基于加权模式挖掘的印尼-英跨语言译后前件扩展方法与流程
本发明属于信息检索领域,具体是基于加权模式挖掘的印尼-英跨语言译后前件扩展方法。
背景技术:
跨语言查询扩展指的是在跨语言信息检索过程中,采用某种策略发现与原查询相关的扩展词,扩展词和原查询组合得到新查询并再次检索的过程。跨语言查询扩展是提高和改善跨语言信息检索性能的关键技术之一,能解决跨语言信息检索中长期困扰的查询主题严重漂移和词不匹配等问题。根据跨语言信息检索的不同阶段,跨语言查询扩展分为查询译前扩展、查询译后扩展和混合式查询扩展等三种。查询译前扩展模型指的是在源语言查询翻译为目标语言之前,采用某些策略从其他源语言文档材料(或者初检源语言文档)中获得源语言扩展词实现译前扩展,然后进行查询翻译,再检索目标语言文档。查询译后扩展发生在源语言查询翻译为目标语言之后,从跨语言初检目标语言文档或者其他目标语言文档材料中获取目标语言扩展词实现译后扩展,然后再次检索目标语言文档。混合式查询扩展的实现要经过三次检索,即首先进行查询译前扩展得到了源语言扩展词实现译前扩展后进行跨语言检索,在此基础上再进行查询译后扩展得到目标语言扩展词,和译后的目标语言查询组合实现混合式扩展,最后再进行第三次检索。
随着网络技术的发展以及机器翻译技术的进步,跨语言查询扩展技术成为一个重要的研究热点。近十几年来,学者们围绕着上述三种跨语言查询扩展模型开展了卓有成效的研究,取得了一些研究成果,例如,闭剑婷等提出的一种基于潜在语义分析的跨语言查询扩展方法(见文献:闭剑婷,苏一丹.基于潜在语义分析的跨语言查询扩展方法[j].计算机工程,2009,35(10):49-53.),吴丹等提出一种基于伪相关反馈的跨语言查询扩展方法(见文献:吴丹,何大庆,王惠临.基于伪相关反馈的跨语言查询扩展[j].情报学报,2010,29(2):232-239.),等等,但还没有最终完全解决跨语言信息检索中存在的技术难题。
随着中国-东盟自由贸易区建设的不断深入以及中国-东盟博览会每年的举办,世界各国与东盟印尼国家之间的交往更加密切和频繁。语言多样化成为了各国与东盟国家之间扩大经贸往来和文化交流的瓶颈和困难,消除语言障碍已经成为一个亟需解决和刻不容缓的重要问题,东盟印尼语跨语言信息检索研究显得迫切,具有重要的现实意义。当前,东盟印尼语跨语言信息检索面临的问题主要表现为查询主题严重漂移、词不匹配以及查询项翻译歧义和多义性等,这些问题也是当前国际上急需解决的跨语言信息检索中普遍存在的难题。东盟印尼语跨语言查询扩展是解决上述问题的核心技术之一。然而,当前跨语言查询扩展研究的主要语言对象是英语、汉语等大语种以及欧洲国家语言和国内的少数民族语言等等,而针对东盟小语种印尼语的跨语言查询扩展研究报道不多,同时,基于关联规则挖掘的跨语言查询扩展研究不是很深入,还存在如下一些主要问题:①还没有找到一种最优的、最普遍适用各种语言环境的支持度计算方法和关联规则评估框架来挖掘文本信息中特征词之间存在的各种复杂关联。现有研究中,项集支持度要么只考虑项集频度,要么只考虑项集权值,或者仅仅将项平均权值与无加权支持度的简单乘积作为项集支持度,等等,使得挖掘出的扩展词质量(即与原查询的相关性)有待于提高;②关联规则评估方面,经典的支持度-置信度评估框架存在难以解决的缺陷,例如,冗余的、或者虚假的关联规则多,虽然出现了一些改进的评估框架,但是,还没有最终解决跨语言检索中查询主题漂移和词不匹配问题。
