基于深度学习的问题自动生成方法与流程
本发明属于自然语言处理
技术领域:
,具体涉及一种基于深度学习的问题自动生成方法。
背景技术:
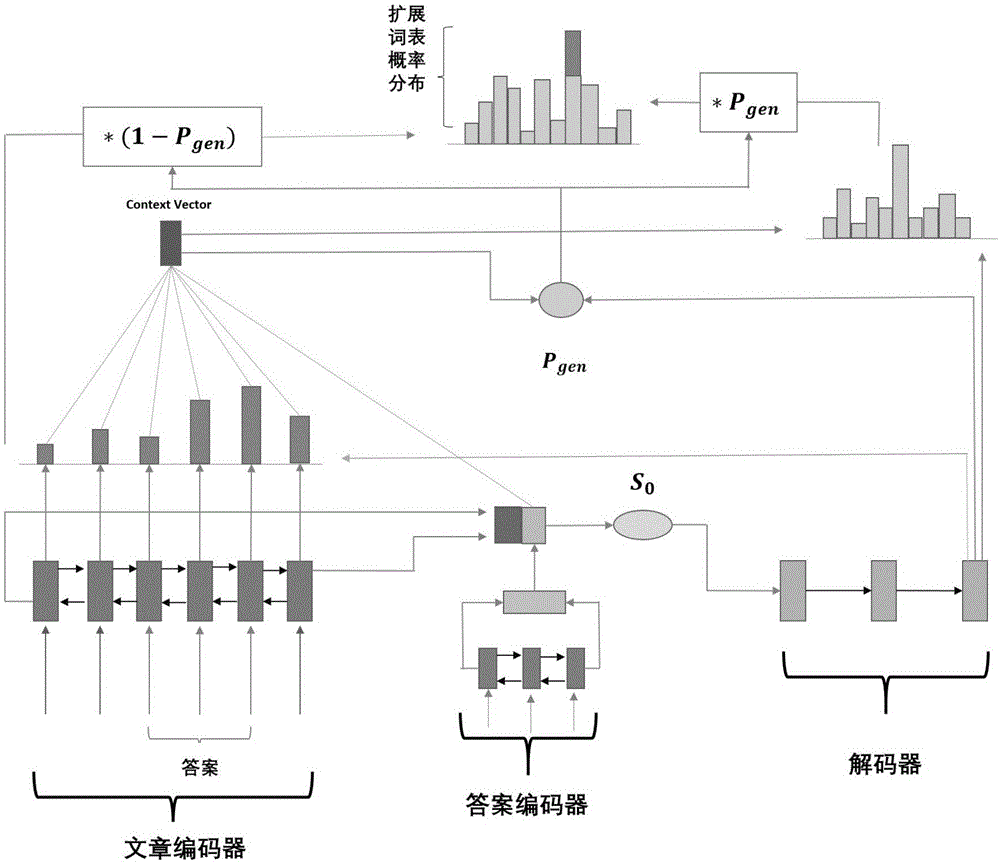
:如何教会机器更好的阅读和理解人类语言是一个较大的挑战,这需要机器能理解自然语言和知道一些必要的常识道理,近年来,关于问题自动生成的研究在自然语言领域内变得越来越流行。问题自动生成就是在给定文章和答案的情况下,自动的生成与文章和答案相关的高质量问题。问题自动生成方法是自动的生成与文章相关的问题的方法,该方法可以广泛的应用于于智能教学、智能问答和知识问答游戏等,例如:智能教育:在儿童教育领域,孩子读完一篇故事后,问题自动生成方法会根据故事内容自动生成各式各样的相关问题,让孩子回答,激发孩子的阅读兴趣。智能辅导:问题自动生成方法可以自动的批量生成练习题,供学生练习。问答游戏:问题自动生成方法可以生成各种各样的问题,让玩家回答,回答正确则获得相应奖励。智能问答:问题自动生成方法可以用来辅助问题回答模型的训练,问题自动生成方法可以生成各种各样的问题,由此可以自动获得大量的<文章,问题,答案>样本,用来训练问题回答模型,应用于智能问答任务。现有方法通常是基于规则来实现问题自动生成方法,严重依赖于人工抓取的特征集,其生成的问题通常存在语句不通顺,语义不合理,词重复,与文章内容不匹配等缺陷。技术实现要素:本发明的目的在于提供一种基于深度学习的问题自动生成方法。实现本发明目的的技术方案为:一种基于深度学习的问题自动生成方法,包括以下步骤:步骤1,构建训练集<文章,答案,问题>、验证集<文章,答案,问题>、预测集<文章,答案>;步骤2,利用深度学习框架tensorflow搭建基于编码器-解码器的序列到序列神经网络模型;步骤3,对训练集、验证集和预测集内的句子进行分词、制作词表、词嵌入操作;步骤4,利用训练集来训练模型,利用验证集检测当前训练的模型是否已经过拟合,如果过拟合,则停止训练;否则继续训练;步骤5,用训练好的模型对预测集进行解码,生成问题。与现有技术相比,本发明的显著优点为:传统的问题自动生成技术基于规则来实现的,严重依赖于人工抓取的特征集,本发明基于深度学习方法,可以自动抓取到重要特征,极大减少了模型对人工抓取特征集的依赖;在应用效果上,基于深度学习的问题自动生成方法也远好于基于规则的方法。附图说明图1是本发明构建的神经网络图。图2是本发明基于深度学习的问题自动生成方法流程图。具体实施方式本发明针对智能教学、智能问答和知识问答游戏等领域所需的问题生成应用,提出了基于深度学习的问题自动生成方法。如图2所示,本发明的一种基于深度学习的问题自动生成方法,包括以下步骤:步骤1,构建训练集<文章,答案,问题>、验证集<文章,答案,问题>、预测集<文章,答案>,所述答案为文章中某一连续片段;步骤2,利用深度学习框架tensorflow搭建基于编码器-解码器的序列到序列神经网络模型;所述神经网络模型包含注意力机制,pointer-generatornetwork,answer-supression机制,注意力损失机制;步骤3,对数据集内的句子进行分词、制作词表、词嵌入操作;所述数据集包括训练集、验证集、预测集;步骤4,利用训练集来训练模型,利用验证集来检测当前训练的模型是否已经过拟合,如果过拟合,则停止训练;否则继续训练;步骤5,用训练好的模型对预测集进行解码,生成问题。进一步的,步骤1构建训练集<文章,答案,问题>、验证集<文章,答案,问题>、预测集<文章,答案>,具体方法为:模型所需的数据集,每个样本包含<文章,答案,问题>三个主要元素,其中答案是文章中的某一连续片段,将数据集按照80%,10%,10%的比例划分为训练集,验证集,预测集。