基于自然语言处理的客服质量自动评分方法与流程
本发明一般涉及互联网金融客户服务质量监控监控领域,具体涉及基于自然语言处理的客服质量自动评分方法。
背景技术:
过去在企业营销活动中,大多数的企业只重视新客户的开发,对于现有的老客户,不注意维持,从而造成了老客户的大量流失。提高客户服务质量,能够有效的阻止老客户的流失,同时能够吸引到更多的新客户。重视客服质量,能够达到事半功倍的效果。因此,通过评分,来监测客户服务的质量,可以有效提高客服质量。
最初,是由人工阅读,或者聆听通话录音,来实现对客服质量的评分。这种人工评分的方式效率低下,很大程度浪费人了人力资源。而且人工评分准确度不高,不同的人评分的标准不同,不利于统计结果。
确定了评分标准之后,通过机器自动评分的方式,可以提高评分的工作效率和准确率。自动评分系统按照不同的评分细则,使用不同的实现方式对客服的文字进行评分,最后将所有评分相加,得出总分。自动评分系统能大大提高客服质量检查的效率和准确率,同时也方便统计结果。
自然语言处理是使用机器处理人类语言的理论和技术。自然语言处理将语言作为计算对象来研究相应的算法,其目标是通过自然语言的形式与机器系统进行人机交互,从而实现更高效和便捷的信息管理。自然语言处理的关键是让计算机“理解”自然语言。
对于文字自动评分算法,目前国内外有一些对于作文进行自动评分应用。但大部分都是偏重于语法正确与否的检测。英文自动评分,往往是根据时态是否正确、人称、单复数等语法规则进行检测。中文自动评分,往往是根据错别字、词汇应用是否准确、是否存在词不达意等等情况进行自动评分。这两类评分都是针对由一个人完成的文本进行评分。而本算法中,客服文字自动评分,是针对“对话”进行评分,文本包含两个人对话的内容,对话是需要进行区分的。本发明提出的评分系统不重视语法和词汇的正确运用,评分的重要依据是客服的表达是否礼貌准确。
技术实现要素:
本发明针对当前人工对客服质量进行评分的低效,提供了基于自然语言处理的客服质量自动评分算法。本发明的目的在于自动对客服质量进行评分,从而减少人工评分消耗的人力,使评分更加公平公正。评分分为两个部分,一是对客服录音进行转写,二是根据评分规则和知识库转写之后的结果进行评分。
本发明的目的至少通过如下技术方案之一实现。
一种基于自然语言处理的客服质量自动评分方法,其包括以下步骤:
(a)对采集到的客服录音进行转写,转写成文字;
(b)利用文本信息特征的统计规律和语法规律进行中文文本校对,利用人工校准结果统计形成的错词知识库,并对录音转写成的文字结果进行校准;
(c)使用基于规则的方法对步骤(a)中转写的文字结果进行分析;
(d)根据评分细则的具体要求,对评分细则进行分类;
(e)对于不涉及具体业务知识的评分细则,直接根据规则进行评分,得到fr;
(f)对于涉及具体业务知识的评分细则,收集知识库,每次对文本评分都需要与知识库中的信息进行比对,得到fk;
(g)计算步骤(e)和步骤(f)中评分的总和,得到最终结果。
进一步的,步骤(a)包括以下步骤:
(a-1)以放置语音文件的文件夹路径作为输入,读取该文件中所有需要被转写的语音文件;
利用testlfasr类中的transform函数首先遍历文件夹中的文件,并且做判断,如果是符合mp3以及wav格式的文件,则进行转写,并输出,如果是其他文件格式,则跳过;接下来,对于文件夹中的子文件夹,递归调用transfrom函数,直到所有的音频文件都完成转写;
