使用递归神经网络进行动态面部分析的系统和方法与流程
本发明涉及面部分析,并且更具体地涉及使用神经网络的面部分析。
背景技术:
视频图像数据的面部分析用于面部动画捕捉、人类活动识别和人机交互。面部分析通常包括头部姿势估计和面部地标(facial landmark)定位。视频中的面部分析是许多应用程序的关键,诸如面部动画捕捉、驾驶员辅助系统和人机交互。用于视频中的面部分析的常规技术估计各个帧的面部属性,然后使用时间贝叶斯过滤来细化估计。视觉估计和时间轨迹这两个相互关联的任务被分离开,并且需要针对贝叶斯过滤进行仔细的手工模型设计和参数调整。需要解决与现有技术相关的这些问题和/或其他问题。
技术实现要素:
公开了一种用于视频中的动态面部分析的方法、计算机可读介质和系统。所述方法包括以下步骤:接收表示包括至少一个头部的图像帧序列的视频数据,以及由神经网络从所述视频数据中提取包括所述至少一个头部的俯仰角、偏转角和转动角的空间特征。所述方法还包括步骤:由递归神经网络处理所述图像帧序列中的两个或更多图像帧的所述空间特征,以为所述至少一个头部产生头部姿势估计。
附图简要说明
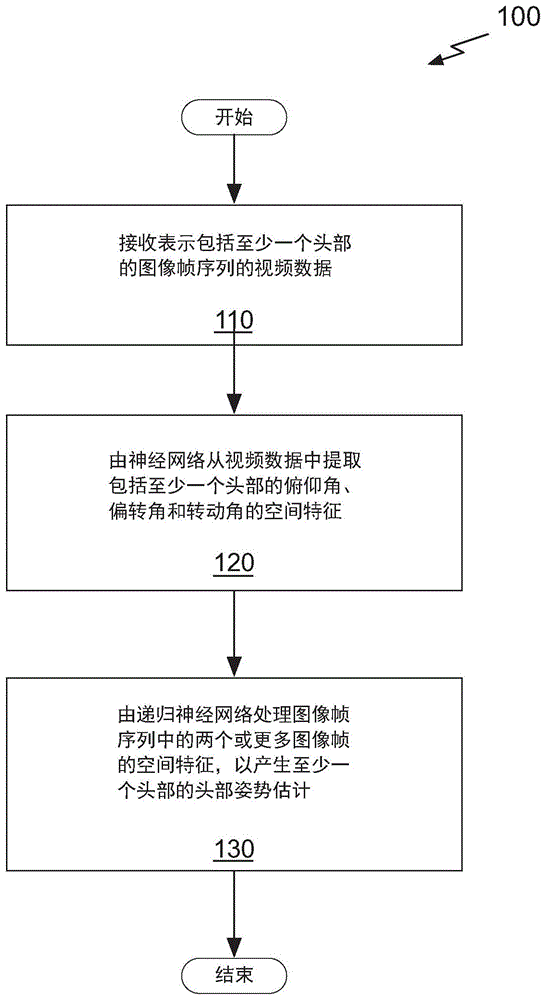
图1A示出了根据一个实施例的用于执行视频中的动态面部分析的方法的流程图;
图1B示出了根据一个实施例的用于视频数据的动态面部分析的系统的框图;
图1C示出了根据一个实施例的用于图1B中所示的视频数据的动态面部分析的系统的另一框图;
图2A示出了根据一个实施例的用于生成每帧头部姿势估计的神经网络的框图;
图2B示出了根据一个实施例的用于生成每帧头部姿势估计的RNN的框图;
图2C示出了根据一个实施例的用于生成每帧面部地标的神经网络的框图;
图2D示出了根据一个实施例的用于生成每帧面部地标的RNN的框图;
图2E示出了根据一个实施例的用于训练和部署图1B和图1C中所示的动态面部分析系统的方法的另一流程图;
图2F示出了根据一个实施例的用于视频数据的动态面部分析的系统的又一框图;
图3示出了根据一个实施例的并行处理单元;
图4A示出了根据一个实施例的图3的并行处理单元的通用处理集群;
图4B示出了根据一个实施例的图3的并行处理单元的分区单元;
图5示出了根据一个实施例的图4A的流式多处理器;
图6示出了可以实现各种先前实施例的各种架构和/或功能的示例性系统。
详细描述
本公开描述了一种面部分析系统,其包括用于动态估计和跟踪视频图像数据中的面部特征的神经网络和递归神经网络(recurrent neural network,RNN)。面部分析系统接收没有深度的颜色数据(例如,RGB分量值)作为输入,并且使用大规模合成数据集来训练,以估计和跟踪头部姿势或面部地标的三维(3D)位置。换句话说,可以训练相同的面部分析系统用于估计和跟踪头部姿势或3D面部地标。在以下描述的上下文中,头部姿势估计由俯仰角(pitch angle)、偏转角(yaw angle)和转动角(roll angle)限定。在一个实施例中,神经网络是卷积神经网络(convolutional neural network,CNN)。在一个实施例中,RNN用于估计和跟踪视频中的面部特征两者。与用于视频的面部分析的传统技术相比,跟踪所需的参数是从训练数据自动学习的。另外,面部分析系统为来自连续视频帧的各种类型的面部特征的视觉估计和时间跟踪两者提供整体解决方案。
图1示出了根据一个实施例的用于动态面部分析的方法100的流程图。方法100可以由程序、定制电路或定制电路和程序的组合来执行。例如,方法100可以由GPU(graphics processing unit,图形处理单元)、CPU(central processing unit,中央处理单元)、神经网络或能够执行面部分析框架的任何处理器执行。此外,本领域普通技术人员将理解的是,执行方法100的任何系统都在本发明的实施例的范围和精神内。
在步骤110中,接收表示包括至少一个头部的图像帧序列的视频数据。在一个实施例中,视频数据包括颜色数据,诸如图像帧的每一个中的每个像素的红色、绿色和蓝色分量值。在一个实施例中,视频数据不包括每个图像帧的深度数据。在一个实施例中,视频数据是由相机捕获的实时图像。在一个实施例中,视频数据包括在训练数据集中。在一个实施例中,训练数据集是合成训练数据集,其包括头部姿势和面部地标两者的准确标签。在一个实施例中,合成训练数据集包括超过500,000帧的视频数据。
在步骤120中,由神经网络从视频数据中提取包括至少一个头部的俯仰角、偏转角和转动角的空间特征。在一个实施例中,神经网络是卷积神经网络(CNN)。在一个实施例中,CNN包括视觉几何组(VGG16)神经网络。在以下描述的上下文中,俯仰角、偏转角和转动角限定视频数据中的头部姿势的估计。
在步骤130中,由递归神经网络(RNN)处理图像帧序列中的两个或更多图像帧的空间特征,以产生至少一个头部的头部姿势估计。在一个实施例中,RNN是门控递归单元(gated recurrent unit,GRU)神经网络。在一个实施例中,RNN是长短期记忆(long short-term memory,LSTM)神经网络。在一个实施例中,RNN是全连接的RNN(fully connected RNN,FC-RNN)。在一个实施例中,神经网络与RNN分开训练。在一个实施例中,神经网络和RNN各自被训练以估计和跟踪视频数据中的头部姿势。在一个实施例中,神经网络和RNN各自被训练以估计和跟踪视频数据中的三维(3D)面部地标。在以下描述的上下文中,面部地标是空间中与头部上的位置对应的3D位置。
现在将根据用户的期望,阐述关于可以或不可以实现前述框架的各种可选架构和特征的更多说明性信息。应该强烈注意的是,出于说明性目的阐述了以下信息,并且不应该被解释为以任何方式进行限制。以下特征中的任一个可以任选地并入或不排除所描述的其他特征。
