基于嵌入式平台的海量地理信息数据的存储与检索方法与流程
本发明属于数据调度算法的技术领域,特别涉及一种基于嵌入式平台的海量地理信息数据的存储与检索方法。
背景技术:
随着地理信息技术、测绘技术的发展,地理信息数据的数据量和质量得到了飞速提高,传统的地理信息数据存储算法和调度算法使用典型的文件方式或者大型数据库管理地理信息数据,会导致软件规模大、地理信息数据调度慢、显示数据刷新慢,只可以在大型服务器端、pc机使用,由于嵌入式平台的软件规模小、文件系统简单、处理器性能弱等特点,因此在嵌入式环境下就无法实现海量地理信息数据的有效存储和读取调度,极大地影响地理信息软件在嵌入式环境下的使用。
技术实现要素:
本发明的目的是:提供一种基于嵌入式平台的海量地理信息数据的存储与检索方法,实现在嵌入式平台下,可以针对大规模的海量地理信息数据进行快速的数据调度与显示。
为解决此技术问题,本发明的技术方案是:
基于嵌入式平台的海量地理信息数据的存储与检索方法,所述的存储与检索方法针对地理信息数据进行分区存储和分类存储相结合;所述的分区存储将数据进行分区域建立索引,在指定范围内调度显示指定的地理信息数据;所述的分类存储为海量地形数据和栅格数据分别采用不同的存储组织形式,地形数据采用差值整数化存储方式;栅格数据采用直接解压缩的压缩格式存储。
所述的存储与检索方法中海量地理信息数据的检索方式为将多个分区文件组织为一个文件,对每个文件建立索引,索引包含文件中的分区数据信息。
所述的分区存储具体调度方式为:在不同显示比例尺下,调取不同级别的地理信息数据。
所述的差值整数化存储方式具体为:将双精度类型的地形数据做差值转化为整型数据进行存储。
所述的直接解压缩的压缩格式为dds格式。
所述的索引文件包含的信息为:索引文件的文件名、瓦片的四个角点的经纬度坐标和海拔高度。
所述的检索方法具体为:通过索引文件中的分区数据信息,得到需要调度的分区数据内容,再读取地理信息数据。
本发明的有益效果是:
本发明的基于嵌入式平台的海量地理信息数据的存储与检索方法,设计了海量地理信息数据的分区显示原则和基于文件索引的海量地理信息检索方式,设计了海量地形数据和栅格数据的存储组织形式,实现了嵌入式平台下大规模的海量地理信息数据的存储、读取、调度;并且大大提高了地理信息数据的读取和调度速度,为嵌入式领域的地理信息软件的研发提供了关键的基础技术,促进了地理信息软件在嵌入式平台下的应用范围。
附图说明
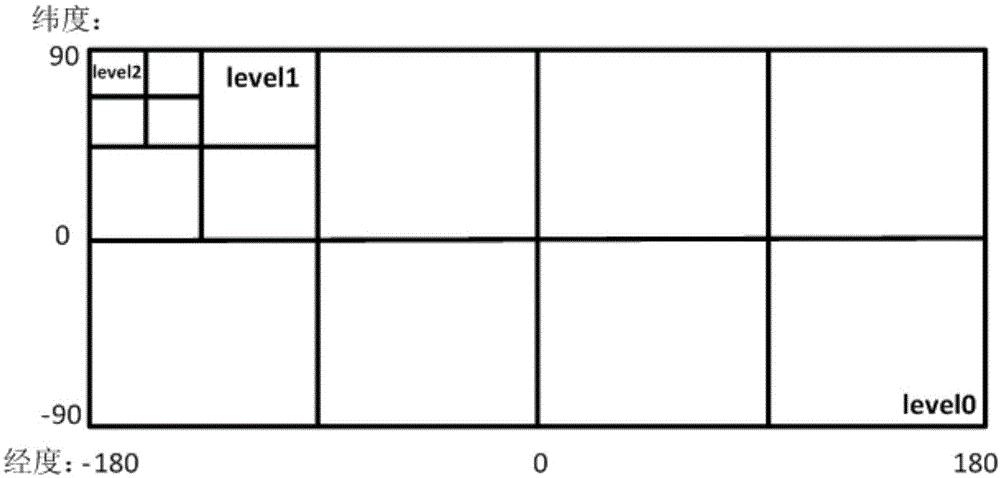
图1地理信息数据lod分级图;
图2本发明的地理信息数据文件命名图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明:
本发明的基于嵌入式平台的海量地理信息数据的存储与检索方法,包括:海量地理信息数据的分区方式,海量地理信息数据的检索方式、海量地形数据的存储组织形式、海量栅格数据的存储组织形式。
海量地理信息数据的分区方式:针对地理信息数据进行分区域建立索引,在指定范围内调度显示指定的地理信息数据。根据嵌入式平台的实际显示能力,对全球范围内的地理信息数据进行lod(levelofdetail)分级处理。在不同显示比例尺下,调取不同级别的地理信息数据。
海量地理信息数据的检索方式:基于提高文件读取速度的考虑,对数据进行了重新组织聚合,将多个分区文件组织为一个文件。在嵌入式环境下,需要在很短的时间内实现海量地理信息数据的调度,因此需要在调度分区数据之前,建立索引文件。通过索引文件中的分区数据信息,得到需要调度的分区数据内容,再读取地理信息数据。
海量地形数据的存储组织形式:在嵌入式环境下,过大的地形数据量可能会无法存储以及严重影响数据更新速度。因此对地形数据采用差值整数化处理。
