一种零售业务及大数据系统的制作方法
本发明涉及大数据系统领域,尤其涉及一种零售业务及大数据系统。
背景技术:
在传统的零售系统中,包括了实体店零售和电子商务。在零售门店中,消费者在实体店中以一手交钱一手交货的方式进行零售业务,在电商平台中,消费者消费时并没有接触过真实商品,通过平台下单购买后由物流配送到家。以上两种销售方式存在共同的弊端,就是零售业务的数据不能互通。
技术实现要素:
本发明的目的在于针对背景技术中的缺陷,提出一种零售业务及大数据系统,通过业务系统和大数据系统,将线上线下的零售业务实现数据互通。
为达此目的,本发明采用以下技术方案:
一种零售业务及大数据系统,包括了线下客户端、业务系统和大数据系统,所述线下客户端获取用户购买数据并传输用户购买数据至业务系统和大数据系统;所述业务系统根据用户购买数据,按照服务类型将业务系统分类成多个独立的微服务;所述大数据系统接收用户购买数据并读取业务系统上应用数据库数据和应用日志数据并进行分析,根据数据分析结果提供零售信息。
优选的,所述业务系统包括服务注册中心,所述服务注册中心用于多个独立的微服务进行注册,每个独立的微服务均从所述服务注册中心获取到每个独立的微服务的注册清单。
优选的,每个独立的服务之间通过服务名进行相互调用来获取每个独立的微服务的数据信息。
优选的,所述业务系统还包括zuul网关,所述zuul网关提供服务治理框架,并将每个独立的微服务的服务实例维护调度至所述服务治理框架,所述服务治理框架自主维护每个独立的微服务的服务实例。
优选的,所述zuul网关统一调用每个独立的微服务对微服务的接口做前置过滤,完成对微服务的接口的拦截和校验。
优选的,所述业务系统还包括配置中心,所述配置中心将业务系统的配置文件放到统一的位置进行管理,所述线下客户端通过接口获取配置文件,在配置中心修改配置文件后,线下客户端所获取到的配置文件也为修改后的配置文件。
优选的,所述大数据系统包括分布式消息队列kafka集群、spark集群、分布式文件系统hdfs和es数据库;
所述业务系统将应用数据库数据、应用日志数据以及用户购买数据写入到所述分布式队列kafka集群中;
所述分布式队列kafka集群将应用数据库数据、应用日志数据以及用户购买数据重新写入到所述分布式文件系统hdfs中;
所述spark集群从所述分布式文件系统hdfs中读取数据,包括但不限于应用数据库数据、应用日志数据以及用户购买数据,所述spark集群对数据进行解析,得出解析结果。
优选的,所述es数据库通过es-hadoop组件将解析结果回写至所述es数据库供所述业务系统读取。
优选的,所述业务系统还包括db数据层,所述db数据层包括但不限于mysql数据库、redis存储系统和es数据库;
所述业务系统和所述大数据系统共用所述db数据层。
附图说明
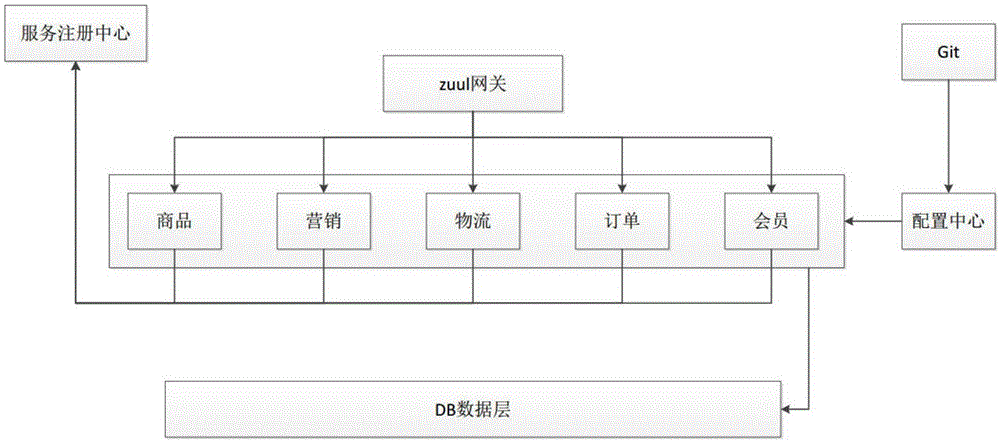
图1是本发明的业务系统架构图;
图2是本发明的大数据系统架构图。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
本实施例的一种零售业务及大数据系统,包括了线下客户端、业务系统和大数据系统,所述线下客户端获取用户购买数据并传输用户购买数据至业务系统和大数据系统;所述业务系统根据用户购买数据,按照服务类型将业务系统分类成多个独立的微服务;所述大数据系统接收用户购买数据并读取业务系统上应用数据库数据和应用日志数据并进行分析,根据数据分析结果提供零售信息。
