一种社会热点与商品品类的匹配方法与流程
本发明涉及一种匹配方法,特别是关于一种社会热点与商品品类的匹配方法。
背景技术:
目前现有的电商平台中对商品与社会热点关联的挖掘并没有一个系统的算法,而是通过店主本身对时事热点情况的掌握,丰富与之相关的商品描述信息。社会热点话题的获取也是通过店主自己的了解。
现有的方法虽然可以满足一部分用户的需求,但是存在许多不足。一方面,店家通过自己对时事热点的掌握修改商品描述需要一定的人力成本,另一方面,店家本身对于热点的了解不够全面,许多商家不了解的热点话题往往是顾客们热衷的话题。另外,店家自身获取信息的途径具有一定的滞后性,而许多热点话题也是具有时效性的,需要根据热点话题的变化对商品描述实时更新,这对于目前的方法是十分困难的。
技术实现要素:
针对上述问题,本发明的目的是提供一种社会热点与商品品类的匹配方法,其能快速准确地找关联,并及时提供给有需求的店家,丰富店家的商品描述,提高商品销售效率。
为实现上述目的,本发明采取以下技术方案:一种社会热点与商品品类的匹配方法,其包括以下步骤:1)构建商品品类知识图谱;2)获取微博热门话题内容;3)将商品品类知识图谱与热门话题内容进行匹配:对于每一个实时产生的热门话题,获得该话题对应的微博内容,对于其中涉及到的知识图谱中的不同实体,采用不同的匹配方法,将匹配结果在已构建好的知识图谱上进行检索,得到最终的匹配得分;4)对商品标题与微博内容进行文本匹配;5)将商品品类知识图谱与热门话题内容的匹配结果与商品标题与微博内容的匹配结果相结合,得到最终的匹配结果。
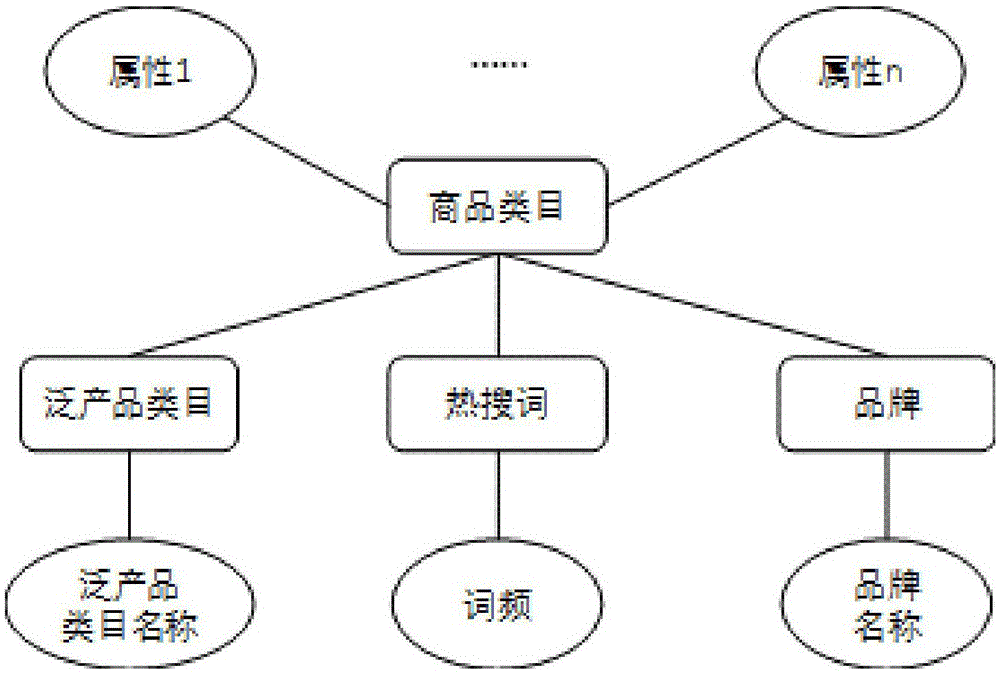
进一步,所述步骤1)中,商品品类知识图谱包括商品品类、三个实体和商品品类属性;每一个商品品类与三个实体关联,三个实体分别是泛产品品类、热搜词和品牌。
进一步,所述泛产品品类是将多个相近的品类集中起来,作为匹配过程中的一个整体,减少匹配品类总数,提高话题匹配成功的概率;所述热搜词是用户在搜索指定商品时输入的搜索词,热搜词具有词频的属性,不同的热搜词被使用的次数不同,使用次数高的热搜词更能够代表对应的品类,在匹配过程中匹配成功之后贡献的得分也相应更高。
进一步,所述步骤2)中,微博数据通过网络爬取,抓取最新的热搜微博内容;这些微博内容围绕同一个微博热搜榜话题,不仅包括话题发起者的微博,同时也包括微博用户对于该话题的相关评论,以及引用该话题的其他微博;将这些微博整理为文本,对其进行除噪过滤,将过滤之后的所有微博内容连接在一起,作为此话题对应的用于分析的微博内容,进而作为语料文本进行匹配。
进一步,所述过滤方法包括以下步骤:2.1)去除所有的标点符号以及表情非常用文本符号;2.2)去除所有以“@”开头以及冒号结尾的字符串;2.3)去除以“#”开头与结尾的字符串。
进一步,所述步骤3)中,匹配结果在已构建好的知识图谱上的检索方法如下:(1)泛产品品类识别检索:泛产品品类名称部分检索累计得分为scoreg1,体识别结果在知识图谱中检索的累计得分为
进一步,所述泛产品品类名称部分检索中,使用hanlp汉语言处理包对微博内容进行分词,并将所有的泛产品品类名称作为词典对分词结果进行过滤;过滤后出现次数最多的前十个词,去除其中出现次数不超过1次的词,用这些词在知识图谱中的泛产品品类名称部分进行检索,即与每一个商品品类下相关的所有泛产品品类名称进行匹配,每匹配成功,便为该品类累计得分
