基于数据驱动融合策略的多目标燃烧优化方法与流程
本发明属于燃煤电站锅炉多目标燃烧优化技术领域,具体来说涉及一种基于数据驱动融合策略的多目标燃烧优化方法。
背景技术:
随着中国电力市场的改革和环保意识的增强,大型燃煤电站锅炉一方面要提高燃烧经济性,另一方面要降低污染物排放。因此,燃煤电站锅炉燃烧优化问题其实是一个减少污染物排放,并增加锅炉效率的多目标优化问题。与单目标问题不同,多目标之间通常相互关联且相互矛盾,提高锅炉效率和降低nox排放即是如此。因此,解决多目标优化问题,就是要找到能最大化均衡各个目标的较好的解。目前,基于数据驱动的多目标燃烧优化受到了广泛的关注,一般来说,该方案又可分为以下两种策略。
第一种数据驱动策略,是基于锅炉燃烧关联规则的多目标优化(以下简称策略1),它是通过挖掘燃煤电站存储的海量历史运行数据,直接找出运行参数和性能指标之间的定量关系,以此作为指导多目标燃烧优化的规则。策略1能直接得到不同工况下唯一优化解,虽然优化过程快,结果也来源于真实的历史运行数据,但是无法保证得到最优解,多目标整体优化程度较低。
第二种数据驱动策略,是基于锅炉燃烧数学模型的多目标优化(以下简称策略2),它是利用历史运行数据,先建立锅炉燃烧过程的数学模型,在此基础上,再利用寻优方法,找出运行参数的优化解,实现燃烧优化。策略2虽然整体优化程度较高,但是缺少对工况的约束,而且优化过程耗时较长。
因此,为了弥补上述两种数据驱动策略的缺陷,兼顾多目标燃烧优化的实时性和有效性,使多目标燃烧优化适合实际在线应用,研究如何将两种数据驱动策略相融合的应用到多目标燃烧优化中,具有重要的理论和现实意义。目前,基于数据驱动融合策略的多目标燃烧优化,在理论研究和实际应用中均还未见报道。
技术实现要素:
针对现有技术的不足,本发明的目的在于提供一种基于数据驱动融合策略的多目标燃烧优化方法。
本发明的目的是通过下述技术方案予以实现的。
一种基于数据驱动融合策略的多目标燃烧优化方法,包括以下步骤:
步骤1,以n分钟(n大于0且小于100)为周期对dcs数据库海量历史运行数据进行再采样,得到再采样数据集,其中,所述dcs数据库海量历史运行数据包括:操作变量的数据、性能变量的数据和工况变量的数据;
步骤2,采用滑动窗口法对再采样数据集中机组负荷和煤质系数两个工况变量进行稳态检测,获取再采样数据集中机组负荷和煤质系数均处于稳态的所有时间区间,所述时间区间的数量为多段,每一段时间区间的数据为一个稳态数据集;
在所述步骤2中,在所述滑动窗口法中,针对再采样数据集中机组负荷和煤质系数两个工况变量的每一个数据,如果窗口中的数据满足公式(2),则定义该窗口所在的时间区间为该工况变量处于稳态的时间区间;如果窗口中的数据不满足公式(2),则窗口向后移动一个数据继续检测,直至检测完所述再采样数据集中该工况变量的所有数据,其中,所述公式(2)如下:
其中,t为滑动窗口检测的开始时间,单位为分钟;m为滑动窗口的宽度;
步骤3,获取稳态数据集,计算每个稳态数据集中每一个变量的平均值,所述变量由操作变量、性能变量和工况变量组成,针对稳态数据集中每一时刻进行判定,判定后,每个稳态数据集形成一个干净数据集,其中,所述判定方法为:如果某时刻的变量值与该变量的平均值的差异de超过20%,则判定该时刻的变量值为异常数据(野值)并将该时刻的变量值用该变量的平均值替代;
在所述步骤3中,所述差异de的计算公式如下:
其中,yvt为稳态数据集中某一变量第vt时刻的变量值,
步骤4,把所有的干净数据集合并,得到一个合并的数据集z0,根据所述数据集z0中机组负荷和煤质系数两个工况变量的值,利用k均值聚类算法分别对所述数据集z0中机组负荷和煤质系数两个工况变量进行聚类划分,得到多个机组负荷区间和多个煤质系数区间,任意一个机组负荷区间和任意一个煤质系数区间组成一个工况分区,得到多个工况分区;
步骤5,针对步骤4所得的工况分区分别进行下述操作:
