金融欺诈检测中时间与成本特征选择方法、设备、介质与流程
本发明涉及金融技术领域,尤其涉及金融欺诈检测中时间与成本特征选择方法、设备、介质。
背景技术:
在大数据时代,我们可以从数据中提取到用户的各类相关特征,如在电商数据中提取用户相关的购物特征,在医疗数据中提取用户相关的体检项目特征等,利用提取得到的特征可以预测用户的商品购买意向或者推断用户的健康状况。在实际应用中,用户的数据特征获取往往有各种不同的代价,比如在获取用户的一系列购物特征或者体检特征时需要一定的成本,如病人在医学诊断中进行的各类测试所需要的成本是不同的。同时,在实际应用中,不少数据特征本身带有时间属性信息,如我们可以使用以下两种特征刻画用户的消费情况:用户前十天的消费金额和用户前三个月的消费金额。相比而言,用户前十天的消费金额这个特征更能刻画用户的最近消费情况,如果不考虑特征获取成本和时间价值,很多理论上效果好的预测模型在应用中会缺乏实用性。同时,在大数据时代,高维数据往往对数据挖掘模型与算法都会带来巨大挑战,引发“维度诅咒”问题。为了减轻“维度诅咒”的影响,提升模型效果,实际的数据挖掘任务往往需要通过特征选择来减少数据特征的维度。传统的特征选择方法通过考虑特征之间的冗余相关性(如特征共线性等),从n个特征中选出k个特征,减少特征维度。但是现有的特征选择方法并没有显式的考虑特征自身的成本和时间价值,因此其实用性受限。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供金融欺诈检测中时间与成本特征选择方法,解决了现有的特征选择方法没有显式的考虑特征自身的成本和时间价值,实用性受限的问题。
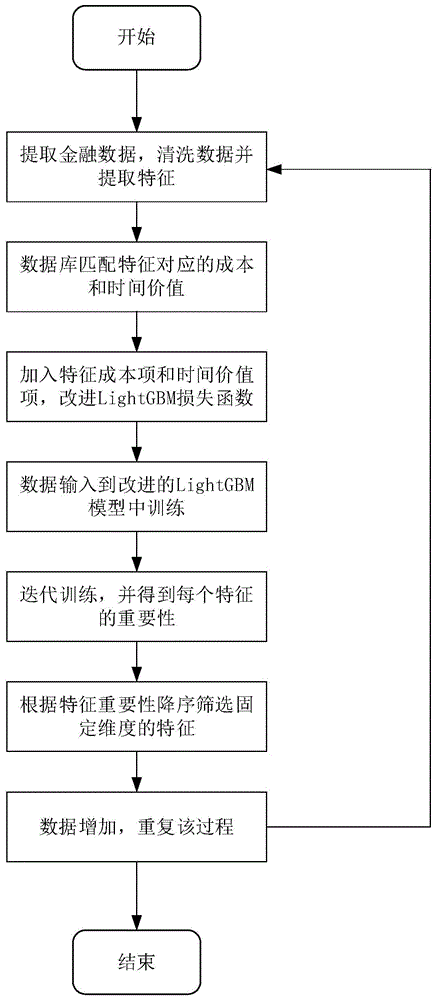
本发明提供金融欺诈检测中时间与成本特征选择方法,包括以下步骤:
提取金融数据特征,从用户数据表中提取出用户的金融数据特征,对所述金融数据特征进行统计,得到统计特征,并对所述统计特征进行筛选,得到n维特征,通过用户主键匹配得到用户标签;
匹配时间与成本价值,匹配数据库中所述n维特征对应的成本价值和时间价值;
构建机器学习模型,将每个特征对应的成本价值和时间价值计入损失函数的一部分,以最小化所述损失函数为目标进行模型训练,将用户特征和用户标签作为模型的输入进行模型训练,得到机器学习模型;
计算特征重要性,通过所述机器学习模型计算每个特征的重要性,对每个特征对应的重要性进行排列,并进行固定维度的特征选择。
进一步地,所述提取金融数据特征步骤具体包括以下步骤:
提取n维特征,从数据库中的用户数据表中提取与用户相关的金融数据特征,通过统计所述金融数据特征的最大值、最小值、中位数、求和、均值、方差,得到统计特征,对所述统计特征进行清洗筛选,得到n维特征;
匹配用户标签,通过业务逻辑对用户进行标签标定,得到用户标签。
进一步地,所述匹配时间与成本价值步骤中,根据所述n维特征匹配数据库中的特征指标价格表和特征指标的时间价值表,获得特征对应的成本价值和时间价值。
进一步地,所述机器学习模型为lightgbm模型。
进一步地,所述构建机器学习模型步骤具体包括以下步骤:
建立原损失函数,建立lightgbm模型的原损失函数,具体公式如下:
其中,
所述定义的误差函数的具体公式如下:
所述衡量树结构好坏的函数的具体公式如下:
其中,t代表第k棵树的叶子个数,λ为参数,ω代表叶子的值;
建立新损失函数,建立lightgbm模型的新损失函数,具体公式如下:
其中,ok代表第k次迭代需要优化的损失函数,i∈[1,n]代表从第1个样本到第n个样本,λ为参数,k代表第k次迭代,xi代表第i个样本的特征,每个样本有n维特征,ψ(k,xi)是关于特征和树结构的代价函数,ψc(k)是第k棵树中特征成本计算的函数;
ψ(k,xi)的具体公式如下:
其中,
ψc(k)的具体公式如下:
其中,βm代表第m个特征的成本,μm代表第m个特征的时间价值,当特征m在第k棵树被使用时,d(k,m)=1,当特征m在第k棵树未被使用时,d(k,m)=0;
使用tk-1(xi)附近的二阶泰勒公式近似ok,具体公式如下:
其中,
其中,
训练lightgbm模型,将[xi,yi],i∈[1,n]作为lightgbm模型的输入,迭代训练后lightgbm模型的输出对应样本的预测值predicti,其中,i代表第i个样本,xi代表第i个样本的n维特征向量,yi代表第i个样本的真实标签值,n代表样本总数,predicti代表第i个样本的预测值。