(a-2)转写结果的输出
从原语音文件的文件名中提取客服人员姓名、客户电话号码、通话时间、客服是否在通话后正确发送短信的信息,组成新的文件名,保存在同一文件夹下,以便文本分析使用转写结果按照json文件格式输出在一个txt文档中,每一句以字典的数据结构{speaker:“”,bg:“”,ed:“”,onebest:“”}进行存储;其中speaker属性表示说话人,bg表示该句话开始的时间,ed表示该句话结束的时间;onebest表示说话的内容;所有的dictionary以列表形式存储在文件里。
进一步的,步骤(b)包括以下步骤:
(b-1)首先根据语法规则,对于文本进行初步校准;
由于转写的文本可能存在错误转写的字词,所以寻找文本中句子的每个字词的可能候选,构造句子的字词候选矩阵;将需要校对的句子中的每个字cz作为基字,以它的同音字集作为cz的候选字集;从该候选集中依词频从高到低挑选出m个候选字,与基字cz共同组成一列字词候选向量zz;因此当句子s中的汉字个数为n时,句子s的字词候选向量构成了句子s的字词候选矩阵matrix(s)=z1z2...zn();在此基础上,利用语言本身所具有的语法规律及统计特征,从字词候选矩阵中选出句子的最佳字词候选序列将其与原句对照,找出错误的字词,并以第一候选即最有可能是正确字词的候选加以改正;同时给出其它可能的候选字词,此时得到初步校准之后的文本;
(b-2)收集正样本和负样本,也就是收集通过转写之后得到的文本,和人工校准之后的文本;
(b-2)对于样本进行分析,统计所有出现率高于设定值的错误词汇,形成错词知识库;(b-3)从初步校准之后的文本中检索,查看是否存在错词知识库中的词语,如果存在,根据上下文分析该词语错误的概率;根据公式(1)计算错误概率;当错误概率超过预先设定的阈值时,表示需要修改该词语,否则不需要修改,
mistake=(wf+wb+ww)/3(1)
其中当该字词上文的字词为f时,wf=1,否则wf=0,该字词下文的字词为b时,wb=1,否则wb=0,ww为该字词本身为错误的概率。
进一步的,步骤(c)包括以下步骤:
(c-1)读取(a-2)中的转写结果;
(c-2)按照speaker进行分类;
首先根据是否有客服人员标志话语,对于speaker进行识别,转写结果中包含speaker1和speaker2,分别代表客服或者客户,要根据如下规则来判断具体哪一组是客服:
若speaker1的话语中出现“您好,团购网,请问有什么可以帮到您”那么speaker1为客服,speaker2为客户;若speaker2的话语中出现“您好,团购网,请问有什么可以帮到您”那么speaker2为客服,speaker1为客户;如果speaker1和speaker2的话语中都没有出现“您好,团购网,请问有什么可以帮到您”,则第一个说话人为客服,另外一个说话人为客户;
根据判断结果分类,将不同speaker话语存储在不同数组中,以便进行分析。
进一步的,步骤(d)包括以下步骤:
(d-1)根据具体的评分规则来进行分类,分类标准包含在(d-2)和(d-3);
(d-2)对其中不需要知识库的评分细则有:首位用于规范、礼貌用语、语速、语音语调、表达流畅、倾听、提问技巧、引导能力、后续跟进、短信发送;
(d-3)需要知识库的评分细则有:积极回应、业务知识、信息运用、确认、同理心、问题澄清、无机械式回答、建议\解决方案、无推诿、合规性。