进一步的,步骤2利用深度学习框架tensorflow搭建基于编码器-解码器的序列到序列神经网络模型,模型包含注意力机制,pointer-generatornetwork,answer-supression机制,注意力损失机制,具体方法为:(1)基于注意力机制的编码器-解码器结构:该网络结构中存在两个编码器,并且均是基于双向lstm神经网络,分别是处理文章的文章编码器,和处理答案的答案编码器,文章编码器的输入为经过分词和词嵌入后的文章,将文章分词后得到的第i个词xi作为文章编码器第i步的输入,其双向lstm在第i步会产生两个方向相反的隐藏层状态上式中的是正向在第i步的隐藏层状态,是反向在第i步的隐藏层状态,我们在每一步中连接正反反向的隐藏层状态基于双向lstm神经网络的文章编码器在首尾两端分别能得到隐藏层状态h1,h|x|,其中|x|代指文章编码器的步长。其答案编码器也是基于双向lstm结构,输入为经过分词和词嵌入后的答案,将输入定义为xanswer,则:上式中的是答案编码器中正向lstm第i步的隐藏层状态,是答案编码器中反向lstm第i步的隐藏层状态,同样的,在其首尾两端也能分别得到隐藏层状态answer1,将其连接起来,则:其中,式中的|xanswer|表示答案编码器的步长。我们将ans_emb_output与文章编码器中得到的h1、h|x|连接起来,作为解码器隐藏层初始状态s0:c=[h|x|:h1:ans_emb_output]h=[h|x|:h1:ans_emb_output]s0=lstmstatetuple(c,h).上式中c,h分别表示lstmcell中的长时记忆状态,短时记忆状态。解码器是一个单层单向的lstm网络:st=lstm(yt-1,st-1)上式中的st是指解码器在第t步解码时的隐藏层状态,yt-1是指第t步的解码器的输入(在训练阶段,为第t-1步的目标词,在预测阶段,为第t-1步的模型生成词)。(2)注意力机制:在解码器每一步解码时,都会得到在文章编码器输入文本上的一个概率分布,假设在第t步解码,可以得到概率分布at:上式中的v,wh,ws,wa和battn是模型需要学习的参数,得到的at是文章编码器的输入文本上的一个概率分布,以下我们记该概率分布为文章注意力分布。由上式可知,其注意力分布由文章编码器隐藏层状态hi,解码器隐藏层状态st,答案信息ans_emb_output共同决定。每一个词都对应一个概率值可以理解该词所获取的注意力权重,我们将该词对应的隐藏层状态hi与相乘,并且求和,得到上下文向量,记做将上下文向量与当前步的解码器隐藏层状态st连接起来,再做两层的线性变换:上式中的v′、v、b、b′都是模型需要学习的参数,我们由上面的计算过程可知,pvocab为预设词表上的概率分布。(3)pointer-generatornetwork该机制可以提高生成词的准确度,通过直接利用文章编码器输入文本中有用信息,有效的处理oov问题。最后得到的每个词的概率值不仅仅取决于上面的计算得出的pvocab,而且也与文章注意力分布at有着密切的关系。定义变量pgen∈[0,1],在解码器解码时,假设在第t步解码,该变量可由上下文向量解码器隐藏层状态st和解码器输入yt计算得出:上式中的bptr表示模型需要学习的参数,σ表示sigmoid函数。显然,得出的pgen在0,1之间,则pgen可以作为一个软阈值,用来选择当前步生成的词是来自于预设词表,还是根据文章注意力分布at从文章编码器的输入文本中采样得到。当要生成的词不在预设词表里,而出现在文章编码器的输入文本里时,该机制会使模型有机会直接从文章编码器的输入文本中取词,从而部分缓解了oov问题。上式中,w表示当前步要生成的词,当该词不在预设词表内,则pvocab(w)=0,故该词只能从文章编码器的输入文本去取,反之,如若该词出现在预设词表中,而不在文章编码器输入文本内,则则该词只能从词表中去取。p(w)表示词w最终的概率,由此我们可知,在每一步解码时最终的词表是由预设词表和当前步的文章编码器的输入文本并集得到的,以下我们记这个最终词表为扩展词表,并且在该扩展词表上会得到一个最终的概率分布p。