服务jn的中间评分。对于公式(2)的理解,基于云用户针对某一云服务在利个性化需求下的评分和个性化评分偏差来计算得到该云用户在相同个性化需求下对其他云服务的中间评分。并且,在本专利中,即使云用户在某一个性化需求下对部分云服务进行过评分,同样还是基于公式(2)来计算该云用户在相同个性化需求下对已评分云服务的中间评分。因为这样可以使矩阵d中更多的数据被学习得到,从而使最终的预测评分更为精确,得到更好的推荐效果。对于公式(1)的理解,计算云用户ui在个性化需求pk下对云服务jn的评分也就是利用云用户ui在个性化需求pk下对除云服务jn以外云服务中间评分与聚合系数w相乘得到,即基于公式(1)来进行计算。pk表示云用户个性化需求的二进制向量,是根据个性化需求的组合情况,比如有四种情况则p(0,0,0,0),当个性化需求为第三种时这p(0,0,1,0),会随着组合变多而增加,还有就是会随着组合方式的变化,p也会有相应的变化。比如若存在同时包含三四种者p(0,0,1,1)。由于个性化偏差矩阵的行和列分代表用户(u)和个性化需求(p),是以用户真实的个性化评分为训练集,从数据中学习矩阵d和w中的参数,对于云服务的预测评分仅依靠四个因素:无个性化需求下的评分矩阵r、个性化偏差矩阵d、项目聚集系数矩阵w和用户个性化需求向量p。矩阵d和w的求解可以转化为正则化优化问题的最小值问题,可以用公式(4)来计算。其中||w||f是矩阵w的frobenius范式(lf范式),||w||1是矩阵w的l1范式,||d||f和||w||1同理;θ和β是学习率。公式(3)可以利用随机梯度下降法(stochasticgradientdescent,sgd)进行优化求解,其中参数的更新通过公式(4)-(6):其中参数α1,β1,λ1,α2,β2,λ2均是学习率,对于di,k,我们只更新位置k的参数,而且是当pk=1时才更新;而wh,j我们只更新相关位置的参数h,即用户已经评分的云服务集。本发明提供的基于稀疏线性方法的云服务个性化推荐方法具有如下有益技术效果:1.可以精准且灵活的定义个性化需求;2.通过学习的相关历史数据来获取云用户在各个性化需求下与无个性需求下的偏差,基于偏差来进行预测,使得推荐结果更为精准。为了验证本专利提出方法的性能,仿真实验从精准率(precision)、召回率(recall)和平均精度均值(map)三个标准来与基准算法进行对比。基准算法是比较常用的两种推荐算法:cf和casa。精准率和召回率是评估推荐系统中比较流行的度量标准,定义c是测试集上得到的推荐列表,d是训练集上得到的推荐列表,令i=c∩d,即i是基于推荐算法得到的正确的服务推荐结果。基于这些,precision和recall的计算公式分别为(7)和(8)。map是另一种常用的排名指标,它将排序项目的推荐等级考虑在内。map可以通过公式(9)计算。其中,m表示云用户的数量,n表示推荐列表的长度,p(k)表示推荐列表中截止k处的精度,m表示相关项目的数量。下面的多组仿真实验图将本文提出的方法与常见的两种推荐算法cf和casa在三种数据集上的表现作比对,评估的标准为上文所提到的精准率(precision)、召回率(recall)和平均精度均值(map)。用户在选择音乐、电影和餐馆时通常也对其有个性化的需求,比如音乐、电影和餐馆的类型,所以本文采用音乐、电影和餐馆三个数据集来模拟云服务数据集,如表3。使用三个不同的数据集是为了验证本文的方法在不同数据集上的表现。表3数据集基于上述三中数据集的仿真试验结果图3至图11,表明上本文提出的方法通常优于基准方法。虽然本文提出的方法在有些方面在某些情况不如基准方法,如在电影数据集上的准确性而言,本文所提出的方法在前10的推荐中不如基准方法,但是在10以后优于基准方法;还有在餐馆数据集上的准确性在20以后不如cf方法,但是在前20中优于基准方法,除此以外,本文方法均优于基准方法。其中在音乐数据集上的表现尤为突出,这是因为音乐数据集较为密集,也就是<用户,项目>对在不同的个性化需求下均存在评分,这样使得偏差矩阵可以更好的学习到评分偏差,使得推荐效果更加准确。同时本文方法在map上表现很好,均优于基准方法相对较多。因此本文提出的模型在个性化推荐中效果更好以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1