图1B示出了根据一个实施例的用于视频数据的动态面部分析的系统105的框图。系统105可以被配置为执行图1A的方法100。系统105包括神经网络115和RNN 125。神经网络115和/或RNN 125可以由图形处理器或能够执行方法100的必要操作的任何处理器实现。系统105为估计和跟踪各种面部特征以用于动态面部分析提供广义的和集成的解决方案。
神经网络115接收视频输入106,视频输入106包括表示图像帧序列的视频数据,所述图像帧序列包括至少一个头部。神经网络115从视频输入106提取空间特征并产生每帧估计116。在一个实施例中,每帧估计116是每帧头部姿势估计。在另一实施例中,每帧估计116是每帧面部地标估计。每帧估计116包括视频输入106的每个帧的至少一个头部的俯仰角、偏转角和转动角。RNN 125处理每帧估计116并产生跟踪数据,具体地是输出轨迹126。在以下描述的上下文中,输出轨迹被稳定并且为整个图像帧序列中的每个帧进行去噪估计。在一个实施例中,跟踪数据是头部姿势跟踪数据。在另一实施例中,跟踪数据是面部地标跟踪数据。
在一个实施例中,当神经网络115和RNN 125被单独或一起训练以估计和跟踪视频输入106中的头部姿势时,视频输入106包括第一训练数据集的至少一部分。在另一个实施例中,当神经网络115和RNN 125被单独或一起训练以估计和跟踪视频输入106中的3D面部地标时,视频输入106包括第二训练数据集的至少一部分。第一训练数据集可以对应于头部姿势,第二训练数据集可以对应于面部地标。在一个实施例中,在训练期间,3D面部地标在单次通过神经网络115和RNN 125中直接回归。与此不同,用于训练面部地标跟踪系统的传统技术需要空间递归学习以逐步细化多次通过面部地标跟踪系统中的预测。与传统技术相比,单次通过在计算成本和性能方面提供了显著的优势。
视频数据帧可以被编码为x和y(例如,像素的帧尺寸)、通道(例如,RGB)和时间长度(例如,帧编号)维度的多维张量。神经网络115可以被配置为在使用一个或更多全连接层产生每帧估计116之前在空间和时间域中执行卷积以及最大池化操作以处理视频数据。
RNN 125为时间序列预测提供基于学习的方法。在一个实施例中,使用长短期存储器(LSTM)实现RNN 125,以在不同时间尺度自适应地发现时间依赖性。在一个实施例中,使用门控递归单元(GRU)实现RNN 125,以在不同时间尺度自适应地发现时间依赖性。RNN 125是基于序列的模型,其捕获时间演变,维持时间步长t的递归隐藏状态ht,其激活依赖于前一时间步长t-1的激活。在一个实施例中,ht被计算为:
其中是激活函数,Whh是隐藏到隐藏的矩阵,ht-1是前一时间步长的隐藏状态,Wih是输入到隐藏矩阵,xt是RNN 125的当前层的输入,bh是偏置值。目标输出yt由yt=Whoht+bo给出。考虑线性激活函数并将偏差项bh归入隐藏状态h中,并且方程式(1)可以简化为:
ht=Whhht-1+Wihxt, (2)
其中,在一个实施例中,在RNN 125被训练之后,Whh和Wih被固定。换句话说,当部署RNN 125用于分类时,在训练期间确定的Whh和Wih的值不被改变或不被更新。
由RNN 125执行的计算类似于贝叶斯过滤器。然而,与贝叶斯过滤器实现相比,RNN 125避免了对每帧估计116执行的计算的跟踪器工程(tracker-engineering)。RNN 125提供了直接从数据学习跟踪特征和参数的统一方法,因此不需要跟踪器工程。与此不同,传统的面部分析技术依赖于特定于问题的设计和跟踪的用户调整,即跟踪器工程。例如,可以对面部边界框、头部的刚性变换参数或面部特征执行跟踪。需要用户基于领域知识在贝叶斯过滤器中设置参数。
当在传统的贝叶斯过滤器实现中使用线性卡尔曼过滤器时,最优估计是:
其中ht是状态,xt是时间t的测量,Kt是随时间更新的卡尔曼增益矩阵(Kalman gain matrix),W和V是状态转移和测量模型的矩阵,和是将ht-1和xt与ht相关的两个权重矩阵。利用估计的状态ht,可以将目标输出估计为yt=Vht。贝叶斯过滤的目标是估计状态ht(以及可选的目标输出yt)。对于卡尔曼过滤器,ht|ht-1和xt|ht各自假设具有高斯分布,并且线性模型用于状态转换和测量(例如,矩阵W和V)。
注意方程式(1)和(3)的相似性:状态ht的最佳估计是前一个状态ht-1的估计与当前输入xt的加权线性组合。卡尔曼过滤器的两个权重矩阵是和RNN 125的两个矩阵是Whh和Wih。RNN 125和贝叶斯过滤器(例如,卡尔曼过滤器或粒子过滤器)之间的一个重要区别是两个权重矩阵和随时间变化,表明计算是自适应估计器。与此不同,对于RNN 125,两个获知的权重矩阵Whh和Wih通常在RNN 125被训练之后被固定。
在实践中,RNN 125和贝叶斯过滤器之间还有另外两个重要的区别。首先,对于贝叶斯过滤器,大多数努力都用于设计状态转换和测量模型,这对于复杂的跟踪任务(例如,面部的非刚性跟踪)通常具有挑战性。RNN125更一般地适用于几乎任何跟踪任务,因为可以从训练数据学习最佳参数Whh和Wih。其次,将贝叶斯过滤器与用于通用视觉任务的静态估计器集成在一起也具有挑战性。与此不同,如图1B所示,RNN 125可以与神经网络115(诸如CNN,其执行生成每帧估计116的逐帧特征提取)连结,以形成用于估计和跟踪两者的端到端系统105。RNN 125映射每帧估计116的序列,以匹配已知地面实况输出训练数据的序列。在一个实施例中,训练神经网络115是针对估计和跟踪两者与RNN 125分开进行训练的。在另一实施例中,训练神经网络115是针对估计和跟踪两者与RNN 125端到端进行的。
图1C示出了根据一个实施例的用于图1B中所示的视频数据的动态面部分析的系统105的另一框图。在一个实施例中,神经网络115是VGG16神经网络135和一个附加的全连接层140。在一个实施例中,Whh和Wih两者都被初始化为随机值,并且RNN 125与神经网络115分开被训练。在一个实施例中,RNN 125是预训练的CNN,其具有被转换为递归层的全连接层。
