一种基于生成式对抗网络的安检违禁品X光图像生成方法与流程
本发明属于数据增强技术领域,特别是涉及一种基于生成式对抗网络的安检违禁品x光图像生成方法。
背景技术:
行李安检对于民航安全有着至关重要的作用,然而,随着选择民航出行的旅客人数逐年上涨,行李安检员面临着越来越大的工作压力,这既降低了行李安检的效率和准确性,同时也不利于安检员的身心健康。近年来,随着卷积神经网络等深度学习算法的快速发展,使用计算机辅助安检员进行行李违禁品识别不再遥不可及。
使用深度学习方法进行图像识别首先需要有足够大的训练数据集,然而在实际中难以获取到大量的行李物品x光图像。此外,物品被随机放置在行李包裹中,在x光下呈现出的姿态也是多种多样的。与人脑不同的是,计算机算法在学习图像特征时,对物品姿态的变化十分敏感,所以行李安检员培训用的安检物品x光图像库并不能满足训练神经网络的需求。如何获取到大量的具有多种姿态的物品x光图像一直是一个难点问题。传统的解决方法是通过平移旋转尺度变换等操作来丰富图像,但这种方法所能获取到的额外信息量有限。使用预先训练好的网络模型虽然也能在一定程度上提升算法性能,但是并不是所有的网络模型都有预先训练好的模型可供使用。
2014年提出的生成式对抗网络(gan)被广泛用于生成新的数据,并且在图像生成方面取得重大突破。例如,pggan可以生成逼真的高分辨率人脸图像,sngan能够有效生成多类别的图像。相较于传统方法,使用生成式对抗网络生成新的安检违禁品x光图像可以更加有效地扩充数据集,从而有助于进一步提升违禁品检测算法的性能。但目前并没有完善的基于生成式对抗网络的图像数据集扩充方法。
技术实现要素:
为了解决上述问题,本发明的目的在于提出一种基于生成式对抗网络的安检违禁品x光图像生成方法。
为了达到上述目的,本发明提供的基于生成式对抗网络的安检违禁品x光图像生成方法包括按顺序进行的下列步骤:
1)根据原始安检违禁品x光图像中安检违禁品的姿态差异对原始安检违禁品x光图像进行分类;
2)构建生成式对抗网络并调整网络参数;
3)将步骤1)中已分类的原始安检违禁品x光图像输入上述生成式对抗网络中,分类别生成新安检违禁品x光图像;
4)构建用于评价生成的新安检违禁品x光图像是否可用的cnn图像分类模型;
5)基于上述构建的cnn图像分类模型对生成的新安检违禁品x光图像进行分类验证。
在步骤1)中,所述的根据原始安检违禁品x光图像中安检违禁品的姿态差异对原始安检违禁品x光图像进行分类的方法是:首先以原始安检违禁品x光图像中的安检违禁品几何中心为原点构建一个空间直角坐标系,则安检违禁品姿态的差异可以转换为其绕三个坐标轴旋转角度的差异;然后根据原始安检违禁品x光图像中违禁品绕三个坐标轴旋转角度的差异进行分类,将原始安检违禁品x光图像分为8个姿态类别。
在步骤2)中,所述的构建生成式对抗网络并调整网络参数的方法是:首先构建一个由判别器和生成器组成的生成式对抗网络,并选取合适的损失函数,然后设置不同的网络参数进行实验,根据实验结果选取最优的参数设置。
在步骤3)中,所述的将步骤1)中已分类的原始安检违禁品x光图像输入上述生成式对抗网络中,分类别生成新安检违禁品x光图像的方法是:首先根据每一类原始安检违禁品x光图像的数量设置一个合适的训练样本数量n,然后使用步骤2)构建的生成式对抗网络生成新的安检违禁品x光图像,所生成的这张图像由n张新安检违禁品x光图像拼接而成,最后将其拆分成n张单独的新安检违禁品x光图像。