操作一:利用约束分级模糊关联规则算法提取每个工况分区的优化规则,再把各个工况分区的优化规则合并,得到全工况下的燃烧优化规则库;
操作二:针对每个工况分区,分别建立以nox排放和锅炉效率为输出变量的lssvr模型,再把各个工况分区下的lssvr模型合并,得到全工况下的燃烧优化模型库;
在所述步骤5中,针对一个工况分区,所述约束分级模糊关联规则算法的步骤为:
第1步:输入已知条件,所述已知条件为作为约束条件的一个工况分区、数据集z0以及数据集z0中各个性能变量的权重等级,所述权重等级为最高和次高;
第2步:从数据集z0中选出满足所述约束条件的所有的数据项,形成新的数据集z;
第3步:采用模糊c均值聚类算法,对数据集z中权重等级为最高的性能变量进行聚类,得到该性能变量的所有模糊分区
第4步:根据模糊分区
第5步:在数据集z1中,选出权重等级为次高的性能变量的变量值为最优值的数据项zo-r作为一条优化规则,其中,当权重等级为次高的性能变量为nox排放时,最优值为最小值;当权重等级为次高的性能变量为锅炉效率时,最优值为最大值;
步骤6,同时运用策略1和策略2,在线进行多目标燃烧优化,
策略1:根据实时工况确定其所属工况分区,从燃烧优化规则库中直接选出该工况分区的优化规则,所述实时工况为机组负荷的实时变量值和煤质系数的实时变量值;
策略2:根据实时工况确定其所属工况分区,从燃烧优化模型库中选出该工况分区的lssvr模型,再将实时工况作为多目标优化的约束,利用改进的多目标粒子群优化算法得到多目标优化非劣解集,再利用多属性决策方法从所述多目标优化非劣解集中选出该实时工况下的唯一最优解;
在策略2获得唯一最优解前,策略1获得优化规则,按照所述优化规则对锅炉二次风系统中的每个操作变量进行调整,当所述策略2得出唯一最优解时,将所述唯一最优解与优化规则进行比较获得两者之间的最佳结果,当最佳结果为优化规则时,按照所述策略2重新计算直至策略2所得唯一最优解为最佳结果,按照唯一最优解对锅炉二次风系统中的每个操作变量再进行调整。
在策略2中,将实时工况作为多目标优化的约束如公式(4)所示:
在公式(4)中,f(x)为多目标函数,flssvr_nox(x)为nox排放lssvr模型的输出值,flssvr_be(x)为锅炉效率lssvr模型的输出值,
在上述技术方案中,改进的多目标粒子群优化算法中粒子速度更新环节利用公式(5)和公式(6)对粒子速度进行更新,具体过程如下:
kk为当前迭代次数,t为总迭代次数,
当kk<t/2时,采用公式(5)更新粒子速度,
v(i,j)kk+1=wv(i,j)kk+c1r1(pb(i,j)kk-px(i,j)kk)+c2r2(pg(i,j)kk-px(i,j)kk)(5)
在公式(5)中,ω为惯性权重,c1个体学习因子,c2为全局学习因子,i为第i个粒子,j为每个粒子的第j维,1≤i≤nn,1≤j≤d,px(i,j)kk为第kk次迭代时第i个粒子第j维的位置;v(i,j)kk为第kk次迭代时第i个粒子第j维的速度,r1和r2为0-1之间的随机数,pb(i,j)kk为第kk次迭代时粒子在搜索过程中的个体最优位置,pg(i,j)kk为第kk次迭代时粒子在搜索过程中的全局最优位置,pg(i,j)kk取自改进的多目标粒子群优化算法建立的外部档案;
当kk>=t/2时,采用公式(6)更新粒子速度,
在公式(6)中,c3为扰动学习因子,r3为0-1之间的随机数,pc(i,j)kk为第kk次迭代时扰动粒子的位置且初始值为0,其中,采用公式(6)更新粒子速度后,pc(i,j)kk每次从外部档案中随机选取且不和pg(i,j)kk相同。