技术实现要素:
本发明提出了基于加权模式挖掘的印尼-英跨语言译后前件扩展方法,应用于跨语言信息检索领域,应用于实际的跨语言搜索引擎和跨语言信息检索系统,提高跨语言检索性能,解决跨语言信息检索中查询主题漂移和词不匹配问题。
本发明采用如下技术方案:
基于加权模式挖掘的印尼-英跨语言译后前件扩展方法,包括下列步骤:
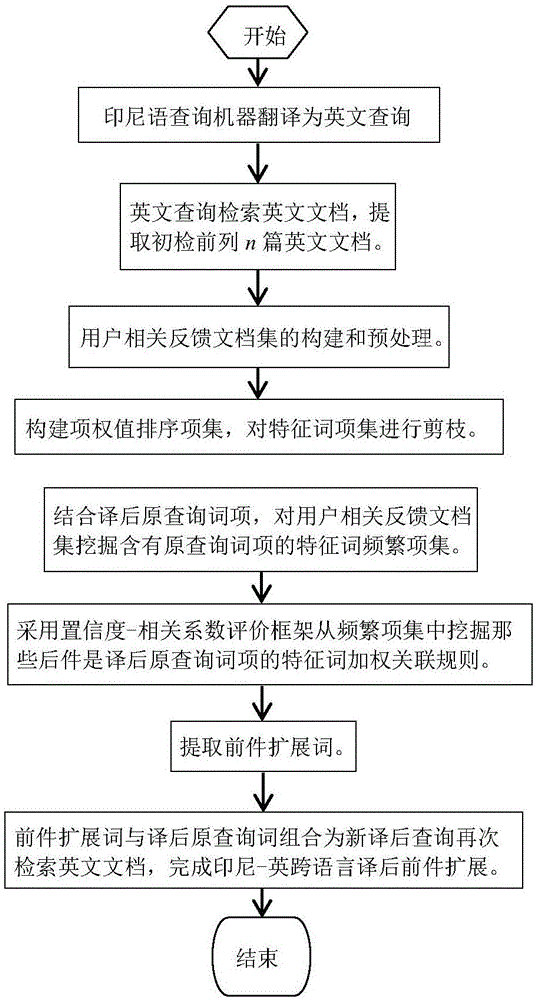
步骤1.印尼语查询机器翻译为英文查询并检索英文文档,提取初检前列n篇英文文档,构建用户相关反馈文档集,预处理用户相关反馈文档集,具体步骤如下:
(1)印尼语查询机器翻译为英文并检索英文文档集得到初检前列英文文档。
(2)用户对初检前列n篇英文文档进行相关性判断得到初检相关文档,构建用户相关反馈文档集。
(3)预处理用户相关反馈文档集,构建英文文档索引库和特征词库,然后转入步骤2。
用户相关反馈文档集预处理内容是:去除英文停用词,通过词干提取得到特征词,计算特征词权值,最后构建英文文档索引库和特征词库。
本发明采用porter程序(详细见网址:http://tartarus.org/martin/porterstemmer)进行词干提取。
用户相关反馈文档集中特征词权值wij的计算公式,如式(1)所示。
式(1)中,wij表示文档di中特征词tj的权值,dfj表示含有特征词tj的文档数量,n表示用户相关反馈文档集的文档总数,tfj,i表示特征词tj在文档di中的词频,max(tfi)表示文档di中出现的最大词频。
式(1)表明,在用户相关反馈文档集中,含有某个特征词的用户相关反馈文档数量越多,则该特征词与原查询越相关,越重要,所述特征词的权值就越高。
步骤2.构建项权值排序项集,对特征词项集进行剪枝,结合译后原查询词项,对用户相关反馈文档集挖掘含有原查询词项的特征词频繁项集,具体步骤如下:
(1)挖掘特征词1_频繁项集l1,具体为如下3个步骤:
(1.1)从特征词库中提取特征词作为1_候选项集c1;
(1.2)扫描英文文档索引库以便统计文档索引库中文档总数n和累加所有特征词权值的总和w,统计特征词1_候选项集c1在英文文档索引库的权值
(1.3)如果wsup(c1)≥ms,ms为最小支持度阈值;则c1就是特征词1_频繁项集l1,添加到特征词频繁项集集合fis(frequentitemset)。
(2)构建权值排序k_候选项集,对k_候选项集进行剪枝,挖掘出特征词k_频繁项集,所述k≥2,具体为如下8个步骤:
(2.1)采用aproiri连接方法将特征词(k-1)_频繁项集lk-1进行自连接得到特征词k_候选项集ck,所述k≥2;
aproiri连接方法详见文献(agrawalr,imielinskit,swamia.miningassociationrulesbetweensetsofitemsinlargedatabase[c]//proceedingsofthe1993acmsigmodinternationalconferenceonmanagementofdata,washingtondc,usa,1993:207-216.)
