一种基于距离向量的裁判文书推荐方法与流程
本发明涉及一种基于距离向量的裁判文书推荐方法,属于长文本分析的技术领域。
背景技术:
随着人工智能技术的发展与信息时代的到来,人们每天接触的消息量越来越大,逐渐从信息匮乏的时代走向了信息过载的时代,如何从中得到有效的信息显得尤为重要。由于目前对大数据的处理方法向着智能化、自动化的方向发展,各种工作也逐渐由智能机器所代替,人类社会与智能机器的交叉越来越多,在这样的时代背景下,智能、方便的人机交互变得越来越重要。在上述所讲到的消息中,不少都是以文本的形式存在的,比如监狱服刑人员的短信,法院裁判文书等等,促进了文本的产生与发展。
文本分析技术旨在通过计算机技术对无结构的文本字符串中包含的词、语法、语义等信息进行表示、理解和抽取,挖掘和分析出其中存在的事实以及隐含的立场、观点和价值,进而推断出文本生成者的意图和目的。文本分析是典型的自然语言处理工作,是文本挖掘、信息检索领域的一个基本研究问题。
在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性。
在神经网络学习中,通过将word映射成连续(高维)向量,这样通过训练,就可以把长文本内容的处理简化为k维向量空间中向量运算,而向量空间上的相似度可以用来表示文本上的相似度。
目前的文本分析技术多为短文本分析技术,面对多为长文本的裁判文书,语法不规则,繁冗复杂,罪名众多,且罪名由多种因素决定的情况下,现有技术难以有效解决目前面临的问题。如何在海量的数据中,找到有效的与当前处理案件罪名相同且情节相同或者相似的案件描述是本发明要处理的问题。
技术实现要素:
针对现有技术的不足,本发明提供了一种基于距离向量的裁判文书推荐方法。
发明概述:
本发明解决的问题主要是长文本的多分类以及推荐问题。将依据法院文书犯罪事实描述,将罪名的分类以及推荐任务转换为根据语义相似度的长文本匹配问题以及各文本在空间中的距离向量问题,同时在判定罪名时对其进行推荐。在神经网络学习中,通过将word映射成连续(高维)向量,这样通过训练,就可以把长文本内容的处理简化为k维向量空间中向量运算,而向量空间上的相似度可以用来表示文本上的相似度。
术语解释:
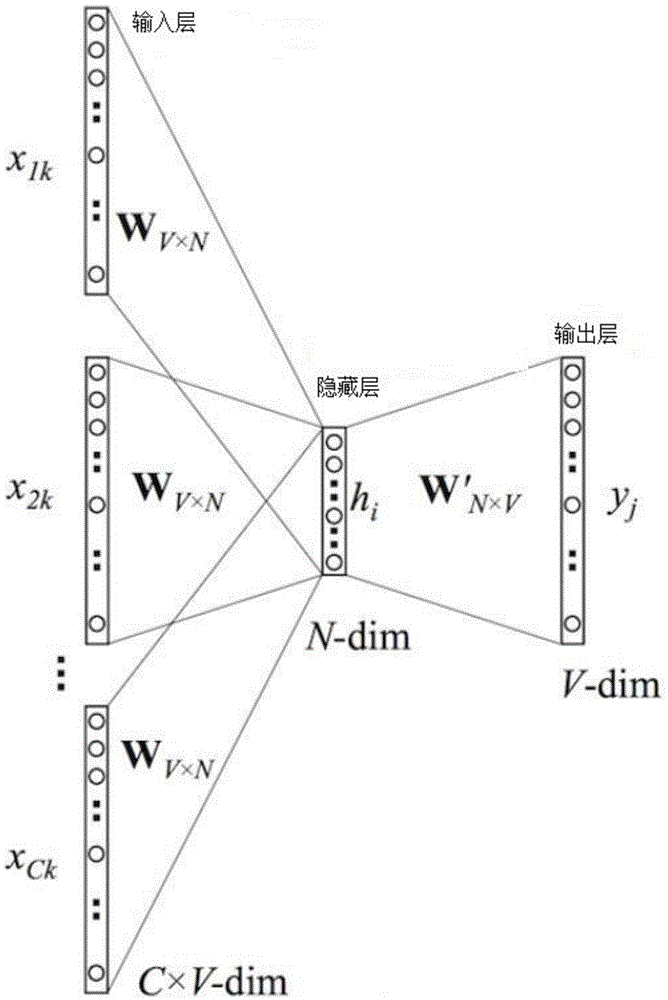
1、cbow神经网络模型,word2vec中的cbow神经网络模型,输入层是由one-hot编码的输入上下文{x1x1,…,xcxc}组成,其中窗口大小为c,词汇表大小为v。隐藏层是n维的向量。最后输出层是也被one-hot编码的输出单词yy。被one-hot编码的输入向量通过一个v×nv×n维的权重矩阵ww连接到隐藏层;隐藏层通过一个n×vn×v的权重矩阵w′w′连接到输出层。
2、余弦相似度:余弦相似度用空间中两个向量夹角的余弦值作为衡量两个个体间差异大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似;如果a和b向量夹角较大,或者反方向,可以说两个向量有很低的相似性,或者两个向量代表的文本基本不相似。
本发明的技术方案为:
一种基于距离向量的裁判文书推荐的方法,包括步骤如下:
(1)数据预处理:本发明申请采用公开的法院文书数据集进行结果评测,由于公开的数据集是原始数据集,不符合模型的输入要求,需对数据进行预处理。对原始数据进行筛选,原始数据为裁判文书,将裁判文书中包含的犯罪事实描述部分利用规则的方法抽取出来,做中文分词处理,得到文书的全部数据集;将文书的全部数据集打乱后,分成若干份,设定为n,其中n-1份做训练数据集,剩下1份做测试数据集;
