一种中文相似问题生成系统与方法与流程
本发明属于自然语言处理技术领域,特别涉及一种中文相似问题生成系统与方法。
背景技术:
现有技术提供了一种相似问题生成系统与方法,采用基于规则和统计相结合的方式,可以提高生成的问题问句与原始问题的匹配程度和合理性;但是,在商业中,问答的本质不在于答案的准确性,这种一对一的准确答案未必是消费者所需要的。
技术实现要素:
针对上述问题,本发明提供一种新的中文相似问题生成系统与方法,该中文相似问题生成系统与方法可以更加智能的回答用户提出的问题,有效保障了平台、商家以及用户之间的利益。
本发明具体技术方案如下:
本发明提供一种中文相似问题生成方法,所述生成方法包括:
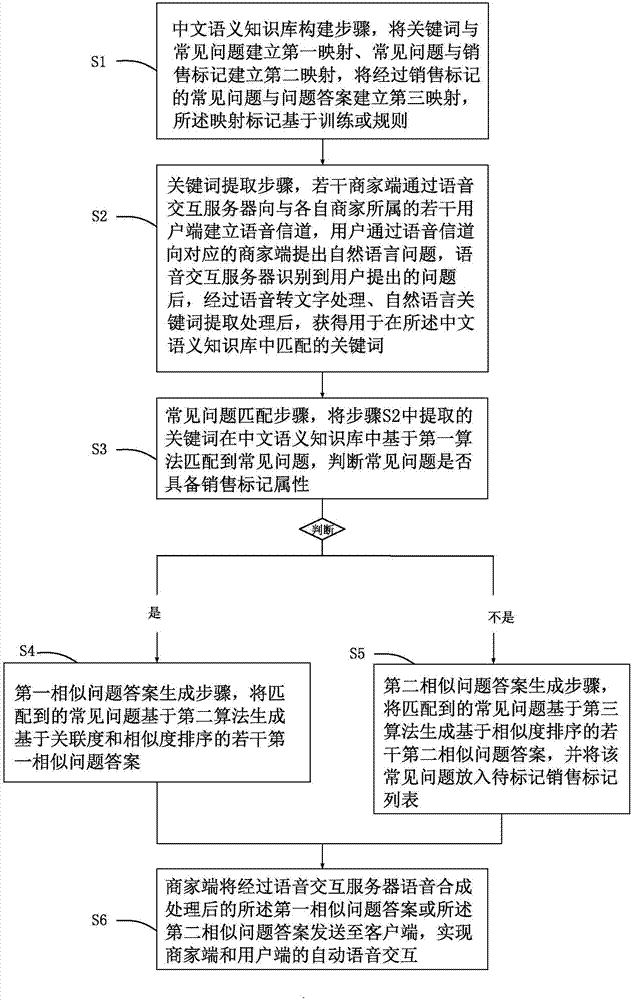
s1:中文语义知识库构建步骤,将关键词与常见问题建立第一映射、常见问题与销售标记建立第二映射,将经过销售标记的常见问题与问题答案建立第三映射,所述销售标记基于训练或规则生成;
s2:关键词提取步骤,若干商家端通过语音交互服务器向与各自商家所属的若干用户端建立语音信道,用户通过语音信道向对应的商家端提出自然语言问题,语音交互服务器识别到用户提出的问题后,经过语音转文字处理、自然语言关键词提取处理后,获得用于在所述中文语义知识库中匹配的关键词;
s3:常见问题匹配步骤,将步骤s2中提取的关键词在中文语义知识库中基于第一算法匹配到常见问题,判断常见问题是否具备销售标记属性,如果为带有销售标记属性的常见问题,则进入步骤s4,如果为不带有销售标记属性的常见问题,则进入步骤s5并将该常见问题放入待标记销售标记列表;
s4:第一相似问题答案生成步骤,将匹配到的常见问题基于第二算法生成基于关联度和相似度排序的若干第一相似问题答案;
s5:第二相似问题答案生成步骤,将匹配到的常见问题基于第三算法生成基于相似度排序的若干第二相似问题答案;
s6:商家端将经过语音交互服务器语音合成处理后的所述第一相似问题答案或所述第二相似问题答案发送至客户端,实现商家端和用户端的自动语音交互。
一种中文相似问题生成系统,所述生成系统包括:
中文语义知识库构建模块,用于构建中文语义知识库,将关键词与常见问题建立第一映射、常见问题与销售标记建立第二映射,将经过销售标记的常见问题与问题答案建立第三映射,所述销售标记基于训练或规则生成;
关键词提取模块,用于若干商家端通过语音交互服务器向与各自商家所属的若干用户端建立语音信道,用户通过语音信道向对应的商家端提出自然语言问题,语音交互服务器识别到用户提出的问题后,经过语音转文字处理、自然语言关键词提取处理后,获得用于在所述中文语义知识库中匹配的关键词;
常见问题匹配模块,用于将关键词提取模块中提取的关键词在中文语义知识库中基于第一算法匹配到常见问题,判断常见问题是否具备销售标记属性,如果为带有销售标记属性的常见问题,则进入第一相似问题答案生成模块,如果为不带有销售标记属性的常见问题,则进入第二相似问题答案生成模块并将该常见问题放入待标记销售标记列表;
第一相似问题答案生成模块,用于将匹配到的常见问题基于第二算法生成基于关联度和相似度排序的若干第一相似问题答案;
第二相似问题答案生成模块,用于将匹配到的常见问题基于第三算法生成基于相似度排序的若干第二相似问题答案;
交互模块,用于商家端将经过语音交互服务器语音合成处理后的所述第一相似问题答案或所述第二相似问题答案发送至客户端,实现商家端和用户端的自动语音交互。
本发明的有益效果如下:
本发明提供一种新的中文相似问题生成系统与方法,该中文相似问题生成系统与方法可以根据相似度在语义知识库中定位相应的答案,并将答案按照各销售标记的关联度进行排序,从而对用户进行解答,并且,对于同一带有销售标记属性的常见问题在语义知识库中定位到的答案可能不止一个,这样可以更加智能引导“答”,而不是简单的一问一答,在问答后可以使得平台、商家和客户之间均获得利益。
附图说明