进一步的,步骤(e)包括以下细节:
(e-1)首尾用语规范
开头包含“您好”“团购网”“请问”“帮”,给一分,并判断该说话人,为客服;公司在文件名中给出标记,判断是否为客服挂断电话,如果是,同时结尾包含“请问”“还有什么问题”给一分,“评价”“生活愉快”“再见”,给一分,否则不给分;如果客服没有说“请问”“还有什么问题”,但是客户说了“没问题”“再见”“没事了”,给分;如果不是客服挂断电话,直接给两分;
(e-2)礼貌用语
在客服的话语中,“请”“您”“麻烦”出现的次数小于等于三次,不给分;出现不礼貌的话语,例如脏话等,不给分,否则给满分;
(e-3)语速
如果客户反馈“你说的太快了”“说慢点”大于两次,不给分;否则给满分;
(e-4)语音语调
如果客户反馈“你能好好说话吗”、“你态度能好点吗”不给分,否则给满分;
(e-5)表达流畅
对于长时间的空白,如果客户说:“等一下”,给分;如果客服说“稍等”,不给分;如果客户提出问题,空白了很长时间之后,客户问“听到吗”,客服回答“线路问题”“系统问题”“没有声音”,给分,如果客服只是回答问题而没有给出解释,不给分;假设在整段录音中,整段录音长度为i,允许出现“的话”的次数为ti,客服的话中出现“的话”的次数为x,x<=ti,得满分;如果x>=ti,0分,否则,给3分;
(e-6)倾听
客户说完话之后,不到一秒钟,客服说话,判断为打断,给0分,出现“你先听客服说完”,给0分,在客户连续说话五分钟以上,客服打断,给满分;
(e-7)提问技巧
出现“你等一下”“听我说”“你说什么”给0分,否则给满分;
(e-8)引导能力:
与业务知识一起判断,如果业务知识中不能一次回答准确,扣掉引导能力的分数;
(e-9)后续跟进:
涉及到两通电话的问题,暂时在程序中不做判断,如果因为这种情况出现不合理扣分,由客服人员自己反馈,鉴定过后,可修改分数;
(e-10)短信发送:
由公司的技术人员发匹配的excel表格,其中包含是否正确发送了信息,由程序作出判断,加在总分中。
进一步的,步骤(f)包括以下步骤:
(f-1)积极回应:
根据积极回应知识库,对于知识库中的问题,如果客服的回答时长小于一秒,判断为不积极回应,给0分;
(f-2)业务知识:
根据业务知识知识库,如果客户提问了其中的问题,客服必须按照知识库中的正确答案进行回答,否则给0分;
(f-3)信息运用
如果客户提出了知识库中的问题,并且在客服的回答中找到了正确的答案给7分;如果客服没有一次性回答正确,导致客户重复问题,或者出现“我不是这个意思”“难道你没理解吗”出现上述情况,大于两次,给5分;如果答非所问,并且客户没有再次提问,给0分;
(f-4)确认:
根据确认知识库,如果客户没有提出明确的问题,客服需要根据业务知识进行确认,直到问题明确再进行回答,否则不给分。
进一步的,步骤g包含以下步骤:
(g-1)根据如下公式将评分细则的评分结果相加:
该公式中f(x)表示总分,fi(x)表示每一个评分细则的得分,sr表示整个评分细则的集合。与现有技术相比,本发明具有如下优点和技术效果:
本发明是基于分析目前已大量实际应用的客服通话录音系统产生的录音,因此不需要为收集客服通话录音而重新部署采集设备;相对于传统的基于人工聆听和人工的主观感觉对于客服质量进行评分,本发明能在保持高准确率和高效率的前提下对客服质量进行评分。另外,本发明采用的评分方法还能够随着业务变化,由用户自主更新规则,而无需修改代码就可以更新评分模型,计算简单,评分速度快,节省大量人力,可应用于实时环境。