(2)训练词向量,获取语义信息:将上述步骤(1)得到的训练数据集输入cbow神经网络模型进行训练,得到训练集中每一个词相应的词向量,构成词向量表;
进一步优选的,cbow神经网络模型中,训练窗口大小为8(即考虑一个词的前八个和后八个),每个单词的向量维度可以自行指定,本模型使用的是200,迭代次数是15次。cbow神经网络模型中使用的参数大小可根据具体模型的需要自行指定。
(3)针对具体任务建立双向lstm模型,利用双向lstm(双向循环神经网络)编码每个长文本的语义信息:单向lstm可以按照人类的阅读顺序从一句话的第一个字记忆到最后一个字,这种lstm结构只能捕捉到上文信息,无法捕捉到下文信息,通过双向lstm获取每个长文本的上文信息和下文信息,即获取该文本数据的语义特征和时序特征;双向lstm包括两个方向不同的lstm,一个lstm按照句子中词的顺序从前往后读取数据,获得上文信息;另一个lstm从后往前按照句子词序的反方向读取数据,获得下文信息;上下文信息是由整个句子提供的,自然包含比较抽象的语义信息(句子的意思),这种方法的优点是充分利用了lstm对具有时序特点的序列数据的处理优势。
进一步优选的,罪名作为远程标签,并附上10个属性,包括profitpurpose(以营利为目的)、buyingandselling(买卖关系)、death(死亡)、violence(暴力行为)、stateorgan(国家机关)、publicplace(公共场所)、illegalpossession(非法占有)、physicalinjury(人身伤害)、intentionalcrime(故意犯罪)和production(涉及生产过程);远程标签及每个属性标签的取值为0、1或者2,0表示文本中不具备该标签特征,1表示文本中具备该标签特征,2表示文本中该特征不可用;将每个文本所对应的罪名及10个属性与上述全部数据集做连接,得到符合双向lstm模型输入的数据集;
(4)训练模型,通过步骤(3)建立的双向lstm模型获取各个文本的特征向量,送入softmax分类器,对罪名进行分类;
所述步骤(3)中,双向lstm模型通过构造两个循环神经网络实现以两个不同的方向获取文本信息,同时这两层都连接相同的输入层。这个结构能够提供给上一层中每个单元结构完整的上下文信息,其中一层在同一时刻向前传递,更新所有隐藏层的信息;另一层信息的传播与上一层相反,通过先计算输出层然后得到不同方向的隐藏层值;由双层双向lstm模型训练得到的输出作为罪名分类的特征向量,在双向lstm之后,经过两层全连接层,激活函数为relu,将第二层全连接层的输出作为第三层全连接层的输入,该激活函数为softmax函数,对罪名进行分类。
根据本发明优选的,在做罪名分类的过程中,将各项罪名以及其对应的属性预测值以文档的形式做输出保存,属性预测值是指属性标签的取值,并与本发明中采用的测试数据集做索引关联,通过计算各个罪名映射到空间中的高维向量之间的余弦相似度,并以第一个犯罪事实描述作为基准犯罪事实描述,通过将两两向量之间的余弦相似度从大到小进行排序,推荐出在相同罪名下,犯罪情节相同或者相似的前n个犯罪事实描述,n的取值范围为15-20。用来协助法官在查找、处理相似案件时的判定罪名及刑期等工作。