进一步,所述实体识别结果在知识图谱中检索:采用bidirectionallstm-crf模型,识别出微博文本中所有类型为泛产品品类的实体;将得到的实体在知识图谱中的泛产品品类名称部分进行检索,如果识别出的实体在之前hanlp分词结果中出现,则不再重复计算。
进一步,所述步骤4)中,商品标题与微博内容匹配方法包括以下步骤:4.1)确定待匹配的文本;4.2)采用knrm[1]模型,knrm通过引入核函数机制,在多个不同相似度下计算每个词的特征向量,由词的特征向量构成句子的特征向量;4.3)将商品标题与微博内容文本的词向量矩阵计算相似度,进而得到相似度矩阵;4.4)在相似度矩阵上使用多个不同的核函数,在多种相似度水平上,分别计算微博文本内各个词对商品标题中词的相关性贡献值,得到商品标题中各词的软词频;4.5)将各词的软词频加和得到用于排序的特征,通过多层感知机得到最终的匹配分数。
进一步,所述步骤5)中,商品品类知识图谱与热门话题内容匹配结果由微博文本与商品泛产品类目名称、品牌名称、热搜词与商品属性的精确匹配这四部分匹配结果综合得到,将这四部分匹配结果通过权重相加得到总得分;并且商品标题与微博内容直接采用文本匹配的方式,使用knrm模型得到匹配结果的得分;将四部分匹配结果通过权重相加的总得分与knrm模型得到匹配结果得分相结合,得到最终得分,将最终分数归一化到[0,1]区间,若分数大于0.5则认为匹配,否则不匹配。
本发明由于采取以上技术方案,其具有以下优点:本发明根据实时获取的微博信息,以及已有的商品信息,可以快速准确地找到这样的关联,并及时提供给有需求的店家,丰富店家的商品描述,提高商品销售效率。
附图说明
图1是本发明的商品品类知识图谱示意图;
图2是本发明的知识图谱检索流程示意图;
图3是本发明的knrm结构示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述。
如图1所示,本发明提供一种社会热点与商品品类的匹配方法,其包括以下步骤:
1)构建商品品类知识图谱;
如图1所示,商品品类知识图谱包括商品品类、三个实体和商品品类属性。每一个商品品类与其它三个实体关联,三个实体分别是泛产品品类、热搜词和品牌,其中商品品类本身还具有一些品类本身特有的属性,热搜词还有词频属性。具体的实体含义如下:
泛产品品类:将多个相近的品类集中起来,作为匹配过程中的一个整体,可以减少匹配品类总数,提高话题匹配成功的概率。原始数据给出了所有的商品品类,但是在这些商品品类中有很多品类对于顾客的需求没有太大的差异,如表1中品类名称所示。
表1泛产品品类示例
表1中呈现了三组泛产品品类名称,它们分别属于休闲娱乐、vr设备、保温壶这三个商品品类。
品牌:对于每一个商品品类,都拥有许多商品品牌;对于品牌名的匹配可以准确找到关联的商品品类。比如卫衣品类下有诸如丹杰仕、乔丹、朵比妮等品牌名称。在微博文本中,许多商家的官方微博内容中经常会涉及到许多品牌名,例如dior官博发布的微博:“青年演员身着dior迪奥二零一八早秋系列精彩演绎时尚街拍……”中提到的品牌名dior。
热搜词:用户在搜索指定商品时输入的搜索词。比如对于中央空调品类下有关的热搜词有家用中央空调、美的中央空调、吸顶空调等。热搜词和微博内容类似,都有口语化现象,因此也更容易在微博文本中匹配成功。加入热搜词之后,大部分的热门话题都与部分商品关联成功。热搜词具有词频的属性,不同的热搜词被使用的次数不同,使用次数高的热搜词更能够代表对应的品类,在匹配过程中匹配成功之后贡献的得分也相应更高。