附图说明
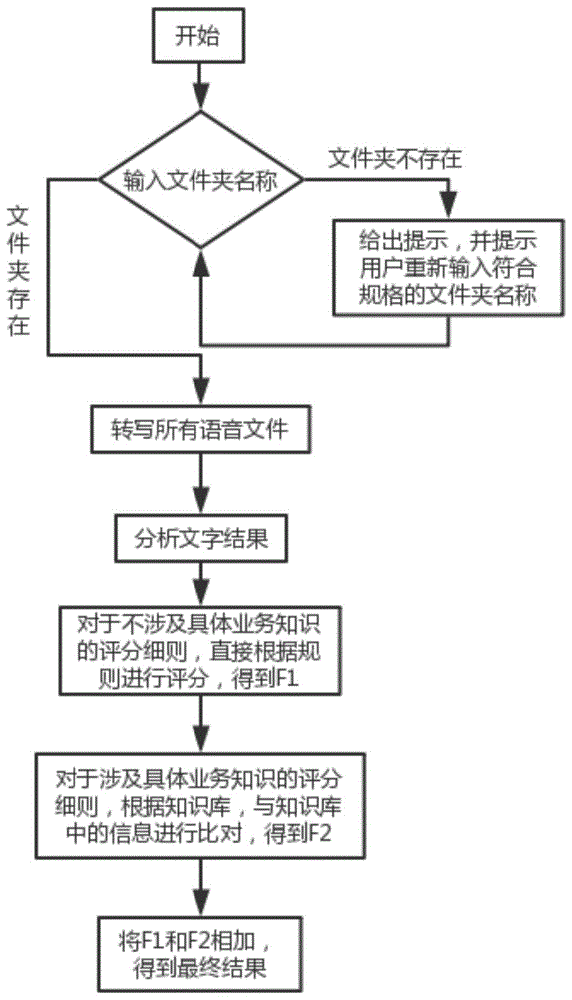
图1为实施例中一种基于自然语言处理的客服质量自动评分方法整体流程图;
图2为实施例中评分结果具体示例图。
具体实施方式
下面将结合附图以及具体实例来详细说明本发明,再次本发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
如图1,基于自然语言处理的客服质量自动评分系统,其主要流程包括以下步骤:
(a)对采集到的客服录音进行转写,转写成文字;
(b)利用文本信息特征的统计规律和语法规律进行中文文本校对,利用人工校准结果统计形成的错词知识库,并对录音转写成的文字结果进行校准;
(c)使用基于规则的方法对步骤(a)中转写的文字结果进行分析;
(d)根据评分细则的具体要求,对评分细则进行分类;
(e)对于不涉及具体业务知识的评分细则,直接根据规则进行评分,得到fr;
(f)对于涉及具体业务知识的评分细则,收集知识库,每次对文本评分都需要与知识库中的信息进行比对,得到fk;
(g)计算步骤(e)和步骤(f)中评分的总和,得到最终结果。
9.步骤(a)要求音频格式必须为mp3或wav,进行语音转写工作,需要注意的是,语音转写可能出现不准确的情况,本方法在能够提高评分准确度的前提下,对转写结果进行校准。
10.步骤(a)主要包含以下步骤:
(a-1)以放置语音文件的文件夹路径作为输入,读取该文件中所有需要被转写的语音文件;
testlfasr类中的transform函数首先遍历文件夹中的文件,并且做判断,如果是符合mp3以及wav格式的文件,则进行转写,并输出,如果是其他文件格式,则跳过;接下来,对于文件夹中的子文件夹,递归调用transfrom函数,直到所有的音频文件都完成转写;
(a-2)转写结果的输出
从原语音文件的文件名中提取客服人员姓名,客户电话号码,通话时间等信息,组成新的文件名,保存在同一文件夹下,以便文本分析使用转写结果按照json文件格式输出在一个txt文档中。例如原音频文件名:“01011111111陈先生2017_10_1814_17_16.mp3”其中“01011111111”字段为客户电话号码,“陈先生”字段为客服人员姓名,“2017_10_1814_17_16”字段为通话时间。重组后形成新的文件名“陈先生0101111111120171018141716.txt”。
转写结果每一句以字典的数据结构({speaker:“”,bg:“”,ed:“”,onebest:“”})进行存储;其中speaker属性表示说话人,bg表示该句话开始的时间,ed表示该句话结束的时间;onebest表示说话的内容;所有的dictionary以列表形式存储在文件里。例如{"bg":"380","ed":"13000","onebest":"你好,团购网,请问什么可以帮您啊","speaker":"2"}
步骤(b)主要目的是对转写结果进行校准,以提高文本评分的准确率。
步骤(a)主要包含以下步骤:
步骤(b)包括以下步骤:
(b-1)首先根据语法规则,对于文本进行初步校准;
