一种基于论坛用户言论的品牌亲密度计算方法与流程
本发明涉及计算机领域及市场营销理论,具体涉及机器学习领域,尤其涉及自然语言处理中的情感分析任务以及人群分类任务。
背景技术:
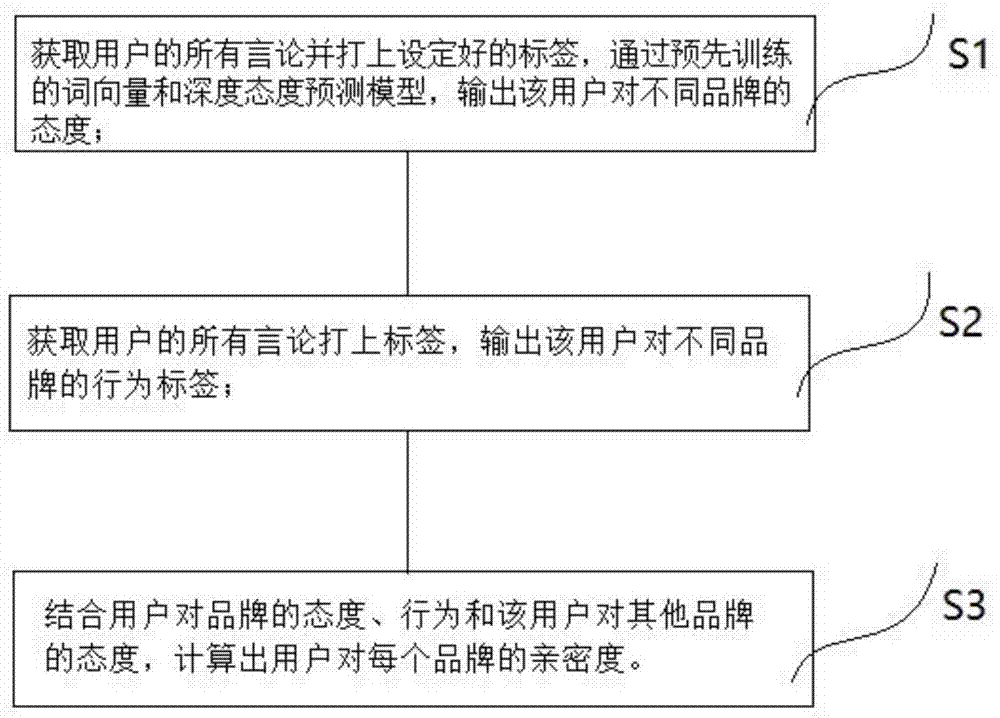
:近年来,社交网络发展迅速,越来越多的内容由网络用户自己产生,一些特定群体的用户通常会在一些特定论坛上讨论一些共同话题,这些特定的个性化信息中蕴含着大量用户的个人喜好和关注对象,通过这些言论数据可以帮助品牌更好的了解用户的需求和体验,可以帮助品牌提升、改善品牌形象,也有助于发现新的市场增长点,对于平台来说,也能帮助平台方理解用户行为,有助于合作精准投放。当前,传统的人群划分通常是根据一些用户的固有属性进行人群划分,例如利用用户的个人资料等静态信息进行人群划分,这种人群划分通常比较片面,而企业在做品牌市场研究的时候,除了以上固有信息外,用户的态度及行为动作也能直接反应用户对品牌的行为偏好,如果运用以上粗矿的人群划分方法,企业的研究结果只能是一个笼统的结果,并不能很精确地得出用户对品牌的亲密度,因此,现有技术中还缺少一种结合用户固有属性和用户的态度、行为以及用户对其他品牌的态度来判断用户对品牌亲密度的方法。技术实现要素:针对上述技术问题,本发明提供了一种基于论坛用户言论的品牌亲密度计算方法,包括以下步骤:步骤s1:获取用户的所有言论并打上设定好的标签,通过预先训练的词向量和深度态度预测模型,输出该用户对不同品牌的态度;步骤s2:获取用户的所有言论打上标签,输出该用户对不同品牌的行为标签;步骤s3:结合用户对品牌的态度、行为和该用户对其他品牌的态度,计算出用户对每个品牌的亲密度。进一步地,所述步骤s1还包括:s101:提取用户的所有言论,并从中找出涉及某个具体品牌的文本;s102:对所述文本进行分词获得词向量,再将所述词向量输入已经训练好的态度预测模型;s103:根据预设表格生成每个用户对每个实体的态度。进一步地,所述词向量是根据glove模型训练好的300维度词向量。进一步地,所述态度预测模型是双向lstm结构。进一步地,所述步骤s2还包括:s201:根据用户的言论,对实体打上行为的标签;s202:根据用户对这个品牌最近的一次言论的行为作为行为标准。进一步地,所述行为的标签包括正用、曾用、将用和仅提及,所述s202的行为标准为用户对这个品牌最近的一次言论的非仅提及行为,若用户对这个品牌没有非仅提及行为,则以最近一次仅提及行为作为行为准则。进一步地,所述步骤s3还包括:s301:根据从实际情况出发定制的记分规则,结合用户对每个实体的态度及行为,输出用户对每个品牌的亲密度得分;s302:考虑竞争环境,对得分进行调整;s303:按照行为优先的规则,对得分再进行调整,最终得到用户对每个品牌的亲密度得分。进一步地,根据步骤s3计算的品牌亲密度分值,将每个用户划分成品牌相对应的人群。进一步地,所述人群根据亲密度分值由低至高划分成流失用户、考虑用户、偏好用户以及忠诚用户。本发明取得的有益效果在于:首先,本发明的基于论坛用户言论的品牌亲密度计算方法是一种只基于文本分析的创新的市场人群分类方法,目前大部分的文本分析通常是针对句子或一段文本的,本发明则是基于一个用户的所有言论,并考虑到时间的先后顺序以及用户的态度变化;其次,目前应用交广的人群分类大部分都是通过人群的属性或者一些标签对人群进行分类,本发明则通过结合用户固有属性和用户的态度、行为以及用户对其他品牌的态度来对人群进行了精确划分,有助于企业更具体地观察市场品牌的竞争力和市场占有情况,并且能帮助企业根据不同的人群来进行更具有针对性的市场情况分析。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1是本发明一实施例的基于论坛用户言论的品牌亲密度计算方法的流程图;图2是本发明一实施例的态度输出流程图;图3是本发明一实施例的行为标签输出流程图。