一种基于多任务人工神经网络的刑期预测方法与流程
本发明涉及一种基于多任务人工神经网络刑期预测方法,属于自然语言处理技术领域。
背景技术:
刑期预测问题是裁判文书信息挖掘与分析重要的基本问题之一,其目标是根据犯罪事实描述,预测此犯罪事实在法律等相关信息基础上,将会被处以的刑期。可用于后续自动审判、法律智能咨询。近年来,以神经网络为基础的自然语言处理技术发展和应用极大地推动了裁判文书信息处理与挖掘的发展。传统基于人工神经网络的刑期预测方法基于犯罪事实描述,直接预测刑期。
随着人工智能相关技术的发展,利用自然语言处理方法对裁判文书进行处理、分析与应用已成为研究的热点。通过刑期预测方法,可根据犯罪事实描述,利用现有的大规模显示裁判文书中包含的信息,给出准确的刑期预测,并且其中涉及到的各种中间计算结果可以进一步应用于诸如罪名预测、文书检索等领域。基于刑期预测方法,可以实现自动审判、法律智能咨询等服务,为法律相关行业提供高效、有效的参考。
基于人工神经网络的刑期预测方法虽然在一定程度上实现了智能化地裁判文书信息挖掘与利用,但是,传统的基于人工神经网络的刑期预测方法,根据犯罪事实描述直接预测刑期,未能充分利用裁判文书中包含的大量信息,忽略了刑期与其他维度各种信息的相关关系,基于单任务人工神经网络的刑期预测方法,仅仅以犯罪事实为输入、仅以刑期为输出,忽略了裁判文书中各个维度的有用信息之间的关联,例如罪名、嫌疑人基本信息、犯罪事实描述的属性信息,因此,导致模型训练的收敛性差、实际预测结果偏差大等问题,难以满足实际应用需求。
因此,如何充分利用裁判文书中所包含的各个维度的有用信息,实现准确、有效地刑期预测,是现在要解决的重要问题。
技术实现要素:
针对现有技术的不足,本发明提供了一种基于多任务人工神经网络刑期预测方法;
本发明可以有效的利用裁判文书中包含的多维度信息,来提高刑期预测的精度。
术语解释:
1、分词处理:是指将一个文本以词语为最小单元分开,即将一句话拆分成单个词语存储,以便于下一步的构建词典。
2、最大化池化方式,是指在一个矩阵中,根据核的大小,取核所覆盖范围内的最大值最为该区域的代表。
3、自注意力机制,根据人的大脑处理信息的原理,人在处理眼睛看到的信息或者耳朵听到的信息的时候,通常注意力只会放在重点区域或者重点信息段上面。本发明的中的注意力机制是指在特征信息从lstm层传输到下一层的时候,有一个权重矩阵将对于结果重要的信息放大传输到下一层,不重要的信息减小比重。
4、神经网络前向传播计算,是指信息流在网络里向前传播,这里的前是指从输入到输出,每一层的结果都是经过上一层的结果经过本层的权重矩阵加上偏置项,最终经过激活函数得到最终输出。
5、全连接神经网络:第n层的每个节点都与第n-1层的所有节点相连,即第n层的每个节点都是上一层的所有节点的加权和。
6、反向传播原理,是指信息反向传播,根据模型最后预测器的输出和目标之间的误差,反向调整模型中的参数,以使输出与真实值之间的误差尽量的小。
本发明的技术方案为:
一种基于多任务人工神经网络刑期预测方法,包括步骤如下:
(1)对原始数据进行预处理:
抽取所需信息,实现数据结构化,构造结构化数据集;
(2)训练阶段:
把结构化数据集随机分为两部分,比例为8:2,大的部分数据集打乱后分成n份,每次取n-1份做训练,1份做验证,做n次交叉验证,评估模型性能,小的部分作为测试数据集;获得当前训练阶段所需要的训练数据,将训练数据依次进行分词处理、词向量映射后,输入模型,获得输出;