在多目标燃烧优化过程中,策略1,算法简单、优化速度快且优化结果来源于真实的历史运行数据,但是多目标整体优化的程度低;策略2,多目标整体优化的程度高,但是算法复杂、优化速度慢。因此,本发明专利为了同时发挥以上两种数据驱动策略的优势,更好的实现快速在线多目标燃烧优化,将上述两种数据驱动策略相融合,在燃烧优化前期采用策略1,针对实时工况,在燃烧优化规则库中,快速选出唯一优化规则,完成初期优化;与此同时,策略2同步进行,将实时工况作为优化约束条件,在各个优化目标的lssvr模型上,应用改进的多目标粒子群优化算法,计算出非劣解集,再通过多属性决策方法,从非劣解集中提炼出唯一最优解,进一步优化燃烧过程,完成深度优化。综上所述,本发明方法弥补了单一数据驱动策略的缺陷,并且全面考虑了实时工况对优化的影响,切实满足了燃煤电站对多目标燃烧优化实时性和有效性的需求。
附图说明
图1为本发明稳态检测示例,其中,图1(a)为机组负荷稳态检测,图1(b)为煤质系数稳态检测;
图2为本发明实施例燃烧优化规则库构建过程;
图3为本发明实施例燃烧优化模型库构建过程;
图4为本发明实施例数据驱动融合策略计算过程;
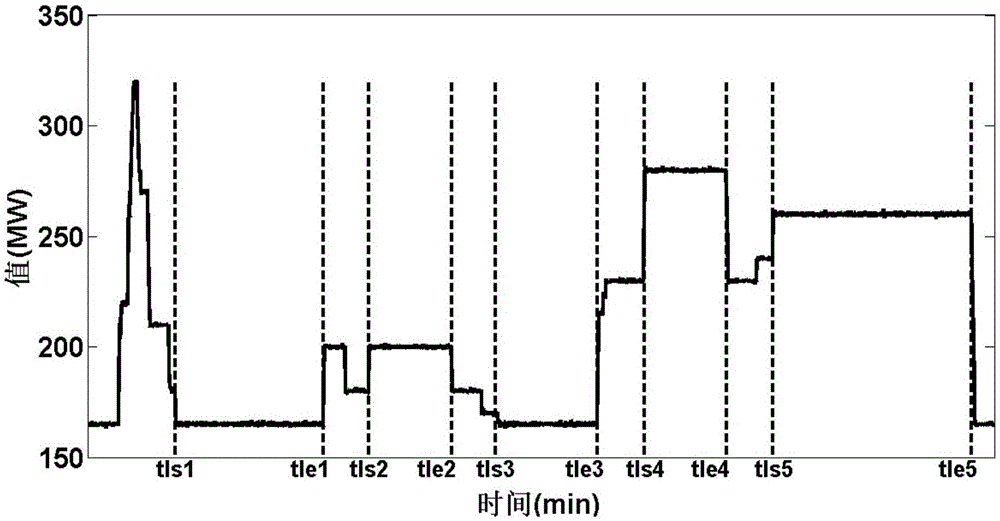
图5为本发明实施例融合策略应用效果。
具体实施方式
下面结合具体实施例进一步说明本发明的技术方案。
一种基于数据驱动融合策略的多目标燃烧优化方法,包括以下步骤:
步骤1,以n分钟(n大于0且小于100)为周期对dcs数据库海量历史运行数据进行再采样,得到再采样数据集,其中,所述dcs数据库海量历史运行数据包括:操作变量的数据、性能变量的数据和工况变量的数据;在本实施例中,n为1。
在所述步骤1中,所述操作变量包括锅炉二次风系统的16个操作变量,具体如表1所示,所述性能变量包括nox排放和锅炉效率,具体如表2所示,所述工况变量包括机组负荷和煤质,其中,煤质由煤质系数cqc表示,并通过式(1)计算,工况变量具体如表3所示。
cqc=机组负荷/总给煤量(1)
表1操作变量
表2性能变量
表3工况变量
步骤2,采用滑动窗口法对再采样数据集中机组负荷和煤质系数两个工况变量进行稳态检测,获取再采样数据集中机组负荷和煤质系数均处于稳态的所有时间区间,所述时间区间的数量为多段,每一段时间区间的数据为一个稳态数据集;
在所述步骤2中,在所述滑动窗口法中,针对再采样数据集中机组负荷和煤质系数两个工况变量的每一个数据,如果窗口中的数据满足公式(2),则定义该窗口所在的时间区间为该工况变量处于稳态的时间区间;如果窗口中的数据不满足公式(2),则窗口向后移动一个数据继续检测,直至检测完所述再采样数据集中该工况变量的所有数据,其中,所述公式(2)如下:
其中,t为滑动窗口检测的开始时间,单位为分钟;m为滑动窗口的宽度;
步骤3,获取稳态数据集,计算每个稳态数据集中每一个变量的平均值,所述变量由操作变量、性能变量和工况变量组成,针对稳态数据集中每一时刻进行判定,判定后,每个稳态数据集形成一个干净数据集,其中,所述判定方法为:如果某时刻的变量值与该变量的平均值的差异de超过20%,则判定该时刻的变量值为异常数据(野值)并将该时刻的变量值用该变量的平均值替代;
在所述步骤3中,所述差异de的计算公式如下:
其中,yvt为稳态数据集中某一变量第vt时刻的变量值,
步骤4,把所有的干净数据集合并,得到一个合并的数据集z0,根据所述数据集z0中机组负荷和煤质系数两个工况变量的值,利用k均值聚类算法分别对所述数据集z0中机组负荷和煤质系数两个工况变量进行聚类划分,得到多个工况分区;
本专利以330mw燃煤发电机组为例,其正常运行的机组负荷范围为140mw至330mw,利用k均值聚类算法将机组负荷的变量值划分为6个机组负荷区间,6个机组负荷区间用数据集ld={ld1,ld2,ld3,ld4,ld5,ld6}表示。利用k均值聚类算法将煤质系数的变量值划分为3个煤质系数区间,3个煤质系数区间即:差、中、好,用数据集
表4机组负荷划分结果
表5煤质系数划分结果
任意一个机组负荷区间和任意一个煤质系数区间组成一个工况分区,即一个工况分区为一个机组负荷区间和一个煤质系数区间的组合,示例如表6所示。
