一种数据处理守护进程的数据分区配置方法、装置及设备与流程
本申请涉及分布式存储技术领域,特别涉及一种数据处理守护进程的数据分区配置方法、装置、设备及计算机可读存储介质。
背景技术:
随着虚拟化和云计算等技术在企业数据中心的大规模应用,分布式存储系统中的数据处理量和复杂度也不断增大。守护进程是一类在后台运行、并且不受任何终端控制的特殊进程,其中,数据处理守护进程是保障存储集群节点正常进行数据处理的关键服务。对于集群节点中的每一个数据处理守护进程,都需要预先为其配置好对应的日志分区和缓存分区。然而,现有技术中一般是由专业技术人员通过手动输入相关指令而实现对分区配置的,效率较低。鉴于此,提供一种解决上述问题的方法是本领域技术人员所亟需解决的。
技术实现要素:
本申请的目的在于提供一种数据处理守护进程的数据分区配置方法、装置、设备及计算机可读存储介质,以便有效地提高对集群节点中各个数据处理守护进程进行数据分区配置的效率和可靠性,并降低人力成本。
为解决上述技术问题,第一方面,本申请提供了一种数据处理守护进程的数据分区配置方法,应用于集群节点,包括:
确定本集群节点中数据处理守护进程的第一数量;
获取各个所述数据处理守护进程的进程标识号;
确定本集群节点中的可用磁盘;
将所述可用磁盘中第一数量个第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区,将所述可用磁盘中第一数量个第二子存储空间确定为与各个所述数据处理守护进程一一对应的缓存分区;
生成并运行各个所述数据处理守护进程的配置文件。
可选地,所述获取各个所述数据处理守护进程的标识号包括:
判断本集群节点是否为主节点;
若是,则接收各个集群节点发送的所述第一数量;向集群监控守护进程申请获取各个集群节点中各个数据处理守护进程的进程标识号,并发送至对应的集群节点;
若否,则将本集群节点的所述第一数量发送至主节点;接收所述主节点发送的进程标识号。
可选地,所述将所述可用磁盘中第一数量个第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区包括:将所述可用磁盘中第一数量个预设大小的所述第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区;
所述将所述可用磁盘中第一数量个第二子存储空间确定为与各个所述数据处理守护进程一一对应的缓存分区包括:将所述可用磁盘中的剩余空间划分为第一数量个所述第二子存储空间,以便作为与各个所述数据处理守护进程一一对应的缓存分区。
可选地,在所述确定本集群节点中的可用磁盘之后,还包括:
判断所述可用磁盘的第二数量是否大于零;
若是,则继续执行所述将所述可用磁盘中第一数量个预设大小的所述第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区的步骤;
若否,则生成报错提示信息。
可选地,在所述将所述可用磁盘中第一数量个预设大小的所述第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区之前,还包括:
确定第二数量个所述可用磁盘的总存储空间;
判断所述总存储空间是否大于第一数量个预设大小的所述第一子存储空间;
若是,则继续执行所述将所述可用磁盘中第一数量个预设大小的所述第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区的步骤;
若否,则生成报错提示信息。
可选地,第一数量个预设大小的所述第一子存储空间均匀分布在第二数量个所述可用磁盘中。
可选地,第i个所述数据处理守护进程对应的日志分区位于第i%s+1个所述可用磁盘中;其中,i=1,2,…,n;n为所述第一数量;s为所述第二数量;%为取余运算。
第二方面,本申请还公开了一种数据处理守护进程的数据分区配置装置,应用于集群节点,包括:
第一确定模块,用于确定本集群节点中数据处理守护进程的第一数量;
获取模块,用于获取各个所述数据处理守护进程的进程标识号;
第二确定模块,用于确定本集群节点中的可用磁盘;
