一种机器学习平台及基于该平台的数据模型优化方法与流程
本发明属于数据模型评估技术领域,特别是涉及一种机器学习平台及基于该平台的数据模型优化方法。
背景技术:
随着大数据的普遍应用与各个领域,数据的处理对信息获取越来越重要。在数据处理的过程中,往往不同数据模型处理的效果不同,不同数据类型采用不同的数据模型起到的效果也大相径庭。这就要求对不同数据模型应用与不同类型的数据进行评估;这个过程十分繁琐,并且需要以大量数据进行验证。如果采用人工操作过程复杂,不易观察,而且工作量大很难达到应有的效果。这就需要建立机器学习平台,用于搭建各种数据模型,同时该机器学习平台通过大数据集群提取源数据;并通过源数据验证数据模型以及建立良好的模型评估方法,构建优良的数据模型和数据模型评估方法。
本发明致力于研发一种机器学习平台及基于该平台的数据模型优化方法,通过源数据验证数据模型以及建立良好的模型评估方法,构建优良的数据模型和数据模型评估方法,解决现有的数据模型构建复杂、验证工作量大且不能进行良好的模型验证的问题。
技术实现要素:
本发明的目的在于提供一种机器学习平台及基于该平台的数据模型优化方法,通过模型构建模块快速构建数据模型,采用数据获取模块获取源数据并通过数据处理模块处理后提工给数据模型,并通过模型评估模块进行数据模型评估,最后采用模型优化模块对数据模型优化,获得良好的数据模型,解决了现有的数据模型构建复杂、验证工作量大且不能进行良好的模型验证的问题。
为解决上述技术问题,本发明是通过以下技术方案实现的:
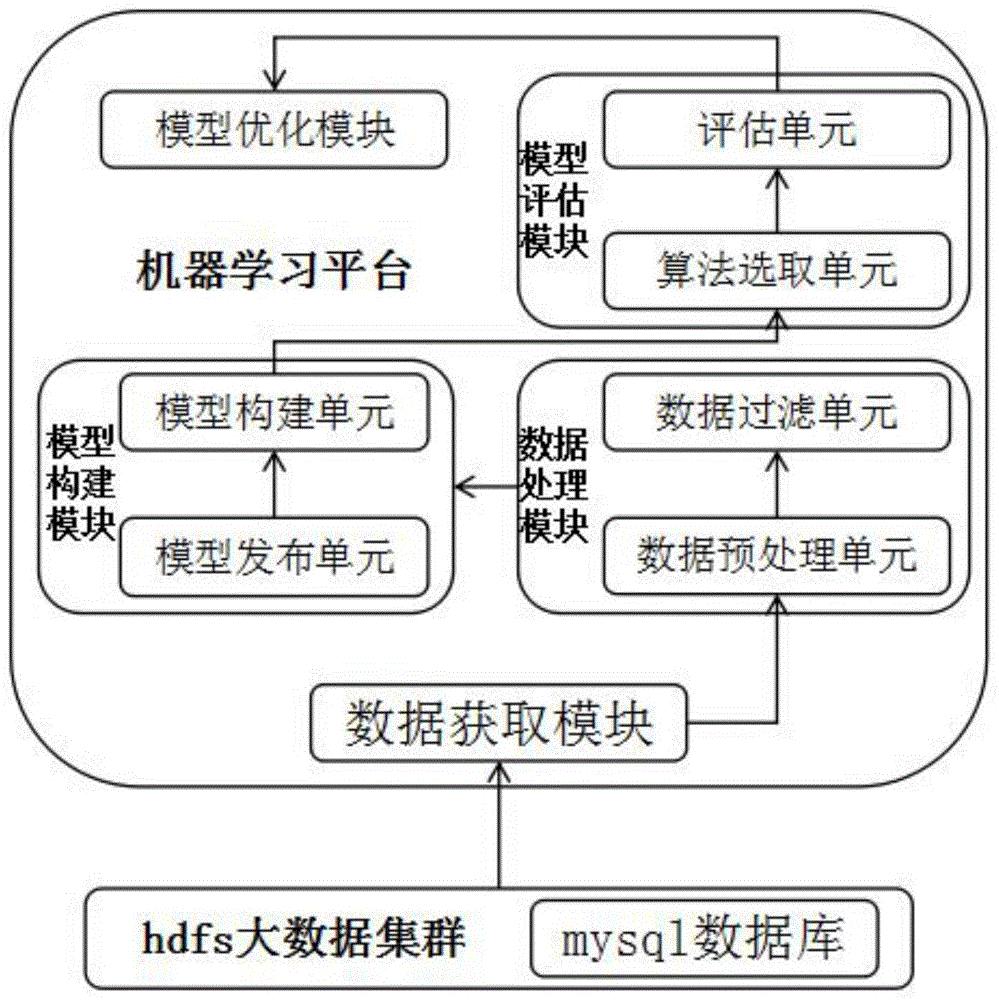
本发明为一种机器学习平台,包括:模型构建模块、数据获取模块、数据处理模块、模型评估模块以及模型优化模块;
所述模型构建模块包括模型构建单元以及模型发布单元;所述模型构建单元用于模型的搭建;所述模型发布单元将构建好的数据模型发布;
所述数据获取模块从hdfs大数据集群的mysql数据库获取源数据并写成hive表;所述数据处理模块还包括数据预处理单元以及数据过滤单元;所述数据预处理单元用于对源数据采样、比例拆分、类型转换以及缺失值填充;所述数据过滤单元用于过滤多余记录和字段;
所述模型评估模块还包括算法选取单元以及评估单元;所述算法选取单元根据模型特征选取适应的评估算法;所述评估单元根据选取的评估算法对数据模型评估;
所述模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化。
优选地,所述数据处理模块还用于将预处理后的数据填充到所述数据模型对应的位置;所述模型评估模块通过对数据模型内的数据预测及评估。
优选地,所述mysql数据库中还存储若干评估算法;所述评估算法具体包括逻辑回归算法、决策树分类算法、朴素贝叶斯算法、随机森林分类算法、梯度提升树分类算法、kmeans算法、梯度提升树回归算法以及决策树回归算法。