(4)answer-supression机制(定义损失函数)由上面的描述,可知在每一步解码时,都会在扩展词表上得到一个概率分布p,在模型的训练阶段,假设在第t步时,我们希望目标词在扩展词表上的概率越大越好:也就是希望其负的对数似然值越小越好,每一步都会有一个损失函数值,我们将编码器所有步的损失函数值加起来,取平均作为最终需要优化的损失函数:假设模型生成的问题中包含答案中出现的词,则生成的问题质量可能较低,我们应当避免该类情况发生,故修改损失函数:上式中表示解码器在第t步解码时,答案中的某个词,表示在扩展词表中最终的概率值。λ是需要人工调优的超参数。可以理解为惩罚项。该惩罚项用来避免模型生成那些在答案中出现的词。(5)注意力损失机制这是训练阶段的一个技巧,用来指导模型在执行注意力机制时,应该更关注到文章的哪一部分,哪一部分的词应该获得更高的关注值。当当前的目标词(当前解码应该生成的词),出现在文章中,则该词应该获取的更高关注程度,以使模型更有可能生成该目标词。假设在第t步解码时,其目标词在文章中出现,记该词为w,则w应该获取更多的关注,所以:在上式中,wpassage代表文章词集合,代表词w所获取的关注值,λa是一个超参数,需要人工手动调优。如当前步的目标词w出现在文章中,并且所获取的关注值则其注意力损失值等于其余情况皆为0。将该注意力损失值加入到损失函数中得:fina_loss=loss+γ*attention_loss上式中γ是一个需要人工手动调优的超参数,由此我们得到了模型最终损失函数的计算方法。注意力损失机制只能在模型训练阶段使用。进一步的,步骤3对数据集内的句子进行分词、制作词表、词嵌入操作,具体为:(1)利用stanfordcorenlp工具包对数据集内的句子进行分词,统计每个词出现的频率,选取出现频率最高的k(k可以自定义设置大小)个词,作为预设的词表,以下记该词表为预设词表。(2)将每个词表示成独热编码,其编码长度为预设词表的大小,记大小为vocab_size,假设在模型训练时,每次从训练集中随机选取batch_size个样本供模型训练,则该批训练样本的形状为[batch_size,vocab_size],将该批训练样本记做矩阵x,词嵌入需要定义参数w形状如[vocab_size,emb_size],词嵌入即x矩阵乘以w矩阵,将得到的结果输入给模型,w矩阵为模型需要学习的参数。进一步的,步骤4训练集在训练模型时,利用验证集来检测当前训练的模型是否已经过拟合,如果过拟合,则停止训练,否则继续训练,具体为:每次从训练集中随机抽取batch_size个样本,来训练模型,我们记这样一次的训练过程为一个train_step,当训练集中的所有训练样本都被抽取训练过,记这样一个过程为一个epoch,当一个epoch训练完毕,接着第二个epoch训练,依次不断循环,因此可能会发生过拟合的情况,每次达到50个train_step时,则将当前训练好的模型,保存下来,将验证集中的样本输入到模型中进行预测,可计算得到损失值,画出损失值的变化曲线,一旦该曲线越过了最低点,则表明当前模型训练可能发生过拟合了,应当停止训练。进一步的,步骤5用训练好的模型对预测集进行解码,生成问题,具体为:在模型训练过程中,我们会得到多个模型,选择在验证集上损失值最低的模型作为训练得到的最优模型,将预测集输入给最优模型,进行解码,解码器每一步解码时,都会得到在扩展词表上的概率分布,利用beamsearch方式从该分布中抽样得到一个词,作为该步所生成的词,这样在解码完成后就会得到连续多个词,连在一起就是完整的句子,这就是所要生成的问题。下面结合实施例对本发明进行详细说明。实施例一种基于深度学习的问题自动生成方法,包括如下步骤:步骤1:构建训练集<文章,答案,问题>、验证集<文章,答案,问题>、预测集<文章,答案>,注意答案是文章中某一连续片段:将数据集按80%,10%,10%比例划分训练集,验证集,预测集。