分配模块,用于将所述可用磁盘中第一数量个第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区,将所述可用磁盘中第一数量个第二子存储空间确定为与各个所述数据处理守护进程一一对应的缓存分区;
执行模块,用于生成并运行各个所述数据处理守护进程的配置文件。
第三方面,本申请还公开了一种数据处理守护进程的数据分区配置设备,应用于集群节点,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序以实现如上所述的任一种数据处理守护进程的数据分区配置方法的步骤。
第四方面,本申请还公开了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时用以实现如上所述的任一种数据处理守护进程的数据分区配置方法的步骤。
本申请所提供的数据处理守护进程的数据分区配置方法应用于集群节点,包括:确定本集群节点中数据处理守护进程的第一数量;获取各个所述数据处理守护进程的进程标识号;确定本集群节点中的可用磁盘;将所述可用磁盘中第一数量个第一子存储空间确定为与各个所述数据处理守护进程一一对应的日志分区,将所述可用磁盘中第一数量个第二子存储空间确定为与各个所述数据处理守护进程一一对应的缓存分区;生成并运行各个所述数据处理守护进程的配置文件。可见,通过部署于集群节点中而自动化运行,本申请可准确高效地自动确定出本集群节点中的数据处理守护进程以及可用磁盘,进而为各个数据处理守护进程分配并设置一一对应的日志分区和缓存分区,极大地提高了对集群节点中各个数据处理守护进程进行数据分区配置的效率和可靠性,降低了人力成本。此外,本申请还使得在各个集群节点中并发进行配置、以及在本集群节点中对多个数据处理守护进程并发进行配置成为了可能,从而进一步有效提高了数据分区配置的处理效率。本申请所提供的数据处理守护进程的数据分区配置装置、设备及计算机可读存储介质可以实现上述数据处理守护进程的数据分区配置方法,同样具有上述有益效果。
附图说明
为了更清楚地说明现有技术和本申请实施例中的技术方案,下面将对现有技术和本申请实施例描述中需要使用的附图作简要的介绍。当然,下面有关本申请实施例的附图描述的仅仅是本申请中的一部分实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图,所获得的其他附图也属于本申请的保护范围。
图1为本申请所提供的数据处理守护进程的数据分区配置方法在一种具体实施方式中的流程图;
图2为本申请所提供的数据处理守护进程的数据分区配置方法在另一种具体实施方式中的流程图;
图3为本申请所提供的一种数据处理守护进程的数据分区配置装置的结构框图。
具体实施方式
本申请的核心在于提供一种数据处理守护进程的数据分区配置方法、装置、设备及计算机可读存储介质,以便有效地提高对集群节点中各个数据处理守护进程进行数据分区配置的效率和可靠性,并降低人力成本。
为了对本申请实施例中的技术方案进行更加清楚、完整地描述,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行介绍。显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
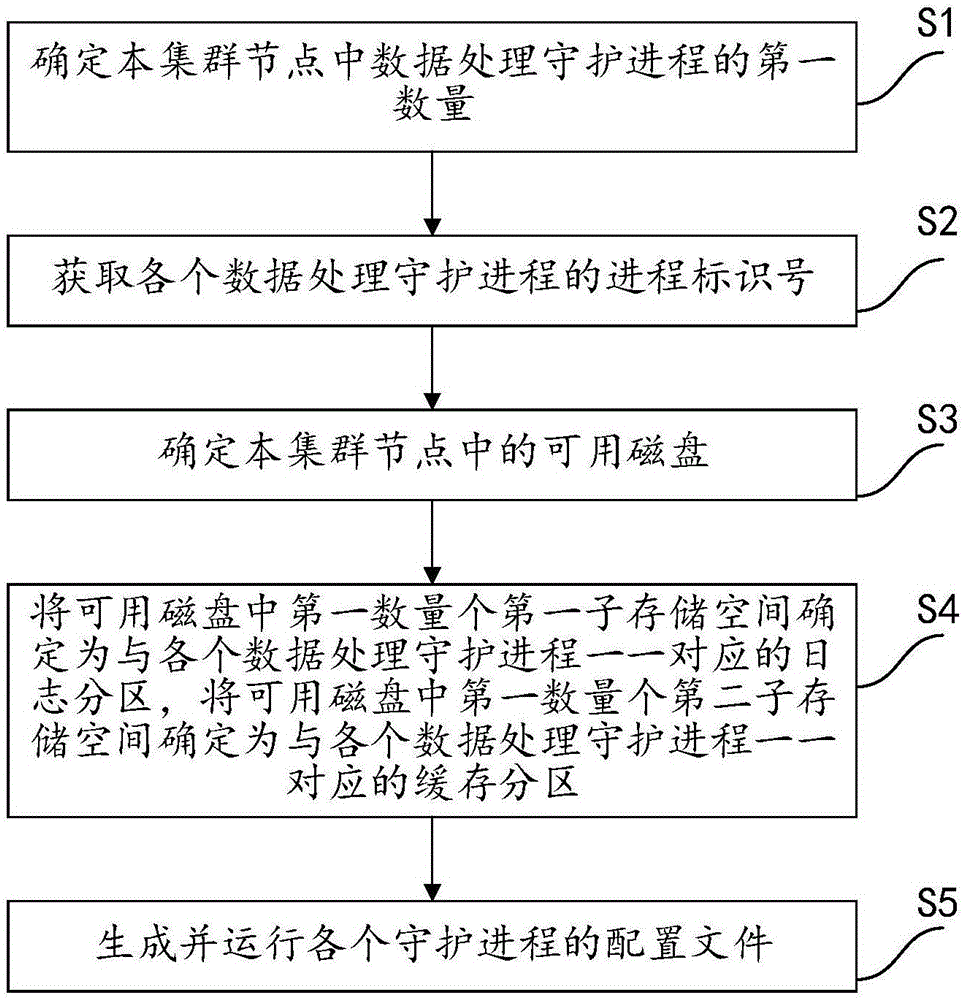
本申请实施例公开了一种数据处理守护进程的数据分区配置方法,应用与集群节点,参照图1所示,该方法主要包括以下步骤:
s1:确定本集群节点中数据处理守护进程的第一数量。
s2:获取各个数据处理守护进程的进程标识号。
s3:确定本集群节点中的可用磁盘。
s4:将可用磁盘中第一数量个第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区,将可用磁盘中第一数量个第二子存储空间确定为与各个数据处理守护进程一一对应的缓存分区。
s5:生成并运行各个守护进程的配置文件。
具体地,不同于现有技术中的手动配置,本申请所提供的数据处理守护进程的数据分区配置方法,具体可以以软件程序的形式部署在集群节点中而自动运行实现。