在步骤4)中,所述的构建用于评价生成的新安检违禁品x光图像是否可用的cnn图像分类模型的方法是:首先构建一个由3个卷积层、3个池化层和3个全连接层组成的cnn图像分类模型,并在最后加入softmax层,然后使用原始安检违禁品x光图像训练该模型,直至得到较高的分类准确率时结束训练。
在步骤5)中,所述的基于上述构建的cnn图像分类模型对生成的新安检违禁品x光图像进行分类验证的方法是:首先将新安检违禁品x光图像依次输入步骤4)构建的cnn图像分类模型中进行分类验证,得到一个输出结果;如果该结果对应正确的安检违禁品类别,且该结果数值大于0.5,则认为这张新安检违禁品x光图像具有较好的质量,可以用于扩充安检违禁品x光图像数据集;若不同时满足上述两个条件,则删除这张新安检违禁品x光图像。
本发明提供的基于生成式对抗网络的安检违禁品x光图像生成方法能够在少量图像样本的基础上,生成大量视觉效果逼真的、具有多种姿态的新图像,可以有效扩充安检违禁品x光图像数据集。
附图说明
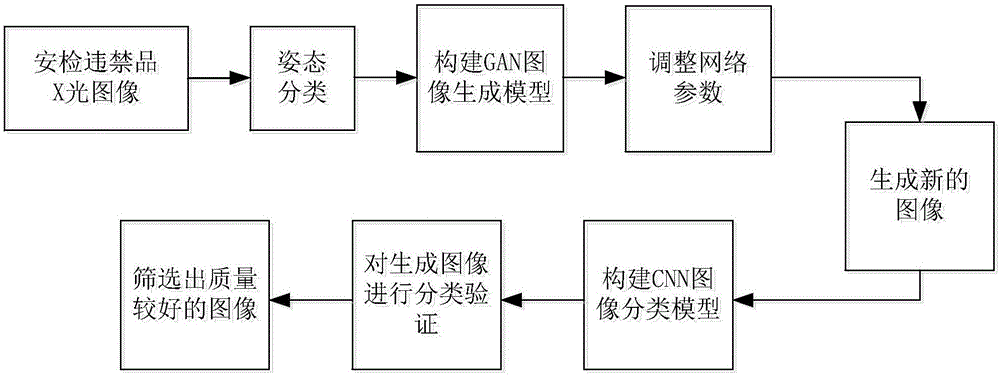
图1为本发明提供的基于生成式对抗网络的安检违禁品x光图像生成方法流程图。
图2为构建以安检违禁品几何中心为原点的空间直角坐标系。
图3为安检违禁品姿态详细分类示意图。
图4为gan框架。
图5为gan中判别器网络结构。
图6为gan中生成器网络结构。
图7为cnn图像分类模型框架。
图8为生成的不同姿态的手枪图像。
图9为生成的不同类别的违禁品图像。
具体实施方式
下面结合附图和具体实施例对本发明提供的基于生成式对抗网络的安检违禁品x光图像生成方法进行详细说明。
如图1所示,本发明提供的基于生成式对抗网络的安检违禁品x光图像生成方法包括按顺序进行的下列步骤:
1)根据原始安检违禁品x光图像中安检违禁品的姿态差异对原始安检违禁品x光图像进行分类;
由于原始安检违禁品x光图像数量有限,且该图像中的目标姿态差异很大,例如一把手枪从不同角度去看,它的外观形状也是不同的。如果直接将所有原始安检违禁品x光图像放入网络中进行训练,网络将难以学习到这些图像的共同特征,生成的新安检违禁品x光图像往往具有难以辨认的目标形状,因此这种新安检违禁品x光图像并不能用来扩充安检违禁品x光图像数据集。
要进一步提高网络的学习效果,可以根据原始安检违禁品x光图像中目标姿态的差异先对该图像进行分类,在此基础上依次放入网络中进行训练。此方法可以通过减小训练图像的内容差异来降低网络学习的难度。
如图2所示,由于手枪在不同视角下对应的姿态差异很大,本发明以原始手枪x光图像为例进行说明。具体分类方法如下:首先,将手枪的几何中心作为原点构建一个空间直角坐标系,枪口所指方向为x轴正方向,握把方向为y轴正方向,垂直于手枪向上方向为z轴正方向。将当前手枪在空间直角坐标系中的位置设定为标准位置,当手枪绕三个坐标轴进行旋转时,其在原始手枪x光图像中的姿态随即发生改变。因此,原始手枪x光图像中手枪姿态的差异可以看作是手枪在空间直角坐标系中绕三个坐标轴旋转的角度差异。手枪在原始手枪x光图像中的方向差异可以由手枪在空间直角坐标系中绕z轴旋转角度的不同来表示。同理,手枪在原始手枪x光图像中的倾斜角差异可以由手枪在空间直角坐标系中绕x轴和y轴旋转角度的不同来表示。原始手枪x光图像中手枪的任意姿态都可以按照上述旋转方法组合得到。