所述模型包括词向量嵌入层、双向lstm层、最大池化层、注意力机制层、平均池化层、分类器、计算损失层、更新参数层;所述词向量嵌入层、所述双向lstm层、所述最大池化层依次连接;所述双向lstm层、所述注意力机制层、所述平均池化层依次连接;所述分类器包括罪名分类器、法律属性分类器、刑期回归预测器,所述罪名分类器、所述法律属性分类器、所述刑期回归预测器都是二分类;所述最大池化层、所述计算损失层、所述更新参数层依次连接;所述双向lstm层、所述注意力机制层、所述法律属性分类器、所述计算损失层、所述更新参数层依次连接;所述最大池化层、所述平均池化层均连接所述刑期回归预测器,所述刑期回归预测、所述计算损失层、所述更新参数层依次连接;所述罪名分类器为m分类,m罪名类型的数量;所述法律属性分类器有18个;包括步骤如下:
a、所述词向量嵌入层将样本从原始数据转换为词向量;方便后面模型输入;
b、所述双向lstm层以词向量为输入,将词向量转换为具有某种语义的特征,输出固定长度的特征向量;
c、所述最大池化层以双向lstm层输出的特征向量为输入,作用是简化模型复杂度使之容易计算,提取主要特征,输出一维向量;
d、所述注意力机制层以双向lstm层输出的特征向量为输入,从特征向量中根据不同的任务提取出不同的信息,输出为每个任务一个一维向量,即法律属性的特征向量;
e、所述平均池化层将所述注意力机制层的输出的多个一维向量合并为一个矩阵,并计算成一个一维向量;作用与最大池化层一样,输出为一个一维向量;
f、所述计算损失层将所述最大池化层的输出与所述平均池化层的输出拼接为一个一维向量,该一维向量经过两层神经网络转化为长度和数据标签一样形式的数据,对于预测罪名和法律属性的分类任务,采用交叉熵形式分类误差,计算输出与目标的误差;对于刑期回归任务,采用均方差形式进行计算误差,计算目标与实际刑期之间的均方误差;将所有误差累计,称之为总损失;
g、所述罪名分类器将所述最大池化层的输出与所述平均池化层的输出拼接成的一个一维向量,变为一个267长度(即为现阶段本发明已有数据库中罪名的数量)的向量,归一化处理后,数值最大的对应位置上的罪名类型即为本条数据预测的罪名;
h、所述法律属性分类器将所述注意力机制层的输出向量变为一个2长度的向量,归一化处理后,数值最大的对应位置上的法律属性型即为本条数据预测的法律属性,即第一个位置的数字大,代表该属性为是,第二个位置的数据大,代表该属性为否;
i、所述刑期回归预测器将所述最大池化层的输出与所述平均池化层的输出拼接成的一个一维向量,再加上嫌疑人基本信息,变为一个数字,该数字即是对该条数据刑期的预测;嫌疑人基本信息为一维,长度为3,包括年龄、性别,是否有前科;
j、所述更新参数层采用反向传播原理,计算输出目标对各个参数节点的梯度,每一层的梯度都是间接由上一层的梯度求出,根据梯度下降的方向更新参数,参数是指上述各层中的参数,包括所述词向量嵌入层的词向量、所述双向lstm层的参数、所述注意力机制层的参数、所述罪名分类器的参数、所述法律属性分类器的参数和所述刑期回归预测器的参数,直到达到预设的迭代次数,将误差最小的模型保存至本地;
(3)测试阶段:
加载训练阶段中保存的模型,对测试数据集进行采样,获得测试所用数据,将测试所用数据输入模型,依次进行分词、词向量映射、神经网络前向传播计算,输出刑期预测值,显示预测刑期,并与实际刑期进行比对,评估模型性能。
进一步优选的,所述步骤(2)中,对于预测罪名和中间属性的分类任务,采用交叉熵形式分类误差,计算输出与目标的误差;交叉熵计算公式如式(ⅰ)所示:
式(ⅰ)中,y′i为标签中的第i个值,yi为对应的预测分量,当交叉熵越小时,说明分类越准确。hy′(y)是指交叉熵;
进一步优选的,所述步骤(2)中,对于刑期回归任务,采用均方差形式进行计算误差,计算目标与实际刑期之间的均方误差;均方差计算公式如式(ii)所示:
式(ii)中,y′i为标签中的第i个值,yi为对应的预测分量,当均方误差越小时,说明预测刑期与真实刑期越接近。msey′(y)指均方差;
根据本发明优选的,所述步骤(1)中,
所需信息包括犯罪事实描述与嫌疑人基本信息数据,嫌疑人基本信息数据包括年龄、性别、是否有前科;
实现数据结构化,是指:
对每一个犯罪嫌疑人的年龄,进行标准处理,如式(ⅰ)所示:
式(ⅲ)中,x为输入数据,μ为输入数据的均值,σ为输入数据的方差,x′为标准化处理后的数据;
对每一个犯罪嫌疑人的性别,0表示男性,1表示女性;
对每一个犯罪嫌疑人的是否有前科信息,0表示无前科信息,1表示有前科信息。
根据本发明优选的,所述步骤(2)中,犯罪事实描述结构化,将犯罪事实依次进行分词处理、词向量映射,包括:对犯罪事实描述与嫌疑人基本信息数据进行分词处理,并将分词结果中的每一个词映射为对应的词向量,即得到犯罪事实描述的特征向量。
进一步优选的,所述分词处理,包括分词、截断或填充,分词后,词语数目多于300词的,截断为300词,不足300词的,采用特殊填充字符填充至300词。按照上述结构化方式将犯罪事实描述进行结构化处理。
进一步优选的,所述词向量映射中,词向量维度采用300维。
根据本发明优选的,所述步骤(2)中,
对获得的各个向量,分别输入各自的后续人工网络中;
将犯罪事实描述的特征向量输入罪名分类器中,该分类器采用两层全连接神经网络(已在名词解释中给出),计算其在469项罪名上的概率分布;
所述法律属性分类器有18个,分别表示金额是否巨大、是否涉毒、是否涉黄、是否以营利为目的、是否非法占有、是否团伙作案、是否涉枪、是否涉黑、是否国家工作人员、是否暴力、是否致人受伤、是否故意为之、是否生产过程犯罪、是否涉恐、是否胁迫他人、是否多次犯罪、是否存在欺骗行为、情节是否严重;每个法律属性分类器包括两层人工神经网络,每个都是二分类器,即最后的预测为是或否中的一个;
将与犯罪事实各个法律相关属性的特征向量(即注意力机制的输出)输入各自的所述法律属性分类器中;
所述刑期回归预测器采用三层全连接神经网络;将所述最大池化层的输出与所述平均池化层的输出拼接成的一个一维向量,再加上嫌疑人基本信息,输入所述刑期回归预测器中,该神经网络采用三层全连接神经网络,嫌疑人基本信息为一维,长度为3,包括年龄、性别,是否有前科;输出刑期的连续值预测,连续值以年为单位,采用小数表示月份。
对获得的各个输出,丢弃罪名预测和18项属性预测最后输出,或者这部分信息另做他用,而只将刑期输出并显示、保存。
本发明的有益效果为:
1、与单任务刑期预测的方法相比,本发明采用多任务模型,不仅可以预测刑期,同时兼顾罪名预测,实现了多效果同时实现。
2、本发明将刑期预测与罪名之间的联系通过神经网络实现,通过罪名预测提高了刑期预测的准确率。
3、与不采用多任务人工神经网络的刑期预测方法相比,本发明提出的方法通过法律文书中引用的法律条款所设计的关键属性信息作为多任务预测目标,实现了对刑期预测任务的辅助作用。
4、本发明独立设计裁判文书数据集,将数据结构化,在一定程上对最终目标的提高起到了促进作用,奠定了坚固的基础。
附图说明