由于转写的文本可能存在错误转写的字词,所以寻找文本中句子的每个字词的可能候选,构造句子的字词候选矩阵;将需要校对的句子中的每个字cz作为基字,以它的同音字集作为cz的候选字集;从该候选集中依词频从高到低挑选出m个候选字,与基字cz共同组成一列字词候选向量zz;因此当句子s中的汉字个数为n时,句子s的字词候选向量构成了句子s的字词候选矩阵matrix(s)=z1z2...zn();在此基础上,利用语言本身所具有的语法规律及统计特征,从字词候选矩阵中选出句子的最佳字词候选序列将其与原句对照,找出错误的字词,并以第一候选加以改正(最有可能是正确字词的候选);同时给出其它可能的候选字词,此时得到初步校准之后的文本;
(b-2)收集正样本和负样本,也就是收集通过转写之后得到的文本,和人工校准之后的文本;例如转写得到的文本中,“团购网”被转写成“团购完”的次数过多,则将该词和该词的上下文词汇记录到错词知识库中。
(b-2)对于样本进行分析,统计所有出现率高于80%的错误词汇,形成错词知识库;
(b-3)从初步校准之后的文本中检索,查看是否存在错词知识库中的词语,如果存在,根据上下文分析该词语错误的概率;根据公式(1)计算错误概率;当错误概率超过设定的阈值时,表示需要修改该词语,否则不需要修改。
mistake=(wf+wb+ww)/3(1)
其中当该字词上文的字词为f时,wf=1,否则wf=0,该字词下文的字词为b时,wb=1,否则wb=0,ww为该字词本身为错误的概率。
例如预先设定阈值为0.7例如“团购网”被转写成“团购完”,若转写之后的文本出现“团购完”一词,并且上文为“您好”,下文为“请问有什么可以帮您”,“团购完”本身的错误概率为0.,7,则mistake=0.9,超过预先设定的阈值,则该词错误,将“团购完”修改为“团购网”
步骤(c)主要对说话人进行区分。
步骤(c)包括以下步骤:
(c-1)读取(a-2)中的转写结果
(c-2)按照speaker进行分类;
首先根据是否有客服人员标志话语,对于speaker进行识别,转写结果中包含speaker1和speaker2,分别代表客服或者客户,要根据如下规则来判断具体哪一组是客服:
若speaker1的话语中出现“您好,团购网,请问有什么可以帮到您”那么speaker1为客服,speaker2为客户。若speaker2的话语中出现“您好,团购网,请问有什么可以帮到您”那么speaker2为客服,speaker1为客户。如果speaker1和speaker2的话语中都没有出现“您好,团购网,请问有什么可以帮到您”,则第一个说话人为客服,另外一个说话人为客户。
根据判断结果分类,将不同speaker话语存储在不同数组中,以便进行分析。
步骤(d)主要对评分规则进行分类。
步骤(d)包括以下步骤:
(d-1)根据具体的评分规则来进行分类,分类标准包含在(d-2)和(d-3);
(d-2)对其中不需要知识库的评分细则有:首位用于规范、礼貌用语、语速、语音语调、表达流畅、倾听、提问技巧、引导能力、后续跟进、短信发送;
(d-3)需要知识库的评分细则有:积极回应、业务知识、信息运用、确认、同理心、问题澄清、无机械式回答、建议\解决方案、无推诿、合规性。
步骤(e)主要对不需要知识库的评分细则进行评分。
步骤(e)包括以下细节:
(e-1)首尾用语规范
开头包含“您好”“团购网”“请问”“帮”,给一分,并判断该说话人,为客服;公司在文件名中给出标记,判断是否为客服挂断电话,如果是,同时结尾包含“请问”“还有什么问题”给一分,“评价”“生活愉快”“再见”,给一分,否则不给分;如果客服没有说“请问”“还有什么问题”,但是客户说了“没问题”“再见”“没事了”,给分;如果不是客服挂断电话,直接给两分,如图2中“首尾用语规范”打分;