具体实施方式为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明,实施方式提及的内容并非对本发明的限定。如图1所示,本发明的一实施例中,使用本申请的基于论坛用户言论的品牌亲密度计算方法来预测某一母婴论坛的用户对各纸尿裤品牌的亲密度,步骤包括:s1:获取用户的所有言论并打上设定好的标签,通过预先训练的词向量和深度态度预测模型,输出该用户对不同品牌的态度;根据母婴论坛用户的id(user_id)获取用户的所有文本数据(content),每个文本有对应的id标记(id)和发言时间(created_at),再根据实际情况,对每条id记录打上实体(品牌)和方面(维度)的标签,如果一条文本数据只提及实体而未提及具体的方面,则方面的标签为null,下述表1是文本数据的实体和方面标签的具体例子,表中第一列记录文本数据的id标记,第二列记录用户的发言文本数据,第三列记录用户的id,第四列记录文本数据的实体标签,第五列记录文本数据的方面标签。[表1]文本数据的实体和方面标签表本实施例的态度预测过程中,对文本数据用jieba进行分词,加入自定义的词典,分词之后的词向量用的是利用母婴论坛文本根据glove模型训练出的词向量,输入的结构是双向lstm。根据表1打上的标签,将数据输入态度预测模型,模型根据训练的结果输出每条文本数据对应实体及方面的态度,下述表2是文本数据对应实体及方面的态度的具体例子,表中第一列记录文本数据的id标记,第二列记录用户的发言文本数据,第三列记录文本数据的实体标签,第四列记录文本数据的方面标签,第五列记录文本数据对应实体及方面的态度。[表2]文本数据对应实体及方面的态度表态度的输出类型有五种,分别是:正面:用户对实体和方面组合表达了明确的正向、肯定的态度;中性:用户对实体和方面组合表达了明确的中性、一般的态度;负面:用户对实体和方面组合表达了明确的负面、否定的态度;疑问:用户对实体和方面组合表达了疑问、不明确的态度;未提及:虽然用户的言论被实体和方面标记,但是用户并未对这个组合表达过态度。这五种态度分别表示了用户的言论中对实体的五种客观评价,这五种分类是结合业务总结出的结果,能比较好的帮助品牌研究用户行为以及帮助品牌研究自己的市场和行业状况。进一步地,由于每个用户对一个实体(品牌)都可能发表过多次言论,且每次提到的维度(方面)和态度都不相同,这个时候该用户对于这个实体(品牌)的态度会按照新的规则,即一个用户对一个实体(品牌)只有一个态度:排除掉未提及的文本,若该用户对该实体的态度只有正面和中性,则认为总体是正面;若该用户对该实体的态度只有负面和中性,则认为总体是负面;若该用户对该实体的态度只有中性,则认为总体是中性;其他的情况则认为总体是疑问,下述表3是根据以上规则所得到的用户001对各品牌的态度,表中第一列记录文本数据的id标记,第二列记录用户的id,第三列记录对应实体,第四列记录对应态度。[表3]用户001对各品牌态度结果iduser_id实体态度000001001品牌a正面000001001品牌b负面000002001品牌c中性000002001品牌d中性000003001品牌e疑问该步骤解决了多次表达态度而产生前后矛盾的问题,是对实际问题场景的建模。步骤s2:获取用户的所有言论打上标签,输出该用户对不同品牌的行为标签;再根据用户的文本数据进行行为的判断,主要是根据中文的正则表达式去给每一句言论打上实体和行为的标签,该步骤从句子粒度打标签而非文本段落粒度,有效提升标签的精确性;结合实体和行为打标签而非仅打上行为标签,可以有效识别行为的主体,下述表4是文本数据的实体和行为标签的具体例子,表中第一列记录文本数据的id标记,第二列记录用户的发言文本数据,第三列记录用户的id,第四列记录文本数据的实体标签,第五列记录文本数据的行为标签。