一种针对以太坊智能合约的静态代码审计系统及方法与流程
本发明属于信息安全技术领域,具体涉及一种在区块链的以太坊平台上针对智能合约的静态代码审计系统及方法。
背景技术:
区块链技术狭义来讲,是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算方式。
以太坊是一个开源的有智能合约功能的公共区块链平台。通过其专用加密货币以太币提供去中心化的虚拟机来处理点对点合约。
智能合约是执行合约条款的计算机交易协议。它本质上就是一段可以执行的代码,当用户访问到该地址上时,智能合约将会自动运行。智能合约是公开的,区块链上的所有用户都可以看到基于区块链的智能合约。
目前已有不少基于区块链的以太坊平台上的智能合约应用,如社会经济平台的backfeed、去中心化预测市场augur和智能电网transactivegrid等,然而在不少应用的开发过程中,设计者只关注其功能性而未考虑其安全问题,导致应用存在有安全隐患,又由于智能合约的内容是公开的,任何人都可以分析其源码从而找到漏洞。
技术实现要素:
本发明的目的是克服上述现有技术的缺陷,提供一种在区块链的以太坊平台上针对智能合约的静态代码审计系统及方法。
本发明所提出的技术问题是这样解决的:
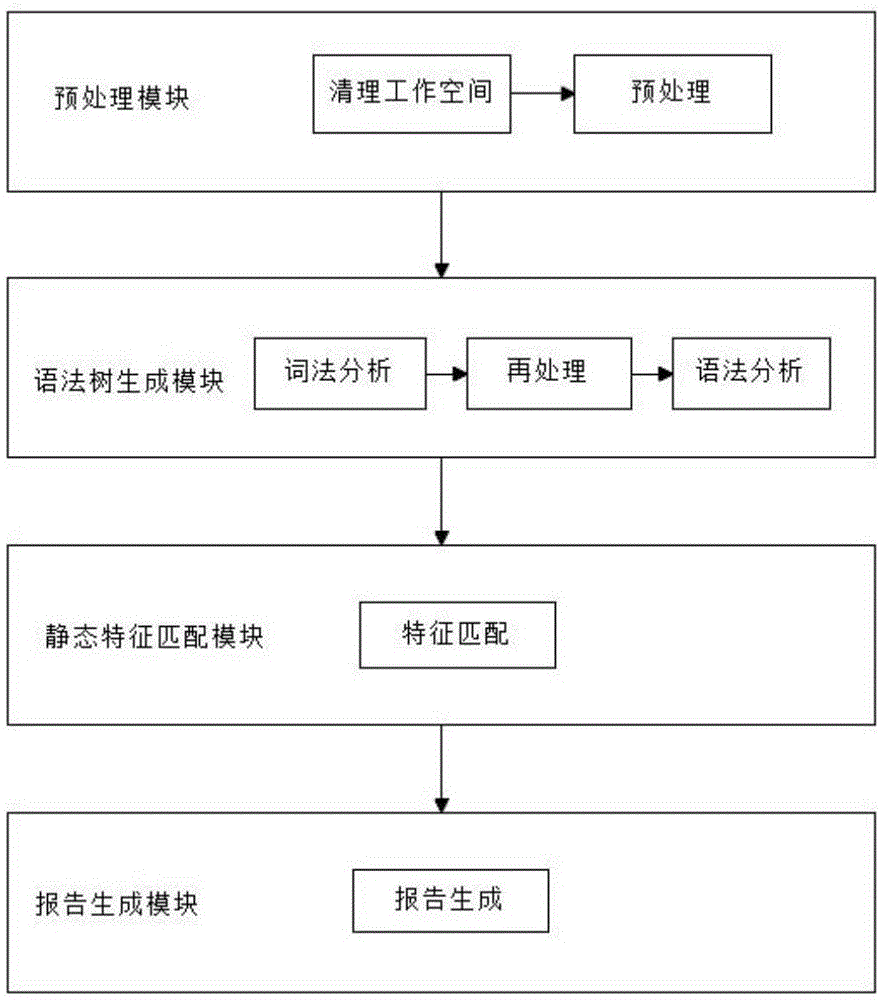
一种在区块链的以太坊平台上针对智能合约的静态代码审计系统,包括预处理模块、语法树生成模块、静态特征匹配模块和报告生成模块;
预处理模块:用于检测用户输入的合法性,将项目整体复制到临时工作目录,删除solidity文件中的注释部分;
语法树生成模块:用于对预处理后的文件进行词法分析和语法分析,生成语法树;
静态特征匹配模块:用于将语法树与预先制定的逻辑匹配规则相匹配,检查是否命中,若命中匹配则记录对应的代码信息;
报告生成模块:用于分类并汇总匹配成功的代码信息,生成报告结果文件。
一种在区块链的以太坊平台上针对智能合约的静态代码审计方法,包括以下步骤:
步骤1.系统预处理:
系统对用户的输入进行合法性检测,然后将项目整体复制到临时工作目录中,并将其中的solidity文件中的注释部分删除;
步骤2.语法树生成:
针对每一个solidity代码文件,首先处理其引用文件,将引用的部分内容复制到当前文件中,然后进行词法分析,把每一个合法的词汇都提取出来,接着对词汇进行再处理操作,将其中的变量和常量封装成对应的结构类型,最后进行语法分析,通过下推自动机等技术将代码表达式转化成语法树的形式;
步骤3.静态特征匹配:
系统将对每一个代码文件对应的语法树进行特征匹配,通过遍历语法树的每一个分支,与预先制定的逻辑规则相匹配,如果匹配成功,则可以定位到具体的表达式上;
步骤4.检测报告生成:
系统将匹配得到的结果首先按照文件进行分类,在每个文件中再按照威胁的类型对结果再分类,对于每个发现的威胁给出具体的代码位置、危害和解决方式;最终,系统汇总所有的结果并生成一个整体的报告。
本发明的有益效果是:
本发明提出一种在区块链的以太坊平台上针对智能合约的静态代码审计系统与方法,利用下推自动机等技术,实现了在区块链的以太坊平台上针对solidity语言编写的智能合约的静态代码审计系统,能够找出并分析智能合约上存在的安全威胁。本发明具有如下特点:使用下推自动机技术,实现了从代码文件到语法树的转换,用清晰的逻辑层次结构来表示抽象的代码内容。利用静态特征匹配技术,能够随时增加、修改或删除制定的逻辑规则,使系统更加灵活可扩展。通过匹配能够检测到智能合约存在的安全问题,降低了应用的安全风险。
附图说明
图1为本发明的系统结构示意图。
具体实施方式
下面结合附图和实施例对本发明进行进一步的说明。
本实施例提供一种在区块链的以太坊平台上针对智能合约的静态代码审计系统,其结构示意图如图1所示,包括预处理模块、语法树生成模块、静态特征匹配模块和报告生成模块;