假设在时间戳t处预训练的全连接层具有以下结构:
其中Wio是预训练的输入到输出矩阵,xt是前一个前馈层的输出,bf是偏差。RNN 125通过以下方程式将预训练的全连接层转换为递归层:
用预训练的全连接层初始化的RNN 125结构仅引入单个隐藏到隐藏的权重矩阵Whh,其需要从头开始训练,而其他权重矩阵是预训练的并且可以仅被微调。
图2A示出了根据一个实施例的用于生成每帧头部姿势估计116的神经网络115的框图。在一个实施例中,神经网络115被实现为CNN,其包括3×3卷积层205,每个卷积层205包括64个神经元,接着是3×3卷积层210,每个卷积层210包括128个神经元,接着是3×3卷积层215,每个卷积层215包括256个神经元,接着是3×3卷积层220,每个卷积层220包括512个神经元,接着是3×3卷积层225,每个卷积层225包括512个神经元。最后的3×3卷积层225生成每帧头部姿势估计116。在一个实施例中,每组3×3卷积层之后是池化层。
图2B示出了根据一个实施例的用于生成输出头部姿势226流的RNN 125的框图。在一个实施例中,RNN 125包括全连接层230,其包括4096个神经元,接着是全连接层240,其包括4096个神经元,接着是全连接层245,其产生限定输出头部姿势226的三个值。三个输出值对应于俯仰角、偏转角和转动角。RNN 125的递归方面由垂直连接示出,其指示每个全连接层230和240的输出值分别被反馈到每个全连接层中,以计算一个或更多后续输出值。在一个实施例中,全连接层230和/或240是预训练的全连接CNN层,其使用方程式(5)转换为递归的全连接层。
图2C示出了根据一个实施例的用于生成每帧面部地标的神经网络115的框图。在一个实施例中,神经网络115被实现为CNN,其包括3×3卷积层205,每个卷积层205包括64个神经元,接着是3×3卷积层210,每个卷积层210包括128个神经元,接着是3×3卷积层215,每个卷积层215包括256个神经元,接着是3×3卷积层220,每个卷积层220包括512个神经元,接着是3×3卷积层225,每个卷积层225包括512个神经元。最后的3×3卷积层225生成每帧面部地标估计116。在一个实施例中,每组3×3卷积层之后是池化层。
图2D示出了根据一个实施例的用于生成每帧面部地标的RNN 125的框图。在一个实施例中,RNN 125包括全连接层230,其包括4096个神经元,接着是全连接层240,其包括4096个神经元,接着是全连接层250,其产生限定输出面部地标246的136个值。136个输出值对应于头部上的不同3D位置。
在一个实施例中,使用一组正则化技术训练RNN 125,正则化技术使用变分丢弃(variational dropout),以在前馈和递归连接两者的每个时间步长处以0.25速率重复相同的丢弃掩码。与此不同,传统技术仅在前馈连接的每个时间步长处采样不同的丢弃掩码,并且针对递归连接不使用丢弃掩码。在一个实施例中,在训练期间应用软梯度裁剪以防止RNN 125的各层的梯度发生爆炸。例如,在一个实施例中,在训练期间使用最小平方误差(l2)损失函数,并且如果梯度||g||的l2范数大于阈值τ=10,则梯度重新缩放为g←gτ/||g||。
在一个实施例中,生成大规模合成头部姿势数据集以用于训练系统105以生成输出轨迹126(即,输出头部姿势226)。在一个实施例中,大规模合成头部姿势数据集总共包含10个主题、70个运动轨迹和510,960个帧。需要生成大规模合成头部姿势数据集,因为虽然有几个数据集可用于静止图像的头部姿势估计,但是目前存在非常有限的基于视频的数据集。由于地面实况收集中的各种困难,头部姿势数据集通常在地面实况注释中具有误差和噪声。例如,传统数据集平均具有1度误差。与此不同,大规模合成头部姿势数据集具有准确的地面实况并且包括高分辨率视频序列。
当神经网络115和RNN 125被端到端地训练时,估计误差减小,并且随着时间的推移,生成更平滑的轨迹,指示系统105学习视频中的头部姿势的时间变化。与此不同,卡尔曼过滤(以及类似的粒子过滤)只能减少每帧估计随时间的变化/噪声,但不能减少估计误差。
用于动态面部分析的第二应用程序是视频中的面部地标定位。在一个实施例中,作为预处理步骤,CNN被训练以对每个帧执行面部检测。对于每个视频,使用高斯过滤器在时间上平滑所检测到的面部区域的中心位置,并且使用所检测到的边界框的最大尺寸来提取面部中心序列以用作系统105的训练数据集。预处理步骤随着时间的推移稳定面部检测并且针对具有错过面部检测的少数帧插入面部区域。
在一个实施例中,采用若干类型的数据增强来生成训练数据集。数据增强可以包括图像的水平镜像、反向播放图像序列、以及面部窗口的小的随机缩放和平移。在一个实施例中,R2损失函数用于训练RNN 125以进行面部地标定位和头部姿势估计。当RNN 125针对面部地标估计被训练时,输出层具有对应于68个面部地标的位置的136个神经元,而当RNN 125针对头部姿势估计被训练时,输出层具有对应于俯仰角、偏转角和转动角的3个神经元。
图2E示出了根据一个实施例的用于训练和部署图1B和图1C中所示的动态面部分析系统105的方法255的另一流程图。方法255可以由程序、定制电路或定制电路和程序的组合来执行。例如,方法255可以由系统105、GPU(图形处理单元)、CPU(中央处理单元)、神经网络或能够执行面部分析框架的任何处理器执行。此外,本领域普通技术人员将理解的是,执行方法255的任何系统都在本发明的实施例的范围和精神内。
在步骤260中,生成用于训练动态面部分析系统(诸如系统105)的大规模合成数据集。在一个实施例中,数据集包括用于训练神经网络115的训练数据的第一部分和用于训练RNN 125的训练数据的第二部分。在另一实施例中,数据集中的训练数据用于训练神经网络115和RNN 125两者。
