一种用电模式提取方法和系统与流程
本发明涉及的是一种用电模式提取方法,具体涉及的是一种电力行业中用电模式提取方法。
背景技术:
在电力行业中,企业用电模式的变化往往反映了企业经营状况变化。经营情况较好的企业,其用电模式呈现稳中有升的态势;经营情况较差的企业,往往存在着用电量骤减,甚至反复波动的情况。此外,受国家法律法规等因素的影响,一个行业内企业的用电量变化往往存在着某些共同的变化趋势。
因此,行业用电模式的演变反映了行业内经营状况。而电力公司传统的人工分析方式,存在着效率低下,分析数据量有限的缺陷。因此电力公司急需一种切实高效的用电模式的提取方法。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的缺陷,提供一种效率更高、更适合在企业用电量相似度比较高的情况下提取出目标行业企业用电模式的方法。
为解决上述技术问题,本发明采用以下技术方案:
在一个方面,本发明提供了一种用电模式提取方法,包括以下步骤:
步骤一、建立目标数据集:根据目标行业的用电企业在特定年份与月份对应的用电量数据建立企业用电量序列rec,rec={<month1,power1>,<month2,power2>,……
<monthn,powern>},1≤n≤12,monthn代表第n个月,powern代表第n个月的电量;
步骤二、对每个企业的用电量序列计算相邻两个月用电量的斜率得到斜率特征序列reckt,reckt={k1,k2,……,kn},1≤n≤11;
步骤三、判断若相邻斜率ki和ki+1满足如ki*ki+1<0或
步骤四、根据获得的拐点序列rec建立用电企业的特征元组序列rectuple,rectuple={tuple1,tuple2,……,tuplen},其中2≤n≤11;其中两两拐点之间用特征元组tuplei表示,tuplei={k,t},其中k表示两个拐点之间的斜率,t表示当前拐点与前一个拐点之间的月份差;
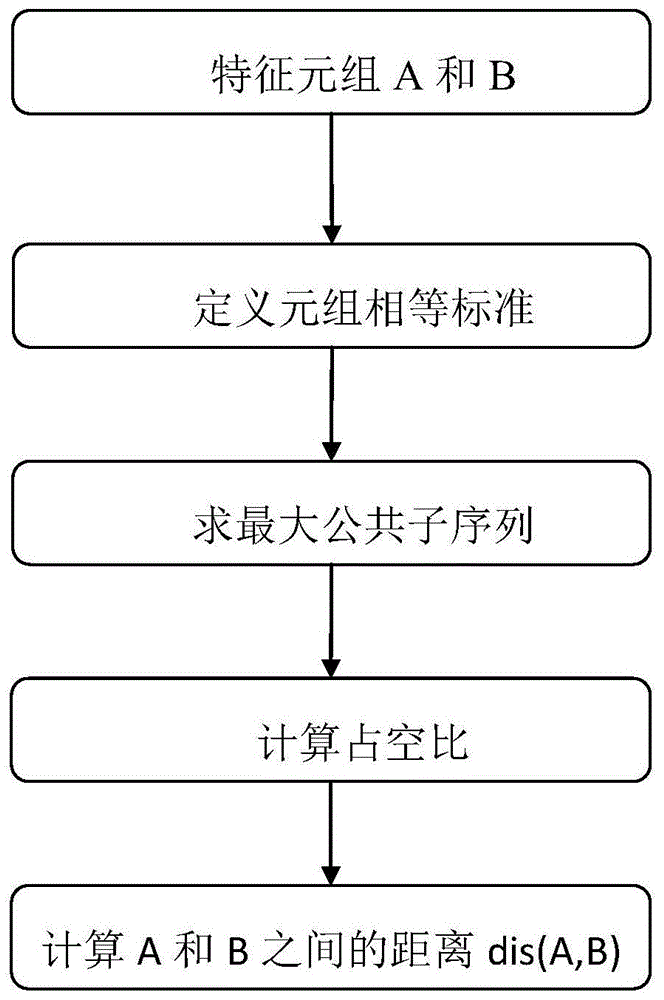
步骤五、基于最大公共子序列计算两个特征元组之间的距离;
步骤六、对于企业用电量序列进行基于距离的聚类并提取每个聚簇的主流分布区间得到目标行业的用电模式。
在以上技术方案中,计算相邻两个月用电量的斜率ki的表达式如下:
在以上技术方案中,步骤五中基于最大公共子序列计算两个特征元组之间的距离的方法如下:
步骤5.1:分别针对两个用电企业的特征元组序列rectuplea={tuple1,tuple2,……,tuplen}和rectupleb={tuple1,tuple2····tuplem}确定两者的公共子序列:
所述公共子序列表示如下:
comseqab={a:<tuple1,a,tuple2,a,……,tuplek,a>,
b:<tuple1,b,tuple2,b,……,tuplek,b>}。
步骤5.2:分别计算特征元组rectuplea和rectupleb的占空比,所述占空比为特征元组序列对应的公共子序列的拐点持续时间之和比上特征元组序列中拐点持续时间之和;
步骤5.3:根据两个用电企业用电量a和b的特征元组序列、特征元组序列的占空比以及最大公共子序列计算用电量a和b的距离dis(a,b),表达式如下:
其中,α和β是两部分的权重比例,满足α+β=1且α≥0,β≥0;len(rectuplea)代表特征元组的长度。
在另一个方面,本发明提供了一种用电模式提取系统,包括:
建立目标数据集模块,用于根据目标行业的用电企业在特定年份与月份对应的用电量数据建立企业用电量序列rec,rec={<month1,power1>,<month2,power2>,……
<monthn,powern>},1≤n≤12,monthn代表第n个月,powern代表第n个月的电量;
斜率特征序列生成模块,用于对每个企业的用电量序列计算相邻两个月用电量的斜率得到斜率特征序列reckt,reckt={k1,k2,……,kn},1≤n≤11;
