弹幕文本相似度计算方法、存储介质、设备及系统与流程
本发明涉及大数据处理领域,具体涉及一种弹幕文本相似度计算方法、存储介质、设备及系统。
背景技术:
随着移动互联网的飞速发展,直播行业也呈现出蓬勃发展之势,越来越多的年轻人喜欢通过观看直播的方式来打发业余时间。
用户在观看直播的过程中,会通过发送弹幕文本的方式与主播或其它用户进行互动,但是在某些热门主播的直播间,由于该直播间用户数量较多,导致该直播间的弹幕量非常巨大,若对于用户发送的每一条弹幕均进行展示,便会导致弹幕铺满整个直播画面,为保证用户的观看体验,直播平台会对弹幕文本间的相似度进行计算,若2条弹幕相识度较高,则仅展示2条弹幕中的1条弹幕,现有技术中对于弹幕相似度的计算有余弦相似度、欧式距离算法等,但这些算法通常只考虑了2条弹幕在空间中的距离,导致弹幕间相似度的计算不够准确。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的在于提供一种弹幕文本相似度计算方法、存储介质、设备及系统,能够有效保证计算得到弹幕文本间相似度的准确性。
本发明第一方面提供一种弹幕文本相似度计算方法,包括以下步骤:
对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
计算相同词项在弹幕a和弹幕b文本中的所占比例;
计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
结合第一方面,在第一种可能的实现方式中,所述计算相同词项在弹幕a和弹幕b文本中的所占比例,计算公式为:
其中,p(a,b)表示相同词项在弹幕a和弹幕b文本中的所占比例,wordi表示相同词项,ni表示相同词项的最小词频,m表示相同词项的个数,la表示弹幕a的文本长度,lb表示弹幕b的文本长度。
结合第一方面的第一种可能的实现方式,在第二种可能的实现方式中,所述计算基于相同词项词频的弹幕a和弹幕b的文本相似度,计算公式为:
其中,simtf(a,b)表示基于相同词项词频的弹幕a和弹幕b的文本相似度。
结合第一方面的第二种可能的实现方式,在第三种可能的实现方式中,所述基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度,计算公式为:
其中,simword2vec(a,b)表示弹幕a和弹幕b在文本空间的相似度,
结合第一方面的第三种可能的实现方式,在第四种可能的实现方式中,所述对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度,计算公式为:
sim(a,b)=λ*simtf(a,b)+(1-λ)simword2vec(a,b)
其中,sim(a,b)表示弹幕a和弹幕b最终相似度,λ为调整系数,取值范围为[0.6,0.8]。
结合第一方面的第三种可能的实现方式,在第五种可能的实现方式中,当弹幕a和弹幕b的最终相似度大于设定阈值时,选取弹幕a或弹幕b中的任一条弹幕在直播画面上展示,另一条未被选取的弹幕在直播画面上不作展示。
本发明第二方面提供一种存储介质,该存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
计算相同词项在弹幕a和弹幕b文本中的所占比例;
计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
本发明第三方面提供一种电子设备,所述电子设备包括:
分词单元,其用于选取待展示弹幕弹幕a和弹幕b,对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
比例计算单元,其用于计算相同词项在弹幕a和弹幕b文本中的所占比例;
第一文本相似度计算单元,其用于计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
第二文本相似度计算单元,其用于将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
最终相似度计算单元,其用于对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
本发明第四方面提供一种弹幕文本相似度计算系统,包括:
分词模块,其用于选取待展示弹幕弹幕a和弹幕b,对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