表6工况分区示例
步骤5,针对步骤4所得的工况分区分别进行下述操作:
操作一:利用约束分级模糊关联规则算法提取每个工况分区的优化规则,再把各个工况分区的优化规则合并,得到全工况下的燃烧优化规则库,燃烧优化规则库构建过程如图2所示。
操作二:针对每个工况分区,分别建立以nox排放和锅炉效率为输出变量的lssvr模型,再把各个工况分区下的lssvr模型合并,得到全工况下的燃烧优化模型库,燃烧优化模型库构建过程如图3所示。
在所述步骤5中,针对一个工况分区,所述约束分级模糊关联规则算法的步骤为:
第1步:输入已知条件,所述已知条件为作为约束条件的一个工况分区、数据集z0以及数据集z0中各个性能变量的权重等级,所述权重等级为最高和次高;
第2步:从数据集z0中选出满足所述约束条件的所有的数据项,形成新的数据集z;
第3步:采用模糊c均值聚类算法,对数据集z中权重等级为最高的性能变量进行聚类,得到该性能变量的所有模糊分区
第4步:根据模糊分区
第5步:在数据集z1中,选出权重等级为次高的性能变量的变量值为最优值的数据项zo-r作为一条优化规则,其中,当权重等级为次高的性能变量为nox排放时,最优值为最小值;当权重等级为次高的性能变量为锅炉效率时,最优值为最大值;
在所述步骤5中,建立所述lssvr模型的方法见参考文献:suykensjak,vandewallej.leastsquaressupportvectormachineclassifiers[j].neuralprocessingletters,1999,9(3):293-300。
步骤6,同时运用策略1和策略2,在线进行多目标燃烧优化,
策略1:根据实时工况确定其所属工况分区,从燃烧优化规则库中直接选出该工况分区的优化规则,所述实时工况为机组负荷的实时变量值和煤质系数的实时变量值;
策略2:根据实时工况确定其所属工况分区,从燃烧优化模型库中选出该工况分区的lssvr模型,再将实时工况作为多目标优化的约束,利用改进的多目标粒子群优化算法得到多目标优化非劣解集,再利用多属性决策方法从所述多目标优化非劣解集中选出该实时工况下的唯一最优解;
在策略2获得唯一最优解前,策略1获得优化规则,按照所述优化规则,对锅炉二次风系统中的每个操作变量进行调整,当所述策略2得出唯一最优解时,将所述唯一最优解与优化规则进行比较,如果唯一最优解中,性能变量nox排放和锅炉效率的变量值均优于优化规则中nox排放和锅炉效率的变量值,则使用策略2得出的唯一最优解对锅炉二次风系统中的每个操作变量再进行调整,否则,保持优化规则对锅炉二次风系统中每个操作变量的调整结果,并重新计算策略2的唯一最优解直至策略2所得唯一最优解为最佳结果。策略1和策略2相融合的数据驱动融合策略计算过程如图4所示。
在策略2中,将实时工况作为多目标优化的约束如公式(4)所示:
在公式(4)中,f(x)为多目标函数,flssvr_nox(x)为nox排放lssvr模型的输出值,flssvr_be(x)为锅炉效率lssvr模型的输出值,
在上述技术方案中,所述改进的多目标粒子群优化算法对标准多目标粒子群优化算法中粒子速度更新环节进行了更改,标准多目标粒子群优化算法中粒子速度更新环节只利用公式(5)对粒子速度进行更新,改进的多目标粒子群优化算法中粒子速度更新环节利用公式(5)和公式(6)对粒子速度进行更新,更改具体过程如下:
kk为当前迭代次数,t为总迭代次数,
当kk<t/2时,采用公式(5)更新粒子速度,
v(i,j)kk+1=wv(i,j)kk+c1r1(pb(i,j)kk-px(i,j)kk)+c2r2(pg(i,j)kk-px(i,j)kk)(5)