拐点序列生成模块,用于判断若相邻斜率ki和ki+1满足如ki*ki+1<0或
特征元组序列生成模块,用于根据获得的拐点序列rec建立用电企业的特征元组序列rectuple,rectuple={tuple1,tuple2,……,tuplen},其中2≤n≤11;其中两两拐点之间用特征元组tuplei表示,tuplei={k,t},其中k表示两个拐点之间的斜率,t表示当前拐点与前一个拐点之间的月份差;
距离计算模块,用于基于最大公共子序列计算两个特征元组之间的距离;
模式聚类模块,用于对于企业用电量序列进行基于距离的聚类并提取每个聚簇的主流分布区间得到目标行业的用电量较为相近。
本发明所达到的有益效果:
本发明采用了最大公共子序列的设计思想,使本发明方法更加适合同行业企业用电量比较相似的情况,从而为用户用电模式的提取提供更加正确的输入,为构建更加有效的模式提取模型奠定基础;
本发明通过引入了基于最大公共子序列的占空比来计算企业用电量之间的距离,直接求解企业用电量的相似度,且考虑最大公共子序列持续时间和整个特征元组序列的持续时间之比,方法更加简洁直观、效率高并且不失正确性,具有很强的适应性;
本发明基于给出的距离函数采用聚类方法进行用电模式提取,具有更高的效率。
附图说明
图1是本发明两个特征元组距离计算流程图;
图2是本发明用电模式提取流程示意图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例:
用电模式提取方法,包括以下步骤:
步骤一、建立目标数据集:根据目标行业的用电企业在特定年份与月份对应的用电量数据建立企业用电量序列rec,rec={<month1,power1>,<month2,power2>,……
<monthn,powern>},1≤n≤12,monthn代表第n个月,powern代表第n个月的电量;
原始数据集s如下,其中每个[……]代表一个企业十二个月的数据,每个(…,…)代表企业某个月的用电量:
第一个企业:
[(1,4153),(2,2954),(3,527),(4,2603),(5,4419),(6,1113),(7,3264),(8,3220),(9,4941),(10,4779),(11,462),(12,3959)];
第二个企业:
[(1,2134),(2,1918),(3,700),(4,69),(5,3120),(6,1061),(7,417),(8,2070),(9,1669),(10,1014),(11,2845),(12,3357)];
第三个企业:
[(1,1458),(2,4360),(3,1088),(4,2423),(5,3306),(6,1521),(7,538),(8,1594),(9,66),(10,438),(11,3746),(12,657)];
第四个企业:
[(1,3196),(2,3364),(3,790),(4,3189),(5,4498),(6,714),(7,891),(8,688),(9,3041),(10,3826),(11,1362),(12,1227)];
第五个企业:
[(1,544),(2,3413),(3,4959),(4,2440),(5,851),(6,4667),(7,2935),(8,2609),(9,88),(10,2220),(11,1942),(12,3215)];
第六个企业:
[(1,3413),(2,4688),(3,3531),(4,1287),(5,4508),(6,210),(7,3376),(8,2855),(9,1477),(10,300),(11,4089),(12,3438)];
第七个企业:
[(1,2718),(2,4052),(3,2568),(4,4905),(5,3113),(6,948),(7,1819),(8,4609),(9,1850),(10,3688),(11,1475),(12,1986)];
第八个企业:
[(1,3212),(2,4912),(3,761),(4,3175),(5,431),(6,2716),(7,367),(8,4065),(9,4623),(10,591),(11,2177),(12,1831)];
第九个企业:
[(1,4220),(2,1477),(3,3718),(4,1846),(5,1682),(6,3054),(7,4983),(8,3289),(9,1613),(10,2612),(11,3658),(12,1213)];
第十个企业:
[(1,2050),(2,3177),(3,363),(4,4603),(5,4588),(6,170),(7,1976),(8,2833),(9,98),(10,3456),(11,2512),(12,3666)];
第十一个企业:
[(1,4538),(2,3637),(3,1615),(4,2712),(5,220),(6,3339),(7,3272),(8,3868),(9,2053),(10,3952),(11,1568),(12,4229)];
第十二个企业:
[(1,3719),(2,206),(3,3539),(4,1156),(5,1473),(6,4719),(7,1661),(8,680),(9,4696),(10,2677),(11,4719),(12,4285)];
第十三个企业:
[(1,3970),(2,3575),(3,1875),(4,1456),(5,1026),(6,4320),(7,4926),(8,429),(9,3861),(10,1122),(11,2674),(12,1745)];
第十四个企业:
[(1,4480),(2,4136),(3,4829),(4,620),(5,3100),(6,3305),(7,3193),(8,942),(9,255),(10,1327),(11,3657),(12,378)];
第十五个企业:
[(1,2216),(2,359),(3,4556),(4,1559),(5,2663),(6,1148),(7,3641),(8,2395),(9,447),(10,4900),(11,1000),(12,1323)]。
步骤二、对每个企业的用电量序列计算相邻两个月用电量的斜率得到斜率特征序列reckt,reckt={k1,k2,……,kn},1≤n≤11;
计算相邻两个月电量的斜率
步骤三、判断若相邻斜率ki和ki+1满足如ki*ki+1<0或
在判断拐点时考虑到起始月份1月份前面没有数据,终止月份12月份后面没有数据;直接将1月份数据和12月份数据从拐点中抹去会损失部分模式,因此将1月份和12月份规定为拐点。
根据本步骤计算出每个企业的拐点序列如下,在本实施例中ε=0.6:
第一个企业:
[(1,4153.0),(3,527.0),(5,4419.0),(6,1113.0),(7,3264.0),(8,3220.0),(9,4941.0),(10,4779.0),(11,462.0),(12,3959.0)];
第二个企业:
[(1,2134.0),(2,1918.0),(3,700.0),(4,69.0),(5,3120.0),(6,1061.0),(7,417.0),(8,2070.0),(10,1014.0),(11,2845.0),(12,3357.0)];
第三个企业:
[(1,1458.0),(2,4360.0),(3,1088.0),(5,3306.0),(6,1521.0),(7,538.0),(8,1594.0),(9,66.0),(10,438.0),(11,3746.0),(12,657.0)];
第四个企业:
[(1,3196.0),(2,3364.0),(3,790.0),(4,3189.0),(5,4498.0),(6,714.0),(7,891.0),(8,688.0),(9,3041.0),(10,3826.0),(11,1362.0),(12,1227.0)];
第五个企业:
[(1,544.0),(2,3413.0),(3,4959.0),(5,851.0),(6,4667.0),(7,2935.0),(8,2609.0),(9,88.0),(10,2220.0),(11,1942.0),(12,3215.0)];
第六个企业:
[(1,3413.0),(2,4688.0),(4,1287.0),(5,4508.0),(6,210.0),(7,3376.0),(8,2855.0),(10,300.0),(11,4089.0),(12,3438.0)];
第七个企业:
[(1,2718.0),(2,4052.0),(3,2568.0),(4,4905.0),(6,948.0),(7,1819.0),(8,4609.0),(9,1850.0),(10,3688.0),(11,1475.0),(12,1986.0)];
第八个企业:
[(1,3212.0),(2,4912.0),(3,761.0),(4,3175.0),(5,431.0),(6,2716.0),(7,367.0),(8,4065.0),(9,4623.0),(10,591.0),(11,2177.0),(12,1831.0)];
第九个企业:
[(1,4220.0),(2,1477.0),(3,3718.0),(4,1846.0),(5,1682.0),(7,4983.0),(9,1613.0),(11,3658.0),(12,1213.0)];
第十个企业:
[(1,2050.0),(2,3177.0),(3,363.0),(4,4603.0),(5,4588.0),(6,170.0),(7,1976.0),(8,2833.0),(9,98.0),(10,3456.0),(11,2512.0),(12,3666.0)];
第十一个企业:
[(1,4538.0),(3,1615.0),(4,2712.0),(5,220.0),(6,3339.0),(7,3272.0),(8,3868.0),(9,2053.0),(10,3952.0),(11,1568.0),(12,4229.0)];
第十二个企业:
[(1,3719.0),(2,206.0),(3,3539.0),(4,1156.0),(5,1473.0),(6,4719.0),(7,1661.0),(8,680.0),(9,4696.0),(10,2677.0),(11,4719.0),(12,4285.0)];
第十三个企业:
[(1,3970.0),(2,3575.0),(3,1875.0),(5,1026.0),(6,4320.0),(7,4926.0),(8,429.0),(9,3861.0),(10,1122.0),(11,2674.0),(12,1745.0)];
第十四个企业:
[(1,4480.0),(2,4136.0),(3,4829.0),(4,620.0),(5,3100.0),(6,3305.0),(7,3193.0),(8,942.0),(9,255.0),(11,3657.0),(12,378.0)];
第十五个企业:
[(1,2216.0),(2,359.0),(3,4556.0),(4,1559.0),(5,2663.0),(6,1148.0),(7,3641.0),(9,447.0),(10,4900.0),(11,1000.0),(12,1323.0)]。
步骤四、根据获得的拐点序列rec建立用电企业的特征元组序列rectuple,rectuple={tuple1,tuple2,……,tuplen},其中2≤n≤11;其中两两拐点之间用特征元组tuplei表示,tuplei={k,t},其中k表示两个拐点之间的斜率,t表示当前拐点与前一个拐点之间的月份差;
对于任意一个记录的斜率特征reckt={k1,k2,……,kn},1≤n≤11,若相邻斜率ki和ki+1满足如ki*ki+1<0或
根据步骤三得到的拐点序列可以计算特征元组序列如下:
第一个企业:
[(-1813.0,2),(1946.0,2),(-3306.0,1),(2151.0,1),(-44.0,1),(1721.0,1),(-162.0,1),(-4317.0,1),(3497.0,1)];