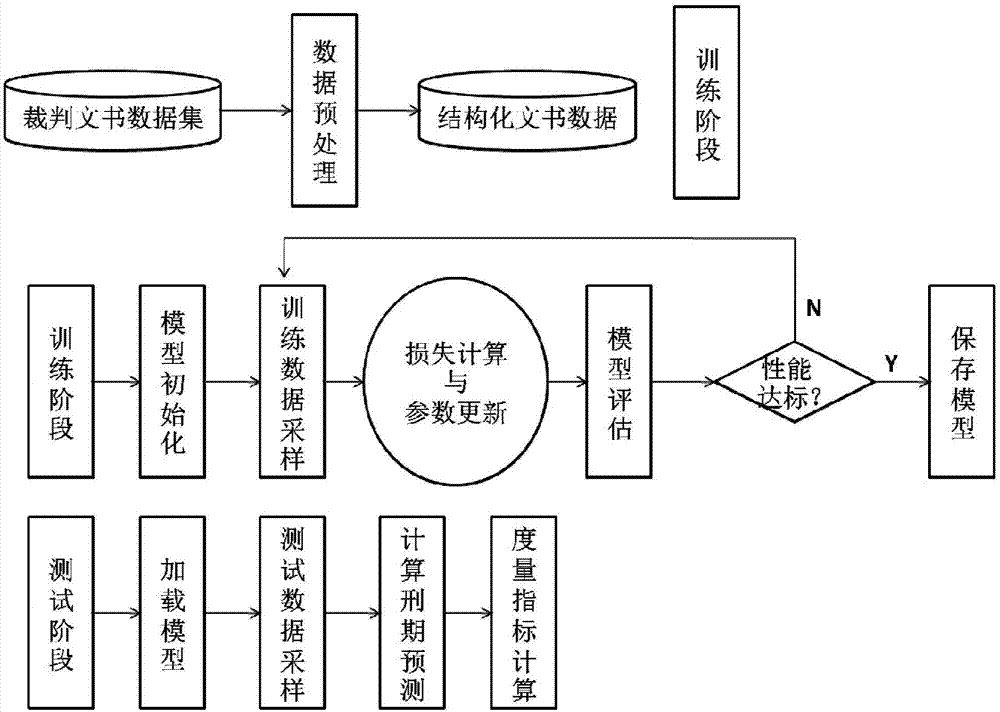
图1是基于多任务人工神经网络的刑期预测方法示意框图;
图2是本发明的刑期预测模型的示意框图;
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例1
一种基于多任务人工神经网络刑期预测方法,如图1所示,包括步骤如下:
(1)对原始数据进行预处理:
抽取所需信息,实现数据结构化,构造结构化数据集;
(2)训练阶段:
把结构化数据集随机分为两部分,比例为8:2,大的部分数据集打乱后分成n份,每次取n-1份做训练,1份做验证,做n次交叉验证,评估模型性能,小的部分作为测试数据集;获得当前训练阶段所需要的训练数据,将训练数据依次进行分词处理、词向量映射后,输入模型,获得输出;
模型如图2所示,模型包括词向量嵌入层、双向lstm层、最大池化层、注意力机制层、平均池化层、分类器、计算损失层、更新参数层;词向量嵌入层、双向lstm层、最大池化层依次连接;双向lstm层、注意力机制层、平均池化层依次连接;分类器包括罪名分类器、法律属性分类器、刑期回归预测器,罪名分类器、法律属性分类器、刑期回归预测器都是二分类;最大池化层、计算损失层、更新参数层依次连接;双向lstm层、注意力机制层、法律属性分类器、计算损失层、更新参数层依次连接;最大池化层、平均池化层均连接刑期回归预测器,刑期回归预测、计算损失层、更新参数层依次连接;罪名分类器为m分类,m罪名类型的数量;法律属性分类器有18个;包括步骤如下:
a、词向量嵌入层将样本从原始数据转换为词向量;方便后面模型输入;
b、双向lstm层以词向量为输入,将词向量转换为具有某种语义的特征,输出固定长度的特征向量;
c、最大池化层以双向lstm层输出的特征向量为输入,作用是简化模型复杂度使之容易计算,提取主要特征,输出一维向量;
d、注意力机制层以双向lstm层输出的特征向量为输入,从特征向量中根据不同的任务提取出不同的信息,输出为每个任务一个一维向量,即法律属性的特征向量;
e、平均池化层将注意力机制层的输出的多个一维向量合并为一个矩阵,并计算成一个一维向量;作用与最大池化层一样,输出为一个一维向量;
f、计算损失层将最大池化层的输出与平均池化层的输出拼接为一个一维向量,该一维向量经过两层神经网络转化为长度和数据标签一样形式的数据,对于预测罪名和法律属性的分类任务,采用交叉熵形式分类误差,计算输出与目标的误差;对于刑期回归任务,采用均方差形式进行计算误差,计算目标与实际刑期之间的均方误差;将所有误差累计,称之为总损失;
g、罪名分类器将最大池化层的输出与平均池化层的输出拼接成的一个一维向量,变为一个267长度(即为现阶段本发明已有数据库中罪名的数量)的向量,归一化处理后,数值最大的对应位置上的罪名类型即为本条数据预测的罪名;
h、法律属性分类器将注意力机制层的输出向量变为一个2长度的向量,归一化处理后,数值最大的对应位置上的法律属性型即为本条数据预测的法律属性,即第一个位置的数字大,代表该属性为是,第二个位置的数据大,代表该属性为否;
i、刑期回归预测器将最大池化层的输出与平均池化层的输出拼接成的一个一维向量,再加上嫌疑人基本信息,变为一个数字,该数字即是对该条数据刑期的预测;嫌疑人基本信息为一维,长度为3,包括年龄、性别,是否有前科;
