一种基于深度学习的SDN应用识别方法与流程
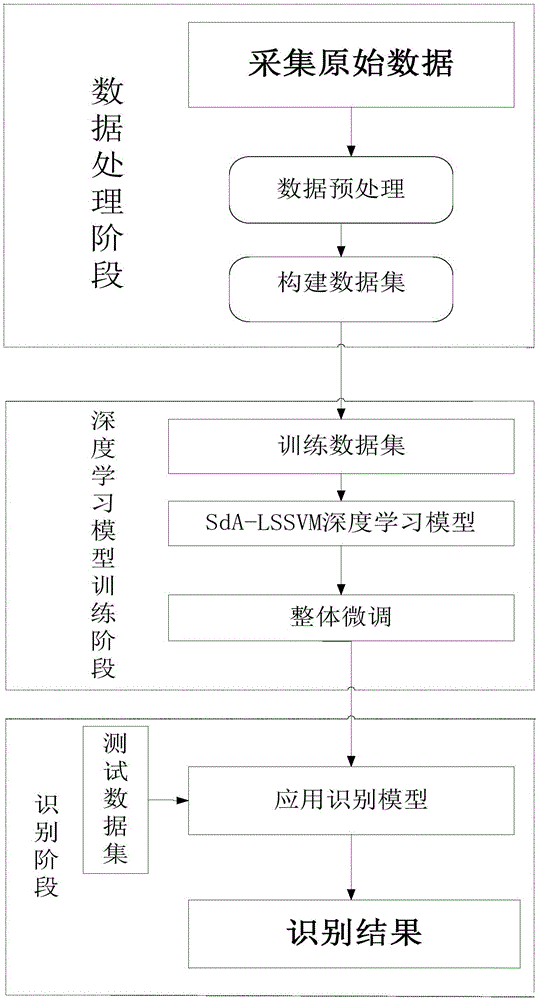
本发明涉及网络通信
技术领域:
,具体涉及一种基于深度学习的sdn应用识别方法。
背景技术:
:随着互联网的普及与发展,即时通信、视频直播、搜索引擎、网约汽车等各类互联网应用层出不穷,覆盖了生活的方方面面,使人们可以不受地域时空的限制,快速沟通、便捷出行,工作学习等方式也发生了巨变。各类新应用不断涌现为我们生活带来便利的同时,也随之产生了异常庞大的网络流量。从海量流量中准确有效地识别出网络应用,将有助于网络管理员对各种业务流进行实时的监控与管理,有助于运营商在规划和建设网络时了解网络各类应用的需求状况,有助于研究人员了解各种网络流量的特征信息及相应的用户行为。可见应用识别是研究差异性服务、qos保障、入侵检测、流量监控以及用户行为分析的前提和基础,对网络安全管理和资源配置都具有十分重要的意义。传统的应用识别方法依赖于网络数据包的端口信息和特征载荷。随着网络的不断发展,应用趋于使用动态端口并采用加密技术,导致传统的应用识别方法面临着巨大的挑战。随着机器学习的兴起,机器学习模型可以从流持续时间、分组到达时间间隔等流量数据中提取每种应用的特征从而实现识别,为应用识别提供了新的技术方法。特别是由机器学习发展而来的深度学习,通过多层神经网络,可以提取海量数据中更深层的非线性特征关系,能够识别加密数据以及未知的新应用,大大提高了应用识别的准确率。因此,运用深度学习方法对流量进行应用识别是当前的研究趋势。作为下一代网络架构,软件定义网络(sdn)目前仅支持基于网络第2/3/4层的路由策略规划,但缺乏对网络更高层的应用感知。若能在sdn中实现应用识别以获取流量的应用层信息,就可以更智能地提供网络服务。同时,与僵化的传统网络架构不同,sdn控制平面和数据平面相分离,逻辑控制集中到了控制器中。控制器所拥有的全局视图有利于从交换机中收集网络流量并提取其统计特征。而且sdn的可编程性允许用户构建流量分析的软件,可作为附加应用程序直接部署在sdn控制平面上,无需安装物理硬件,为sdn的应用识别提供了有力的支持。sdn、深度学习等新兴技术的出现,为流量应用识别提供了新的思路与技术支持,以实现更精细的网络流量管理,提高网络服务质量。近年来国内外的研究人员为了应对网络应用的复杂性,对应用识别展开了大量的研究工作。技术实现要素:本发明针对现有技术的不足,提出了一种基于深度学习的sdn应用识别方法。本发明解决其技术问题所采用的技术方案如下:一种基于深度学习的sdn应用识别方法,其特征在于,包括三个阶段:(1)数据处理阶段(1.1)数据预处理:特征值标准化:在sdn网络流量数据采集中,对流量数据进行标准化处理:其中σ(x)是均方差,是x分布的平均值;标记项的处理:对不同非数字格式的应用类型进行标记编码。(1.2)数据集的构建:对步骤一输出的每一类数据划分为无标记数据集、有标记数据集和测试数据集;无标记数据集、有标记数据集是供深度学习模型训练使用,测试数据集用来测试深度学习模型的识别性能。(3)sda-lssvm深度学习模型训练阶段(2.1)建立sda-lssvm深度学习模型:由多个去噪自动编码器dae堆叠形成堆叠去噪编码器sda,其中,每个去噪自动编码器dae的隐含层的特征表达作为下一个去噪自动编码器dae的输入,将最后一个去噪自动编码器dae的隐含层接入最小二乘向量机lssvm,作为lssvm的输入层进行识别,形成sda-lssvm深度学习模型;lssvm中的约束是等式约束,在优化目标函数中采用误差平方和的方式,通过最优条件将原来svm中需要求解的二次规划问题转化为线性方程组求解问题。(2.2)确定sda中每个隐含层的节点个数和所有隐含层的个数,以及lssvm中所有隐含层的个数;第一层dae的隐含层节点个数为输入的流量特征数和最后一层dae的隐含层节点个数是输出应用类型个数。(2.3)训练sda-lssvm深度学习模型:用无标记的数据集作为sda-lssvm深度学习模型的输入,堆叠去噪编码器sda通过不断的无监督学习特征表达后,将隐含层的特征表达输入lssvm中进行识别,lssvm中隐含层之间的权重为去噪自动编码器dae逐层训练时所得到的权值矩阵,得到一个标准的bp神经网络,然后用有标记的数据集对网络进行反向的有监督微调,最终得到训练好的sda-lssvm深度学习模型。