(2.2)如果k=2,删除没有包含译后英文原查询词项的特征词k_候选项集ck,将包含有译后英文原查询词项的ck留下,然后,转入步骤(2.3);如果k>2,则直接转入步骤(2.3)。
(2.3)统计特征词k_候选项集ck在英文文档索引库的项权值(w1,w2,…,wk),并且排降序,使得w1≥w2≥…≥wk,这样就得到特征词权值排序k_候选项集ck=(i1,i2,…,ik)。
(2.4)对权值排序k_候选项集ck=(i1,i2,…,ik)的子项集c1=(i1),c12=(i1,i2),c123=(i1,i2,i3),…,c123…k-1=(i1,i2,…,ik-1)进行考察,如果存在某个子项集是非频繁的,则该项集ck是非频繁的,剪除该项集ck;
(2.5)对于余下的权值排序k_候选项集ck,如果
(2.6)对剪枝后余下的权值排序k_候选项集ck,根据权值排序k_候选项集ck在英文文档索引库中的出现次数
式(3)中,w和n的定义同式(2),
(2.7)如果wsup(ck)≥ms,ms为最小支持度阈值;则该权值排序k_候选项集ck就是特征词k_频繁项集lk,添加到特征词频繁项集集合fis。
(2.8)若特征词k_频繁项集lk为空集,则特征词频繁项集挖掘结束,转入如下步骤3,否则,k加1后转入步骤(2.1)继续循环。
步骤3.采用置信度-相关系数评价框架从频繁项集集合fis中挖掘那些后件是译后原查询词项的特征词加权关联规则,具体步骤如下:
(3.1)对于特征词频繁项集集合fis中每一个加权k_频繁项集lk,所述k≥2,构建任意一个lk的所有真子集项集集合;
(3.2)从真子集项集集合中任意取出两个真子集项集qt和et,且
式(4)中,k1、k2项k12分别为特征词项集qt、et以及项集(qt,et)的项集长度,n1、n2和n12分别为特征词项集qt、et以及项集(qt,et)在英文文档索引库中出现的次数,w1、w2和w12分别为特征词项集qt、et以及项集(qt,et)在英文文档索引库中的项集权值,w和n定义同式(2)。
(3.3)如果wicc(qt,et)>0,则计算特征词加权关联规则置信度(weightedassociationruleconfidence,warc)warc(et→qt),若warc(et→qt)≥最小置信度阈值mc,则关联规则et→qt是特征词强加权关联规则模式,加入到特征词加权关联规则模式集合war(weightedassociationrule)。warc(et→qt)的计算公式如式(5)所示。
式(5)中,k1、k12、n1、n12、w1和w12的定义同式(4)。
(3.4)如果lk的真子集项集集合中每个真子集项集当且仅当都被取出一次,则转入如下步骤(3.5),否则,转入步骤(3.2)再顺序进行各个步骤。
(3.5)从特征词频繁项集集合fis中重新取出另一个加权k_频繁项集lk,并转入步骤(3.1)进行新一轮特征词加权关联规则模式挖掘,直到fis中每一个k_频繁项集lk都被取出为止,这时特征词加权关联规则模式挖掘结束,转入如下步骤4。
步骤4.从特征词加权关联规则模式集合war中提取规则前件et作为前件扩展词,计算前件扩展词权值。
从特征词加权关联规则模式集合war中提取每个关联规则et→qt的前件et作为前件扩展词,该扩展词权值we的计算公式如式(6)所示。
we=max(warc)+max(wicc)(6)
式(6)中,max(warc)和max(wicc)分别表示特征词加权关联规则置信度中的最大值和相关系数中的最大值。当扩展词重复出现在多个加权关联规则模式时,会存在多个置信度和相关系数的情况,这时取其值最大值用来计算该扩展词的权值。
步骤5.前件扩展词与译后原查询词组合为新译后查询再次检索英文文档,完成印尼-英跨语言译后前件扩展。