在公式(5)中,ω为惯性权重,c1个体学习因子,c2为全局学习因子,i为第i个粒子,j为每个粒子的第j维,1≤i≤nn,1≤j≤d,px(i,j)kk为第kk次迭代时第i个粒子第j维的位置;v(i,j)kk为第kk次迭代时第i个粒子第j维的速度,r1和r2为0-1之间的随机数,pb(i,j)kk为第kk次迭代时粒子在搜索过程中的个体最优位置,pg(i,j)kk为第kk次迭代时粒子在搜索过程中的全局最优位置,pg(i,j)kk取自改进的多目标粒子群优化算法建立的外部档案;
当kk>=t/2时,采用公式(6)更新粒子速度,
在公式(6)中,c3为扰动学习因子,r3为0-1之间的随机数,pc(i,j)kk为第kk次迭代时扰动粒子的位置且初始值为0,其中,采用公式(6)更新粒子速度后,pc(i,j)kk每次从外部档案中随机选取且不和pg(i,j)kk相同。
在所述改进的多目标粒子群优化算法中,ω=0.9,c1=c2=c3=1.8。标准多目标粒子群优化算法见参考文献:c.a.c.coello,g.t.pulido,m.s.lechuga.handlingmultipleobjectiveswithparticleswarmoptimization[j].ieeetransactionsonevolutionarycomputation,2004,8(3):256-279。
在所述多属性决策方法中,设多属性决策问题的方案集为s={s1,s2,…,ssn},属性集为q={q1,q2,…,qqm}。方案集s即为改进的多目标粒子群优化算法得到的非劣解集;属性集q即为待优化的目标集合,也即本专利所述的性能变量集合。对于方案si按属性qj进行测度,得到si关于qj的属性值为avij,i=1,2,…,sn,j=1,2,…,qm。矩阵av=(avij)sn×qm称为方案集s对属性集q的决策矩阵。通常不同属性的量纲也是不同的,为统一计算,必须对决策矩阵进行规范化,规范化如式(7)所示。
规范化后的决策矩阵为rv=(rvij)sn×qm,属性权重向量为aw={aw1,aw2,…,awqm},其中,
本专利以机组负荷区间[293,330]、煤质系数区间[1.81,2.20]为例,进行燃烧优化应用实验。从历史数据库中选出符合此工况分区的训练数据集(1200条数据)和测试数据集(600条数据),分别计算出策略1的燃烧优化规则和策略2的lssvr模型。
在约束分级模糊关联规则算法中,将nox排放的权重等级设为1级,锅炉效率的权重等级设为2级,策略1得到的燃烧优化规则如表7所示,其中,操作变量也仅列出周界风a层挡板开度和燃尽风ccofa层挡板开度。
表7优化规则结果
为了使得到的优化规则能在实际锅炉燃烧过程中被更好地理解和应用,再用取中值的方法把性能变量nox排放的模糊区间转变成具体的数值,实际优化规则如表8所示。
表8实际优化规则
在测试数据集上,应用策略1得到的优化规则,与测试数据集中原有历史运行数据做比较,nox排放平均值下降69.47mg/m3,锅炉效率平均值提升0.09%。
在测试数据集上,利用公式(4)计算策略2的非劣解集,得到非劣解集后,在多属性决策中,将nox排放的权重设为0.7,锅炉效率的权重设为0.3,再进一步计算每一种工况的唯一最优解,策略2计算时间总共为251.356s,得到的部分工况的唯一最优解如表9所示。与测试数据集中原有历史运行数据做比较,nox排放平均值下降73.97mg/m3,锅炉效率平均值提升0.31%。
表9策略2部分优化结果
由于在燃煤电站dcs数据库中,每个测点的运行数据通常每秒保存并处理一次,所以,含有600条数据的测试数据集,在现实中可以认为近似需要600s的计算时间。将两种数据驱动策略相融合,应用于测试数据集上,优化整体效果可以近似如图5所示。
再根据式(9)进行计算,其中,
以上对本发明做了示例性的描述,应该说明的是,在不脱离本发明的核心的情况下,任何简单的变形、修改或者其他本领域技术人员能够不花费创造性劳动的等同替换均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!