一种基于seq2seq+attention的中文文本纠错方法与流程
本发明属于中文文本纠错的技术领域,特别涉及到电力通信管理系统中产生的通信设备检修记录的纠错领域。
背景技术:
该领域涉及到的主要研究对象,关键技术和实际应用价值主要包括:
电力通信管理系统:是作为智能电网重要支撑的电力专用通信网络系统,是总部和省公司“两级部署”,总部、分部、省公司、市县公司“四级应用”的通信管理系统“sg—tms”。通过标准化规范化的项目建设以及对系统实用化的大力推进,“sg—tms”已经深度融入数万电力通信专业人员的日常工作中,并且全面采集了数万台设备几年来的建设、运行、管理数据,积累下来的海量电力通信数据和众多外部系统数据、公共数据一同形成了开展大数据分析的基础。
设备检修记录:智能电网通信的信息化管理系统中已经积累了大量检修数据、方式数据、运行记录数据,其中既有规范的结构化数据如检修类型、执行日期等,也有很多类似运行记录一类的半结构化数据,还有很多类似路由方式描述、“三措一案”文档、图片等非结构化数据。通过对这些过程和结论数据的深入分析与挖掘,可以总结出管理规律,对现有的制度和管理方式进行优化和合理安排。还可以通过大数据手段实现对运行方式、“三措一案”等流程化工作的机器自动初审、对工作记录的自动辅助纠错补缺等智能化功能,降低管理人员劳动强度,提升方式、检修审批效率和记录规范性。
基于字粒度:主要有两个原因:第一,由于设备检修记录中包含错别字或者存在缺失情况,导致分词结果不准确,所以纠错任务不适合在词粒度上进行;第二,在给定固定的词汇表的情况下,基于词语的纠错任务无法处理oov(outofvocabulary)的词语。
rnn:rnn是一种序列连接模型,通过网络节点中的循环来捕获动态序列。与标准前馈神经网络不同,rnn可以保留任意长度的上下文窗口的状态信息。虽然rnn很难训练,并且通常包含数百万个参数,但网络架构,优化技术和并行计算方面的最新进展使得它们能够成功地进行大规模学习。
双向rnn:在经典的循环神经网络中,状态是从前往后单向传输的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。这时就需要双向rnn来解决这类问题。例如,在本发明的文本纠错任务中,预测一个语句中缺失的词语不仅需要根据前文来判断,也需要结合后面的内容,这时双向rnn就可以发挥它的作用。
lstm:longshort-termmemory,是长短期记忆网络。rnn在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间的联系时会涉及雅可比矩阵的多次相乘,这会带来梯度消失或者梯度爆炸的问题。为了解决此问题,sepphochreiter等人[3]提出了lstm模型,通过增加输入门限,遗忘门限和输出门限,使得自循环的权重是变化的,这样一来在模型参数固定的情况下,不同时刻的积分尺度可以动态改变,从而避免了梯度消失或者梯度膨胀的问题。
seq2seq:seq2seq是一个encoder–decoder结构的网络,它的输入是一个序列,输出也是一个序列,encoder中将一个可变长度的信号序列变为固定长度的向量表达,decoder将这个固定长度的向量变成可变长度的目标的信号序列。