(3)应用识别阶段(3.1)对待识别的sdn网络流量数据按步骤(1.1)中的方法进行标准化处理,得到适用于sda-lssvm深度学习模型输入的数据。(3.2)将标准化处理后的数据输入步骤(2)训练好的sda-lssvm深度学习模型中,得到sdn应用类型。本发明的有益效果是:本发明创新性的提出了一种基于深度学习的sdn应用识别方法,构建了sda-lssvm深度学习模型,该sda-lssvm深度学习模型克服了传统应用识别技术无法识别加密流量、识别率不稳定等局限性,且可以自动学习并提取网络流量特征信息具有良好的自适应性。附图说明图1为本发明方法的流程图;图2为sda-lssvm应用模型图。具体实施方式下面结合附图对本发明作进一步的说明。如图1所示,本发明提供的一种基于深度学习的sdn应用识别方法,包括三个阶段:(1)数据处理阶段(1.1)数据预处理:特征值标准化:在sdn网络流量数据采集中,原始数据一般会具有不同的尺度,且每类数据的平均值、方差等都不相同;对流量数据进行标准化处理:其中σ(x)是均方差,是x分布的平均值;标准化后的特征项具有近似均值和标准均方差,以此来消除高变异性和缩放效应。标记项的处理:lssvm需要有标记数据集进行有监督训练,因此对不同非数字格式的应用类型进行标记编码。如表1,每个码号对应某一种具体的应用。表1数据集标记编码应用类型wwwmailftp-controlftp-pasvattack标号01234应用类型p2pdatabaseftp-datamultimediaservices标号56789(1.2)数据集的构建:对步骤一输出的每一类数据划分为无标记数据集、有标记数据集和测试数据集;无标记数据集、有标记数据集是供深度学习模型训练使用,而测试数据集则是用来测试深度学习模型的识别性能的。(4)sda-lssvm深度学习模型训练阶段,如图2所示。(2.1)建立sda-lssvm深度学习模型:由于去噪自动编码器dae能够实现对输入数据的重构,当一个去噪自动编码器训练好了之后,其中间的隐含层就可以看做是输入数据的特征表达;由多个去噪自动编码器dae堆叠形成堆叠去噪编码器sda,其中,每个去噪自动编码器dae的隐含层的特征表达作为下一个去噪自动编码器dae的输入,将最后一个去噪自动编码器dae的隐含层接入最小二乘向量机lssvm,作为lssvm的输入层进行识别,形成sda-lssvm深度学习模型;lssvm中的约束是等式约束,在优化目标函数中采用误差平方和的方式,通过最优条件将原来svm中需要求解的二次规划问题转化为线性方程组求解问题,从而降低计算复杂度。(2.2)确定sda中每个隐含层的节点个数和所有隐含层的个数,以及lssvm中所有隐含层的个数;除了第一层dae的隐含层节点个数为输入的流量特征数和最后一层dae的隐含层节点个数是输出应用类型个数,中间的dae隐含层节点个数是不确定;而隐含层节点个数是通过大量的模拟仿真实验确定的;隐含层层数将直接关联深度学习模型的深度,可以通过隐含层层数的增加有利于对特征的更全面的学习。(2.3)训练sda-lssvm深度学习模型:用无标记的数据集作为sda-lssvm深度学习模型的输入,堆叠去噪编码器sda通过不断的无监督学习特征表达后,将隐含层的特征表达输入lssvm中进行识别,lssvm中隐含层之间的权重为去噪自动编码器dae逐层训练时所得到的权值矩阵,得到一个标准的bp神经网络,然后用有标记的数据集对网络进行反向的有监督微调,最终得到训练好的sda-lssvm深度学习模型。(3)应用识别阶段(3.1)对待识别的sdn网络流量数据按步骤(1.1)中的方法进行标准化处理,得到适用于sda-lssvm深度学习模型输入的数据;(3.2)将标准化处理后的数据输入步骤(2)训练好的sda-lssvm深度学习模型中,得到sdn应用类型。此外,可以通过测试数据集测试深度学习模型的识别性能。上述实施例用来解释说明本发明,而不是对本发明进行限制。在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1