在实际应用中,线下客户端包括手机、ipad、摄像头和导购屏等智能件,线下实体店主要通过摄像头捕捉会员身份信息,消费者扫商品二维码的行为以及其它硬件设备捕捉到的信息通过网络发送到业务系统及大数据系统,由业务系统和大数据系统进行数据交互和解析,根据分析结果提供精准的消费信息给用户,打通线下实体店和线上渠道之间的数据,结合线上线下的运营经验和数据,更好的实现数据互通,更好的服务消费者。
如图1所示,业务系统按照服务类型将业务系统分类成多个独立的微服务,包括但限于订单、商品、营销、会员信息、物流和渠道等微服务,每个微服务均为独立的服务。
优选的,所述业务系统包括服务注册中心,所述服务注册中心用于多个独立的微服务进行注册,每个独立的微服务均从所述服务注册中心获取到每个独立的微服务的注册清单。每个独立的服务之间通过服务名进行相互调用来获取每个独立的微服务的数据信息。
微服务通过分解巨大单体式应用为多个服务方法解决了复杂性问题,每个微服务相对较小;每个单体应用不局限于固定的技术栈,可以自由选择开发技术,提供api服务;每个微服务单独地开发,测试和部署;微服务系统改善故障隔离,一个服务宕机不会影响其他的服务的运行;系统非常容易扩展。
业务系统提供一个服务注册中心,所述服务注册中心专门用于为每个微服务提供注册,每个微服务都可以获取服务注册中心的注册清单,每个微服务相互调用不在通过现有具体ip地址,而是通过服务名来进行调用。
优选的,所述业务系统还包括zuul网关,所述zuul网关提供服务治理框架,并将每个独立的微服务的服务实例维护调度至所述服务治理框架,所述服务治理框架自主维护每个独立的微服务的服务实例。所述zuul网关统一调用每个独立的微服务对微服务的接口做前置过滤,完成对微服务的接口的拦截和校验。
业务系统外层调用都必须通过zuul网关,zuul网关提供一个服务治理框架,并将每个微服务的服务实例的维护工作交给服务治理框架自动完成,提供负载均衡的功能。在网关服务上进行统一调度来对微服务接口做前置过滤,以实现对微服务接口的拦截和校验。
所述业务系统还包括配置中心,所述配置中心将业务系统的配置文件放到统一的位置进行管理,位置包括但不限于git,所述线下客户端通过接口获取配置文件,在配置中心修改配置文件后,线下客户端所获取到的配置文件也为修改后的配置文件。
优选的,如图2所示,所述大数据系统包括分布式消息队列kafka集群、spark集群、分布式文件系统hdfs和es数据库;
所述业务系统将应用数据库数据、应用日志数据以及用户购买数据写入到所述分布式队列kafka集群中;
所述分布式队列kafka集群将应用数据库数据、应用日志数据以及用户购买数据重新写入到所述分布式文件系统hdfs中;
所述spark集群从所述分布式文件系统hdfs中读取数据,包括但不限于应用数据库数据、应用日志数据以及用户购买数据,所述spark集群对数据进行解析,得出解析结果。
所述es数据库通过es-hadoop组件将解析结果回写至所述es数据库供所述业务系统读取。
所述业务系统还包括db数据层,所述db数据层包括但不限于mysql数据库、redis存储系统和es数据库;
所述业务系统和所述大数据系统共用所述db数据层。
采用上述系统架构是因为在分布式文件系统hdfs上使用spark集群创建的数据库为大数据提供统一的操作接口,分布式文件系统hdfs的数据相对于线上更加稳定,可以作为数据恢复的最后一道防线,而es数据库具快速读取,存储大量数据和自动灾备的功能。
以上结合具体实施例描述了本发明的技术原理。这些描述只是为了解释本发明的原理,而不能以任何方式解释为对本发明保护范围的限制。基于此处的解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些方式都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!