比例计算模块,其用于计算相同词项在弹幕a和弹幕b文本中的所占比例;
第一文本相似度计算模块,其用于计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
第二文本相似度计算模块,其用于将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
最终相似度计算模块,其用于对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
结合第四方面,在第一种可能的实现方式中,所述比例计算模块计算相同词项在弹幕a和弹幕b文本中的所占比例,计算公式为:
其中,p(a,b)表示相同词项在弹幕a和弹幕b文本中的所占比例,wordi表示相同词项,ni表示相同词项的最小词频,m表示相同词项的个数,la表示弹幕a的文本长度,lb表示弹幕b的文本长度。
与现有技术相比,本发明的优点在于:在进行弹幕文本间相似度计算时,首先对弹幕文本进行分词,然后基于分词得到弹幕间的相同词项,以及相同词项的最小词频,根据相同词项和最小词频,计算基于相同词项词频的弹幕间的文本相似度,以及在文本空间的文本相似度,最后对基于相同词项词频的文本相似度和在文本空间的文本相似度分别赋予权重进行计算,计算后得到的值作为弹幕文本间的最终相似度,在计算文本相识度时,进行进行相同词项的考虑,有效保证计算得到弹幕文本间相似度的准确性。
附图说明
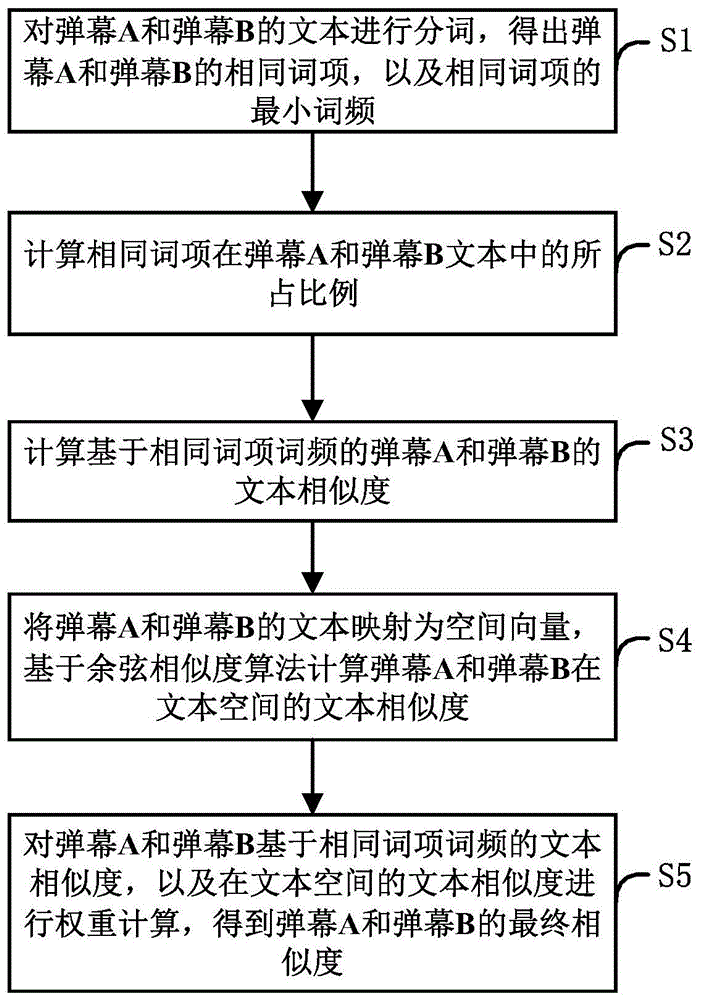
图1为本发明实施例中一种弹幕文本相似度计算方法的流程图;
图2为本发明实施例中一种电子设备的结构示意图。
具体实施方式
本发明实施例提供了一种弹幕文本相似度计算方法,基于弹幕文本的短语词频进行相似度计算,有效保证弹幕间相似度计算的准确性。本发明实施例还相应地提供了存储介质、电子设备和弹幕文本相似度计算系统。
以下结合附本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1所示,本发明实施例提供的一种弹幕文本相似度计算方法的一实施例包括:
s1:对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频。
本发明实施例中对于弹幕文本的分词可以使用现有技术中的常用分词软件,如jieba等。
本发明实施例中,对于弹幕a和弹幕b的相同词项,以及相同词项的最小词频的得出,举例说明如下,假设弹幕a的文本为“主播操作厉害”,弹幕b的文本为“这个主播很厉害”,将弹幕a分词后,为“主播”、“操作”和“厉害”,弹幕b分词后,为“这个”、“主播”、“很”和“厉害”,则弹幕a和弹幕b的相同词项为“主播”、“厉害”。“主播”在弹幕a中出现1次,在弹幕b中出现1次,故相同词项“主播”的最小词频为1;“厉害”在弹幕a中出现1次,在弹幕b中出现1次,故“厉害”的最小词频为1。词频指某个相同词项在某条弹幕中出现的次数,相同词项在不同弹幕中的词频,取最小值作为该相同词项的最小词频,例如相同词项a在弹幕a中的词频为2,相同词项a在弹幕a中的词频为1,则相同词项a的住校词频为1。
s2:计算相同词项在弹幕a和弹幕b文本中的所占比例。即计算相同词项在弹幕a和弹幕b合起来的整个文本中所占的比例,即将弹幕a和弹幕b和为一个整体,然后计算相同词项在这个整体中所占的比例,通过对相同词项所占比例的计算,可以在一种程度上反映文本间的相关度,相同词项越多,相同词项在整体中所占比例越高,则弹幕文本间的语义越相关。
s3:计算基于相同词项词频的弹幕a和弹幕b的文本相似度。基于相同词项词频的文本相似度,能够表现出相同词项在弹幕a和弹幕b中的代表性,相同词项的词频越高,代表性则越差,就越难判断2个弹幕文本间的相似度。
s4:将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度。
本发明实施例中,word2vec是一群用来产生词向量的相关模型,这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本,网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的,训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,向量为神经网络之隐藏层。