第二个企业:
[(-216.0,1),(-1218.0,1),(-631.0,1),(3051.0,1),(-2059.0,1),(-644.0,1),(1653.0,1),(-528.0,2),(1831.0,1),(512.0,1)];
第三个企业:
[(2902.0,1),(-3272.0,1),(1109.0,2),(-1785.0,1),(-983.0,1),(1056.0,1),(-1528.0,1),(372.0,1),(3308.0,1),(-3089.0,1)];
第四个企业:
[(168.0,1),(-2574.0,1),(2399.0,1),(1309.0,1),(-3784.0,1),(177.0,1),(-203.0,1),(2353.0,1),(785.0,1),(-2464.0,1),(-135.0,1)];
第五个企业:
[(2869.0,1),(1546.0,1),(-2054.0,2),(3816.0,1),(-1732.0,1),(-326.0,1),(-2521.0,1),(2132.0,1),(-278.0,1),(1273.0,1)];
第六个企业:
[(1275.0,1),(-1700.5,2),(3221.0,1),(-4298.0,1),(3166.0,1),(-521.0,1),(-1277.5,2),(3789.0,1),(-651.0,1)];
第七个企业:
[(1334.0,1),(-1484.0,1),(2337.0,1),(-1978.5,2),(871.0,1),(2790.0,1),(-2759.0,1),(1838.0,1),(-2213.0,1),(511.0,1)];
第八个企业:
[(1700.0,1),(-4151.0,1),(2414.0,1),(-2744.0,1),(2285.0,1),(-2349.0,1),(3698.0,1),(558.0,1),(-4032.0,1),(1586.0,1),(-346.0,1)];
第九个企业:
[(-2743.0,1),(2241.0,1),(-1872.0,1),(-164.0,1),(1650.5,2),(-1685.0,2),(1022.5,2),(-2445.0,1)];
第十个企业:
[(1127.0,1),(-2814.0,1),(4240.0,1),(-15.0,1),(-4418.0,1),(1806.0,1),(857.0,1),(-2735.0,1),(3358.0,1),(-944.0,1),(1154.0,1)];
第十一个企业:
[(-1461.5,2),(1097.0,1),(-2492.0,1),(3119.0,1),(-67.0,1),(596.0,1),(-1815.0,1),(1899.0,1),(-2384.0,1),(2661.0,1)];
第十二个企业:
[(-3513.0,1),(3333.0,1),(-2383.0,1),(317.0,1),(3246.0,1),(-3058.0,1),(-981.0,1),(4016.0,1),(-2019.0,1),(2042.0,1),(-434.0,1)];
第十三个企业:
[(-395.0,1),(-1700.0,1),(-424.5,2),(3294.0,1),(606.0,1),(-4497.0,1),(3432.0,1),(-2739.0,1),(1552.0,1),(-929.0,1)];
第十四个企业:
[(-344.0,1),(693.0,1),(-4209.0,1),(2480.0,1),(205.0,1),(-112.0,1),(-2251.0,1),(-687.0,1),(1701.0,2),(-3279.0,1)];
第十五个企业:
[(-1857.0,1),(4197.0,1),(-2997.0,1),(1104.0,1),(-1515.0,1),(2493.0,1),(-1597.0,2),(4453.0,1),(-3900.0,1),(323.0,1)]。
