一种异质网络大数据分类中多响应参数优化方法与流程
本发明涉及一种异质网络大数据分类,具体说是一种异质网络大数据分类中多响应参数优化方法。
背景技术:
异质网络中具有多种类型的边和节点,是一种信息网络,在异质网络中存在海量的语义信息,为了满足用户的需求,需要对异质网络中的大数据进行分类处理。而目前分类处理的方法可分为三个方向:
(1)vapnik等人提出了支持向量机,支持向量机是一种统计学习方法,在农业信息学、模式识别、生物信息学、网络入侵和故障诊断等领域中的应用较为频繁。支持向量机存在泛化能力强和学习速度快的特点,约束常数、支持向量机核函数参数以及核函数的类型对大数据分类的影响较大。对异质网络中的大数据进行分类时,需要人为确定一些参数,易出现不是最优参数的现象。当前大数据分类中参数优化方法存在分类效率低和分类结果准确率低的问题,需要对大数据分类中参数优化方法进行研究。
(2)丁胜、张进、李波提出了一种基于mea的svm参数优化方法,该方法将“反思”机制和“学习”机制引入思维进化算法中,通过子群体之间存在的信息共享特性进行学习,比较子群体之间的适应度值,根据比较结果进行反思,完成大数据分类参数的优化,将该方法优化后的参数应用在大数据分类中,分类所用的时间较长,存在分类效率低的问题。
(3)林怡、季昊魏等人提出了一种基于鱼群算法的分类参数优化方法,该方法首先对分类参数进行分析,采用仿生鱼群算法对正则化参数和小波核参数进行寻优,根据寻优结果建立参数优化后的分类模型,完成异质网络中大数据的分类,该方法得到的分类结果与实际结果不符,存在分类结果准确率低的问题。
(4)王震宇、梁雪春提出了一种基于cfoa的分类参数优化方法,该方法采用混沌果蝇优化算法对异质网络大数据分类中的重要参数进行调整,通过基于lozi’s映射的混沌算法对果蝇种群搜索和多样性的遍历性进行优化,避免出现局部最优,完成分类参数的优化,该方法分类所用的时间较长,存在分类效率低的问题。
综上所述,提出一种异质网络大数据分类中多响应参数优化方法。
技术实现要素:
为解决前面揭示的问题,本发明的目的是提供一种异质网络大数据分类中多响应参数优化方法。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
采用当前方法对大数据分类中的参数进行优化时,计算样本分布半径的期望值,根据计算结果得到不同类型样本的分布期望半径。设置目标函数,通过样本分布半径的期望值和样本的分布期望半径得到目标函数的最小值,完成大数据分类参数的优化。
附图说明
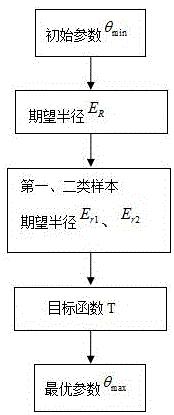
图1是本发明一种异质网络大数据分类中多响应参数优化方法工作流程图;
图2是本发明一种异质网络大数据分类中多响应参数优化方法中优化参数选择工作原理图;
具体实施方式
本发明一种异质网络大数据分类中多响应参数优化方法,包括以下具体的优化参数选择和多响应参数优化方法。
参考图1所示,本发明一种异质网络大数据分类中多响应参数优化方法实现的具体步骤如下:
设
设
式中,
设
式中,
设
式中,
给参数
本发明一种异质网络大数据分类中多响应参数优化方法中多响应参数优化方法工作原理,具体如下:
对异质网络大数据分类中的多响应参数进行优化之前,需要选择优化的参数。异质网络大数据分类中多响应参数优化方法在支持向量机理论基础上对参数进行分析,确定需要进行优化的参数。
采用支持向量机分类方法对异质网络中的大数据进行分类时,将低维线性问题通过核函数映射到高维空间中,将不可分问题转变为可分问题。最初的支持向量机优化问题如下:
式中,
式中,
通常情况下rbf核为支持向量机默认的核函数,设
通过上述分析得到异质网络大数据分类中需要优化的多响应参数,分别是惩罚因子
本发明一种异质网络大数据分类中多响应参数优化方法中多响应参数优化方法工作原理,具体如下:
采用小生境遗传算法对异质网络大数据分类中存在的多响应参数进行优化,对异质网络种群中的个体进行编码,计算个体的适应度函数,根据计算结果得到个体共享后适应度,通过迭代选择、交叉、变异,获得最优种群,完成异质网络大数据分类中多响应参数的优化。
在异质网络中随机生成种群,将其作为初始种群,通过浮点数编码方法对种群个体进行编码。采用nloo方法对支持向量机的分类性能进行评价,对异质网络中的
将目标函数与
设
式中,
式中,
设
设
式中,
式中,
通过变异概率
- 还没有人留言评论。精彩留言会获得点赞!