进一步地,所述计算特征重要性步骤中,根据基尼系数计算lightgbm模型的特征重要性,将计算得到的特征重要性进行降序排序,筛选得到维度为m的特征,具体公式如下:
其中,m代表样本中的第m个特征,k代表决策树模型的树的总棵树,ψ(k,m)代表在第k棵树中使用特征m进行划分后的减少的基尼系数值的和。
进一步地,所述提取n维特征步骤中,选择缺失值少于缺失值阈值的特征,得到n维特征,所述缺失值阈值为40%~60%。
一种电子设备,包括:处理器;
存储器;以及程序,其中所述程序被存储在所述存储器中,并且被配置成由处理器执行,所述程序包括用于执行上述金融欺诈检测中时间与成本特征选择方法。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行上述金融欺诈检测中时间与成本特征选择方法。
相比现有技术,本发明的有益效果在于:
本发明提供金融欺诈检测中时间与成本特征选择方法,包括以下步骤:提取金融数据特征,从用户数据表中提取出用户的金融数据特征,对金融数据特征进行统计,得到统计特征,并对统计特征进行筛选,得到n维特征,通过用户主键匹配得到用户标签;匹配时间与成本价值,匹配数据库中n维特征对应的成本价值和时间价值;构建机器学习模型,将每个特征对应的成本价值和时间价值计入损失函数的一部分,以最小化损失函数为目标进行模型训练,将用户特征和用户标签作为模型的输入进行模型训练,得到机器学习模型;计算特征重要性,通过机器学习模型计算每个特征的重要性,对每个特征对应的重要性进行排列,并进行固定维度的特征选择。本发明涉及电子设备与可读存储介质,用于执行金融欺诈检测中时间与成本特征选择方法。本发明基于互联网金融公司的第三方金融欺诈数据,在特征选择过程中除了考虑特征间的冗余相关性外,还考虑了特征自身的成本价值和时间价值,提出了时间与成本敏感的特征选择方法,即在限定特征成本和给定特征时间价值的前提下选择部分特征来进行有效建模。在限定特征成本和给定特征时间价值的前提下选择部分特征进行有效建模,实用性广。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。本发明的具体实施方式由以下实施例及其附图详细给出。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明的金融欺诈检测中时间与成本特征选择方法流程图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
金融欺诈检测中时间与成本特征选择方法,如图1所示,包括以下步骤:
提取金融数据特征,从用户数据表中提取出用户的金融数据特征,对金融数据特征进行统计,得到统计特征,并对统计特征进行筛选,得到n维特征,具体为[特征1,特征2,…,特征n],通过用户主键匹配得到用户标签;优选的,提取金融数据特征步骤具体包括以下步骤:
提取n维特征,从数据库中的用户数据表中提取与用户相关的金融数据特征,通过统计金融数据特征的最大值、最小值、中位数、求和、均值、方差等,得到统计特征,对统计特征进行清洗筛选,得到n维特征,即[特征1,特征2,..,特征n];优选的,提取n维特征步骤中,选择缺失值少于缺失值阈值的特征,得到n维特征,缺失值阈值为40%~60%。本实施例中,缺失值阈值最优为50%。
匹配用户标签,通过业务逻辑对用户进行标签标定,得到用户标签。本实施例中,用户标签的定义是用户的好坏,通过业务逻辑来对用户进行标签标定区分好坏用户,0代表好用户,1代表坏用户,此处提取得到的用户特征和用户标签用于后续的模型训练。
匹配时间与成本价值,匹配数据库中n维特征对应的成本价值和时间价值,用于后续的模型训练;每个特征都有一定的成本和时间价值,本发明中的特征成本为每个特征的价格,时间价值为每类特征在时间维度上的重要性,优选的,匹配时间与成本价值步骤中,根据n维特征匹配数据库中的特征指标价格表和特征指标的时间价值表,获得特征对应的成本价值和时间价值,统计特征的成本为用到的所有特征的价格综合,时间价值同理。