步骤五、基于最大公共子序列计算两个特征元组之间的距离;
最大公共子序列的思想是指:对于两个序列a={x1,x2,……,xk,……xm,……,xp,……}和b={y1,y2,……,yt,……yv,……,yu,……yq},在a和b两个序列中满足xk=yt,xm,=yv,,xp=yu且其余元素均不相等,则a和b的公共子序列为{xk,xm,xp}或者{yt,yv,yu}。
若两个元组tuplep和tupleq,斜率kp,kq满足kp/kq∈[1-λ,1+λ],且持续时长tp,tq满足|tp-tq|/max(tp,tq)∈[0,a],则称两个元组为“公共”元组,其中0≤λ≤1。
对于特征元组序列rectuplea={tuple1,tuple2,……,tuplen}和rectupleb={tuple1,tuple2····tuplem},两者的公共子序列为comseqab={a:<tuple1,a,tuple2,a,……,tuplek,a>,b:<tuple1,b,tuple2,b,……,tuplek,b>}。
仅以本实施例中第一个企业和第二个企业的特征元组举例说明:
根据以下两个特征元组计算两者之间的距离步骤如下:
rectuplea:
(-1813.0,2),(1946.0,2),(-3306.0,1),(2151.0,1),(-44.0,1),(1721.0,1),(-162.0,1),(-4317.0,1),(3497.0,1)]
rectupleb:
(-216.0,1),(-1218.0,1),(-631.0,1),(3051.0,1),(-2059.0,1),(-644.0,1),(1653.0,1),(-528.0,2),(1831.0,1),(512.0,1)]
(一)求取两个特征元组的最大公共元组,方法如下:
利用最大公共子串的方法求解公共元组序列,即公共子串只要求
相对顺序一致,而不要求连续,可得公共元组序列为:
comseqab={a:<(2151.0,1),(1721.0,1),(3497.0,1)>,
b:<(3051.0,1),(1653.0,1),(1831.0,1)>}。
判断方法为:
根据本步骤其中λ=0.6,a=0.3;判断特征元组(2151,1)和(3051,
1)是否为公共元组的过程如下:
2151/3051=0.7∈[1-0.6,1+0.6]
(1-1)/max(1,1)=0∈[0,0.3]
因此,特征元组(2151,1)和(3051,1)是公共元组。其余以
此类推,可得公共元组序列comseqab={a:<(2151.0,1),(1721.0,1),(3497.0,1)>,b:<(3051.0,1),(1653.0,1),(1831.0,1)>}。
(二)求取两个特征元组的的占空比:
根据占空比的含义:公共子序列持续时间和整个特征元组序列的持续时间之比,通过公式
spaceta=(1+1+1)/(2+2+1+1+1+1+1+1)=0.33
spacetb=(1+1+1)/(1+1+1+1+1+1+1+2+1+1)=0.3
(三)求取两个特征元组的距离?此步可根据以上推导出来。
根据以下公式可计算出用电曲线ah和b之间的距离:
其中α=0.5,β=0.5;
其中len(rectupleb)的含义为rectupleb的长度。
步骤六、对于企业用电量序列进行基于距离的聚类并提取每个聚簇的主流分布区间得到目标行业的用电模式。
利用基于最大公共子序列的距离定义方法可以量化两个用电曲线之间的聚类。采用基于密度的无监督学习聚类方法,对企业用电数据进行聚类。生成若干个聚簇:c1,c2,……,ck.提取每个聚簇每个月用电的主流分布区间就构成了聚簇的用电模式:
pattern(ci)={<month1,mink1,maxk1>,<month2,mink2,maxk2>,……,<monthn,minkn,maxkn>},1≤n≤12.