进一步优选的,假设文本x和文本y对应的向量分别为x和y,则余弦相似度的计算公式如式(ⅰ)所示:
根据本发明优选的,所述步骤(2),通过双向lstm获取文本的上文信息和下文信息,即获取该文本数据的语义特征和时序特征;包括步骤如下:
a、求取t时刻lstm单元中的输入门的值it,lstm单元指的是细胞状态,由于lstm拥有三个门,每个门由一个sigmoid神经网络层和一个元素级相乘操作组成,sigmoid层输出0-1之间的值,每个值表示对应的部分信息是否应该通过。0值表示不允许信息通过,1值表示允许所有信息通过。这种结构使得lstm有能力对细胞状态添加或者删除信息,来保护和控制细胞状态,如式(ⅱ)所示:
it=σ(wihht-1+wixxt+bi)(ⅱ)
式(ⅱ)中,σ表示sigmoid激活函数;wih是输入门中输入项ht-1对应的权重矩阵,wix是输入门中输入项xt对应的权重矩阵,ht-1是上一时刻隐藏层的输出,xt是当前时刻的输入,bi是输入门的偏置项;
b、求取t时刻lstm单元中的遗忘门的值ft,如式(ⅲ)所示:
ft=σ(wfhht-1+wfxxt+bf)(ⅲ)
式(ⅲ)中,wfh是遗忘门中输入项ht-1对应的权重矩阵,wfx是遗忘门中输入项xt对应的权重矩阵,bf是遗忘门的偏置项;
c、求取t时刻lstm单元中的输出门的值ot,如式(ⅳ)所示:
ot=σ(wohht-1+woxxt+bo)(ⅳ)
式(ⅳ)中,woh是输出门中输入项ht-1对应的权重矩阵,wox是输出门中输入项xt对应的权重矩阵,bo是输出门的偏置项;
d、求取t时刻lstm单元的输入状态gt,如式(ⅴ)所示:
gt=tanh(wghht-1+wgxxt+bg)(ⅴ)
式(ⅴ)中,wgh是单元状态中输入项ht-1对应的权重矩阵,wgx是单元状态中输入项xt对应的权重矩阵,bg是单元状态的偏置项,tanh表示双曲正切函数,用作激活函数;
e、求取t时刻的lstm单元的细胞状态ct,如式(ⅵ)所示:
ct=it⊙gt+ft⊙ct-1(ⅵ)
式(ⅵ)中,ct-1是上一时刻的细胞状态,⊙表示按元素乘;
f、求t时刻lstm单元的隐藏层状态ht,如式(ⅶ)所示:
ht=ot⊙tanh(ct)(ⅶ)
式(ⅶ)中,tanh表示双曲正切函数用作激活函数;ot代表当前时刻的输出,ct代表当前时刻的细胞状态。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免无关紧要的内容进入记忆。因此文本数据经过lstm单元之后,在各种门结构的控制作用下,输出的特征表示既包含有丰富的语义特征,又含有丰富的时序特征。
本发明的有益效果为:
1、本发明所述基于距离向量的裁判文书推荐方法,利用双向lstm模型结构简单,同时兼顾了裁判文书的上下文语义信息,易于数据的训练。
2、本发明所述基于距离向量的裁判文书推荐方法,提出了利用罪名作为罪名分类以及推荐的远程标签,想法新颖,在罪名作为远程标签的基础上,利用10个附加属性作为辅助罪名分类的标签。
3、本发明所述基于距离向量的裁判文书推荐方法,针对性强,通过计算各个文书在空间中的距离向量的远近,进而推荐出数个在相同罪名下,犯罪情节相同或者相似的裁判文书,此举在法官查找、处理类似案件时对罪名以及的刑期的判定时提供了有力帮助,极大的减少了法官等工作人员的工作量,效果显著。
附图说明
图1为本发明cbow神经网络模型的结构框图;