优选地,所述源数据采样又包括随机采样和分层采样;所述比例拆分是将源数据拆分成用于模型训练以及用于模型验证。
基于机器学习平台的数据模型优化方法,包括如下过程:
数据读取:所述数据获取模块从数据源中选择数据表;
数据探索:所述数据处理模块通过查看源数据以及可视化图形探索数据分布情况;
数据处理:所述数据处理模块对源数据字段过滤、类型转换、数字索引、样本区分以及样本平衡;
选取算法:所述模型评估模块根据数据模型的特征选取预测算法;
模型评估:所述模型评估模块通过输出模型的混淆矩阵和模型准确度对数据模型评估;
模型优化:所述模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化。
优选地,所述字段过滤用于过滤掉与要建立的数据模型无关的字段以及严重缺失的字段;所述类型转换用于将关键字段转换成double类型,以适应进入模型训练;
所述数字索引用于对不同类型变量建立便于识别和查找的索引;所述样本区分用于将选取的数据区分成模型训练数据和模型验证数据;所述样本平衡用于将训练样本中的征服样本平衡,保证数据模型的无偏性。
本发明具有以下有益效果:
1、本发明通过模型构建模块快速构建数据模型,采用数据获取模块获取源数据并通过数据处理模块处理后提工给数据模型,其中数据处理模块对源数据字段过滤、类型转换、数字索引、样本区分以及样本平衡,保证进入到数据模型的数据的有效性、减少模型评估误差,模型评估模块通过输出模型的混淆矩阵和模型准确度对数据模型评估,方便对数据模型的优化。
2、本发明通过模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化,提高了数据模型的可信度以及精确度。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的一种机器学习平台的结构示意图;
图2为本发明的基于机器学习平台的数据模型优化方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1所示,本发明为一种机器学习平台,包括:模型构建模块、数据获取模块、数据处理模块、模型评估模块以及模型优化模块;
模型构建模块包括模型构建单元以及模型发布单元;模型构建单元用于模型的搭建;模型发布单元将构建好的数据模型发布;
数据获取模块从hdfs大数据集群的mysql数据库获取源数据并写成hive表;读取所连接的大数据集群上的hdfs文件并读取mysql数据库;把任务流程执行后,组件生成的数据,写入到hive表中;若是输入的表名不存在,则会自动创建该表,若已存在,该节点执行时会提示该表已存在,不会写入数据。数据处理模块还包括数据预处理单元以及数据过滤单元;数据预处理单元用于对源数据采样、比例拆分、类型转换以及缺失值填充;其中,类型转换将表的字段类型转成另一个类型,支持转换为double,int,string三种类型;缺失值填充用来将空值或者一个指定的值替换为最大值,最小值,均值或者一个自定义的值。可以通过给定一个缺失值的配置列表,来实现将输入表的缺失值用指定的值来填充;