商品品类属性:除了几个与商品品类相关的实体之外,商品品类本身也有若干属性。比如品类t恤下拥有属性衬衫领形、袖长等属性;品类珍珠胸针下拥有属性镶嵌材质等。
2)获取微博热门话题内容;
微博数据通过网络爬取,抓取最新的热搜微博内容。这些微博内容围绕同一个微博热搜榜话题,不仅包括话题发起者的微博,同时也包括微博用户对于该话题的相关评论,以及引用该话题的其他微博。将这些微博整理为文本,对其进行除噪过滤,将过滤之后的所有微博内容连接在一起,作为此话题对应的用于分析的微博内容,进而作为语料文本进行匹配。
过滤方法如下:
2.1)去除所有的标点符号以及表情等非常用文本符号。
发微博或者评论微博的用户用语具有口语化以及随意性等特点,甚至有时整篇内容都是没有意义的符号。比如表示震惊的情绪时,可能会使用大量的感叹号,以及表达一些丰富的情感时,常使用一些特殊的表情符号,这些加强情感的符号对于商品品类的匹配没有较多的帮助,属于文本噪音,需要删去。
2.2)去除所有以“@”开头以及冒号结尾的字符串。
微博内容中一个非常鲜明的特点就是当微博涉及到其他用户或者是想让其他用户看到这篇微博时,会使用@加上该用户的昵称。除了一些官方微博以外,大部分用户的昵称对于商品的匹配过程是没有贡献的,甚至会产生极大的误导。因此用正则表达式匹配的方法将这些昵称删除。
2.3)去除以“#”开头与结尾的字符串。
与昵称问题类似,以“#”开头结尾的往往表示一个话题的名称。正常情况下,在一个话题中使用这样的符号引用另一个与之相似的话题并不会有不良影响,但许多微博用户并不遵循这种相似性规则,甚至有的人喜欢在某话题下面引用与之毫不相关的话题,这便对不同话题之间的比对造成干扰。所以删除类似这样的话题引用。
3)将商品品类知识图谱与热门话题内容进行匹配:对于每一个实时产生的热门话题,获得该话题对应的微博内容。对于其中涉及到的知识图谱中的不同实体,采用不同的匹配方法,将匹配结果在已构建好的知识图谱上进行检索,得到最终的匹配得分。
如图2所示,匹配结果在已构建好的知识图谱上的检索方法如下:
(1)泛产品品类识别检索:
(1.1)使用hanlp汉语言处理包对微博内容进行分词,并将所有的泛产品品类名称作为词典对分词结果进行过滤。过滤后出现次数最多的前十个词,去除其中出现次数不超过1次的词。用这些词在知识图谱中的泛产品品类名称部分进行检索,即与每一个商品品类下相关的所有泛产品品类名称进行精确匹配。每匹配成功,便为该品类累计得分
其中,
(1.2)对微博内容进行命名实体识别(ner):采用bidirectionallstm-crf模型,识别出微博文本中所有类型为泛产品品类的实体。将得到的实体在知识图谱中的泛产品品类名称部分进行检索。为了避免重复,如果识别出的实体在之前hanlp分词结果中出现,则不再重复计算。实体识别结果在知识图谱中检索的累计得分
其中,
(2)品牌名称识别检索:
品牌名称检索识别部分直接使用步骤(1.2)中的实体识别结果,识别出所有类型为品牌的实体。将这些实体在知识图谱中进行检索,与每个商品品类下相关的所有品牌进行比对,累计得分scoreb为:
其中,
(3)热搜词识别检索:
热搜词不同于泛产品品类名称与品牌名称,它的内容往往很随意,比如对于品类项链,有热搜词迪士尼黄金苹果吊坠、soinlove钻石旗舰店,这样的热搜词里面不仅可能包含泛产品品类名称和品牌名称,还可能包含其他的实体,例如迪士尼和旗舰店。因此无法使用简单的分词技术或者命名实体识别方法得到满意的结果。