步骤280可以与步骤265、270和275并行完成。在一个实施例中,大规模合成数据集用于同时训练神经网络115和RNN 125两者。或者,步骤280可以在步骤265、270和275中的任何一个之前或之后串行完成。在步骤280中,神经网络(诸如神经网络115)被训练,以使用大规模合成数据集生成每帧估计116。每帧估计116可以是每帧头部姿势估计或每帧面部地标估计。在训练期间,将每帧估计116与包括在大规模合成数据集中的地面实况训练样本进行比较,以计算估计误差。给定估计误差,神经网络115的每层中的参数在误差减少的方向上被更新。可以迭代地重复训练过程,直到达到目标精度和收敛度。
在步骤265中,使用大规模合成数据集预训练CNN。在步骤270中,CNN被转换为RNN(诸如RNN 125)。在一个实施例中,方程式(5)用于将预训练的CNN转换为RNN。在步骤275中,使用大规模合成数据集微调RNN 125以产生经训练的RNN 125。在步骤285中,系统105(包括经训练的神经网络115和经训练的RNN 125)被部署,以执行动态面部分析。重要的是,当系统105被部署以基于图像帧序列生成跟踪数据时,系统105以单次通过方式操作。换句话说,系统105针对一个图像帧输出的跟踪数据不被提供作为用以产生后续图像帧的跟踪数据的输入。单次通过操作减少了从输入视频到生成跟踪数据的延迟。大规模合成数据集提高了性能,特别是系统105的准确性。在一个实施例中,系统105被首先训练以仅产生头部姿势估计,并且系统105稍后被训练以仅产生面部地标估计。
图2F示出了根据一个实施例的用于视频数据的动态面部分析的系统203的又一框图。系统203包括神经网络115和RNN 200。神经网络115被训练以产生每帧估计216,其可包括头部姿势估计和面部地标估计两者。在一个实施例中,RNN 200包括全连接层230和全连接层240。全连接层240的输出被提供给全连接层245和全连接层250两者。全连接层230和全连接层240可以被训练以产生对应于视频输入106中的图像序列的用于头部姿势和面部地标两者的稳定和去噪的特征向量。
全连接层245生成限定输出头部姿势226的三个值,并且全连接层250生成限定输出面部地标246的136个值。三个输出值对应于俯仰角、偏转角和转动角。RNN 200的递归方面由反馈连接示出,该反馈连接指示全连接层230和全连接层240中的每一个的输出值分别被反馈到全连接层中的每一个,以计算一个或更多后续输出值。在一个实施例中,全连接层230和/或全连接层240是预训练的全连接CNN层,其使用方程式(5)转换为递归的全连接层。在一个实施例中,利用使用单个训练数据集的神经网络115端对端地对RNN 200进行训练。在另一实施例中,使用单个训练数据集或单独的训练数据集,与神经网络分开地训练RNN 200。
与传统的贝叶斯过滤器相比,基于RNN的系统105学习联合地估计每帧估计116(或测量),并采用由神经网络115和RNN125提供的单个端到端网络在时间上跟踪每帧估计116。此外,系统105不依赖于传统技术中所需的复杂且特定于问题的跟踪器工程或特征工程。另外,基于RNN的系统105提供可以扩展到视频中的面部分析的其他任务的通用方法。
系统105提供用于估计和跟踪各种面部特征以用于动态面部分析的通用和集成解决方案。与专门设计仅用于面部地标跟踪的传统技术相比,系统105可用于执行视频数据的各种特征跟踪和面部分析任务,诸如跟踪头部姿势、面部地标、面部表情和面部分割。
并行处理架构
图3示出了根据一个实施例的并行处理单元(PPU)300。PPU 300可以被配置为实现系统105。
在一个实施例中,PPU 300是在一个或更多集成电路设备上实现的多线程处理器。PPU 300是一种延迟隐藏架构,其设计成并行处理大量线程。线程(即,执行的线程)是被配置为由PPU 300执行的指令集的实例化。在一个实施例中,PPU 300是被配置为实现用于处理三维(3D)图形数据以生成二维(2D)图像数据以在显示设备(诸如液晶显示器(liquid crystal display,LCD)设备)上显示的图形渲染管线的图形处理单元(GPU)。在其他实施例中,PPU 300可以用于执行通用计算。尽管出于说明性目的,本文提供了一个示例性并行处理器,但应强烈注意的是,这样的处理器仅是出于说明性目的而提出的,并且可采用任何处理器来补充和/或替代该处理器。
如图3所示,PPU 300包括输入/输出(I/O)单元305、主机接口单元310、前端单元315、调度器单元320、工作分配单元325、集线器330、交叉开关(Xbar)370、一个或更多通用处理集群(general processing cluster,GPC)350,以及一个或更多分区单元380。PPU 300可以经由系统总线302连接到主机处理器或其他外围设备。PPU 300还可以连接到包括多个存储器设备304的本地存储器。在一个实施例中,本地存储器可以包括多个动态随机存取存储器(DRAM)设备。
I/O单元305被配置为通过系统总线302从主机处理器(未示出)发送和接收通信(即,命令、数据等)。I/O单元305可以经由系统总线302或通过一个或更多中间设备(诸如存储器桥)与主机处理器直接通信。在一个实施例中,I/O单元305实现用于通过PCIe总线进行通信的外围组件互连快速(Peripheral Component Interconnect Express,PCIe)接口。在替代实施例中,I/O单元305可以实现用于与外部设备进行通信的其他类型的公知接口。
I/O单元305耦合到主机接口单元310,主机接口单元310对经由系统总线302接收的分组进行解码。在一个实施例中,分组表示被配置为使PPU300执行各种操作的命令。主机接口单元310将解码的命令发送到如命令可指定的PPU 300的各种其他单元。例如,一些命令可以被发送到前端单元315。其他命令可以被发送到集线器330或PPU 300的其他单元,诸如一个或多个复制引擎、视频编码器、视频解码器、电源管理单元等(未明确示出)。换句话说,主机接口单元310被配置为在PPU 300的各种逻辑单元之间路由通信。
