面向行人重识别任务的基于成对样本随机遮挡策略的数据扩充方法与流程
本发明属于图像检索技术领域,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术,更进一步涉及一种面向行人重识别任务的基于成对样本随机遮挡策略的数据扩充方法。
背景技术:
在监控视频中,由于背景遮挡和行人距摄像头较远导致的低分辨率等原因,经常无法得到可以用于人脸识别的图片。而当人脸识别技术无法正常使用的情况下,行人重识别就成为了一个非常重要的替代品技术。行人重识别有一个非常重要的特性就是跨摄像头,所以学术界评价性能的时候,是要检索出不同摄像头下的相同行人图片。行人重识别已经在学术界研究多年,但直到最近几年随着深度学习的发展,才取得了非常巨大的突破。
传统基于图像的通过特征表达方法进行行人重识别的算法大致分为如下几类:
(1)底层视觉特征:这种方法基本上都是将图像划分为多个区域,对每个区域提取多种不同的底层视觉特征,组合后得到鲁棒性更好的特征表示形式,最常用的就是颜色直方图;
(2)中层语义属性:通过语义信息判断两幅图象中是否属于同一行人,比如颜色、衣服以及携带的包等信息,相同的行人在不同的视频拍摄下语义属性很少变化;
(3)高级视觉特征:特征的选择技术对行人重识别的识别率进行提升。使用深度学习进行行人重识别的方法与传统方法最大的区别在于,它不需要人工的选取特征,通过端到端的学习,自动的学习行人图片中的各种特征。因此,在行人重识别领域,面对众多可以选择的特征,基于深度学习模型的方法能够达到较好的效果。现有的深度学习模型主要属于卷积神经网络的类别,通常使用的模型有caffenet、vggnet和残差网络等。
行人重识别问题相比于普通图像分类问题存在以下问题:
(1)有标签数据规模小:现有行人重识别的数据库行人数据很多,数据总量很大,但是单个行人的图像数据量小;
(2)数据缺乏多样性:由于数据中包含的单个个体图像数据规模较小,训练数据集提供的图像信息自然不够丰富;
(3)现场场景复杂,经常会出现行人被遮挡的现象,采用理想状态下的数据集训练模型很难直接应用到实际场景中。
行人重识别数据集样本多样性差的问题极大地限制了深度学习模型处理行人重识别任务的性能。由于数据规模有限,导致这些模型学习的特征表达不具有鲁棒性,并且模型容易产生过拟合的情况。
技术实现要素:
本发明的目的在于克服上述现有技术的不足,提出了一种面向行人重识别任务的基于成对样本随机遮挡策略的数据扩充方法。本发明与现有技术中数据扩充的方法相比,利用了孪生深度学习模型训练数据的特点,同时考虑了孪生网络训练的困难,提出了一种新的数据扩充方法。通过增加训练数据对的多样性,有效缓解单个行人数据集类别少且缺乏多样性问题给带来的影响,提升了模型的泛化性能,让行人重识别方法可以更好的处理复杂环境下的相行人重识别问题,可广泛应用于智能视频监控、智能安保等领域。
为了实现上述目的,本发明采用的技术方案是:
一种面向行人重识别任务的基于成对样本随机遮挡策略的数据扩充方法,
在训练阶段,首先通过采用基于成对样本随机遮挡策略的数据扩充方法增加样本的多样性,提高深度行人重模型训练过程中的鲁棒性,进而提高模型的泛化性能;
在测试阶段,无需对测试图像进行遮挡处理就可以有效的进行行人重识别任务,具体包括以下步骤:
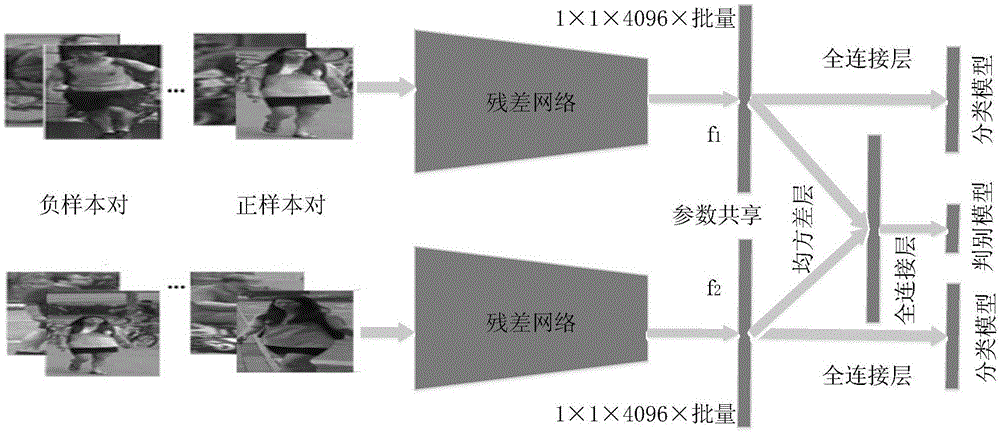
s1构建行人重识别深度孪生残差网络
s1.1、构造第一深度残差网络,采用迁移学习策略,导入在imagenet数据集上预训练的残差网络参数,将其作为第一深度残差网络的基础参数;
s1.2、通过复制第一深度残差网络的模型结构和参数得到第二深度残差网络;
s1.3、计算两个深度残差网络输出的特征向量差值的平方,利用卷积层和分类器进行二分类,判断上述两个深度残差网络的输入是否是同一类别的图像;