预处理模块:用于检测用户输入的合法性,将项目整体复制到临时工作目录,删除solidity文件中的注释部分;
语法树生成模块:用于对预处理后的文件进行词法分析和语法分析,生成语法树;
静态特征匹配模块:用于将语法树与预先制定的逻辑匹配规则相匹配,检查是否命中,若命中匹配则记录对应的代码信息;
报告生成模块:用于分类并汇总匹配成功的代码信息,生成报告结果文件。
一种在区块链的以太坊平台上针对智能合约的静态代码审计方法,包括以下步骤:
步骤1.系统预处理:系统对用户的输入进行合法性检测,然后将项目整体复制到临时工作目录中,并将其中的solidity文件中的注释部分删除,其具体包括以下步骤:
步骤1-1.用户输入待审计的智能合约项目目录或者单个代码文件的路径path,系统检测首先检测path是否合法,如果path非法则警告提示,如果path合法则进入步骤1-2;
步骤1-2.系统定位到path所在位置,将整个目录或文件全部复制到临时工作目录work中;
步骤1-3.遍历工作目录work,找到以sol为后缀名的solidity代码文件,把文件中的注释部分全部删除;
步骤2.语法树生成:针对每一个solidity代码文件,首先处理其引用文件,将引用的部分内容复制到当前文件中,然后进行词法分析,把每一个合法的词汇都提取出来,接着对词汇进行再处理操作,将其中的变量和常量封装成对应的结构类型,最后进行语法分析,通过下推自动机等技术将代码表达式转化成语法树的形式;具体包括以下步骤:
步骤2-1.系统维护一个待解析文件列表lista和一个已解析文件列表listb,最初将所有的solidity代码文件全部放入lista中,listb置空;
步骤2-2.检查lista中是否有文件,若有则依次将其取出并对其进行步骤2-3的操作,否则进入步骤2-8;
步骤2-3.对于任一solidity代码文件,系统首先检查solidity代码文件是否在已解析文件列表中,若在则进入步骤2-2,否则进入步骤2-4;
步骤2-4.检查文件是否存在“import”关键词,若存在则确定solidity代码文件有引用文件,系统通过“import”关键词后的路径来定位得到引用文件的路径,将引用关系记录下来,然后针对引用文件进入步骤2-3操作;如果不存在引用文件则进入步骤2-5;
步骤2-5.系统利用有限自动机技术,对代码内容进行词法分析:
对于一个字符ci,下标i为字符在代码内容中的位置,如果它是“(”、“)”、“{”、“}”等界限制词,则将其单独提取出来;
如果字符ci是双引号或者单引号,则依次判断它之后的字符,直到
如果字符ci是下划线“_”或者字母,则依次判断它之后的字符,直到
如果字符ci是数字,则依次判断它之后的字符,直到
如果字符ci是“+”、“-”、“*”等运算、赋值或比较符号,则依次判断它之后的字符,直到
系统将提取出来的单词以名称name的形式保存,系统在判断过程中同时也通过检测换行符来确定每个单词所在的行号,最终生成单词结构word,它由word的名称namew和行号nw的二元组(namew,nw)表示;
步骤2-6.系统对词法分析生成的二元组结构word进行再处理操作:
对于一个二元组wordt,下标t表示第t个二元组,首选判断其单词名称namew是否为solidity语言的基本类型,如果是则继续判断之后的word结构,使其中的namew值的排列能够满足solidity的变量声明结构,直到wordt-wordt+j无法再构成一个合法的变量声明,j为正整数,然后将wordt-wordt+j-1封装成一个由基本类型typev、限制关键词restrictionv、变量名称namev和行号nv组成的四元组变量var,其表达式为(typev,restrictionv,namev,nv),同时将原来的单词结构wordt替换为var,并删除从wordt+1到wordt+j-1的单词结构;如果wordt中的名称namew为字符串或数字常量,则将其直接封装为一个由类型typec(字符串或数字)、内容contentc和行号nc组成的三元组结构constant,其表达式为(typec,contentc,nc),然后将原wordt替换为constant;对于其他的namew值则保持不变;