在一个实施例中,由主机处理器执行的程序对缓冲区中的命令流进行编码,该缓冲区向PPU 300提供工作负载以进行处理。工作负载可以包括要由那些指令处理的多个指令和数据。缓冲区是存储器中的区域,其可由主机处理器和PPU 300两者访问(即,读取/写入)。例如,主机接口单元310可以被配置为由I/O单元305经由通过系统总线302发送的存储器请求访问连接到系统总线302的系统存储器中的缓冲区。在一个实施例中,主机处理器将命令流写入缓冲区,然后将指向命令流开始的指针发送到PPU300。主机接口单元310向前端单元315提供指向一个或更多命令流的指针。前端单元315管理一个或更多流,从流中读取命令并将命令转发到PPU 300的各个单元。
前端单元315耦合到调度器单元320,调度器单元320配置各种GPC350以处理由一个或更多流限定的任务。调度器单元320被配置为跟踪与由调度器单元320管理的各种任务有关的状态信息。状态可以指示任务被指派给哪个GPC 350、任务是活动的还是不活动的、与任务相关联的优先级等。调度器单元320管理一个或更多GPC 350上的多个任务的执行。
调度器单元320耦合到工作分配单元325,工作分配单元325被配置为分派任务以在GPC 350上执行。工作分配单元325可以跟踪从调度器单元320接收的多个调度任务。在一个实施例中,工作分配单元325管理GPC350中的每一个的待处理任务池和活动任务池。待处理任务池可以包括多个时隙(例如,32个时隙),其包含指派给由特定GPC 350处理的任务。活动任务池可以包括用于由GPC 350主动处理的任务的多个时隙(例如,4个时隙)。当GPC 350完成任务的执行时,该任务从GPC 350的活动任务池中被逐出,并且来自待处理任务池中的其他任务中的一个被选择并被调度用于在GPC 350上执行。如果活动任务在GPC 350上空闲,诸如在等待数据依赖性被解决时,则活动任务可以从GPC 350中被逐出并返回到待处理任务池,而待处理任务池中的另一任务被选择并被调度用于在GPC 350上执行。
工作分配单元325经由XBar 370与一个或更多GPC 350进行通信。XBar 370是将PPU 300的许多单元耦合到PPU 300的其他单元的互连网络。例如,XBar 370可以被配置为将工作分配单元325耦合到特定GPC 350。虽然未明确示出,但是PPU 300的一个或更多其他单元被耦合到主机接口单元310。其他单元也可以经由集线器330连接到XBar 370。
任务由调度器单元320管理,并由工作分配单元325分派到GPC 350。GPC 350被配置为处理任务并生成结果。结果可以由GPC 350内的其他任务消耗,经由XBar 370路由到不同的GPC 350,或者存储在存储器304中。结果可以经由分区单元380写入存储器304,分区单元380实现用于向/从存储器304写入和读取数据的存储器接口。在一个实施例中,PPU 300包括数目为U的分区单元380,其等于耦合到PPU 300的独立且不同的存储器设备304的数目。下面将结合图4B更详细地描述分区单元380。
在一个实施例中,主机处理器执行驱动程序内核,该驱动程序内核实现应用程序编程接口(application programming interface,API),该API使得在主机处理器上执行的一个或更多应用程序能够调度操作以在PPU 300上执行。应用程序可以生成指令(即,API调用),其导致驱动程序内核生成一个或更多任务以供PPU 300执行。驱动程序内核将任务输出到由PPU300处理的一个或更多流。每个任务可包括一个或更多相关线程组,本文称为线程束(warp)。线程块可以指代包括用于执行任务的指令的多个线程组。同一线程组中的线程可以通过共享存储器交换数据。在一个实施例中,一个线程组包括32个相关线程。
图4A示出了根据一个实施例的图3的PPU 300的GPC 350。如图4A所示,每个GPC 350包括用于处理任务的多个硬件单元。在一个实施例中,每个GPC 350包括管线管理器410、预光栅操作单元(pre-raster operations unit,PROP)415、光栅引擎425、工作分配交叉开关(work distribution crossbar,WDX)480、存储器管理单元(memory management unit,MMU)490,以及一个或更多纹理处理集群(Texture Processing Cluster,TPC)420。应当理解的是,图4A的GPC 350可以包括代替图4A中所示的单元或者除了图4A中所示的单元之外的其他硬件单元。
在一个实施例中,GPC 350的操作由管线管理器410控制。管线管理器410管理用于处理分配给GPC 350的任务的一个或更多TPC420的配置。在一个实施例中,管线管理器410可以配置一个或更多TPC420中的至少一个以实现图形渲染管线的至少一部分。例如,TPC420可以被配置为在可编程的流式多处理器(streaming multiprocessor,SM)440上执行顶点着色器程序。管线管理器410还可以被配置为将从工作分配单元325接收的分组路由到GPC 350内的适当逻辑单元。例如,一些分组可以被路由到PROP 415和/或光栅引擎425中的固定功能硬件单元,而其他分组可以被路由到TPC420以供图元引擎435或SM 440处理。
PROP单元415被配置为将由光栅引擎425和TPC420生成的数据路由到分区单元380中的光栅操作(Raster Operations,ROP)单元,下面将更详细地描述。PROP单元415还可以被配置为执行颜色混合的优化、组织像素数据、执行地址转换等。