s1.4、计算两个残差网络输出特征向量的欧式距离,对于同类别图像采用其特征之间的欧式距离作为网络模型的正则损失;
s2构造训练数据集
s2.1、打乱训练数据集中图像的顺序,产生训练数据对,在模型参数训练的过程中将不同类别的图像对每个时期乘以因子1.01直到不同类别的图像对与相同类别的图像对之间的比例由1:1逐渐增加到4:1;
s2.2、将每张图片的尺寸调整成256×256,并且随机裁剪成224×224;
s2.3、从每一批的训练数据中随机选择2/3的样本对采用基于成对样本随机遮挡策略操作,用于数据扩充从而增加了训练样本的多样性,具体是:
在执行基于成对样本随机遮挡策略的过程中,随机选择90%的样本进行同步遮挡,即两张图片遮挡相同的区域;5%的样本对随机遮挡第一张图像,第二张图像不进行遮挡处理;剩下5%的样本对随机遮挡第二张图像,第一张图像不进行遮挡处理;
在执行基于成对样本随机遮挡策略的过程中,对于需要遮挡的图像被均等的划分为16×16的网格,每张图像被均匀的划分为256个图像块,随机产生一个1~128的随机数nre用于记录要遮挡的图像块的个数;
在执行基于成对样本随机遮挡策略的过程中,随机产生nre个图像块的位置,用训练样本集中所有图像的均值替代对应位置的像素值;
s3行人重识别深度孪生残差网络模型训练
s3.1、利用步骤s2已构造好的训练数据集采用批量梯度下降算法对行人重识别深度孪生残差网络进行参数训练;
s3.2、参数训练好之后,将第一深度残差网络取出用于行人图像的特征提取;
s4构建测试样本集,包括查询集和库集两个集合;
s5测试样本重识别性能
将所有测试样本集中的图像送入训练好的第一深度残差网络中进行特征提取,并且根据查询集和库集中样本在特征空间的欧式距离查找要搜索的行人;
s6输出行人重识别结果。
步骤s1.1具体如下:
s1.1.1、去除现有的深度残差网络最后的全连接层和概率层,形成第一深度残差网络,输出输入图像的特征向量f1;
s1.1.2、对第一深度残差网络添加卷积层和全连接softmax分类器,设置卷积层的特征图数为行人身份类别数n,卷积层将f1映射成为n维向量,由全连接分类器输出最终类别预测;
s1.1.3、对于第一深度残差网络的输入和输出,定义损失函数:
其中,x表示输入网络中的所有的行人数据,input表示深度孪生网络的输入,output表示深度孪生网络的输出。
步骤s1.2具体如下:
s1.2.1、去除第一深度残差网络最后的全连接层和概率层,形成第二深度残差网络,输出输入图像的特征向量f2;
s1.2.2、对第二深度残差网络添加卷积层和全连接softmax分类器,设置卷积层的特征图数为行人身份类别数n,卷积层将f2映射成为n维向量,由全连接分类器输出最终类别预测;
s1.2.3、对于第二深度残差网络的输入和输出,定义损失函数:
其中,x表示输入网络中的所有的行人数据,input表示深度孪生网络的输入,output表示深度孪生网络的输出。
步骤s1.3具体如下:
s1.3.1、设置平方层,将两个深度残差网络输出的特征向量f1、f2取差值平方,得到fs=(f1-f2)2
s1.3.2、设置特征映射图数为2的卷积层,将fs映射成为2维向量输出;
s1.3.3、全连接softmax分类器对输出的2维向量产生最终预测,即输入图像对是否来自同一类别;
s1.3.4、对于相同类别或不同类别的输入图像对q,定义损失函数:
其中,i表示2维向量的第i维,q为输入图像对,s为深度残差网路预测两张图像是否属于同一类的预测类别。
步骤s1.4具体如下:
s1.4.1、对于输入图像对(xi,xj),计算两个深度残差网络输出的特征向量f1、f2的欧式距离
其中(xi,xj)表示两张输入的图像对,d(xi,xj)表示图像xi和xj在特征空间的距离。
步骤s3.1具体如下:
s3.1.1、采用批量下降法对步骤s1.1.3、步骤s1.2.3、步骤s1.3.4的3个损失函数进行最优化;
s3.1.2、设置3个损失函数的权重,分别为λ1,λ2,λ3;
s3.1.3、经过一系列实验进行参数调试,确定最优的权重值。
步骤s3.2具体如下:
s3.2.1、将3个损失函数训练到最优即最小化损失函数;
s3.2.2、取出训练好的深度残差网络作为下一步的分类模型。
步骤s4具体如下:
s4.1、构建测试样本集,包括查询集和库集两个集合;
s4.2、调整测试样本集中的每张图片尺寸,让图片可以直接输入到深度残差网络,网络可以利用预训练的模型参数,减少模型训练的计算量。
步骤s5具体如下:
s5.1、分类模型是单通道的深度残差网络,对应的输入为单张图像;
s5.2、分类标准采用首位命中率和平均精度均值,其中,首位命中率指搜索结果中最靠前的一张图是正确结果的概率,一般通过实验多次来取平均值;平均精度均值是取多次查询准确率的均值来代表查询的准确率,二者数值越高表示模型性能越好。
本发明与现有技术相比具有以下优点:
第一,本发明提出的基于成对样本随机遮挡策略,在孪生网络样本不充足的情况下,可以有效的扩充训练样本的数量,同时提高训练样本的多样性。
第二,本发明提出的基于成对样本随机遮挡策略本发明是一种轻量级方法,不需要任何额外的参数学习或内存消耗,它可以轻松集成到各种孪生深度学习模型中,而无需改变学习策略。
第三,本发明提出的基于成对样本随机遮挡策略是现有数据增强和正则化方法的补充方法,通过跟其它正则化方法组合,基于成对样本随机遮挡策略的数据扩充方法进一步提高了识别性能。
第四,本发明提出的基于成对样本随机遮挡策略应用到行人重识别问题上,可以有效地提升孪生深度模型行人重识别方面的在首位命中率跟平均精度均值方面的性能。
第五,本发明提出的基于成对样本随机遮挡策略有效的缓解了孪生深度学习模型由于有效训练样本缺失问题引起的模型参数训练不充分的问题,同时有效地提升深度学习模型对遮挡样本的稳健性。
第六,本发明提出的基于成对样本随机遮挡策略,通过遮挡训练集中样本的显著性区域可以让模型学习到次显著性的特征,进而提升模型的性能。
第七,多组实验的结果表明采用本发明提出的数据扩充的方法产生的数据集可以很好模拟复杂场景下的数据行人数据,让训练好的模型具有良好的泛化性能,进而让模型处理复杂场景行人重识别问题方法有更大的优势。
附图说明
图1是本发明的网络结构图;
图2是本发明的步骤图。
具体实施方式
下面结合附图对本发明做进一步的详细说明。
参照图1,本发明实现的具体步骤如下:
s1,构建行人重识别深度孪生残差网络模型:
s1.1、构造深度残差网络模型(resnet),其结构为:输入层→卷积层→残差块→残差块→残差块→残差块→残差块→归一化层→全连接softmax分类器组成的深度卷积神经网络;
s1.2、采用迁移学习策略,导入采用imagenet数据集训练好的模型参数;
s1.3、去除resnet模型中最后两层,即“fc1000“和“prob”层,添加rate为0.9的dropout层,然后添加卷积层conv_1和softmax分类层,得到新的深度残差网络模型,即第一深度残差网络resnet_1;
s1.4、通过复制第一深度残差网络resnet_1模型的结构和参数得到第二深度残差网络resnet_2;
s1.5、通过计算第一深度残差网络resnet_1和第二深度残差网络resnet_2输出的4096维特征向量差值的平方得到4096维的“diff_feature”层,在这层之后添加rate为0.9的dropout层,然后添加卷积层conv_2和softmax层进行二分类,以此判断孪生网络输入是否为同一类别的图像。
s1.6、计算两个残差网络输出特征向量的欧式距离,对于同类别图像采用其特征之间的欧式距离作为网络模型的正则损失。
s2训练数据集构造:
s2.1、随机打乱数据集中图像的顺序,然后从相同/不同的类中选择另一幅图像组成正/负样本对,为了减轻预测偏差,我们设置负样本对和正样本对之间的初始比率为1:1,在模型参数训练的过程中将其每个时期乘以因子1.01直到它达到1:4,这样可以让模型高效地收敛,并且有效的抑制过拟合的风险;
s2.2、将每张图片的尺寸调整成256×256,并且随机裁剪成224×224;
s2.3、从每一批的训练数据中随机选择2/3的样本对采用基于成对样本随机遮挡策略操作,用于数据扩充从而增加了训练样本的多样性,具体是:
在执行基于成对样本随机遮挡策略的过程中,随机选择90%的样本进行同步遮挡,5%的样本对随机遮挡第一张图像,剩下5%的样本对随机遮挡第二张图像;
在执行基于成对样本随机遮挡策略的过程中,对于需要遮挡的图像被均等的划分为16×16的网格,每张图像被均匀的划分为256个图像块,随机产生一个1~128的随机数nre用于记录要遮挡的图像块的个数;
在执行基于成对样本随机遮挡策略的过程中,随机产生nre个图像块的位置,用训练样本集中所有图像的均值替代对应位置的像素值。
s3训练深度孪生残差网络模型:
s3.1、利用已构造好的训练数据集采用批量梯度下降算法对深度孪生残差网络模型进行参数训练;
s3.2、参数训练好之后,将第一深度残差网络resnet_1取出用于行人图像的特征提取。
s4,构建测试样本,包括查询集和库集两个集合;
s5,测试样本分类:将测试样本送入训练好的第一深度残差网络resnet_1模型中进行分类,并且在模型输出层得到分类结果。
s6,输出分类结果。
步骤s2.1中所述的深度残差网络模型结构参数如下:
对于第一层输入层,设置特征图谱数目为3,即图像的三个颜色通道;
对于第二层卷积层,设置特征图谱数目为64;
对于第三层第一个残差块9层,设置特征图谱数目为64;
对于第四层第二个残差块3层,设置特征图谱数目为64;
对于第五层第三个残差块6层,设置特征图谱数目为128;
对于第六层第四个残差块3层,设置特征图谱数目为256,进行快捷连接;
对于第七层第五个残差块6层,设置特征图谱数目为256;
对于第八层归一化层,设置为批量归一化方式;
对于第九层池化层,设置特征图谱数目为256;
对于第10层全连接softmax分类器,设置特征图谱数目为行人类别数目。
步骤s1.1具体如下:
s1.1.1、去除“fc1000”和“prob”层的第一深度残差网络resnet_1网络输出4096维的特征向量f1;
s1.1.2、设置卷积层conv_1的特征图数为行人身份类别数n,卷积层conv_1将f1映射成为n维向量,由softmax分类层输出最终类别预测;
s1.1.3、对于输入input,softmax的输出output,定义损失函数:
其中,x表示输入网络中的所有的行人数据,input表示深度孪生网络的输入,output表示深度孪生网络的输出。
步骤s1.2具体如下:
s1.2.1、去除“fc1000”和“prob”层的第二深度残差网络resnet_2网络输出4096维的特征向量f2;
s1.2.2、设置卷积层conv_1的特征图数为行人身份类别数n,卷积层conv_1将f2映射成为n维向量,由softmax分类层输出最终类别预测;
s1.2.3、对于输入input,softmax的输出output,定义损失函数:
其中,x表示输入网络中的所有的行人数据,input表示深度孪生网络的输入,output表示深度孪生网络的输出。
步骤s1.3具体如下:
s1.3.1、设置平方层,将两个深度残差网络输出的特征向量f1、f2取差值平方,得到fs=(f1-f2)2
s1.3.2、卷积层conv_2的特征图谱数为2,将fs映射成为2维向量;
s1.3.3、全连接softmax分类器对输出的2维向量产生最终预测,即输入图像对是否来自同一类别;
s1.3.4、对于输入图像对q(same/different),定义损失函数:
其中,i表示2维向量的第i维,q为输入图像对,s为深度残差网路预测两张图像是否属于同一类的预测类别;
步骤s1.4具体如下:
s1.4.1、对于输入图像对(xi,xj),计算两个深度残差网络输出的特征向量f1、f2的欧式距离
s1.4.2、定义相同类别图像对的正则损失函数:
其中(xi,xj)表示两张输入的图像对,d(xi,xj)表示图像xi和xj在特征空间的距离。
步骤s3如何构建训练集:
打乱训练数据集中图像的顺序,产生训练数据对,控制不同类别的图像对与相同类别的图像对之间的比例由1∶1逐渐增加到4∶1;
步骤s3.1、具体如下:
s3.1.1、采用批量下降法对步骤s1.1.3、步骤s1.2.3、步骤s1.3.4的3个损失函数进行最优化;
s3.1.2、设置3个损失函数的权重,分别为λ1,λ2,λ3;
s3.1.3、经过一系列实验进行参数调试,确定最优的权重值;
步骤s4.2具体如下:
s4.2.1、将3个损失函数训练到最优即最小化损失函数;
s4.2.2、.取出训练好的网络作为下一步的分类模型;
步骤s5如何构建测试样本如下:
s5.1、包括查询集和库集两个集合;
s5.2、将测试样本中的每张图片调整尺寸调整为224×224;
步骤s6具体如下:
4-1a.分类模型是单通道的resnet,对应的输入为单张图像;
4-1b.分类标准采用ranklaccuracy和map,即结果中最靠前的一张图是正确结果的准确率和多次查询准确率的均值;
下面对本发明的效果做进一步的说明:
1、实验条件:
本发明的实验是在双nvidiagtx1080tigpu的硬件环境和matlab2017的软件环境下进行的。
本发明的实验使用了三个行人重识别数据集market-1501、dukemmc、以及cuhk03。
market-1501数据集该数据集在清华大学校园中采集,图像来自6个不同的摄像头,其中有一个摄像头为低像素。同时该数据集提供训练集和测试集。训练集包含12,936张图像,测试集包含19,732张图像。图像由检测器自动检测并切割,包含一些检测误差(接近实际使用情况)。训练数据中一共有751人,测试集中有750人。所以在训练集中,平均每类(每个人)有17.2张训练数据。
dukemmc数据集在杜克大学内采集,图像来自8个不同摄像头。该数据集提供训练集和测试集。训练集包含16,522张图像,测试集包含17,661张图像。训练数据中一共有702人,平均每类(每个人)有23.5张训练数据。是目前最大的行人重识别数据集,并且提供了行人属性(性别/长短袖/是否背包等)的标注。
cuhk03数据集在香港中文大学内采集,图像来自2个不同摄像头。该数据集提供机器检测和手工检测两个数据集。其中检测数据集包含一些检测误差,更接近实际情况。平均每个人有9.6张训练数据。
2、结果分析:
本发明的仿真实验采用本发明方法与(1)未使用本发明提出的数据扩充方法(discnn)训练和(2)使用本发明提出的数据扩充方法(improveddiscnn)对三个数据集进行分类,并将分类效果进行对比分析。
表1是本发明的实验采用三种卷积神经网络模型和本发明方法对总体正确率进行对比的统计表。表1中的“数据集”表示采用的行人重识别数据集类型、“方法”包含未采用本发明的方法discnn和采用本发明的方法improveddiscnn重识别结果,“accuracy”表示分类的正确率,rank-1表示第一次识别即为正确行人的概率,“verif+identif”表示未使用行人对齐网络的孪生网络,“base+align”表示未使用孪生结构的行人对齐网络,“(base+verif)+(align+verif)”表示本发明使用的方法。
表1行人重识别结果比较一览表
从表1可以看出,本发明方法在三个数据集上结果均优于其他方法。
- 还没有人留言评论。精彩留言会获得点赞!