[表4]文本数据的实体和行为标签表行为输出的类型有四种,分别为:在用:用户表达了正在使用实体;曾用:用户表达了曾经使用过实体;将用:用户表达了未来可能会选择使用实体:仅提及(null):无法判断用户对实体的行为。这四种行为对应了市场上用户人群对品牌的使用情况,能够比较准确的反应用户的使用状况。进一步地,由于每个用户对一个实体(品牌)可能发表过多次言论,且每次提到的行为都不相同,这个时候该用户对于这个实体(品牌)的行为会按照新的规则,即一个用户对一个实体(品牌)只有一个行为:根据用户对这个实体(品牌)最近的一次言论的非null行为作为行为标准,若用户对这个实体(品牌)无非null行为,则记为null,下述表5为用户001在不同发言时间对实体的行为表,表中第一列记录文本数据的id标记,第二列记录记录用户的id,第三列记录文本数据的实体标签,第四列记录发言时间,第五列记录文本数据的行为标签,下述表6是根据上述规则得到的用户001对各品牌的行为结果,表中第一列记录文本数据的id标记,第二列记录记录用户的id,第三列记录文本数据的实体标签,第五列记录文本数据的行为标签。[表5]用户001在不同发言时间对实体的行为表iduser_id实体created_at行为000001001品牌b2017-11-1null000002001品牌c2018-1-15在用000002001品牌d2018-1-15曾用000005001品牌a2017-11-20在用000006001品牌a2017-12-05曾用000006001品牌d2017-12-05在用000007001品牌e2017-12-26将用000007001品牌a2017-12-26曾用000008001品牌e2017-12-26null[表6]用户001对各品牌的行为结果iduser_id实体行为000006001品牌a曾用000002001品牌bnull000002001品牌c在用000006001品牌d曾用000007001品牌e将用步骤s3:结合用户对品牌的态度、行为和该用户对其他品牌的态度,计算出用户对每个品牌的亲密度。进一步地,根据从实际出发制定的规则,结合用户对每个品牌的具体结果输出亲密度的得分,具体的得分规则如下:s301:根据下述表7对用户对应的不同实体进行打分[表7]基于态度、行为的实体亲密度记分规则表下述表8是根据上述规则进行用户001对不同品牌亲密度的记分,表中第一列记录用户的id,第二列记录实体标签,第三列记录得分情况(score)。[表8]user_id实体score001品牌a1001品牌b1001品牌c3001品牌d1001品牌e3s302:考虑竞争环境,如果一个用户提及多个实体(品牌),各实体(品牌)得分为1或2的则记分不变,其余实体(品牌)排除掉非并列的最高分全部减一分,下述表9是根据上述规则重新进行的用户001对不同品牌亲密度的记分,表中第一列记录用户的id,第二列记录实体标签,第三列记录得分情况(score)。[表9]user_id实体score001品牌a1001品牌b1001品牌c2001品牌d1001品牌e2s303:按照行为优先的规则,凡是用户提及在用的,得分应至少都是3分以上,若低于3分则调整为3分,凡是用户提及将用的都是考虑,得分应为2分以下,若高于2分则调整为2分,下述表10是根据上述规则得到最终的用户001对不同品牌亲密度的记分,表中第一列记录用户的id,第二列记录实体标签,第三列记录得分情况(score)。[表10]user_id实体score001品牌a1001品牌b1001品牌c3001品牌d1001品牌e2进一步地,根据品牌亲密度的分值,将每个用户划分成品牌对应的四种人群中的一类,其中:score=1,是流失用户;score=2,是考虑用户;score=3,是偏好用户;score=4,是忠诚用户。