光栅引擎425包括多个固定功能硬件单元,其被配置为执行各种光栅操作。在一个实施例中,光栅引擎425包括设置引擎、粗光栅引擎、剔除引擎、裁剪引擎、精细光栅引擎和图块合并(tile coalescing)引擎。设置引擎接收经变换的顶点并生成与由顶点限定的几何图元相关联的平面方程。平面方程被发送到粗光栅引擎以生成图元的覆盖信息(例如,用于图块的x、y覆盖掩码)。粗光栅引擎的输出可以被发送到剔除引擎,其中与未通过z测试的图元相关联的片段被剔除,并且被发送到裁剪引擎,其中位于视锥体之外的片段被裁剪掉。经过裁剪和剔除留下来的那些片段可以被传递到精细光栅引擎,以基于由设置引擎生成的平面方程来生成像素片段的属性。光栅引擎425的输出包括要由例如在TPC420内实现的片段着色器处理的片段。
包括在GPC 350中的每个TPC420包括M管道控制器(M-Pipe Controller,MPC)430、图元引擎435、一个或更多SM 440,以及一个或更多纹理单元445。MPC430控制TPC420的操作,将从管线管理器410接收的分组路由到TPC420中的适当单元。例如,与顶点相关联的分组可以被路由到图元引擎435,其被配置为从存储器304取回与该顶点相关联的顶点属性。与此不同,与着色器程序相关联的分组可以被发送到SM 440。
在一个实施例中,纹理单元445被配置为从存储器304加载纹理贴图(例如,纹理像素的2D阵列)并对纹理贴图进行采样以产生采样纹理值,用于在由SM 440执行的着色器程序中使用。纹理单元445实现纹理操作,诸如使用mip-map(即,不同细节水平的纹理贴图)的过滤操作。纹理单元445还用作SM 440到MMU 490的加载/存储路径。在一个实施例中,每个TPC420包括两个(2)纹理单元445。
SM 440包括可编程的流式处理器,其被配置为处理由多个线程表示的任务。每个SM 440是多线程的并且被配置为同时执行来自特定线程组的多个线程(例如,32个线程)。在一个实施例中,SM 440实现SIMD(Single-Instruction,Multiple-Data,单指令、多数据)架构,其中线程组(即,warp)中的每个线程被配置为基于同一指令集处理不同的数据集。线程组中的所有线程都执行相同的指令。在另一实施例中,SM 440实现SIMT(Single-Instruction,Multiple Thread,单指令、多线程)架构,其中线程组中的每个线程被配置为基于同一指令集处理不同的数据集,但是线程组中的各个线程在执行期间允许发散。换句话说,当用于该线程组的指令被分派用于执行时,该线程组中的一些线程可以是活动的,从而执行该指令,而该线程组中的其他线程可以是不活动的,从而执行空操作(no-operation,NOP)而不是执行指令。可以在下面结合图5更详细地描述SM 440。
MMU 490提供GPC 350和分区单元380之间的接口。MMU 490可以提供虚拟地址到物理地址的转换、存储器保护和存储器请求的仲裁。在一个实施例中,MMU 490提供一个或更多转换后备缓冲器(translation lookaside buffer,TLB),用于改善存储器304中的虚拟地址到物理地址的转换。
图4B示出了根据一个实施例的图3的PPU 300的存储器分区单元380。如图4B所示,存储器分区单元380包括光栅操作(Raster Operation,ROP)单元450、二级(L2)高速缓存460、存储器接口470和L2交叉开关(XBar)465。存储器接口470被耦合到存储器304。存储器接口470可以实现16位、32位、64位、128位数据总线等,用于高速数据传输。在一个实施例中,PPU 300包括U个存储器接口470,每个分区单元380一个存储器接口470,其中每个分区单元380被连接到相应的存储器设备304。例如,PPU300可以被连接到多达U个存储器设备304,诸如图形双倍数据速率、版本5、同步动态随机存取存储器(graphics double-data-rate,version 5,synchronous dynamic random access memory,GDDR5SDRAM)。在一个实施例中,存储器接口470实现DRAM接口,并且U等于8。
在一个实施例中,PPU 300实现多级存储器层级。存储器304位于耦合到PPU 300的SDRAM的片外。可以取回来自存储器304的数据并将其存储在L2高速缓存460中,L2高速缓存460位于芯片上并且在各种GPC350之间共享。如图所示,每个分区单元380包括与对应的存储器设备304相关联的L2高速缓存460的一部分。然后,可以在GPC 350内的各种单元中实现较低级别的高速缓存。例如,SM 440中的每一个可以实现一级(L1)高速缓存。L1高速缓存是专用于特定SM 440的专用存储器。可以取回来自L2高速缓存460的数据并将其存储在L1高速缓存的每一个中,以便在SM 440的功能单元中进行处理。L2高速缓存460被耦合到存储器接口470和XBar 370。
ROP单元450包括ROP管理器455、颜色ROP(Color ROP,CROP)单元452和Z ROP(ZROP)单元454。CROP单元452执行与像素颜色相关的光栅操作,例如颜色压缩、像素混合等。ZROP单元454结合光栅引擎425实现深度测试。ZROP单元454从光栅引擎425的剔除引擎接收与像素片段相关联的样本位置的深度。ZROP单元454测试与片段相关联的样本位置相对深度缓冲器中的对应深度的深度。如果片段通过样本位置的深度测试,则ZROP单元454更新深度缓冲器并将深度测试的结果发送到光栅引擎425。ROP管理器455控制ROP单元450的操作。应当理解的是,分区单元380的数量可以与GPC 350的数量不同,因此,每个ROP单元450可以耦合到GPC 350中的每一个。因此,ROP管理器455跟踪从不同GPC 350接收的分组,并且确定由ROP单元450生成的结果被路由到哪个GPC 350。CROP单元452和ZROP单元454经由L2XBar 465耦合到L2高速缓存460。