s5:对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
本发明实施例中,对弹幕a和弹幕b会计算得到两个文本相似度,分别为基于相同词项词频的文本相似度和在文本空间的文本相似度,对基于相同词项词频的文本相似度和在文本空间的文本相似度分别赋予权重进行计算,计算后得到的值作为弹幕a和弹幕b的最终相似度。
本发明实施例中。当弹幕a和弹幕b的最终相似度大于设定阈值时,选取弹幕a或弹幕b中的任一条弹幕在直播画面上展示,另一条未被选取的弹幕在直播画面上不作展示。
本发明实施例弹幕文本相似度计算方法,在进行弹幕文本间相似度计算时,首先对弹幕文本进行分词,然后基于分词得到弹幕间的相同词项,以及相同词项的最小词频,根据相同词项和最小词频,计算基于相同词项词频的弹幕间的文本相似度,以及在文本空间的文本相似度,最后对基于相同词项词频的文本相似度和在文本空间的文本相似度分别赋予权重进行计算,计算后得到的值作为弹幕文本间的最终相似度,在计算文本相识度时,进行进行相同词项的考虑,有效保证计算得到弹幕文本间相似度的准确性。
可选地,在上述图1对应的实施例的基础上,本发明实施例提供的一种弹幕文本相似度计算方法的第一个可选实施例中,计算相同词项在弹幕a和弹幕b文本中的所占比例,计算公式为:
其中,p(a,b)表示相同词项在弹幕a和弹幕b文本中的所占比例,wordi表示相同词项,ni表示相同词项的最小词频,m表示相同词项的个数,la表示弹幕a的文本长度,lb表示弹幕b的文本长度。
计算基于相同词项词频的弹幕a和弹幕b的文本相似度,计算公式为:
其中,simtf(a,b)表示基于相同词项词频的弹幕a和弹幕b的文本相似度。
可选地,在上述图1对应的第一个可选实施例的基础上,本发明实施例提供的一种弹幕文本相似度计算方法的第二个可选实施例中,基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度,计算公式为:
其中,simword2vec(a,b)表示弹幕a和弹幕b在文本空间的相似度,
对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度,计算公式为:
sim(a,b)=λ*simtf(a,b)+(1-λ)simword2vec(a,b)
其中,sim(a,b)表示弹幕a和弹幕b最终相似度,λ为调整系数,取值范围为[0.6,0.8],优选的取值为0.7,因为基于相同词项词频的文本相似度较为重要更能反映弹幕文本间的相似度,故基于相同词项词频的文本相似度权重较大。
以下结合一实例对本发明实施例中弹幕a和弹幕b的最终相似度的整个计算过程进行说明。
假设弹幕a的文本为“主播操作厉害”,弹幕b的文本为“这个主播很厉害”,则弹幕a和弹幕b的相同词项为“主播”和“厉害”,“主播”的最小词频为1,“厉害”的最小词频为1。
计算相同词项在弹幕a和弹幕b文本中的所占比例:
p(a,b)=(1+1)/4+5=0.22;
计算基于相同词项词频的弹幕a和弹幕b的文本相似度:
simtf(a,b)=log(1+(2-0.22)/2+1)=0.201;
基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度:
simword2vec(a,b)=0.68
计算得到弹幕a和弹幕b的最终相似度:
sim(a,b)=λ*simtf(a,b)+(1-λ)simword2vec(a,b)=0.6*0.201+0.4*0.68=0.392
故计算得到弹幕a和弹幕b的最终相似度为0.392。
假设还有一条弹幕c,弹幕c的文本为“中国骄傲”,此时计算弹幕a和弹幕c之间的相似度,弹幕a和弹幕c之间的相同词项没有,最小词频也是0。
计算相同词项在弹幕a和弹幕c文本中的所占比例:
p(a,c)=0/5+3=0;
计算基于相同词项词频的弹幕a和弹幕c的文本相似度:
simtf(a,c)=log(1+0)=0;
基于余弦相似度算法计算弹幕a和弹幕c在文本空间的文本相似度:
simword2vec(a,c)=0.35
计算得到弹幕a和弹幕c的最终相似度:
sim(a,c)=λ*simtf(a,c)+(1-λ)simword2vec(a,c)=0.6*0+0.4*0.35=0.14