对于任意一个部署了本申请所提供方法的集群节点而言,可确定出本集群节点中需要创建的数据处理守护进程的总数,即所说的第一数量,不妨用n表示。容易理解的是,在分布式集群中,数据处理守护进程创建后便会生成进程标识号,根据进程标识号可在整个分布式集群的诸多集群节点中唯一地识别出对应的数据处理守护进程。
数据分区中的数据包括日志数据和缓存数据。如前所述,每个数据处理守护进程都需要设置一个对应的日志分区和缓存分区,因此,集群节点还需要确定出本集群节点中的可用磁盘,从而在可用磁盘中划分出一个个的子存储空间作为日志分区或者缓存分区。容易理解的是,当有第一数量个即n个数据处理守护进程时,相应地就要设置第一数量个即n个日志分区,并且分别与各个数据处理守护进程一一对应;类似地,还要设置第一数量个即n个缓存分区,并且分别与各个数据处理守护进程一一对应。
容易理解的是,所说的可用磁盘即为在该集群节点中能够作为数据处理守护进程数据分区而使用的磁盘。优选地,可选择读写速度较快的ssd硬盘即固态硬盘。如此可实现冷热数据的分离存储,有利于提高存储集群的读写性能。
当为该集群节点中的各个数据处理守护进程均划分好日志分区和缓存分区后,便可根据划分结果生成各个数据处理守护进程对应的配置文件,通过运行各个配置文件,即可写入相关配置信息,完成数据处理守护进程的初始化配置。
本申请所提供的数据处理守护进程的数据分区配置方法包括:确定本集群节点中数据处理守护进程的第一数量;获取各个数据处理守护进程的进程标识号;确定本集群节点中的可用磁盘;将可用磁盘中第一数量个第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区,将可用磁盘中第一数量个第二子存储空间确定为与各个数据处理守护进程一一对应的缓存分区;生成并运行各个数据处理守护进程的配置文件。可见,通过部署于集群节点中而自动化运行,本申请可准确高效地自动确定出本集群节点中的数据处理守护进程以及可用磁盘,进而为各个数据处理守护进程分配并设置一一对应的日志分区和缓存分区,极大地提高了对集群节点中各个数据处理守护进程进行数据分区配置的效率和可靠性,降低了人力成本。此外,本申请还使得在各个集群节点中并发进行配置、以及在本集群节点中对多个数据处理守护进程并发进行配置成为了可能,从而进一步有效提高了数据分区配置的处理效率。
本申请所提供的数据处理守护进程的数据分区配置方法,在上述内容的基础上,作为一种优选实施例,获取各个数据处理守护进程的标识号包括:
判断本集群节点是否为主节点;
若是,则接收各个集群节点发送的第一数量;向集群监控守护进程申请获取各个集群节点中各个数据处理守护进程的进程标识号,并发送至对应的集群节点;
若否,则将本集群节点的第一数量发送至主节点;接收主节点发送的进程标识号。
具体地,在分布式集群中,可具体由分布式集群的主节点来获取各个集群节点中数据处理守护进程的第一数量,从而获取整个分布式集群中需创建的数据处理守护进程的总数量,进而向集群监控守护进程申请获取每个数据处理守护进程的进程标识号,并发送至对应的集群节点。
本申请所提供的数据处理守护进程的数据分区配置方法,在上述内容的基础上,作为一种优选实施例,将可用磁盘中第一数量个第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区包括:将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区;
将可用磁盘中第一数量个第二子存储空间确定为与各个数据处理守护进程一一对应的缓存分区包括:将可用磁盘中的剩余空间划分为第一数量个第二子存储空间,以便作为与各个数据处理守护进程一一对应的缓存分区。
具体地,本实施例中,在为本集群节点的n个数据处理守护进程划分日志分区和缓存分区时,具体可先划分出日志分区,并且可为各个日志分区设定统一大小,即所说的预设大小,然后再利用剩余的存储空间作为缓存分区。
当然,本领域技术人员可根据实际应用情况而自行设置日志分区的预设大小,例如,优选可设置为5gb。
本申请所提供的数据处理守护进程的数据分区配置方法,在上述内容的基础上,作为一种优选实施例,在确定本集群节点中的可用磁盘之后,还包括:
判断可用磁盘的第二数量是否大于零;
若是,则继续执行将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区的步骤;
若否,则生成报错提示信息。
具体地,在确定出本集群节点中的可用磁盘后,不妨设可用磁盘的第二数量为s。为了防止后续步骤中报错,可预先对第二数量s进行校验:若s大于零,则可判定正常;若s不大于零,则说明该集群节点中无可用磁盘,可立即生成报错提示信息以便及时提醒用户。
本申请所提供的数据处理守护进程的数据分区配置方法,在上述内容的基础上,作为一种优选实施例,在将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区之前,还包括:
确定第二数量个可用磁盘的总存储空间;
判断总存储空间是否大于第一数量个预设大小的第一子存储空间;
若是,则继续执行将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区的步骤;
若否,则生成报错提示信息。
具体地,为了防止后续步骤中报错,可预先对可用磁盘的容量大小进行校验:不妨设每个日志分区的预设大小为r,s个可用磁盘的总存储空间为r,则n个日志分区所需的总存储空间大小为r*n,所以,若r大于r*n,则说明还有剩余空间用作为缓存分区,可判定正常;若r不大于r*n,则说明可用磁盘没有足够空间用作日志分区和缓存分区,由此可生成报错提示信息以便及时提醒用户。
本申请所提供的数据处理守护进程的数据分区配置方法,在上述内容的基础上,作为一种优选实施例,第一数量个预设大小的第一子存储空间均匀分布在第二数量个可用磁盘中。
具体地,为了保障每个可用磁盘存储性能的均衡性,可在s个可用磁盘中均匀地设置n个日志分区。
作为一种优选实施方式,第i个数据处理守护进程对应的日志分区位于第i%s+1个可用磁盘中;其中,i=1,2,…,n;n为第一数量;s为第二数量;%为取余运算。
以n为10,s为5的情况为例:则对于第1个和第6个数据处理守护进程,i%5+1=2,其日志分区位于第2个可用磁盘中;对于第2个和第7个数据处理守护进程,i%5+1=3,其日志分区位于第3个可用磁盘中;对于第3个和第8个数据处理守护进程,i%5+1=4,其日志分区位于第4个可用磁盘中;对于第4个和第9个数据处理守护进程,i%5+1=5,其日志分区位于第5个可用磁盘中;对于第5个和第10个数据处理守护进程,i%5+1=1,其日志分区位于第1个可用磁盘中。
由此,通过均匀分配后,不妨设每个可用磁盘上日志分区的个数为m,则m*s=n。然后进一步地,可将每个可用磁盘的剩余空间进行m等分,得到m个第二子存储空间,作为缓存分区。
上述内容可具体参考图2,图2为本申请所提供的数据处理守护进程的数据分区配置方法在另一具体实施方式中的流程图,该过程包括:
s201:确定本集群节点中数据处理守护进程的第一数量。
s202:获取各个数据处理守护进程的进程标识号。
s203:确定本集群节点中的可用磁盘。
s204:判断可用磁盘的第二数量是否大于零;若是,则进入s205;若否,则进入s210。
s205:确定第二数量个可用磁盘的总存储空间;进入s206。
s206:判断总存储空间是否大于第一数量个预设大小的第一子存储空间;若是,则进入s207;若否,则进入s210。
s207:将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区;进入s208。
s208:将可用磁盘中的剩余空间划分为第一数量个第二子存储空间,以便作为与各个数据处理守护进程一一对应的缓存分区;进入s209。
s209:生成并运行各个数据处理守护进程的配置文件。
s210:生成报错提示信息。
下面对本申请所提供的数据处理守护进程的数据分区配置装置进行介绍。
请参阅图3,图3为本申请所提供的一种数据处理守护进程的数据分区配置装置的结构框图,应用于集群节点,包括:
第一确定模块1,用于确定本集群节点中数据处理守护进程的第一数量;
获取模块2,用于获取各个数据处理守护进程的进程标识号;