本发明与现有技术相比,具有以下有益效果:
(1)本发明提出一种基于加权模式挖掘的印尼-英跨语言译后前件扩展方法。该发明方法将项集权值和频度与用户相关文档集的特征词总权值和文档总数融合,挖掘特征词频繁项集,通过项权值排序对特征词项集进行剪枝,挖掘效率得到提升,采用置信度-相关系数评价框架从特征词频繁项集中挖掘特征词加权关联规则,提取所述关联规则前件作为印尼-英跨语言译后前件扩展词,实现印尼-英跨语言查询译后前件扩展。实验结果表明,本发明能提高和改善跨印尼-英语言文本信息检索性能,具有较好的应用价值和推广前景。
(2)选择国际上普遍使用的标准数据集ntcir-5clir作为本发明方法实验语料。与现有对比方法比较,实验结果表明,本发明方法的跨语言检索结果p@15和平均r-查准率值都比现有对比方法的检索结果高,效果显著,说明本发明方法的检索性能均优于对比方法,能提高印尼-英跨语言信息检索性能,减少跨语言信息检索中查询漂移和词不匹配问题,具有很高的应用价值和广阔的推广前景。
附图说明
图1为本发明基于加权模式挖掘的印尼-英跨语言译后前件扩展方法的流程示意图。
具体实施方式
为了更好地说明本发明的技术方案,下面将本发明涉及的相关概念介绍如下:
1.特征词关联规则的前件和后件:设x、y是任意的特征词项集,将形如x→y的蕴含式称为特征词关联规则,其中,x称为规则前件,y称为规则后件。
2.印尼-英跨语言译后前件扩展:
从印尼-英跨语言检索初检结果前列相关文档集中挖掘那些后件是译后原查询词项项集的特征词关联规则,提取这些规则的前件作为扩展词,扩展词与译后原查询词项组合为新查询,再次检索英文文档,以便提高检索性能,这个过程称为印尼-英跨语言译后前件扩展。
3.特征词项集支持度
假设跨语言初检相关文档集由d1,d2,…,dn等文档组成,每篇文档特征词表示为t1,t2,…,tm,其对应的特征词权值为wi1,wi2,…,wim,则本发明提出特征词项集t支持度(weighteditemsetsupport,wis)的计算方法,如式(7)所示。
其中,nt、wt分别为特征词项集t在跨语言初检相关文档集中出现的频度和项集权值累加总和值,w为跨语言初检相关文档集中所有特征词权值总和值,n是跨语言初检相关文档集的文档总数,ki为项集t的长度(即项个数)。
式(7)的支持度计算公式将项集权值和频度与初检用户相关反馈英文文档集的特征词总权值和文档总数融合,克服了现有加权支持度计算的缺陷。
假设最小支持度阈值为ms,若wis(t)≥ms,则项集t是频繁项集。
4.加权关联规则置信度和相关系数
本发明提出特征词加权关联规则(t1→t2)置信度(weightedassociationruleconfidence,warc)计算方法如式(8)所示。
其中,i=i1∪i2,
本发明提出特征词项集相关系数(weighteditemsetcorrelationcoefficient,wicc)的计算方法如式(9)所示。
式(9)中,k1、k2项k12分别为特征词加权项集t1、t2以及项集(t1,t2)的项集长度,n1、n2和n12分别为特征词加权项集t1、t2以及项集(t1,t2)在英文文档索引库中出现的次数,w1、w2和w12分别为特征词加权项集t1、t2以及项集(t1,t2)在英文文档索引库中的项集权值,w和n定义同式(7)。
假设最小置信度阈值为mc,若warc(i1→i2)≥mc,且wicc(i1,i2)>0,则是i1→i2强加权关联规则模式。
5.初检用户相关英文文档集中特征词权值的计算
印尼-英跨语言初检用户相关反馈文档集是译后扩展词的挖掘数据源。
本发明提出初检用户相关反馈文档集中特征词权值wij的计算公式,如式(10)所示。