步骤2:利用深度学习框架tensorflow搭建基于编码器-解码器的序列到序列的神经网络模型,其模型包含有注意力机制,pointer-generatornetwork,answer-supression机制,注意力损失机制:(1)基于注意力机制编码器-解码器结构:该神经网络模型中有文章编码器和答案编码器,且编码器都是基于双向lstm神经网络,将经过分词和词嵌入后的文章和答案分别输入到文章编码器,答案编码器:式中表示正向lstm神经网络,表示反向lstm神经网络,表示正向网络的第i步隐藏层状态,表示反向神经网络第i步隐藏层状态。将编码器中每一步的正向反向隐藏层状态连接起来得:基于双向lstm神经网络的文章编码器在首尾两端分别能得到隐藏层状态h|x|,h1,|x|表示文章编码器步长。同理,将经过分词和词嵌入后的答案输入到答案编码器,然后再做和文章编码器同样的处理,则在其首尾两端也能分别得到隐藏层状态answer1,将其连接起来,则:其中,式中的|xanswer|表示答案编码器的步长。解码器是基于一个单层单向的lstm神经网络,其初始隐藏层状态s0:c=[h|x|:h1:ans_emb_output]h=[h|x|:h1:ans_emb_output]s0=lstmstatetuple(c,h).上式中c,h分别表示lstmcell中的长时记忆状态,短时记忆状态。(2)注意力机制:其中,上式中wh、ws、wa、vt和battn都是模型需要学习的参数,hi表示文章编码器在第i步的隐藏层状态,st表示解码器在第t步的隐藏层状态。上式中,v′,v,b,b′是模型需要学习的参数,表示在第t步解码时得到的上下文向量,得到的pvocab表示在预设词表上的概率分布。(3)pointer-generatornetwork上式中bptr表示模型需要学习的参数,其中表示在第t步解码时得到的上下文向量,st表示解码器在第t步得到的隐藏层状态,yt表示解码器在第t步的输入,σ表示sigmoid函数,由此上式得到的pgen数值介于0,1之间。上式中表示文章编码器中第i个输入词wi在解码器第t步执行注意力机制时所获取的关注值。得到的p(w)表示词w在扩展词表上最终的概率值。(4)answer-supression机制(定义损失函数)上式中表示解码器在第t步的目标词,表示该目标词在扩展词表中最终的概率值,losst表示解码器在第t步的损失值。将解码器所有步的损失值求和取平均作为损失函数。上式中表示出现在答案中的某个词,表示该词在扩展词表中的最终概率值,如不在扩展词表中则为0。λ表示需要人工调优的超参数。(5)注意力损失机制上式中表示词w在解码器第t步解码时获取的关注值,wpassage表示文章词集合,λa表示需要人工调优的超参数。只有当当前步目标词出现在文章中,且该目标词所获取的关注值小于λa时,才会产生注意力损失。final_loss=loss+γ*attention_loss修改损失函数,得到最终的损失函数,γ表示需要人工调优的超参数。步骤3:对数据集(包括训练集、验证集、预测集)内的句子进行分词、制作词表、词嵌入操作:利用stanfordcorenlp工具包对数据集中的句子进行分词,并且得到预设词表,对每个词进行独热编码,其编码长度为预设词表内词的个数,记预设词表词个数为vocab_size,对于batch_size个样本作为一批待训练样本,其形状为[batch_size,vocab_size],记为x矩阵,词嵌入需要定义一个矩阵w,其形状为[vocab_size,emb_size],将矩阵x乘以矩阵w,所得到的结果作为模型的输入,w矩阵是模型在训练时需要学习的参数。