j、更新参数层采用反向传播原理,计算输出目标对各个参数节点的梯度,每一层的梯度都是间接由上一层的梯度求出,根据梯度下降的方向更新参数,参数是指上述各层中的参数,包括词向量嵌入层的词向量、双向lstm层的参数、注意力机制层的参数、罪名分类器的参数、法律属性分类器的参数和刑期回归预测器的参数,直到达到预设的迭代次数,将误差最小的模型保存至本地。;
(3)测试阶段:
加载训练阶段中保存的模型,对测试数据集进行采样,获得测试所用数据,将测试所用数据输入模型,依次进行分词、词向量映射、神经网络前向传播计算,输出刑期预测值,显示预测刑期,并与实际刑期进行比对,评估模型性能。
实施例2
根据实施例1所述的一种基于多任务人工神经网络刑期预测方法,其区别在于:
步骤(2)中,对于预测罪名和中间属性的分类任务,采用交叉熵形式分类误差,计算输出与目标的误差;交叉熵计算公式如式(ⅰ)所示:
式(ⅰ)中,y′i为标签中的第i个值,yi为对应的预测分量,当交叉熵越小时,说明分类越准确。hy′(y)是指交叉熵;
步骤(2)中,对于刑期回归任务,采用均方差形式进行计算误差,计算目标与实际刑期之间的均方误差;均方差计算公式如式(ii)所示:
式(ii)中,y′i为标签中的第i个值,yi为对应的预测分量,当均方误差越小时,说明预测刑期与真实刑期越接近。msey′(y)指均方差;
所述步骤(1)中,
所需信息包括犯罪事实描述与嫌疑人基本信息数据,嫌疑人基本信息数据包括年龄、性别、是否有前科;
实现数据结构化,是指:
对每一个犯罪嫌疑人的年龄,进行标准处理,如式(ⅰ)所示:
式(ⅲ)中,x为输入数据,μ为输入数据的均值,σ为输入数据的方差,x′为标准化处理后的数据;
对每一个犯罪嫌疑人的性别,0表示男性,1表示女性;
对每一个犯罪嫌疑人的是否有前科信息,0表示无前科信息,1表示有前科信息。
步骤(2)中,犯罪事实描述结构化,将犯罪事实依次进行分词处理、词向量映射,包括:对犯罪事实描述与嫌疑人基本信息数据进行分词处理,并将分词结果中的每一个词映射为对应的词向量,即得到犯罪事实描述的特征向量。
分词处理,包括分词、截断或填充,分词后,词语数目多于300词的,截断为300词,不足300词的,采用特殊填充字符填充至300词。按照上述结构化方式将犯罪事实描述进行结构化处理。
词向量映射中,词向量维度采用300维。
步骤(2)中,对获得的各个向量,分别输入各自的后续人工网络中;
将犯罪事实描述的特征向量输入罪名分类器中,该分类器采用两层全连接神经网络(已在名词解释中给出),计算其在469项罪名上的概率分布;
法律属性分类器有18个,分别表示金额是否巨大、是否涉毒、是否涉黄、是否以营利为目的、是否非法占有、是否团伙作案、是否涉枪、是否涉黑、是否国家工作人员、是否暴力、是否致人受伤、是否故意为之、是否生产过程犯罪、是否涉恐、是否胁迫他人、是否多次犯罪、是否存在欺骗行为、情节是否严重;每个法律属性分类器包括两层人工神经网络,每个都是二分类器,即最后的预测为是或否中的一个;
将与犯罪事实各个法律相关属性的特征向量(即注意力机制的输出)输入各自的法律属性分类器中;
法律属性及对应的罪名如表1所示:
表1
刑期回归预测器采用三层全连接神经网络;将最大池化层的输出与平均池化层的输出拼接成的一个一维向量,再加上嫌疑人基本信息,输入刑期回归预测器中,该神经网络采用三层全连接神经网络,嫌疑人基本信息为一维,长度为3,包括年龄、性别,是否有前科;输出刑期的连续值预测,连续值以年为单位,采用小数表示月份。
对获得的各个输出,丢弃罪名预测和18项属性预测最后输出,或者这部分信息另做他用,而只将刑期输出并显示、保存。
- 还没有人留言评论。精彩留言会获得点赞!