海量栅格数据的存储组织形式:由于dds格式的数据压缩格式不需要cpu解压就可以直接传到显存,而且到了显存之后也不会解压,这极大地减少了显存的使用量,并且提高了纹理加载速度,有很大的优势。因此在嵌入式环境下,采用gpu可以直接解压缩的dds压缩格式作为栅格数据的格式,提高解压缩效率。
具体描述如下:
海量地理信息数据的分区方式:海量地理信息数据的内容种类很多,包含地形、栅格、矢量等内容,覆盖全球范围的地理信息数据量很大,可以达到tb量级。在此量级下,嵌入式环境下需要针对地理信息数据进行分区域建立索引,对全球范围内的地理信息数据进行lod(levelofdetail)分级处理,并且根据实际显示器的显示能力,实现不同显示比例尺下显示不同层级的地理数据。
地球按照正球体的模型建模,地理信息数据按照经度、纬度为坐标轴组织。将地理信息数据在全球范围内分八块,如图1所示。然后在每一块内,再平均分四块,依次拆分。最终形成初始层级为8块,然后每一层级向下拆分4块的lod数据分区方式。
海量地理信息数据的检索方式:地理信息数据按照分区原则定义了每个分区数据的范围,在数据信息很大的情况下,地理信息数据的各个分区文件个数会非常大,在11级全球范围内,会有44739240个分区数据。在嵌入式环境下,操作系统对文件的总个数有限制,并且文件个数过多,在程序运行时会造成频繁的文件打开关闭操作,影响地理信息数据的调度速度和显示速度。基于提高文件读取速度的考虑,对分区文件进行了重新组织聚合,将多个分区文件组织为一个文件。按照四叉树的思想对数据进行重组。
举例:如图2所示,将第4级,x坐标为6,y坐标为47的分区数据、以及向下分6级的四叉树分区数据,将10920个分区数据组织为一个文件,文件以4_6_47_6为命名。
海量地理信息数据的检索方式:在嵌入式环境下,需要在很短的时间内完成对海量地理信息数据的调度,因此在调度分区数据时,需要建立索引文件。从索引文件中获取瓦片的信息,再读取地理信息数据。索引文件主要包含瓦片的四个角点的经纬度坐标和海拔高度,索引文件的文件名采用聚合文件名。在软件初始化时,首先读取索引文件信息,构建数据树,通过数据树的瓦片信息进行瓦片数据的调度和读取。
海量地形数据的存储组织形式:在嵌入式环境下,由于硬盘的存储空间有限,无法存储全部的双精度类型的地形数据,并且由于更新条件有限,过大的地形数据量会严重影响数据加载更新速度。因此对地形数据进行差值处理,然后处理为双字节的整数。
举例:假如某点的高度是2565.36米,假如使用双精度类型存储时需要8个字节,因为地形数据是采用分区的方式存储的,因此采用差值存储并且整数化处理,取此块数据的左下角2142.12米为基准,两者的差值是(2565.36-2142.12)=423.24米,然后差值423.24*100倍数=42324。short类型的存储空间是0-65536,可以存储此值,占据2个字节。
海量栅格数据的存储组织形式:在嵌入式环境下,由于存储空间有限,栅格数据需要采用压缩算法,减少存储空间。传统的图像压缩算法有jpg、png等压缩算法,在压缩比方面满足要求,但是在嵌入式环境下的解压缩效率不高,影响嵌入式下的数据读取速度。由于dds的压缩优势。因此采用dds压缩格式作为栅格数据的格式。
举例:在4_6_47_6的栅格文件中,首先存储的是文件信息,包含数据类型、版本信息、四叉树层级、瓦片尺寸,瓦片尺寸指的是栅格的像素尺寸,嵌入式环境下采用256*256,可以满足速度和效果的平衡。然后是从4-6-47的瓦片开始,向下分四块,采用左上、右上、左下、右下的顺序排列,依次采用此顺序存储瓦片数据。采用索引方式,首先存储的是数据内容的偏移地址和长度,然后再读取栅格数据。
- 还没有人留言评论。精彩留言会获得点赞!