步骤4:利用训练集来训练模型,利用验证集来检测当前训练的模型是否已经过拟合,如果过拟合,则停止训练,否则继续训练:每次从训练集中随机抽取一批样本,供模型进行训练,称这样一个过程为一个train_step,每训练50个train_step时,保存当前训练好的模型,输入验证集,计算当前模型在验证集上的损失值,并画出损失值的变化曲线,当越过最低点时,说明模型已发生过拟合,则应当停止训练。步骤5:用训练好的模型对预测集进行解码,生成问题:(1)将预测集中经过分词和词嵌入后的文章和答案输入到训练好的模型中,进行预测,生成与文章和答案匹配的问题。(2)输出生成的问题。实施例2结合图1、图2,下面详细说明本发明的实施过程,步骤如下:步骤1:构建训练集<文章,答案,问题>、验证集<文章,答案,问题>、预测集<文章,答案>,注意答案是文章的某一连续片段:在本发明实验中我们使用squad,dureader两份公开数据集,并且均按照80%,10%,10%比例划分出训练集,验证集,预测集,其划分后的具体情况如表1:表1:squad,dureader数据集划分情况数据集文章-答案对数量(squad)文章-答案对数量(dureader)训练集7434533780验证集92934218预测集95344225步骤2:利用深度学习框架tensorflow搭建基于编码器-解码器的序列到序列的神经网络模型,其模型包含有注意力机制,pointer-generatornetwork,answer-supression机制,注意力损失机制,详细的神经网络模型如图1所示。(1)基于注意力机制编码器-解码器结构:文章编码器和答案编码器均是基于双向lstm神经网络:式中表示正向lstm神经网络,表示反向lstm神经网络,表示正向lstm网络的第i步隐藏层状态,表示反向lstm神经网络第i步隐藏层状态。解码器是基于单层单向的lstm神经网络:st=lstm(yt-1,st-1)上式中的st是指解码器在第t步解码时的隐藏层状态,yt-1是指第t步的解码器的输入(在训练阶段,为第t-1步的目标词,在预测阶段,为第t-1步的模型生成词)。其中无论是双向lstm还是单向lstm,在本发明实验中,其隐藏层神经元个数均设置为256,其中文章编码器和答案编码器步长分别视文章和答案长度而定,而解码器步长设置为50。(2)注意力机制:上式中wh、ws、wa、vt和battn都是模型需要学习的参数,其中参数wh、ws、wa、vt均是以一个均匀分布来进行初始化,而参数battn则是以初始常数为0.0初始化。上式中v′,v,b,b′均是模型需要学习的参数,均是以一个标准差为1e-4的截断正态分布来进行初始化。(3)pointer-generatornetwork上式中bptr表示模型需要学习的参数,其中参数是以一个均匀分布来进行初始化的,bptr是以常数0.0初始化的。表示在解码器第t步解码时得到的上下文向量,st表示解码器在第t步得到的隐藏层状态,yt表示解码器在第t步的输入,σ表示sigmoid函数,由此上式得到的pgen数值介于0,1之间。上式中表示预设词表中第i个词wi,在解码器第t步执行注意力机制时所获取的关注值。得到的p(w)表示词w在扩展词表上最终的概率值。(4)answer-supression机制(定义损失函数)上式中表示解码器在第t步的目标词,表示该目标词在扩展词表中最终的概率值,losst表示解码器在第t步的损失值。将解码器所有步的损失值求和取平均作为损失函数。上式中表示出现在答案中的词,表示该词在扩展词表中的最终概率值,如不在扩展词表中则为0。λ表示需要人工调优的超参数,在本发明实验中,对于该超参数我们尝试了0.001,0.005,0.01,0.05,0.1,0.2,发现当λ=0.01表现最优,于是设置λ为0.01。(5)注意力损失机制上式中表示词w在解码器第t步解码时获取的关注值,wpassage表示文章中词集合,λa表示需要人工调优的超参数,对于该超参数,在本发明实验中我们尝试了0.6,0.7,0.75,0.8,0.85,0.9,发现当λa=0.85时表现最优,于是设置λa为0.85。