然后,根据手枪枪口方向的差异对其进行分类,主要分为向左和向右两类,对应于空间直角坐标系中的标准位置和镜像位置,如图3(a)所示。之后,根据手枪绕z轴旋转的角度差异分为4类:0°±45°,90°±45°,180°±45°和-90°±45°,如图3(b)所示。x光图像中安检违禁品由于方向不同所导致的外形差异是最主要的差异。最后,根据手枪绕x轴和y轴旋转的角度差异可分别进一步细分为4类:0°~45°,-45°~0°,45°~90°,-90°~-45°,如图3(c)所示。将原始安检违禁品x光图像按照上述方法进行分类,可使每一类x光图像中的安检违禁品姿态差异显著减小。在本发明中,考虑到已获取的原始安检违禁品x光图像数量有限,对每类原始安检违禁品x光图像主要进行了前两种分类:标准、镜像位置以及方向。
2)构建生成式对抗网络并调整网络参数;
生成式对抗网络(generativeadversarialnetwork,gan)由生成器(generator,g)和判别器(discriminator,d)两部分组成。生成器通过学习真实数据的分布来生成假的数据样本,判别器的作用是判断一个输入样本是真实数据还是生成数据。整个网络的学习过程如图4所示,生成器要生成尽可能逼真的假图像,判别器则要尽可能区分出真实图像和假图像。二者同时训练和优化,直至最后判别器无法有效区分真假图像,即认为生成器生成了和真实图像一样的假图像。
判别器的基本结构是一个卷积神经网络(convolutionalneuralnetwork,cnn),如图5所示。其包含4个步长为2的卷积层和1个全连接层,卷积核数量分别为32,64,128和256,卷积核大小为5×5和3×3。除了最后一层,每一层采用lrelu激活函数,最后一层采用tanh激活函数。生成器的基本结构为一个逆向的卷积神经网络,如图6所示,共包含1个全连接层和5个步长为2的卷积层,卷积核数量分别为512,256,128,64和32,卷积核大小为3×3和5×5,每一层均采用relu激活函数。
生成器和判别器的训练和优化是通过最小化损失函数实现的,损失函数的选择对生成式对抗网络整体性能有着重要影响。本发明采用了ct-gan的损失函数,并对其进行了简化改进,如式(1)所示:
l(d,g)=d(g(z))-d(x)+λ1gp+λ2ct(1)
其中,l为损失值,d为判别器,g为生成器;z为生成器输入的随机噪声,g(z)为生成的假数据,x为真实的数据,d(g(z))为判别器输入假数据时对应的输出结果,d(x)为判别器输入真实数据时对应的输出结果;gp和ct分别为梯度惩罚项及一致性正则化项,如式(2)、(3)所示,λ1和λ2为分别梯度惩罚项gp和一致性正则化项ct对应的权重系数。
其中,x'为介于真实数据x和生成的假数据g(z)之间的随机采样。
ct=ex[max(0,d(d(x1),d(x2))-m)](3)
其中,x1和x2为真实的数据分布,m为常量。
完成生成式对抗网络的构建之后,需要进一步对网络参数进行调整,使生成式对抗网络在安检违禁品x光图像数据集上学习效果达到最佳。
生成式对抗网络的网络参数主要分为两种,一种是由网络随机产生一个初始值,之后通过循环迭代来不断更新,另一种是超参数,这种参数需要人为设定。对于超参数的设定仅仅依靠经验还不够,还需要考虑到实际中的数据集规模、图像大小以及网络层数等内容。本发明对超参数的取值进行了多次实验,并通过比较生成图像的质量差异来确定最佳的超参数值。这些超参数具体包括:网络学习率、迭代次数、损失函数的权重系数λ1和λ2、生成器和判别器的训练频率。当生成图像的质量效果最佳时,对应的超参数取值分别为:网络学习率0.0002,迭代次数2000次,损失函数的权重系数λ1和λ2分别取0.5和5,生成器每训练1次,判别器也同时训练1次。