图2为本发明基于距离向量的裁判文书推荐方法流程框图。
图3为本发明基于距离向量的裁判文书推荐方法之罪名分类流程框图。
图4为本发明基于距离向量的裁判文书推荐方法之余弦相似度计算过程示意图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例1
一种基于距离向量的裁判文书推荐的方法,如图2所示,包括步骤如下:
(1)数据预处理:本发明申请采用公开的法院文书数据集进行结果评测,由于公开的数据集是原始数据集,不符合模型的输入要求,需对数据进行预处理。对原始数据进行筛选,原始数据为裁判文书,将裁判文书中包含的犯罪事实描述部分利用规则的方法抽取出来,做中文分词处理,得到文书的全部数据集;将文书的全部数据集打乱后,分成若干份,设定为n,其中n-1份做训练数据集,剩下1份做测试数据集;
(2)训练词向量,获取语义信息:将上述步骤(1)得到的训练数据集输入cbow神经网络模型进行训练,cbow神经网络模型的结构框图如图1所示,得到训练集中每一个词相应的词向量,构成词向量表;
(3)针对具体任务建立双向lstm模型,利用双向lstm(双向循环神经网络)编码每个长文本的语义信息:单向lstm可以按照人类的阅读顺序从一句话的第一个字记忆到最后一个字,这种lstm结构只能捕捉到上文信息,无法捕捉到下文信息,通过双向lstm获取每个长文本的上文信息和下文信息,即获取该文本数据的语义特征和时序特征;双向lstm包括两个方向不同的lstm,一个lstm按照句子中词的顺序从前往后读取数据,获得上文信息;另一个lstm从后往前按照句子词序的反方向读取数据,获得下文信息;上下文信息是由整个句子提供的,自然包含比较抽象的语义信息(句子的意思),这种方法的优点是充分利用了lstm对具有时序特点的序列数据的处理优势。
(4)训练模型,通过步骤(3)建立的双向lstm模型获取各个文本的特征向量,送入softmax分类器,对罪名进行分类。
实施例2
根据实施例1所述的一种基于距离向量的裁判文书推荐的方法,其区别在于,
cbow神经网络模型中,训练窗口大小为8(即考虑一个词的前八个和后八个),每个单词的向量维度可以自行指定,本模型使用的是200,迭代次数是15次。cbow神经网络模型中使用的参数大小可根据具体模型的需要自行指定。
罪名作为远程标签,并附上10个属性,包括profitpurpose(以营利为目的)、buyingandselling(买卖关系)、death(死亡)、violence(暴力行为)、stateorgan(国家机关)、publicplace(公共场所)、illegalpossession(非法占有)、physicalinjury(人身伤害)、intentionalcrime(故意犯罪)和production(涉及生产过程);远程标签及每个属性标签的取值为0、1或者2,0表示文本中不具备该标签特征,1表示文本中具备该标签特征,2表示文本中该特征不可用;将每个文本所对应的罪名及10个属性与上述全部数据集做连接,得到符合双向lstm模型输入的数据集;
步骤(3)中,双向lstm模型通过构造两个循环神经网络实现以两个不同的方向获取文本信息,同时这两层都连接相同的输入层。这个结构能够提供给上一层中每个单元结构完整的上下文信息,其中一层在同一时刻向前传递,更新所有隐藏层的信息;另一层信息的传播与上一层相反,通过先计算输出层然后得到不同方向的隐藏层值;由双层双向lstm模型训练得到的输出作为罪名分类的特征向量,在双向lstm之后,经过两层全连接层,激活函数为relu,将第二层全连接层的输出作为第三层全连接层的输入,该激活函数为softmax函数,对罪名进行分类。