由此,可以得到该行业某年的用电模式patternindustry{pattern(c1),……,pattern(ck)}。
本实施例中将以上数据分为三个聚簇。
第一个聚簇为:
[(-1813.0,2),(1946.0,2),(-3306.0,1),(2151.0,1),(-44.0,1),(1721.0,1),(-162.0,1),(-4317.0,1),(3497.0,1)],
[(1275.0,1),(-1700.5,2),(3221.0,1),(-4298.0,1),(3166.0,1),(-521.0,1),(-1277.5,2),(3789.0,1),(-651.0,1)],
[(-2743.0,1),(2241.0,1),(-1872.0,1),(-164.0,1),(1650.5,2),(-1685.0,2),(1022.5,2),(-2445.0,1)],
[(-344.0,1),(693.0,1),(-4209.0,1),(2480.0,1),(205.0,1),(-112.0,1),(-2251.0,1),(-687.0,1),(1701.0,2),(-3279.0,1)],
[(-395.0,1),(-1700.0,1),(-424.5,2),(3294.0,1),(606.0,1),(-4497.0,1),(3432.0,1),(-2739.0,1),(1552.0,1),(-929.0,1)]。
第二个聚簇为:
[(-216.0,1),(-1218.0,1),(-631.0,1),(3051.0,1),(-2059.0,1),(-644.0,1),(1653.0,1),(-528.0,2),(1831.0,1),(512.0,1)],
[(2902.0,1),(-3272.0,1),(1109.0,2),(-1785.0,1),(-983.0,1),(1056.0,1),(-1528.0,1),(372.0,1),(3308.0,1),(-3089.0,1)],
[(168.0,1),(-2574.0,1),(2399.0,1),(1309.0,1),(-3784.0,1),(177.0,1),(-203.0,1),(2353.0,1),(785.0,1),(-2464.0,1),(-135.0,1)]。
第三个聚簇为:
[(1127.0,1),(-2814.0,1),(4240.0,1),(-15.0,1),(-4418.0,1),(1806.0,1),(857.0,1),(-2735.0,1),(3358.0,1),(-944.0,1),(1154.0,1)],
[(-1461.5,2),(1097.0,1),(-2492.0,1),(3119.0,1),(-67.0,1),(596.0,1),(-1815.0,1),(1899.0,1),(-2384.0,1),(2661.0,1)],
[(-3513.0,1),(3333.0,1),(-2383.0,1),(317.0,1),(3246.0,1),(-3058.0,1),(-981.0,1),(4016.0,1),(-2019.0,1),(2042.0,1),(-434.0,1)]。
提取每个月的主流用电模式可以获得聚簇的用电特征:
第一个聚簇的用电特征为:
[(1,<-3512,-688>),(2,<-1831,3333>),(3,<-688,3051>),(4,<-2051,3051>),(5,<147,382>),(6,<147,382>),(7,<147,382>),(8,<147,382>),(9,<-431,382>),(10,<-431,382>)];
第二个聚簇的用电特征为:
[(1,<168,1127>),(2,<-2814,-2574>),(3,<1854,4240),(4,<-15,1854>),(5,<-4418,-3780>),(6,<177,1860>),(7,<-203,857>),(8,<-2735,2353>),(9,<785,3358>),(10,-2464,-944),(11,<-135,1154>)];
第三个聚簇的用电特征为:
[(1,<-2743,-344>),(2,<-1461,4197>),(3,<-4209,1097>),(4,<-2492,2480>),(5,<-277,3119>),(6,<-1881,1650>),(7,<-1685,596>),(8,<-1685,-277>),(9,<-766,1701>),(10,<-766,1701>),(11,<-3279,2661>)];
第四个聚簇的用电特征为:
[(1,<1275,2902>),(2,<-3272,2207>,(3,<-1700332>),(4,<-286,400>),(5,<-286,400>),(6,<-286,400>),(7,<-286,400>),(8,<-286,400>),(9,<-286,400>),(10,<-286,400>),(11,<-3089,511>)]。
本发明采用了最大公共子序列的设计思想,使本发明方法更加适合同行业企业用电量比较相似的情况,从而为用户用电模式的提取提供更加正确的输入,为构建更加有效的模式提取模型奠定基础。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!