构建机器学习模型,将每个特征对应的成本价值和时间价值计入损失函数的一部分,以最小化损失函数为目标进行模型训练,将用户特征和用户标签作为模型的输入进行模型训练,得到机器学习模型;优选的,机器学习模型为lightgbm模型。引入lightgbm决策树模型,通过重新定义lightgbm决策树模型的损失函数,即把每个特征的成本价值和时间价值作为新损失函数的一部分,并以最小化这个损失函数为目标进行模型迭代,以[用户特征,用户标签]作为模型的输入进行模型训练。具体地,优选的,构建机器学习模型步骤具体包括以下步骤:
建立原损失函数,建立lightgbm模型的原损失函数,具体公式如下:
其中,
定义的误差函数,即l的具体公式如下:
衡量树结构好坏的函数,即ω的具体公式如下:
其中,t代表第k棵树的叶子个数,λ为参数,ω代表叶子的值;
建立新损失函数,建立lightgbm模型的新损失函数,具体公式如下:
其中,ok代表第k次迭代需要优化的损失函数,i∈[1,n]代表从第1个样本到第n个样本,λ为参数,k代表第k次迭代,xi代表第i个样本的特征,每个样本有n维特征,ψ(k,xi)是关于特征和树结构的代价函数,ψc(k)是第k棵树中特征成本计算的函数;
ψ(k,xi)的具体公式如下:
其中,
ψc(k)的具体公式如下:
其中,βm代表第m个特征的成本,μm代表第m个特征的时间价值,当特征m在第k棵树被使用时,d(k,m)=1,当特征m在第k棵树未被使用时,d(k,m)=0;
由于
其中,
其中,
训练lightgbm模型,将[xi,yi],i∈[1,n]作为lightgbm模型的输入,迭代训练后lightgbm模型的输出对应样本的预测值predicti,其中,i代表第i个样本,xi代表第i个样本的n维特征向量,yi代表第i个样本的真实标签值,n代表样本总数,predicti代表第i个样本的预测值。
计算特征重要性,通过构建机器学习模型步骤训练得到的机器学习模型计算每个特征的重要性,对每个特征对应的重要性进行排列,并进行固定维度的特征选择。优选的,计算特征重要性步骤中,根据基尼系数计算lightgbm模型的特征重要性,具体公式如下:
其中,m代表样本中的第m个特征,k代表决策树模型的树的总棵树,ψ(k,m)代表在第k棵树中使用特征m进行划分后的减少的基尼系数值的和。
将计算得到的特征重要性进行降序排序,筛选得到维度为m的特征(m<n),n为原特征的维度。
一种电子设备,包括:处理器;
存储器;以及程序,其中程序被存储在存储器中,并且被配置成由处理器执行,程序包括用于执行上述金融欺诈检测中时间与成本特征选择方法。
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行上述金融欺诈检测中时间与成本特征选择方法。
本发明提供金融欺诈检测中时间与成本特征选择方法,包括以下步骤:提取金融数据特征,从用户数据表中提取出用户的金融数据特征,对金融数据特征进行统计,得到统计特征,并对统计特征进行筛选,得到n维特征,通过用户主键匹配得到用户标签;匹配时间与成本价值,匹配数据库中n维特征对应的成本价值和时间价值;构建机器学习模型,将每个特征对应的成本价值和时间价值计入损失函数的一部分,以最小化损失函数为目标进行模型训练,将用户特征和用户标签作为模型的输入进行模型训练,得到机器学习模型;计算特征重要性,通过机器学习模型计算每个特征的重要性,对每个特征对应的重要性进行排列,并进行固定维度的特征选择。本发明涉及电子设备与可读存储介质,用于执行金融欺诈检测中时间与成本特征选择方法。本发明基于互联网金融公司的第三方金融欺诈数据,在特征选择过程中除了考虑特征间的冗余相关性外,还考虑了特征自身的成本价值和时间价值,提出了时间与成本敏感的特征选择方法,即在限定特征成本和给定特征时间价值的前提下选择部分特征来进行有效建模。在限定特征成本和给定特征时间价值的前提下选择部分特征进行有效建模,实用性广。
以上,仅为本发明的较佳实施例而已,并非对本发明作任何形式上的限制;凡本行业的普通技术人员均可按说明书附图所示和以上而顺畅地实施本发明;但是,凡熟悉本专业的技术人员在不脱离本发明技术方案范围内,利用以上所揭示的技术内容而做出的些许更动、修饰与演变的等同变化,均为本发明的等效实施例;同时,凡依据本发明的实质技术对以上实施例所作的任何等同变化的更动、修饰与演变等,均仍属于本发明的技术方案的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!