一种融合多特征的老挝语人名地名实体识别方法与流程
本发明涉及一种融合多特征的老挝语人名地名实体识别方法,属于自然语言处理中小语种识别领域。
背景技术:
命名实体识别作为自然语言处理的一个重要基础任务,目前学术上主要以神经网络和传统的统计机器学习方法结合作为训练模型。因为相对比传统的统计机器学习方法可以省去人工提取特征的步骤,相对比基于规则的方法其更具有泛化性。因此目前学术中主流的命名实体识别的模型为blstm+crf。虽然blstm+crf在通用命名实体识别领域中展现出了较好的性能,但在老挝语命名实体识别领域中的应用仍存在人名地名识别率不高、模型欠拟合等问题。因为相比于一般领域的命名实体,老挝语命名实体识别有以下几个问题:(1)语料情况复杂,标注语料不充足;(2)语法等命名规则了解不充分;(3)在词性标注和分词较基础领域老挝语研究相对较少。
技术实现要素:
本发明要解决的技术问题是提供一种融合多特征的老挝语人名地名实体识别方法,用于解决老挝语人名地名识别率不高、模型欠拟合等问题。
本发明采用的技术方案是:一种融合多特征的老挝语人名地名实体识别方法,其特征在于:包括以下步骤:
step1:获取老挝语人名地名命名实体语料,进行语料预处理;
step2:将blstm算法训练老挝语词语的后缀、前缀字符级向量;
step3:对老挝语词语进行词向量转化,通过gensim的word2vec模型,训练具有上下文语义的词向量;
step4:将字符级向量和词向量进行组合拼接,得到完整的特征向量;
step5:将老挝语人名地名多特征融合到crf算法模型中,形成优化的crf模型;
step6:将step4得到的完整特征向量输入到step5得到的crf优化模型进行老挝语人名地名实体词识别训练。
具体地,所述步骤step2具体步骤如下:
step2.1:建立blstm模型:使用tensorflow深度学习框架,python程序语言进行blstm算法的编写;
step2.2:设置模型参数:设置迭代次数为10000次,学习率设置为0.1、0.01、0.001三种,通过最后在训练集上体现的准确率,选择合适的学习率;
step2.3:训练字符级向量:将老挝语词语进行字符切分,输入到blstm算法中进行训练。
具体地,所述步骤step3具体步骤如下:
step3.1:老挝语分词:通过老挝语分词工具,通过分词算法计算机会自动将老挝语句子切分成单词;
step3.2:去除停用词:将老挝语停用词作成一个词典,将分词后的老挝语进行筛选;
step3.3:训练词向量:首先安装gensim包,调用word2vec算法模型,将筛选后的老挝语词语作为输入,word2vec算法将词语的频率和上下文信息进行训练,最终输出具有了上下文语义特征的词向量。
具体地,所述步骤step4具体步骤如下:
step4.1:安装科学计算模块:通过python安装numpy科学计数模块,进行特征向量的矩阵运算;
step4.2:特征向量拼接:将步骤step2中训练的字符级特征向量矩阵维度设置为固定值,将步骤step3中训练的具有上下文语义特征的词向量矩阵维度设置的和step2一致,使用加载的numpy科学计数模块,进行运算,将两组特征向量进行拼接组合成一组特征向量。
具体地,所述步骤step5具体步骤如下:
step5.1:整理老挝语语言学特征:老挝人名字前面多有冠词,老挝语地名前多有指示词;
step5.2:将老挝语语言学特征制定成规则,将规则融合到条件随机场crf算法中,形成可以对老挝语人名地名实体词的识别的优化的crf模型。
具体地,所述步骤step6具体步骤如下:
step6.1:识别老挝语人名地名:将step4中拼接成的完整特征向量作为输入,step5融合老挝语语言学特征的条件随机场crf算法作为输出层算法,最后输出老挝语人名地名识别标志。
本发明的有益效果是:
(1)该融合老挝语多特征命名实体识别方法中,在老挝语人名地名精度有较大的提高。
(2)该融合老挝语多特征命名实体识别方法中,使用了深度学习和机器学习融合的算法,增加了迭代的次数,优化了训练的速度。
(3)该融合老挝语多特征命名实体识别方法中,在老挝语命名实体语料不充足的情况下也可以有较好的识别精度。
附图说明
图1为本发明中的流程图;
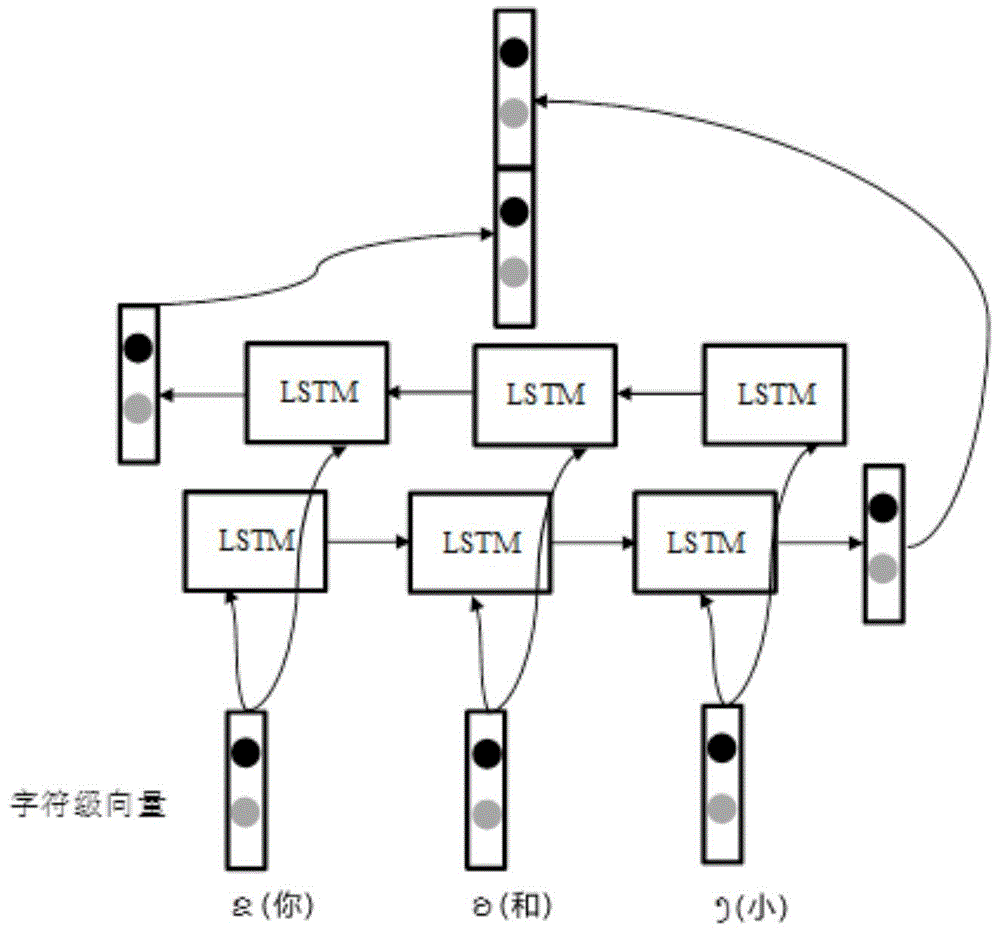
图2为本发明中的blstm训练字符级向量的基本结构图;
图3是本发明所采用crf读取组合向量并输出的基本结构图。
具体实施方式
下面结合附图和具体实施例,对本发明做进一步的说明。
实施例1:如图1-3所示,一种融合老挝语多特征命名实体识别方法,具体步骤如下:
step1,获取老挝语人名地名命名实体语料,进行预训练操作。所述步骤step1,数据通过老挝语留学生手动标注语料,30000个老挝语词语,将27000个老挝语词语做训练集,3000个词语做测试集。
step2,将blstm算法训练老挝语词语的后缀、前缀等字符级向量。所述步骤step2,将step1预训练好的词词语输入到blstm来训练,在blstm训练前设置学习率、步长等一系列超参数。将迭代次数设置为10000,学习率设置为0.1,0.01.0.001三种,通过最后在训练集上体现的准确率,选择合适的学习率。
step3,对老挝语词语进行词向量转化,通过gensim的word2vec模型,训练具有上下文语义的词向量。所述步骤step3安装gensim模型,调取模型中word2vec算法,将分好词的老挝语训练集输入到word2vec算法中,设置word2vec部分参数,最后输出老挝语具有语义特征的词向量。
step4,将字符级向量和词向量进行组合拼接。所述步骤step4、step2训练的字符级特征向量和step3中训练的词向量拼接成大小一致的组合向量。
step5,将老挝语人名地名多特征融合成crf规则。所述步骤step5具体为:安装crf运行环境,将老挝语人名地名语言学特征编写成crf可识别规则,形成融合老挝语语言学特征的优化crf模型,crf计算公式为:
上面的式子t为转移矩阵,用于刻画相邻分数的依赖转移关系,y1,….,ym代表词的一系列标签,st代表得分向量,m表示词语的个数。在crf层中应用softmax激活函数,将概率分布计算出来,式子如下:
z表示概率分布统计,最后,序列概率计算的式子如下:
上式中p代表序列概率的值。
step6,将完整的特征向量输入到融合了多特征的crf模型进行老挝语人名地名命名实体识别训练。具体地,将step4中组合的特征向量输入到step5融合了老挝语语言学特征的优化crf模型中,完成最终的老挝语人名地名的识别。
- 还没有人留言评论。精彩留言会获得点赞!