在完成生成式对抗网络构建、损失函数选择以及网络参数调整之后,即可使用生成式对抗网络在分类完的数据集上训练网络,生成新安检违禁品x光图像。
3)将步骤1)中已分类的原始安检违禁品x光图像输入上述生成式对抗网络中,分类别生成新安检违禁品x光图像;
在本发明中,生成器的输入为一个n×128的噪声向量,服从标准正态分布,n为同时参与生成式对抗网络训练的样本数量。相较于将所有图像同时放入网络进行训练,选择其中的一部分图像参与训练,可以减少运算所需时间和内存;相较于一次训练一张图像,多张图像同时训练则可以加快网络收敛速度。样本数量n的取值依据用于训练的每一类原始安检违禁品x光图像的总数而定。生成器的输出为一张由n张新安检违禁品x光图像拼接成的大图像。
将上述大图像拆分成单独的新安检违禁品x光图像。由于生成式对抗网络在训练过程中具有不稳定性,因此生成的新安检违禁品x光图像中存在少量视觉质量较差的图像。此外,有一些新安检违禁品x光图像虽然能被人眼辨认出是什么物品,但是并不一定能被神经网络准确识别和分类。这两种图像是无法用于安检违禁品x光图像数据集扩充的。因此,在完成新安检违禁品x光图像生成之后,需要做进一步的图像筛选,确保最后留下的图像都具有较好的视觉质量。
4)构建用于评价生成的新安检违禁品x光图像是否可用的cnn图像分类模型;
步骤3)生成的新安检违禁品x光图像的质量评价问题可以转换为能否准确被cnn图像分类模型分类的问题。首先构建一个cnn图像分类模型,并用真实拍摄得到的原始安检违禁品x光图像训练该模型。当cnn图像分类模型能够准确分类原始安检违禁品x光图像后,放入新安检违禁品x光图像,验证其能否被cnn图像分类模型分入正确类别。如果一张新安检违禁品x光图像对应的cnn图像分类模型匹配结果是正确的安检违禁品类别,则可保留;如果对应的cnn图像分类模型匹配结果是其他错误的安检违禁品类别,则认为这张新安检违禁品x光生成图像质量效果较差,需要删除掉。经过cnn图像分类模型筛选之后留下的新安检违禁品x光图像才可以用以扩充安检违禁品x光图像数据集。
目前有很多具有高分类准确率的cnn图像分类模型,由于本发明中涉及到的原始安检违禁品x光图像总数较少,采用过于复杂的cnn图像分类模型进行图像分类容易导致过拟合,如vgg、resnet及googlenet。本发明构建了一个简易的cnn图像分类模型,如图7所示,包含3个卷积层、3个池化层和3个全连接层,最后添加了softmax层。softmax层的作用是将最后cnn图像分类模型输出的结果转换成一个概率值,对应每个类别的概率值之和为1,这样可以更加直观地了解cnn图像分类模型匹配结果,公式如式(4)所示:
x为输入,y为输出。每个卷积层的卷积核数量分别为32,64及128,卷积核大小分别为5×5和3×3,全连接层的神经元数量分别为1024,256及6。批量大小为64,用真实拍摄得到的原始安检违禁品x光图像训练cnn图像分类模型,训练次数为25轮。
首先使用真实拍摄的原始安检违禁品x光图像训练cnn图像分类模型,将所有原始安检违禁品x光图像的70%作为训练集,30%作为测试集。当cnn图像分类模型在两个数据集上都能取得较高的分类准确率时,即可认为该模型可以识别出一张步骤3)生成的新安检违禁品x光图像属于哪个违禁品类别。
5)基于上述构建的cnn图像分类模型对生成的新安检违禁品x光图像进行分类验证;