图5示出了根据一个实施例的图4A的流式多处理器440。如图5所示,SM 440包括指令高速缓存505、一个或更多调度器单元510、寄存器文件520、一个或更多处理核550、一个或更多特殊功能单元(special function unit,SFU)552、一个或更多加载/存储单元(load/store unit,LSU)554、互连网络580、共享存储器/L1高速缓存570。
如上所述,工作分配单元325分派任务用于在PPU 300的GPC 350上执行。任务被分配给GPC 350内的特定TPC420,并且如果任务与着色器程序相关联,则可以将任务分配给SM 440。调度器单元510从工作分配单元325接收任务,并管理指派给SM 440的一个或更多线程组(即,线程束)的指令调度。调度器单元510调度并行线程组中的线程用于执行,其中每个组称为线程束。在一个实施例中,每个线程束包括32个线程。调度器单元510可以管理多个不同的线程束、调度线程束用于执行,然后在每个时钟周期期间将指令从多个不同的线程束分派给各个功能单元(即,核550、SFU 552和LSU 554)。
在一个实施例中,每个调度器单元510包括一个或更多指令分派单元515。每个分派单元515被配置为向一个或更多功能单元发送指令。在图5所示的实施例中,调度器单元510包括两个分派单元515,其使得来自相同warp的两个不同指令能够在每个时钟周期期间被分派。在替代实施例中,每个调度器单元510可以包括单个分派单元515或附加分派单元515。
每个SM 440包括寄存器文件520,其为SM 440的功能单元提供一组寄存器。在一个实施例中,寄存器文件520在每个功能单元之间被划分,使得每个功能单元被分配寄存器文件520的专用部分。在另一实施例中,寄存器文件520在由SM 440执行的不同线程束之间被划分。寄存器文件520为连接到功能单元的数据路径的操作数提供临时存储。
每个SM 440包括L个处理核550。在一个实施例中,SM 440包括大数目(例如,128个等)的不同的处理核550。每个核550可以包括完全管线化的单精度的处理单元,其包括浮点算术逻辑单元和整数算术逻辑单元。核550还可以包括双精度处理单元,其包括浮点算术逻辑单元。在一个实施例中,浮点算术逻辑单元实现用于浮点算术的IEEE 754-2008标准。每个SM 440还包括执行特殊功能(例如,属性评估、倒数平方根等)的M个SFU 552,以及实现共享存储器/L1高速缓存570和寄存器文件520之间的加载和存储操作的N个LSU 554。在一个实施例中,SM 440包括128个核550、32个SFU 552和32个LSU 554。
每个SM 440包括互连网络580,互连网络580将功能单元中的每一个连接到寄存器文件520并且将LSU 554连接到寄存器文件520、共享存储器/L1高速缓存570。在一个实施例中,互连网络580是交叉开关,其可以被配置为将任何功能单元连接到寄存器文件520中的任何寄存器,并且将LSU 554连接到共享存储器/L1高速缓存570中的寄存器文件和存储器位置。
共享存储器/L1高速缓存570是片上存储器阵列,其允许SM 440与图元引擎435之间以及SM 440中的线程之间的数据存储和通信。在一个实施例中,共享存储器/L1高速缓存570包括64KB的存储容量,并且位于从SM 440到分区单元380的路径中。共享存储器/L1高速缓存570可用于高速缓存读取和写入。
上述PPU 300可以被配置为比传统CPU快得多地执行高度并行计算。并行计算在图形处理、数据压缩、生物识别、流处理算法等方面具有优势。
当被配置用于通用并行计算时,可以使用更简单的配置。在该模型中,如图3所示,省略固定功能图形处理单元,创建更简单的编程模型。在该配置中,工作分配单元325将线程块直接指派和分配给TPC420。块中的线程执行相同的程序,在计算中使用唯一线程ID来确保每个线程生成唯一结果,使用SM 440执行程序和执行计算,使用共享存储器/L1高速缓存570在线程之间进行通信,以及使用LSU 554通过分区共享存储器/L1高速缓存570和分区单元380读取和写入全局存储器。
当被配置用于通用并行计算时,SM 440还可以写入调度器单元320可以用于在TPC420上启动新工作的命令。
在一个实施例中,PPU 300包括图形处理单元(GPU)。PPU 300被配置为接收指定用于处理图形数据的着色器程序的命令。图形数据可以被限定为一组图元,诸如点、线、三角形、四边形、三角形条等。通常,图元包括指定图元的多个顶点的数据(例如,在模型空间坐标系中)以及与图元的每个顶点相关联的属性。PPU 300可以被配置为处理图形图元以生成帧缓冲区(即,用于显示器的每个像素的像素数据)。
应用程序将场景的模型数据(即,顶点和属性的集合)写入诸如系统存储器或存储器304的存储器。模型数据限定可在显示器上可见的每个对象。然后,应用程序对驱动程序内核进行API调用,其请求渲染和显示模型数据。驱动程序内核读取模型数据并将命令写入一个或更多流以执行处理模型数据的操作。命令可以引用要在PPU 300的SM 440上实现的不同着色器程序,包括顶点着色器、外壳着色器、域着色器、几何着色器和像素着色器中的一个或更多。例如,SM 440中的一个或更多可以被配置为执行顶点着色器程序,该顶点着色器程序处理由模型数据限定的多个顶点。在一个实施例中,不同的SM 440可以被配置为同时执行不同的着色器程序。例如,SM 440的第一子集可以被配置为执行顶点着色器程序,而SM 440的第二子集可以被配置为执行像素着色器程序。SM 440的第一子集处理顶点数据以产生经处理的顶点数据并将经处理的顶点数据写入L2高速缓存460和/或存储器304。在经处理的顶点数据被光栅化(即,从三维数据变换为屏幕空间中的二维数据)以产生片段数据之后,SM 440的第二子集执行像素着色器以产生经处理的片段数据,然后将其与其他经处理的片段数据混合并写入存储器304中的帧缓冲区。顶点着色器程序和像素着色器程序可以同时执行,以管线化方式处理来自同一场景的不同数据,直到场景的所有模型数据都被渲染到帧缓冲区。然后,帧缓冲区的内容被发送到显示控制器以在显示设备上显示。