第二确定模块3,用于确定本集群节点中的可用磁盘;
分配模块4,用于将可用磁盘中第一数量个第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区,将可用磁盘中第一数量个第二子存储空间确定为与各个数据处理守护进程一一对应的缓存分区;
执行模块5,用于生成并运行各个数据处理守护进程的配置文件。
可见,通过部署于集群节点中而自动化运行,本申请可准确高效地自动确定出本集群节点中的数据处理守护进程以及可用磁盘,进而为各个数据处理守护进程分配并设置一一对应的日志分区和缓存分区,极大地提高了对集群节点中各个数据处理守护进程进行数据分区配置的效率和可靠性,降低了人力成本。此外,本申请还使得在各个集群节点中并发进行配置、以及在本集群节点中对多个数据处理守护进程并发进行配置成为了可能,从而进一步有效提高了数据分区配置的处理效率。
在上述内容基础上,作为一种优选实施例,本申请所提供的数据处理守护进程的数据分区配置装置中,获取模块2具体用于:
判断本集群节点是否为主节点;若是,则接收各个集群节点发送的第一数量;向集群监控守护进程申请获取各个集群节点中各个数据处理守护进程的进程标识号,并发送至对应的集群节点;若否,则将本集群节点的第一数量发送至主节点;接收主节点发送的进程标识号。
在上述内容基础上,作为一种优选实施例,本申请所提供的数据处理守护进程的数据分区配置装置中,分配模块4具体用于:
将可用磁盘中第一数量个预设大小的第一子存储空间确定为与各个数据处理守护进程一一对应的日志分区;将可用磁盘中的剩余空间划分为第一数量个第二子存储空间,以便作为与各个数据处理守护进程一一对应的缓存分区。
在上述内容基础上,作为一种优选实施例,本申请所提供的数据处理守护进程的数据分区配置装置中,还包括校验模块,用于在第二确定模块3确定本集群节点中的可用磁盘之后,判断可用磁盘的第二数量是否大于零,并在可用磁盘的第二数量大于零时生成报错提示信息。
在上述内容基础上,作为一种优选实施例,校验模块还用于确定第二数量个可用磁盘的总存储空间;判断总存储空间是否大于第一数量个预设大小的第一子存储空间;并在总存储空间不大于第一数量个预设大小的第一子存储空间时生成报错提示信息。
在上述内容基础上,作为一种优选实施例,第一数量个预设大小的第一子存储空间均匀分布在第二数量个可用磁盘中。
在上述内容基础上,作为一种优选实施例,第i个数据处理守护进程对应的日志分区位于第i%s+1个可用磁盘中;其中,i=1,2,…,n;n为第一数量;s为第二数量;%为取余运算。
进一步地,本申请还公开了一种数据处理守护进程的数据分区配置设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序以实现如上所述的任一种数据处理守护进程的数据分区配置方法的步骤。
进一步地,本申请还公开了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时用以实现如上所述的任一种数据处理守护进程的数据分区配置方法的步骤。
本申请所提供的数据处理守护进程的数据分区配置装置、设备及计算机可读存储介质的具体实施方式与上文所描述的数据处理守护进程的数据分区配置方法可相互对应参照,这里就不再赘述。
本申请中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
还需说明的是,在本申请文件中,诸如“第一”和“第二”之类的关系术语,仅仅用来将一个实体或者操作与另一个实体或者操作区分开来,而不一定要求或者暗示这些实体或者操作之间存在任何这种实际的关系或者顺序。此外,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上对本申请所提供的技术方案进行了详细介绍。本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以对本申请进行若干改进和修饰,这些改进和修饰也落入本申请的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!