将生成的新安检违禁品x光图像依次放入cnn图像分类模型中进行测试,验证cnn图像分类模型匹配结果是否正确,以及匹配结果对应的概率值是否大于0.5,必须满足这两个条件才认为新安检违禁品x光图像具有较好的质量。例如一张新手枪x光图像被cnn图像分类模型识别为刀具类别,或者即使被正确分为手枪类别,但对应的cnn图像分类模型的输出概率值小于0.5,则都认为这张新手枪x光图像的质量效果不符合要求,应删除这张图像。
所有新安检违禁品x光图像在经过cnn图像分类模型的分类验证后,保留下来的新安检违禁品x光图像具有较高的辨识度,可以用于安检违禁品x光图像数据集的扩充以及后续安检违禁品检测算法的训练。
本发明在实验中使用的原始安检违禁品x光图像全部是通过安检机采集得到的,安检机型号为“安天下th5030”。实验中共使用了由5种原始安检违禁品x光图像组成的5个数据集,分别为:手枪、打火机、水果刀、锤子和螺丝刀。由于原始安检违禁品x光图像中的安检违禁品姿态种类有限,本发明初步将其分为8个姿态类别,每类约150张图像,图像大小为96×96。所有实验在ubuntu16.04系统中进行,编程语言为python2.7,深度学习框架为tensorflow1.0。算法在gpu上运行,显卡型号为nvidia10603gb。
首先基于手枪数据集进行实验。每次随机选取64张原始手枪x光图像参与训练,即样本数量n的取值为64。生成的新手枪x光图像如图8所示,每一行对应一种姿态类别。从图中可以发现,绝大多数的新手枪x光图像都具有较为逼真的手枪形状,少部分新手枪x光图像中的手枪形状不符合实际,如:枪管弯曲、枪管前后粗细不同、形状不规则等。这些视觉质量差的新手枪x光图像需要在后续步骤中删除。
为了验证本发明中构建的生成式对抗网络在生成其它安检违禁品x光图像时的泛化能力,本发明再次基于打火机、水果刀等四类不同的原始安检违禁品x光图像组成的数据集进行了实验,参数不变,生成的新安检违禁品x光图像结果如图9所示。可以看到不同的安检违禁品种类都能生成具有较好视觉质量的新安检违禁品x光图像,但仍然是有少数的新安检违禁品x光图像具有不真实的物品形状。
在图像筛选实验中,原始安检x光图像训练数据集共包含六个类别,其中安检违禁品有手枪、水果刀、打火机、锤子、螺丝刀五类。除此之外,本发明还选取了一些与上述原始安检违禁品x光图像有着相似外形和颜色的原始安检x光正常物品图像,将其作为一个负样本类别。每类物品共有图像500张,图像大小为96×96。经过25轮训练,cnn图像分类模型在测试集上的分类准确率为95.31%。cnn图像分类模型训练完成之后,每类安检违禁品选取640张生成的新安检违禁品x光图像进行分类验证。将这五类新安检违禁品x光图像全部放入训练好的cnn图像分类模型中进行分类,保留下来(对应cnn图像分类模型匹配结果是正确的,且概率值大于0.5)的新安检违禁品x光图像数量见表1:
表1、安检违禁品x光图像分类验证实验结果
从表1可以看出,大部分新安检违禁品x光图像都可以被cnn图像分类模型正确识别和分类,这也说明大部分新安检违禁品x光图像都具有不错的视觉质量,可以用来扩充安检违禁品x光图像数据集。
最后,针对手枪等五种不同安检违禁品,本发明分别生成并筛选出了1万张具有不同姿态的新安检违禁品x光图像,初步构建成一个安检违禁品x光图像数据集。此外,使用本发明方法可以进一步生成更多类别更多姿态的新安检违禁品x光图像。
- 还没有人留言评论。精彩留言会获得点赞!