对于所有的商品品类,找到该品类下相关的所有热搜词,将它们在微博内容中进行检索,检索结果累计得分scoreh为:
其中,valueh代表第h个在微博内容中出现热搜词的词频;sl表示该品类具有的热搜词数量,由于热搜词数据中不同品类下拥有的热搜词数量不同,热搜词数量多的品类在匹配中有可能会得到更高的分数,但实际上热搜词数量多的品类并不代表与话题有更多的关联,而是代表该品类在用户搜索过程中的表述形式更多样。因此,为了降低热搜词数量过多或过少对匹配得分造成的偏差,在原匹配分数上除以
(4)商品属性识别检索:
由于不同商品品类属性种类各异,属性值在表达方式上也不规范,因此匹配过程与热搜词的匹配过程类似。对于所有的商品品类,找到品类具有的属性值,将他们再微博内容中进行检索,检索结果累计得分scorea为:
其中,
(5)根据泛产品品类识别检索、品牌名称识别检索、热搜词识别检索和商品属性识别检索结果,得到最终匹配得分score为:
4)为了考虑语义信息的影响,对商品标题与微博内容进行文本匹配:
商品标题与微博内容匹配采用文本匹配的方法,使用了机器学习的方法。
4.1)确定待匹配的文本;
微博热门话题采用整理好的微博正文内容文本即可,而在商品品类方面,采用商品标题文本,因为大部分的商品标题都是由商家书写,同时没有绝对规范的格式,与微博内容中常见的日常用语风格相近。对于某一商品品类,将该品类下的若干条商品标题连接起来形成待匹配的文本。
4.2)采用knrm[1]模型,相比于传统的基于交互的匹配模型drmm[2],knrm通过引入核函数机制,在多个不同相似度下计算每个词的特征向量,由每个词的特征向量构成整个句子的特征向量,其模型结构如图3所示。
4.3)将商品标题与微博内容文本的词向量矩阵计算相似度,进而得到相似度矩阵。
4.4)在相似度矩阵上使用多个不同的核函数,在多种相似度水平上,分别计算微博文本内各个词对商品标题中词的相关性贡献值,得到商品标题中各词的软词频(soft-tf);
4.5)将各词的soft-tf加和得到用于排序的特征,通过多层感知机得到最终的匹配分数。
5)将商品品类知识图谱与热门话题内容的匹配结果与商品标题与微博内容的匹配结果相结合,得到最终的匹配结果;
其中,商品品类知识图谱与热门话题内容匹配结果由上述四个步骤中的四部分匹配结果综合得到,分别是微博文本与商品泛产品类目名称、品牌名称、热搜词与商品属性的精确匹配,将这四部分匹配结果通过权重相加得到总得分。另外,商品标题与微博内容直接采用文本匹配的方式,使用knrm模型得到匹配结果的得分。将四部分匹配结果通过权重相加的总得分与knrm模型得到匹配结果得分相结合,得到最终得分,将最终分数归一化到[0,1]区间,若分数大于0.5则认为匹配,否则不匹配;
结合时采用的权重为通过实验取评测指标最高时对应的权重,该权重对应的结合后得分即为最终得分;其中,评测指标为预先设定的指标,具体准确度、召回率与精确率。
综上所述,本发明解决了商品品类与微博热门话题的关联问题,通过实验证明了本发明匹配方法的有效性,可以挖掘出微博话题与商品品类的关联。
上述各实施例仅用于说明本发明,各个步骤都是可以有所变化的,在本发明技术方案的基础上,凡根据本发明原理对个别步骤进行的改进和等同变换,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!