目前大部分的文本分析通常是针对句子或一段文本的,而本实施例的方法则是基于一个用户的所有言论,并考虑到时间的先后顺序、态度变化,且目前应用交广的人群分类大部分都是通过人群的属性或者一些标签对人群进行分类,而本实施例的方法能够比较深入利用人群的言论信息,结合行业市场洞察方法,对人群进行分类。在本发明另一实施例中,本发明的步骤s1还包括:s101:提取用户的所有言论,并从中找出涉及某个具体品牌的文本;例如,一个用户在论坛的发言如下述表11所示,表中第一列文本数据的id,第二列记录用户的id,第三列文本数据(content)。[表11]对以上发言记录根据业务需求打上实体和方面的标签,下述表12是改用户相关文本数据的实体和方面标签,表中第一列记录文本数据的id,第二列记录文本数据,第三列记录文本数据的实体(品牌)标签,第四列记录文本数据的方面标签。[表12]idcontent实体方面0000003我家宝宝用的帮宝适的纸尿裤,好像有点过敏,帮宝适过敏0000004尤妮佳的纸尿裤怎么样尤妮佳null0000005不知道要不要用花王花王null0000006好奇我已经用了大半包,性价比高,好用。好奇性价比0000007我们家用的好奇好奇null0000010我家宝宝9个月就穿好奇家了,好用一直回购。好奇null0000011大王天使是用过最厚的,简直了,容易捂疹子。大王天使厚薄度s102:对所述文本进行分词获得词向量,再将所述词向量输入已经训练好的态度预测模型;对于这些文本数据(content)先分词,然后输入已经训练好的态度预测模型,其中词向量用的是训练好的300维的词向量,输出的态度预测结果。如下述表13所示,表中第一列记录文本数据的id,第二列记录文本数据的实体标签,第三列记录文本数据的方面标签,第四列记录文本数据的态度标签。[表13]id实体方面态度0000003帮宝适过敏负面0000004尤妮佳null疑问0000005花王null疑问0000006好奇性价比正面0000007好奇null未提及0000010好奇null正面0000011大王天使厚薄度负面s103:根据预设表格生成每个用户对每个实体的态度。根据业务实际情况,会出现用户对一个品牌发表过多次言论,且每次提到的方面和态度都不相同,这个时候该用户对于这个实体的态度的计算规则如图2所示:排除未提及的文本数据,将态度输出分为四种类型,最终生成用户对每个实体的态度,如下述表14所示,表中第一列记录用户的id,第二列记录文本数据的实体标签,第三列记录文本数据的态度标签。[表14]user_id实体态度001帮宝适负面001尤妮佳疑问001花王疑问001好奇正向001大王天使负面如图3所示,在本发明另一实施例中,本发明的步骤s2还包括:s201:根据用户的言论,对实体打上行为的标签;获取用户的言论数据,并根据文本数据(content)对实体打上行为标签,下述表15是用户对每个实体的行为标签,表中第一列记录文本数据的id标记,第二列记录用户的发言文本数据,第三列记录文本数据的实体标签,第五列记录文本数据的行为标签,第五列记录发言时间(created_at)。[表15]s202:根据用户对这个品牌最近的一次言论的行为作为行为标准。根据一个用户对一个实体(品牌)只有一个行为:以用户对一个实体(品牌)最近一次言论的非null行为作为行为标准,下述表16是根据上述规则生成的用户对每个实体的行为,表中第一列记录用户的id,第二列记录文本数据的实体标签,第三列记录文本数据的行为标签。[表16]user_id实体行为001帮宝适在用001好奇在用以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本
技术领域:
中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1