attention机制:采用编码器-解码器结构的神经网络模型需要将输入序列中的必要信息表示为一个固定长度的向量,而当输入序列很长时则难以保留全部的必要信息,尤其是当输入序列的长度比训练数据集中的更长时。dzmitrybahdanau等人使用attention机制每生成一个词时都会在输入序列中找出一个与之最相关的词集合,之后模型根据当前的上下文向量和所有之前生成出的词来预测下一个目标词
技术实现要素:
针对通信设备检修记录的错误发现和纠错,本发明提出了基于attention机制的seq2seq神经网络模型。实现检修记录纠错的步骤如下:
一种基于seq2seq+attention的中文文本纠错方法,其特征在于,包括以下步骤:
步骤1,文本预处理:首先基于python读取数据库中的检修记录,提取文档文件中的所有内容,然后利用正则表达式进行中文分句操作,将结果存入文本文件中,每一行对应一个句子,同时将人工标注的正确文本存入另一个文本文件中,和原始文件一一对应;记录下电力通信领域中的专有符号,和常见的汉字表共同组成字符表;
步骤2,构建基于attention的seq2seq神经网络模型,具体包括:
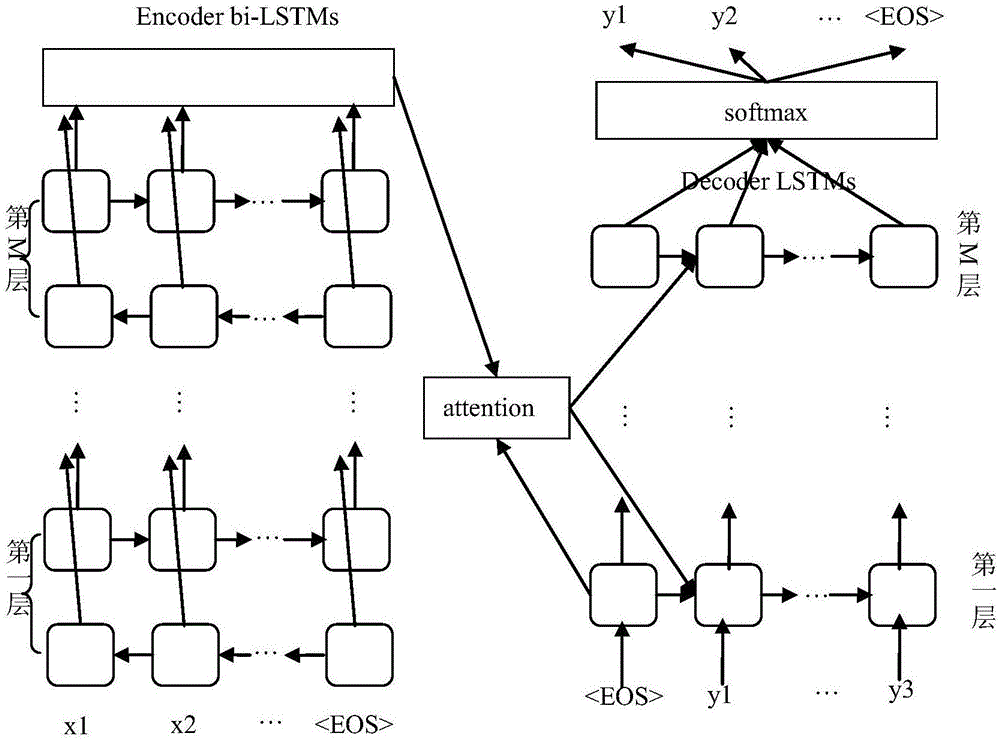
步骤2.1,构建encoder模块层,包括embeddinglayer和m层双向lstm,其中:
层一、embeddinglayer的输入为当前字符的one-hot编码,one-hot编码可以根据步骤1中形成的字符表得到;embeddinglayer的输出为当前字符的字向量即:
et=et·xt
其中xt是t时刻输入字符的one-hot编码,是v维列向量,v是步骤1得到的字符表中的字符总数;e是字符向量矩阵,是v×d维矩阵,在具体实现过程中,d取100-200之间的数字,d代表每一个字符向量的维度,矩阵e是模型的参数,通过训练得到;et是t时刻输入字符的字向量;
在具体实现过程中,使用tensorflow中tf.nn.embedding_lookup函数,得到字符向量;
层二、m层双向lstm中的基本单元是lstm,第j层t时刻lstm的隐藏状态计算公式如下:
其中,
基于lstm的计算公式得到:从前往后传播的隐藏状态向量
在具体实现过程中,可以使用tensorflow中的函数basiclstmcell来实现;
步骤2.2,构建decoder模块层,decoder模块层是一个m层单向lstm语言模型结构,每一层初始状态向量均来自encoder;
计算损失函数:
其中,yt是one-hot编码,代表t时刻输出的字符,p是输出序列长度;
步骤2.3,构建attention模块层:在encoder模块层中得到最后一层所有时刻的隐藏状态向量
α=softmax(w)
在计算decoder模块层中t时刻每一层的隐藏状态向量时,加入β;
步骤3,采用adam优化方法进行模型训练:神经网络模型构建成功之后,数据从输入到输出的整个流程,以tensorflow中计算图的形式存在,直接利用tf.train.adamoptimizer().minimize()进行迭代训练,找到参数最优值;
步骤4,进行纠错任务,具体是:
在decoder阶段,采用beamsearch进行推断过程,beamsize为2,每次挑选两个概率最高的字符,作为下一次预测的输入,遇见终止符<eos>时,停止推断,得到输出序列。
因此,本发明具有如下优点:
(1)与现有的基于规则的纠错方案,端到端的深度模型可以避免人工提取特征,减少人工工作量。而且,rnn序列模型对文本任务拟合能力强。
(2)在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,效果更好。
附图说明
图1是神经网络总体框架。
具体实施方式
具体实施时,本发明所提供技术方案可由本领域技术人员采用计算机软件技术实现自动运行流程。以下结合附图和实施例详细说明本发明技术方案。
步骤1:文本预处理
利用python中的相关工具读取数据库中的检修记录,提取文档文件中的所有内容,然后利用正则表达式进行中文分句操作,将结果存入文本文件中,每一行对应一个句子,同时将人工标注的正确文本存入另一个文本文件中,和原始文件一一对应。记录下电力通信领域中的专有符号,和常见的汉字表共同组成本发明所用到的字符表。
步骤2:构建基于attention的seq2seq神经网络模型
(1)encoder模块
encoder模块主要包括两部分:embeddinglayer和m层双向lstm。
embeddinglayer的输入为当前字符的one-hot编码,one-hot编码可以根据步骤1中形成的字符表得到。embeddinglayer的输出为当前字符的字向量即:
et=et·xt
其中xt是t时刻输入字符的one-hot编码,是v维列向量,v是步骤1得到的字符表中的字符总数。e是字符向量矩阵,是v×d维矩阵,在具体实现过程中,d取100-200之间的数字,d代表每一个字符向量的维度,矩阵e是模型的参数,通过训练得到。et是t时刻输入字符的字向量。
在具体实现过程中,使用tensorflow中tf.nn.embedding_lookup函数,得到字符向量。
m层双向lstm中的基本单元是lstm,第j层t时刻lstm的隐藏状态计算公式如下:
其中,
基于上述lstm的计算公式得到:从前往后传播的隐藏状态向量
在具体实现过程中,可以使用tensorflow中的函数basiclstmcell来实现。
(2)decoder模块
decoder模块是一个m层单向lstm语言模型结构,每一层初始状态向量均来自encoder。
计算损失函数:
其中,yt是one-hot编码,代表t时刻输出的字符,p是输出序列长度。
(3)attention模块
在encoder模块中得到最后一层所有时刻的隐藏状态向量
α=softmax(w)
在计算decoder模块中t时刻每一层的隐藏状态向量时,加入β。
步骤3:采用adam优化方法进行模型训练
神经网络模型构建成功之后,数据从输入到输出的整个流程,以tensorflow中计算图的形式存在,直接利用tf.train.adamoptimizer().minimize()进行迭代训练,找到参数最优值。
步骤4:进行纠错任务
在decoder阶段,采用beamsearch进行推断过程,beamsize为2,每次挑选两个概率最高的字符,作为下一次预测的输入,遇见终止符<eos>时,停止推断,得到输出序列。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可对所描述的具体实施例做修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!