PPU 300可以包括在台式计算机、膝上型计算机、平板计算机、智能电话(例如,无线、手持设备)、个人数字助理(personal digital assistant,PDA)、数码相机、手持电子设备等中。在一个实施例中,PPU 300体现在单个半导体衬底上。在另一实施例中,PPU 300与一个或更多其他逻辑单元(诸如精简指令集计算机(reduced instruction set computer,RISC)CPU、存储器管理单元(memory management unit,MMU)、数模转换器(digital-to-analog converter,DAC)等)一起被包括在片上系统(system-on-a-chip,SoC)中。
在一个实施例中,PPU 300可以包括在包括诸如GDDR5SDRAM的一个或更多存储器设备304的图形卡上。图形卡可以被配置为与台式计算机的主板上的PCIe插槽接口,该主板包括例如北桥芯片组和南桥芯片组。在又一实施例中,PPU 300可以是包括在主板的芯片组(即,北桥)中的集成图形处理单元(integrated graphics processing unit,iGPU)。
可以在PPU 300内执行各种程序,以便实现神经网络的各个层。例如,设备驱动程序可以在PPU 300上启动内核以在一个SM 440(或多个SM 440)上实现神经网络。设备驱动程序(或由PPU 300执行的初始内核)还可以启动PPU 300上的其他内核以执行神经网络的其他层。另外,神经网络的一些层可以在PPU 300内实现的固定单元硬件上实现。应当理解的是,在由SM 440上的后续内核处理之前,来自一个内核的结果可以由一个或更多中间固定功能硬件单元处理。
示例性系统
图6示出了示例性系统600,其中可以实现各种先前实施例的各种架构和/或功能。示例性系统600可用于实现用于动态面部分析的系统105。
如图所示,提供了系统600,其包括连接到通信总线602的至少一个中央处理器601。通信总线602可以使用任何合适的协议(诸如PCI(Peripheral Component Interconnect,外围组件互连)、PCI-Express、AGP(Accelerated Graphics Port,加速图形端口)、超传输(HyperTransport)或任何其他总线或一个或更多点对点通信协议)来实现。系统600还包括主存储器604。控制逻辑(软件)和数据存储在主存储器604中,主存储器604可以采用随机存取存储器(RAM)的形式。
系统600还包括输入设备612、图形处理器606和显示器608,即传统的CRT(cathode ray tube,阴极射线管)、LCD(liquid crystal display,液晶显示器)、LED(light emitting diode,发光二极管),等离子显示器等。可以从输入设备612(例如键盘、鼠标、触摸板、麦克风等)接收用户输入。在一个实施例中,图形处理器606可以包括多个着色器模块、光栅化模块等。前述模块中的每一个甚至可以位于单个半导体平台上以形成图形处理单元(GPU)。
在本说明书中,单个半导体平台可以指单个基于单一半导体的集成电路或芯片。应当注意的是,术语单个半导体平台还可以指具有增加的连接性的多芯片模块,其模拟片上操作,并且相对于利用传统的中央处理单元(CPU)和总线的实现方式进行了实质性的改进。当然,根据用户的期望,各种模块也可以单独设置或者以半导体平台的各种组合设置。
系统600还可以包括辅助贮存器610。辅助贮存器610包括例如硬盘驱动器和/或可移除存储驱动器、代表软盘驱动器、磁带驱动器、光盘驱动器、数字多功能盘(digital versatile disk,DVD)驱动器、录音设备、通用串行总线(universal serial bus,USB)闪存。可移除存储驱动器以众所周知的方式从可移除存储单元读取和/或向其写入。
计算机程序或计算机控制逻辑算法可以存储在主存储器604和/或辅助贮存器610中。这样的计算机程序在被执行时使系统600能够执行各种功能。存储器604、贮存器610和/或任何其他存储是计算机可读介质的可能示例。与手势相关联的数据流可以存储在主存储器604和/或辅助存储器610中。
在一个实施例中,各种先前附图的架构和/或功能可以在中央处理器601、图形处理器606、能够具有中央处理器601和图形处理器606两者的至少一部分能力的集成电路(未示出)、芯片组(即,设计成作为执行相关功能的单元工作和销售的一组集成电路等),和/或用于任何其他的集成电的上下文中实现。
此外,各种先前附图的架构和/或功能可以在通用计算机系统、电路板系统、专用于娱乐目的的游戏控制台系统、专用系统和/或任何其他所需的系统的上下文中实现。例如,系统600可以采用台式计算机、膝上型计算机、服务器、工作站、游戏控制台、嵌入式系统和/或任何其他类型的逻辑的形式。此外,系统600可以采用各种其他设备(包括但不限于个人数字助理(PDA)设备、头戴式显示设备,自动驾驶车辆、移动电话设备、电视等)的形式。
此外,虽然未示出,但是系统600可以耦合到用于通信目的的网络(例如,电信网络、局域网(local area network,LAN)、无线网络、诸如因特网的广域网(wide area network,WAN),对等网络、有线网络等)。
虽然上面已经描述了各种实施例,但是应该理解的是,它们仅以示例的方式呈现,而不是限制。因此,优选实施例的宽度和范围不应受任何上述示例性实施例的限制,而应仅根据所附权利要求及其等同物来限定。
- 还没有人留言评论。精彩留言会获得点赞!