在做罪名分类的过程中,如图3所示,将各项罪名以及其对应的属性预测值以文档的形式做输出保存,属性预测值是指属性标签的取值,并与本发明中采用的测试数据集做索引关联,通过计算各个罪名映射到空间中的高维向量之间的余弦相似度,并以第一个犯罪事实描述作为基准犯罪事实描述,通过将两两向量之间的余弦相似度从大到小进行排序,推荐出在相同罪名下,犯罪情节相同或者相似的前n个犯罪事实描述,n的取值范围为15-20。用来协助法官在查找、处理相似案件时的判定罪名及刑期等工作。
假设文本x和文本y对应的向量分别为x和y,则余弦相似度的计算公式如式(ⅰ)所示,如图4所示:
所述步骤(2),通过双向lstm获取文本的上文信息和下文信息,即获取该文本数据的语义特征和时序特征;包括步骤如下:
a、求取t时刻lstm单元中的输入门的值it,lstm单元指的是细胞状态,由于lstm拥有三个门,每个门由一个sigmoid神经网络层和一个元素级相乘操作组成,sigmoid层输出0-1之间的值,每个值表示对应的部分信息是否应该通过。0值表示不允许信息通过,1值表示允许所有信息通过。这种结构使得lstm有能力对细胞状态添加或者删除信息,来保护和控制细胞状态,如式(ⅱ)所示:
it=σ(wihht-1+wixxt+bi)(ⅱ)
式(ⅱ)中,σ表示sigmoid激活函数;wih是输入门中输入项ht-1对应的权重矩阵,wix是输入门中输入项xt对应的权重矩阵,ht-1是上一时刻隐藏层的输出,xt是当前时刻的输入,bi是输入门的偏置项;
b、求取t时刻lstm单元中的遗忘门的值ft,如式(ⅲ)所示:
ft=σ(wfhht-1+wfxxt+bf)(ⅲ)
式(ⅲ)中,wfh是遗忘门中输入项ht-1对应的权重矩阵,wfx是遗忘门中输入项xt对应的权重矩阵,bf是遗忘门的偏置项;
c、求取t时刻lstm单元中的输出门的值ot,如式(ⅳ)所示:
ot=σ(wohht-1+woxxt+bo)(ⅳ)
式(ⅳ)中,woh是输出门中输入项ht-1对应的权重矩阵,wox是输出门中输入项xt对应的权重矩阵,bo是输出门的偏置项;
d、求取t时刻lstm单元的输入状态gt,如式(ⅴ)所示:
gt=tanh(wghht-1+wgxxt+bg)(ⅴ)
式(ⅴ)中,wgh是单元状态中输入项ht-1对应的权重矩阵,wgx是单元状态中输入项xt对应的权重矩阵,bg是单元状态的偏置项,tanh表示双曲正切函数,用作激活函数;
e、求取t时刻的lstm单元的细胞状态ct,如式(ⅵ)所示:
ct=it⊙gt+ft⊙ct-1(ⅵ)
式(ⅵ)中,ct-1是上一时刻的细胞状态,⊙表示按元素乘;
f、求t时刻lstm单元的隐藏层状态ht,如式(ⅶ)所示:
ht=ot⊙tanh(ct)(ⅶ)
式(ⅶ)中,tanh表示双曲正切函数用作激活函数;ot代表当前时刻的输出,ct代表当前时刻的细胞状态。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免无关紧要的内容进入记忆。因此文本数据经过lstm单元之后,在各种门结构的控制作用下,输出的特征表示既包含有丰富的语义特征,又含有丰富的时序特征。
- 还没有人留言评论。精彩留言会获得点赞!