式(10)中,wij表示文档di中特征词tj的权值,dfj表示含有特征词tj的文档数量,n表示用户相关反馈文档集的文档总数,tfj,i表示特征词tj在文档di中的词频,max(tfi)表示文档di中出现的最大词频。
式(10)表明,在用户相关反馈文档集中,含有某个特征词的用户相关反馈文档数量越多,则该特征词与原查询越相关,越重要,所述特征词的权值就越高。
6.印尼-英跨语言译后前件扩展词权值的计算
本发明将加权置信度(warc)和相关系数(wicc)作为衡量印尼-英跨语言译后前件扩展词权值重要依据,提出前件扩展词权值we的计算公式,如式(11)所示。
we=max(warc)+max(wicc)(11)
式(11)中,max(warc)和max(wicc)分别表示关联规则置信度和相关系数中的最大值。当前件扩展词重复出现在多个加权关联规则模式时,会存在多个置信度和相关系数的情况,这时取最大值max(warc)和max(wicc)用来计算该扩展词的权值。
如图1所示,基于加权模式挖掘的印尼-英跨语言译后前件扩展方法,包括下列步骤:
步骤1.印尼语查询机器翻译为英文查询并检索英文文档,提取初检前列n篇英文文档,构建用户相关反馈文档集,预处理用户相关反馈文档集,具体步骤如下:
(1)印尼语用户查询机器翻译为英文并检索英文文档集得到初检前列英文文档。
(2)用户对初检前列n篇英文文档进行相关性判断得到初检相关文档,构建用户相关反馈文档集。
(3)预处理用户相关反馈文档集,构建英文文档索引库和特征词库,然后转入步骤2。
用户相关反馈文档集预处理内容是:去除英文停用词,通过词干提取得到特征词,计算特征词权值,最后构建英文文档索引库和特征词库。
本发明采用porter程序(详细见网址:http://tartarus.org/martin/porterstemmer)进行词干提取。
用户相关反馈文档集中特征词权值wij的计算公式,如式(12)所示。
式(12)中,wij表示文档di中特征词tj的权值,dfj表示含有特征词tj的文档数量,n表示用户相关反馈文档集的文档总数,tfj,i表示特征词tj在文档di中的词频,max(tfi)表示文档di中出现的最大词频。
式(1)表明,在用户相关反馈文档集中,含有某个特征词的用户相关反馈文档数量越多,则该特征词与原查询越相关,越重要,所述特征词的权值就越高。
步骤2.构建项权值排序项集,对特征词项集进行剪枝,结合译后原查询词项,对用户相关反馈文档集挖掘含有原查询词项的特征词频繁项集,具体步骤如下:
(1)挖掘特征词1_频繁项集l1,具体为如下3个步骤:
(1.1)从特征词库中提取特征词作为1_候选项集c1;
(1.2)扫描英文文档索引库以便统计文档索引库中文档总数n和累加所有特征词权值的总和w,统计特征词1_候选项集c1在英文文档索引库的权值
(1.3)如果wsup(c1)≥ms,ms为最小支持度阈值;则c1就是特征词1_频繁项集l1,添加到特征词频繁项集集合fis(frequentitemset)。
(2)构建权值排序k_候选项集,对k_候选项集进行剪枝,挖掘出特征词k_频繁项集,所述k≥2,具体为如下8个步骤:
(2.1)采用aproiri连接方法将特征词(k-1)_频繁项集lk-1进行自连接得到特征词k_候选项集ck,所述k≥2;
aproiri连接方法详见文献(agrawalr,imielinskit,swamia.miningassociationrulesbetweensetsofitemsinlargedatabase[c]//proceedingsofthe1993acmsigmodinternationalconferenceonmanagementofdata,washingtondc,usa,1993:207-216.)