(e-2)礼貌用语
在客服的话语中,“请”“您”“麻烦”出现的次数小于等于三次,不给分;出现不礼貌的话语,例如脏话等,不给分,否则给满分,如图2所示,礼貌用语次数为10词,所以给满分;
(e-3)语速
如果客户反馈“你说的太快了”“说慢点”大于两次,不给分;否则给满分,如图2中的“语速”。
(e-4)语音语调
如果客户反馈“你能好好说话吗”“你态度能好点吗”不给分,否则给满分;
(e-5)表达流畅
对于长时间的空白,如果客户说:“等一下”,给分;如果客服说“稍等”,不给分;如果客户提出问题,空白了很长时间之后,客户问“听到吗”,客服回答“线路问题”“系统问题”“没有声音”,给分,如果客服只是回答问题而没有给出解释,不给分;假设在整段录音中,整段录音长度为i,允许出现“的话”的次数为ti,客服的话中出现“的话”的次数为x,x<=ti,得满分;如果x>=ti,0分,否则,给3分;
(e-6)倾听
客户说完话之后,不到一秒钟,客服说话,判断为打断,给0分,出现“你先听客服说完”,给0分,在客户连续说话五分钟以上,客服打断,给满分,如图2中,当发现打断次数过多,则扣掉该项分数,并且输出“打断次数过多”这一扣分理由。
(e-7)提问技巧
出现“你等一下”“听我说”“你说什么”给0分,否则给满分;
(e-8)引导能力:
与业务知识一起判断,如果业务知识中不能一次回答准确,扣掉引导能力的分数;
(e-9)后续跟进:
涉及到两通电话的问题,暂时在程序中不做判断,如果因为这种情况出现不合理扣分,由客服人员自己反馈,鉴定过后,可修改分数。
(e-10)短信发送:
由公司的技术人员发匹配的excel表格,其中包含是否正确发送了信息,由程序作出判断,加在总分中。
步骤(f)主要对需要知识库的评分细则进行评分。
步骤(f)包括以下步骤:
(f-1)积极回应:
根据积极回应知识库,对于知识库中的问题,如果客服的回答时长小于一秒,判断为不积极回应,给0分;
(f-2)业务知识:
根据业务知识知识库,如果客户提问了其中的问题,客服必须按照知识库中的正确答案进行回答,否则给0分;
(f-3)信息运用
如果客户提出了知识库中的问题,并且在客服的回答中找到了正确的答案给7分;如果客服没有一次性回答正确,导致客户重复问题,或者出现“我不是这个意思”“难道你没理解吗”出现上述情况,大于两次,给5分;如果答非所问,并且客户没有再次提问,给0分;
(f-4)确认:
根据确认知识库,如果客户没有提出明确的问题,客服需要根据业务知识进行确认,直到问题明确再进行回答,否则不给分;
(f-5)建议/解决方案:
根据知识库,如果客户提出的问题在“建议/解决方案”知识库中,则对比客服给出的答案是否包含知识库中该问题答案的所有关键词,若包含,则给满分,否则不给分。如图2,客户提出问题“京东”(京东为该问题的关键词,只要客户话语中包含该问题的关键词,就认为客户提出了该问题),客服给出了相应答案,因此给满分;
步骤(g)主要计算总分。
步骤(g)包含以下步骤:
(g-1)根据如下公式将评分细则的评分结果相加:
该公式中f(x)表示总分,fi(x)表示每一个评分细则的得分,sr表示整个评分细则的集合。
- 还没有人留言评论。精彩留言会获得点赞!