只有当当前步目标词出现在文章中,且该目标词所获取的关注值小于λa时,才会产生注意力损失。final_loss=loss+γ*attention_loss修改损失函数,得到最终的损失函数,其中γ表示需要人工调优的超参数,在本发明实验中,尝试了γ=0.01,0.05,0.1,0.15,0.2,发现当γ=0.05时表现最优。步骤3:对数据集(包括训练集、验证集、预测集)内的句子进行分词、制作词表、词嵌入操作:利用stanfordcorenlp工具包对数据集中的句子进行分词,并且得到预设词表,本实验中设置预设词表大小为20000,即vocab_size=20000,对每个词进行独热编码,其编码长度为预设词表的大小,每次选取batch_size个样本作为一批待训练样本,在本发明实验中设置batch_size=16,即每次从训练集中随机选取16个样本进行训练,则其形状为[batch_size,vocab_size],词嵌入需要定义一个矩阵w,其形状为[vocab_size,emb_size],在本实验中,我们设置emb_size=128,将矩阵x乘以矩阵w,所得到的结果作为模型的输入,w矩阵是模型在训练时需要学习的参数。步骤4:利用训练集来训练模型,利用验证集来检测当前训练的模型是否已经过拟合,如果过拟合,则停止训练,否则继续训练:每次从训练集中随机抽取一批样本,供模型进行训练,称这样一个过程为一个train_step,在本实验中,我们设置每训练50个train_step时,则保存当前训练好的模型,并且计算当前模型在验证集上的损失值,画出损失值的变化曲线,当越过最低点时,说明模型已发生过拟合,则应当停止训练。步骤5:用训练好的模型对预测集进行解码,生成问题:(1)在模型训练过程中,我们会得到多个模型,选择在验证集上损失值最低的模型作为模型训练得到的最优模型,将预测集输入给最优模型,进行解码,解码器每一步解码时,都会得到在扩展词表上的概率分布,利用beamsearch方式从该分布中采样得到一个词,作为该步所生成的词,这样在解码完成后就会得到连续多个词,连在一起就是一个完整的句子,这就是所要生成的问题,在本实验中,我们设置beamsize=4。(2)输出生成的问题。本实验使用了squad,dureader两份公开的问答数据集,提取了每个样本内的<文章,答案,问题>三个主要元素,作为本发明实验的数据集。本次实验在ubuntu16.04系统下进行,使用了stanfordcorenlp工具包和深度学习框架tensorflow1.20。本发明采用公开的问答数据集来检验模型的问题生成效果。为测试本发明算法的性能,将提出的基于深度学习的问题自动生成方法与传统的基于规则的问题生成方法[michaelheilmanandnoaha.smith.2010.goodquestion!statisticalrankingforquestiongeneration.inhumanlanguagetechnologies:the2010annualconferenceofthenorthamericanchapteroftheassociationforcomputationallinguistics.associationforcomputationallinguistics,losangeles,california,pages609–617]在预测集上进行对比,对比指标包括blue1,rouge指标等。表2:基于深度学习的问题生成模型和基于规则的问题生成模型对比表2为基于深度学习的问题生成模型和基于规则的问题生成模型在squad,dureader上的表现情况,可以看出在各项指标上,基于深度学习在效果都大幅领先于基于规则的效果,其中最大领先幅度达到8.11,最小领先幅度也有3.43。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1