(2.2)如果k=2,删除没有包含译后英文原查询词项的特征词k_候选项集ck,将包含有译后英文原查询词项的ck留下,然后,转入步骤(2.3);如果k>2,则直接转入步骤(2.3)。
(2.3)统计特征词k_候选项集ck在英文文档索引库的项权值(w1,w2,…,wk),并且排降序,使得w1≥w2≥…≥wk,这样就得到特征词权值排序k_候选项集ck=(i1,i2,…,ik)。
(2.4)对权值排序k_候选项集ck=(i1,i2,…,ik)的子项集c1=(i1),c12=(i1,i2),c123=(i1,i2,i3),…,c123…k-1=(i1,i2,…,ik-1)进行考察,如果存在某个子项集是非频繁的,则该项集ck是非频繁的,剪除该项集ck;
(2.5)对于余下的权值排序k_候选项集ck,如果
(2.6)对剪枝后余下的权值排序k_候选项集ck,根据权值排序k_候选项集ck在英文文档索引库中的出现次数
式(14)中,w和n的定义同式(13),
(2.7)如果wsup(ck)≥ms,则该权值排序k_候选项集ck就是特征词k_频繁项集lk,添加到特征词频繁项集集合fis。
(2.8)若特征词k_频繁项集lk为空集,则特征词频繁项集挖掘结束,转入如下步骤3,否则,k加1后转入步骤(2.1)继续循环。
步骤3.采用置信度-相关系数评价框架从频繁项集集合fis中挖掘那些后件是译后原查询词项的特征词加权关联规则,具体步骤如下:
(3.1)对于特征词频繁项集集合fis中每一个加权k_频繁项集lk,所述k≥2,构建任意一个lk的所有真子集项集集合;
(3.2)从真子集项集集合中任意取出两个真子集项集qt和et,且
式(15)中,k1、k2项k12分别为特征词项集qt、et以及项集(qt,et)的项集长度,n1、n2和n12分别为特征词项集qt、et以及项集(qt,et)在英文文档索引库中出现的次数,w1、w2和w12分别为特征词项集qt、et以及项集(qt,et)在英文文档索引库中的项集权值,w和n定义同式(13)。
(3.3)如果wicc(qt,et)>0,则计算特征词加权关联规则置信度(weightedassociationruleconfidence,warc)warc(et→qt),若warc(et→qt)≥最小置信度阈值mc,则关联规则et→qt是特征词强加权关联规则模式,加入到特征词加权关联规则模式集合war(weightedassociationrule)。warc(et→qt)的计算公式如式(16)所示。
式(16)中,k1、k12、n1、n12、w1和w12的定义同式(15)。
(3.4)如果lk的真子集项集集合中每个真子集项集当且仅当都被取出一次,则转入如下步骤(3.5),否则,转入步骤(3.2)再顺序进行各个步骤。
(3.5)从特征词频繁项集集合fis中重新取出另一个加权k_频繁项集lk,并转入步骤(3.1)进行新一轮特征词加权关联规则模式挖掘,直到fis中每一个k_频繁项集lk都被取出为止,这时特征词加权关联规则模式挖掘结束,转入如下步骤4。
步骤4.从特征词加权关联规则模式集合war中提取规则前件et作为前件扩展词,计算前件扩展词权值。
从特征词加权关联规则模式集合war中提取每个关联规则et→qt的前件et作为前件扩展词,该扩展词权值we的计算公式如式(17)所示。
we=max(warc)+max(wicc)(17)
式(17)中,max(warc)和max(wicc)分别表示特征词加权关联规则置信度中的最大值和相关系数中的最大值。当扩展词重复出现在多个加权关联规则模式时,会存在多个置信度和相关系数的情况,这时取其值最大值用来计算该扩展词的权值。
步骤5.前件扩展词与译后原查询词组合为新译后查询再次检索英文文档,完成印尼-英跨语言译后前件扩展。
实验设计与结果:
为了说明本发明方法的有效性,特进行了基于本发明方法和对比方法的印尼-英跨语言信息检索实验,比较本发明方法和对比方法的跨语言检索性能。
实验语料:
以信息检索领域中国际上普遍使用的跨语言标准数据集ntcir-5clir语料(见网址:http://research.nii.ac.jp/ntcir/permission/ntcir-5/perm-en-clir.html)作为本发明实验语料,即选择ntcir-5clir语料中的英文文档集mainichidailynews2000、2001年和koreatimes2001年的新闻文本,共有26224篇英文文档作为本发明实验数据,具体是mainichidailynews2000的新闻文本6608篇(简称m0数据集),mainichidailynews2001的5547篇(简称m1数据集)和koreatimes2001年的14069篇(简称k1数据集)。
ntcir-5clir语料有文档测试集、50个查询主题集及其对应的结果集,其中,每个查询主题类型有title、desc、narr和conc等4种类型,结果集有2种评价标准,即高度相关,相关的rigid标准和高度相关、相关和部分相关的relax标准。本发明实验用的查询主题类型选择title和desc类型,title查询属于短查询,以名词和名词性短语简要描述查询主题,desc查询属于长查询,以句子形式简要描述查询主题。
选择p@15和平均r-查准率作为本发明方法实验结果的评价指标。所述p@15是指对于测试查询返回的前15个结果的准确率,所述平均r-查准率是指对所有查询所对应的r-查准率的算术平均值,所述r-查准率是指当r个文档被检索后所计算的查准率。
由于ntcir-5clir语料没有提供印尼语查询版本,我们特请翻译机构的东盟语言专业翻译人员将其50个中文版查询主题语料人工翻译为印尼语查询作为本发明实验的源语言查询。
现有技术对比方法:
(1)对比方法1:印尼-英跨语言基准检索方法。所述对比方法1指将印尼语查询通过机器翻译为英文后检索英文文档得到的检索结果,检索过程中没有实行各种查询扩展。
(2)对比方法2:基于伪相关反馈的印尼-英跨语言查询译后扩展方法。所述对比方法2是基于文献(吴丹,何大庆,王惠临.基于伪相关反馈的跨语言查询扩展[j].情报学报,2010,29(2):232-239.)的跨语言查询扩展方法实现印尼-英跨语言查询译后扩展的检索结果。实验方法:提取印尼-英跨语言初检前列英文文档20篇构建初检相关文档集,提取特征词项并计算其权值,按权值降序排列将前列20个特征词项作为英文扩展词实现印尼-英跨语言查询译后扩展。
(3)对比方法3:基于完全加权正负关联规则的印尼-英跨语言查询译后前件扩展方法。所述对比方法3采用文献(周秀梅,黄名选.基于项权值变化的完全加权正负关联规则挖掘[j].电子学报,2015,43(8):1545-1554.)的完全加权正负关联规则挖掘技术对印尼-英跨语言初检用户相关反馈文档集挖掘特征词关联规则,将规则后件是原查询词项的关联规则前件作为扩展词,实现印尼-英跨语言查询译后扩展。实验参数是:最小置信度阈值mc为0.5,最小支持度阈值ms分别为0.2,0.25,0.3,0.35,0.4,最小兴趣度阈值mi为0.02。
实验结果如下:
运行本发明方法和对比方法的源程序,首先将50个印尼语查询主题的title和desc查询通过机器翻译系统翻译为英文,并检索英文文档,以实现印尼-英跨语言信息检索。实验时,对跨语言初检前列50篇英文文档进行用户相关反馈后得到初检用户相关反馈文档(为了简便,本实验中,将初检前列50篇文档中含有已知结果集中的相关文档视为初检相关文档)。通过实验,我们得到本发明方法和各对比方法的印尼-英跨语言检索结果p@15和平均r-查准率分别如表1至表2所示,实验过程中挖掘到3_项集,其中,本发明方法的实验参数是:最小置信度阈值mc=0.1,最小支持度阈值ms分别为0.0009,0.001,0.002,0.003,0.004,0.005。
表1本发明方法与对比方法的检索性能p@15值比较(title查询主题)
表2本发明方法与对比方法的检索性能平均r-查准率比较(title查询主题)
表3本发明方法与对比方法的检索性能p@15值比较(desc查询主题)
表4本发明方法与对比方法的检索性能平均r-查准率比较(desc查询主题)
表1至表4表明,本发明方法的跨语言检索结果p@15和平均r-查准率值都比3个对比方法检索结果的高,效果显著。实验结果表明,本发明方法是有效的,确实能提高印尼-英跨语言信息检索性能,具有很高的应用价值和广阔的推广前景。
- 还没有人留言评论。精彩留言会获得点赞!