步骤2-7.系统对生成的word、var和constant结构进行语法分析:
solidity语言的最外层结构主要为contract(合约)、library(库)和interface(接口),系统将其统称为mainblock;系统首先找到“contract”、“library”和“interface”关键词,然后创建相应的类型结构:
对于一个二元组wordt,如果其名称namew为contract、library或interface,则创建mainblock结构,然后根据后续的word、var和constant结构依次确定其类型typemb、名称namemb和继承关系basemb,直到出现一个wordkk,kk为正整数,其中的名称namew为界符“{”;
然后以界符“{”和“}”为边界,对其中的内容继续解析,在此阶段主要的结构为statevariables(变量表达式)、functions(函数)、functionmodifiers(函数调节器)、events(事件)、structtypes(结构类型)和enumtypes(枚举类型);
系统采用下推自动机的技术,根据solidity语言制定的规约规则将变量、常量和运算、赋值或比较符号规约成变量表达式;
对于函数类型,系统将根据solidity的函数定义规则,依次检测其名称namef、参数paramf、限制词restrictionf和返回值returnf,然后再以界符“{”和“}”为边界,对其中的表达式内容进行解析,解析过程同变量表达式,最后得到表达式集合explistf,并将其添加到函数结构中;如果函数声明后的内容不是界符“{”而是分号“;”,则该函数为抽象函数,函数解析结束;函数解析结束后,将生成的函数结构添加到mainblock中;
对于函数调节器,系统将根据solidity的函数调节器定义规则,依次检测其名称namem和参数paramm,然后再以界符“{”和“}”为边界,对其中的表达式内容进行解析,解析过程同变量表达式,最后得到表达式集合explistm,然后将其添加到函数调节器结构中;函数调节器解析结束后,将生成的函数调节器结构添加到mainblock中;
对于事件类型,系统将根据solidity的事件定义规则依次检测其名称namee和参数parame,并将生成的事件结构添加到mainblock中;
对于结构类型,系统将根据solidity的结构定义规则将依次检测其名称names和其中的变量values,并将生成的结构添加到mainblock中;
对于枚举结构,系统将将根据solidity的枚举定义规则依次检测其名称nameenum和其中枚举的对象valueenum,并将生成的枚举结构添加到mainblock中;
通过上述解析操作,系统将会生成一个或若干个语法树,此时该代码文件已解析完成,将其放入已解析文件列表listb中,同时在未解析文件列表lista中将solidity代码文件删除,返回步骤2-2;
步骤2-8.所有的代码文件已经全部解析为语法树的形式,系统将进入静态特征匹配阶段;
步骤3.静态特征匹配:
系统将对每一个代码文件对应的语法树进行特征匹配,通过遍历语法树的每一个分支,与预先制定的逻辑规则相匹配,如果匹配成功,则可以定位到具体的表达式上;
步骤4.检测报告生成:
系统将匹配得到的结果首先按照文件进行分类,在每个文件中再按照威胁的类型对结果再分类,对于每个发现的威胁给出具体的代码位置、危害和解决方式;最终,系统汇总所有的结果并生成一个整体的报告。
- 还没有人留言评论。精彩留言会获得点赞!