图1为实施例1中文相似问题生成方法的流程图;
图2为实施例1步骤s4的流程图;
图3为实施例2中文相似问题生成系统的结构框图。
具体实施方式
下面结合附图和以下实施例对本发明作进一步详细说明。
附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
实施例1
本发明实施例1提供一种中文相似问题生成系统与方法,如图1所示,所述生成方法包括:
s1:中文语义知识库构建步骤,将关键词与常见问题建立第一映射、常见问题与销售标记建立第二映射,将经过销售标记的常见问题与问题答案建立第三映射,所述销售标记基于训练或规则生成;
s2:关键词提取步骤,若干商家端通过语音交互服务器向与各自商家所属的若干用户端建立语音信道,用户通过语音信道向对应的商家端提出自然语言问题,语音交互服务器识别到用户提出的问题后,经过语音转文字处理、自然语言关键词提取处理后,获得用于在所述中文语义知识库中匹配的关键词;
s3:常见问题匹配步骤,将步骤s2中提取的关键词在中文语义知识库中基于第一算法匹配到常见问题,判断常见问题是否具备销售标记属性,如果为带有销售标记属性的常见问题,则进入步骤s4,如果为不带有销售标记属性的常见问题,则进入步骤s5并将该常见问题放入待标记销售标记列表;
s4:第一相似问题答案生成步骤,将匹配到的常见问题基于第二算法生成基于关联度和相似度排序的若干第一相似问题答案;
s5:第二相似问题答案生成步骤,将匹配到的常见问题基于第三算法生成基于相似度排序的若干第二相似问题答案;
s6:商家端将经过语音交互服务器语音合成处理后的所述第一相似问题答案或所述第二相似问题答案发送至客户端,实现商家端和用户端的自动语音交互。
本发明提供一种新的中文相似问题生成方法,该中文相似问题生成方法可以根据相似度在语义知识库中定位相应的答案,并将答案按照各销售标记的关联度进行排序,从而对用户进行解答,并且,对于同一带有销售标记属性的常见问题在语义知识库中定位到的答案可能不止一个,这样可以更加智能引导“答”,而不是简单的一问一答,在问答后可以使得平台、商家和客户之间均获得利益。
步骤s1中,中文语义知识库中关键词与常见问题之间、经过销售标记的常见问题与问题答案之间均可采用多种的映射关系,常见问题与销售标记之间优选采用一一对应的映射关系。常见问题与销售标记之间建立映射关系,也可以是问题答案与销售标记之间建立映射关系,属于本领域相关技术人员的常规选择。
步骤s1中,销售标记可以用字母或数字表示,比如分成a、b、c、d共4个类别。所述规则为:根据商家的销售专家知识,比如根据潜在客户的购买阶段,分别为“马上购买”、“有需求”、“有购买欲望”以及“有潜在欲望”递减赋予不同常见问题销售标记,判断的方式包括但不限于将销售类别按人群兴趣点语句、竞品语句、询价语句、品牌语句,上述专家知识不应理解为对本发明保护范围的限定,其他能够能够提高销售转化率(roi)的分类方式均可。如“人群兴趣点语句”标记为a类,“竞品语句”标记为b类,“询价语句”标记为c类,“品牌语句”标记为d类。当数据量较大比如超出10000条时,可基于训练生成,训练的方法包括已知的机器学习算法,比如神经网络算法、马尔可夫算法,基于本发明构思选择其他ai算法训练销售标记均在本发明保护之内。
本实施例的步骤s4中,匹配出的带有销售标记的常见问题的数量为2个或2个以上,在实际的问答中,当用户连续提出多个问题时,或者是用户提出的为一个问句,但是基于第一算法匹配出的为至少两个问题时,可以根据s2-s5的步骤匹配出基于关联度和相似度排序的第一相似问题答案或者匹配出基于相似度排序的第二相似问题答案,这样可以更好的满足用户的需求,可以方便商家将“有潜在欲望”的消费者转变为“马上购买”的消费者,同时,用户与商家之间的语音交互可以为平台带来更大的利益,因此,该方法可以更好的保证平台、商家与用户之间的利益。接上文示例,在计算关联度时对销售标记按照如下方式赋值,其中a类关联度为0.1、b类关联度为0.2、c类关联度为0.3、d类关联度为0.4,系统处理自然语音问题的过程如表1、表2所示:
例如:
当输入的问题不带有销售标记时,通过第三算法输出答案,输出顺序为新鲜的、全市最低、t鲜花店好,输出的回答顺序按照相似度的高低已调整好。
表2
还可以分别计算各答案的关联度,如新鲜的(0.1)、在朝阳(0.1)、海淀有店铺(0.1)、送货(0.4)、有广西的兰花(0.2)、有促销(0.4),此时输出答案的顺序为送货、有促销、有广西的兰花、新鲜的、在朝阳、海淀有店铺,基于本发明构思,这种方式排序也是可以的;当输入的问题不带有销售标记时,通过第三算法输出答案,输出顺序为新鲜的、在朝阳、海淀有店铺、送货、有广西的兰花、有促销,输出的回答顺序按照相似度的高低已调整好。
如图2所示,本实施例中,步骤s4包括如下步骤:
s41:对于带有销售标记属性的常见问题,在中文语义知识库中通过第二算法基于相似度生成若干第一相似问题答案,所述第二算法包括但不限于基于word2vec计算常见问题与问题答案之间的相似度,基于本发明构思选择其他ai算法计算相似度均在本发明保护之内;
s42:计算带有销售标记属性的常见问题的关联度,基于关联度值对生成的第一相似问题答案进行排序,所述关联度基于训练或规则计算。
由于一个常见问题可能对应多个问题答案,此时,需要通过第二算法计算该常见问题与各问题答案之间的相似度,取相似度值最高的答案为该常见问题的备选输出答案,由于用户提出了多个带有销售标记的问题,因此需要计算各销售标记的关联度,基于关联度的值对各备选输出答案进行排序输出实际答案,可以大大提升平台、商家以及用户之间的利益。
本实施例的步骤s42中基于规则计算包括但不限于基于商家的销售专家知识对中文语义知识库中的各销售标记赋予关联度,基于训练的计算包括对中文语义知识库中每个销售标记进行关联度赋值,计算模型对赋予了关联度的销售标记进行训练,所述计算模型是基于人工智能深度学习技术建立的;接上文示例,计算模型分别赋予了分值的销售标记进行训练,通过训练好的计算模型可以直接对各销售标记进行赋值;根据关联度输出答案时,更加有针对性,更加满足用户的需求,进而保证平台、商家和用户之间的利益。
本实施例中步骤s3中的第一算法包括但不限于递归神经网络算法,基于本发明构思选择其他ai算法计算相似度均在本发明保护之内;步骤s5中的第三算法包括但不限于自然语言处理算法。
本发明的自然语言处理(nlp,naturallanguageprocessing)算法包括但不限于基于统计的机器学习算法(machinelearning)和深度学习算法(deeplearning)。以下nlp算法的选择均在本发明构思之内,分类算法可以选择lr(logisticregression,逻辑回归又叫逻辑分类)、svm(supportvectormachine,支持向量机)、nb(naivebayes,朴素贝叶斯)、dt(decisiontree,决策树)、集成算法(比如1).bagging、2).randomforest(随机森林)、3).gb(梯度提升,gradientboosting)、4).gbdt(gradientboostingdecisiontree)、5).adaboost、6).xgboost)、最大熵模型;回归算法可以选择lr(linearregression,线性回归)、svr(支持向量机回归)、rr(ridgeregression,岭回归);聚类算法可以选择knn、kmeans算法、层次聚类、密度聚类;降维算法可以选择sgd(随机梯度下降);概率图模型算法可以选择贝叶斯网络、hmm、crf(条件随机场);文本挖掘算法可以选择模型(比如lda(主题生成模型,latentdirichletallocation)、最大熵模型)、关键词提取(比如1).tf-idf、2).bm25、3).textrank、4).pagerank、5).左右熵:左右熵高的作为关键词、6).互信息)、词法分析(比如1).分词–①hmm(因马尔科夫)–②crf(条件随机场)、2).词性标注、3).命名实体识别)、句法分析(比如1).句法结构分析、2).依存句法分析)、文本向量化(比如1).tf-idf、2).word2vec、3).doc2vec、4).cw2vec)、距离计算(比如1).欧氏距离、2).相似度计算);优化算法可以选择正则化(比如1).l1正则化、2).l2正则化);深度学习算法可以选择bp、cnn、dnn、rnn、lstm。