故计算得到弹幕a和弹幕c的最终相似度为0.14,明显的弹幕a和弹幕b之间的相似度远大于弹幕a和弹幕c之间的相识度,符合事实,说明本发明实施例的弹幕文本相似度计算方法计算结果精确度高。
本发明实施例提供的一种存储介质的一实施例包括:该存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
计算相同词项在弹幕a和弹幕b文本中的所占比例;
计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
可选地,在上述存储介质实施例的基础上,本发明实施例提供的一种存储介质的第一个可选实施例中,存储介质可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是但不限于:电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
可选地,在上述存储介质的实施例及第一个可选实施例的基础上,本发明实施例提供的一种存储介质的第二个可选实施例中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
可选地,在上述存储介质的实施例及第一、第二个可选实施例的基础上,本发明实施例提供的一种存储介质的第三个可选实施例中,可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如java、smalltalk、c++,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
参见图2所示,本发明实施例提供的一种电子设备的一实施例包括:
分词单元,其用于选取待展示弹幕弹幕a和弹幕b,对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
比例计算单元,其用于计算相同词项在弹幕a和弹幕b文本中的所占比例;
第一文本相似度计算单元,其用于计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
第二文本相似度计算单元,其用于将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
最终相似度计算单元,其用于对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
本发明实施例提供的一种弹幕文本相似度计算系统的一实施例包括:
分词模块,其用于选取待展示弹幕弹幕a和弹幕b,对弹幕a和弹幕b的文本进行分词,得出弹幕a和弹幕b的相同词项,以及相同词项的最小词频;
比例计算模块,其用于计算相同词项在弹幕a和弹幕b文本中的所占比例;
第一文本相似度计算模块,其用于计算基于相同词项词频的弹幕a和弹幕b的文本相似度;
第二文本相似度计算模块,其用于将弹幕a和弹幕b的文本通过word2vec模型映射为空间向量,然后基于余弦相似度算法计算弹幕a和弹幕b在文本空间的文本相似度;
最终相似度计算模块,其用于对弹幕a和弹幕b基于相同词项词频的文本相似度,以及在文本空间的文本相似度进行权重计算,得到弹幕a和弹幕b的最终相似度。
可选地,在上述弹幕文本相似度计算系统对应的实施例的基础上,本发明实施例提供的一种弹幕文本相似度计算系统的第一个可选实施例中,比例计算模块计算相同词项在弹幕a和弹幕b文本中的所占比例,计算公式为:
其中,p(a,b)表示相同词项在弹幕a和弹幕b文本中的所占比例,wordi表示相同词项,ni表示相同词项的最小词频,m表示相同词项的个数,la表示弹幕a的文本长度,lb表示弹幕b的文本长度。
本发明实施例的弹幕文本相似度计算系统,在进行弹幕文本间相似度计算时,首先对弹幕文本进行分词,然后基于分词得到弹幕间的相同词项,以及相同词项的最小词频,根据相同词项和最小词频,计算基于相同词项词频的弹幕间的文本相似度,以及在文本空间的文本相似度,最后对基于相同词项词频的文本相似度和在文本空间的文本相似度分别赋予权重进行计算,计算后得到的值作为弹幕文本间的最终相似度,在计算文本相识度时,进行进行相同词项的考虑,有效保证计算得到弹幕文本间相似度的准确性。
本发明不局限于上述实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围之内。本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!