实施例2
一种中文相似问题生成系统,如图3所示,所述生成系统包括:
中文语义知识库构建模块1,用于构建中文语义知识库,将关键词与常见问题建立第一映射、常见问题与销售标记建立第二映射,将经过销售标记的常见问题与问题答案建立第三映射,所述销售标记基于训练或规则生成;
关键词提取模块2,用于若干商家端通过语音交互服务器向与各自商家所属的若干用户端建立语音信道,用户通过语音信道向对应的商家端提出自然语言问题,语音交互服务器识别到用户提出的问题后,经过语音转文字处理、自然语言关键词提取处理后,获得用于在所述中文语义知识库中匹配的关键词;
常见问题匹配模块3,用于将关键词提取模块2中提取的关键词在中文语义知识库中基于第一算法匹配到常见问题,判断常见问题是否具备销售标记属性,如果为带有销售标记属性的常见问题,则进入第一相似问题答案生成模块4,如果为不带有销售标记属性的常见问题,则进入第二相似问题答案生成模块5并将该常见问题放入待标记销售标记列表;
第一相似问题答案生成模块4,用于将匹配到的常见问题基于第二算法生成基于关联度和相似度排序的若干第一相似问题答案;
第二相似问题答案生成模块5,用于将匹配到的常见问题基于第三算法生成基于相似度排序的若干第二相似问题答案;
交互模块6,用于商家端将经过语音交互服务器语音合成处理后的所述第一相似问题答案或所述第二相似问题答案发送至客户端,实现商家端和用户端的自动语音交互。
本实施例中,所述中文语义知识库构建模块1中,所述规则包括但不限于根据商家的销售专家知识,当数据量较大时可基于训练生成,所述训练方法包括已知的机器学习算法。
本实施例中,所述中文语义知识库构建模块1的中文语义知识库中关键词与常见问题之间、经过销售标记的常见问题与问题答案之间均可采用多种的映射关系,常见问题与销售标记之间优选采用一一对应的映射关系。
本发明提供一种新的中文相似问题生成系统,该中文相似问题生成系统可以根据相似度在语义知识库中定位相应的答案,并将答案按照各销售标记的关联度进行排序,从而对用户进行解答,并且,对于同一带有销售标记属性的常见问题在语义知识库中定位到的答案可能不止一个,这样可以更加智能引导“答”,而不是简单的一问一答,在问答后可以使得平台、商家和客户之间均获得利益。
由于本发明的方法描述是在计算机系统中实现的。该计算机系统例如可以设置在服务器或客户端的处理器中。例如本文所述的方法可以实现为能以控制逻辑来执行的软件,其由服务器中的cpu来执行。本文所述的功能可以实现为存储在非暂时性有形计算机可读介质中的程序指令集合。当以这种方式实现时,该计算机程序包括一组指令,当该组指令由计算机运行时其促使计算机执行能实施上述功能的方法。可编程逻辑可以暂时或永久地安装在非暂时性有形计算机可读介质中,例如只读存储器芯片、计算机存储器、磁盘或其他存储介质。除了以软件来实现之外,本文所述的逻辑可以利用分利部件、集成电路、与可编程逻辑设备(诸如,现场可编程门阵列(fpga)或微处理器)结合使用的可编程逻辑,或者包括它们任意组合的任何其他设备来体现。所有此类实施旨在落入本发明的范围之内。
以上所述实施例仅仅是本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明的权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!