数据过滤单元用于过滤多余记录和字段;其中,记录过滤指对数据按照过滤表达式进行筛选;字段过滤指将表中多余的字段进行删除。
模型评估模块还包括算法选取单元以及评估单元;算法选取单元根据模型特征选取适应的评估算法;评估单元根据选取的评估算法对数据模型评估;
模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化。
其中,数据处理模块还用于将预处理后的数据填充到数据模型对应的位置;模型评估模块通过对数据模型内的数据预测及评估。
其中,mysql数据库中还存储若干评估算法;评估算法具体包括逻辑回归算法、决策树分类算法、朴素贝叶斯算法、随机森林分类算法、梯度提升树分类算法、kmeans算法、梯度提升树回归算法以及决策树回归算法。
其中,源数据采样又包括随机采样和分层采样;以随机方式生成采样数据,支持按个数采样、按比例采样两种方式;数据集按字段的值分层抽取一定比例或者一定数据的随机样本。按个数采样,采样个数为100,则根据分组列字段值,每一种值抽取100条数据。按比例采样:分组列字段值为0的抽取50%的数据,字段值为1的抽取80%的数据,更多个字段值,以此类推。比例拆分是将源数据拆分成用于模型训练以及用于模型验证;对输入的数据按比例进行拆分,分别输出两份数据;拆分比例:训练数据集占数据源的比例默认为0.8,范围是0到1之间。
请参阅图2所示,基于机器学习平台的数据模型优化方法,包括如下过程:
数据读取:数据获取模块从数据源中选择数据表;
数据探索:数据处理模块通过查看源数据以及可视化图形探索数据分布情况;
数据处理:数据处理模块对源数据字段过滤、类型转换、数字索引、样本区分以及样本平衡;
选取算法:模型评估模块根据数据模型的特征选取预测算法;
模型评估:模型评估模块通过输出模型的混淆矩阵和模型准确度对数据模型评估;
模型优化:模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化。
其中,字段过滤用于过滤掉与要建立的数据模型无关的字段以及严重缺失的字段;类型转换用于将关键字段转换成double类型,以适应进入模型训练;
数字索引用于对不同类型变量建立便于识别和查找的索引;样本区分用于将选取的数据区分成模型训练数据和模型验证数据;样本平衡用于将训练样本中的征服样本平衡,保证数据模型的无偏性。
本发明在实际使用过程中,首先采用模型构建单元构件数据模型;模型发布单元将构建好的数据模型发布。数据获取模块从数据源中选择数据表;具体的为,读取所连接的大数据集群上的hdfs文件并读取mysql数据库中的源数据。
数据处理模块通过查看源数据以及可视化图形探索数据分布情况,具体的包括全表统计:查看各个字段的最大值,最小值,平均值,标准差,去重记录数,缺失记录数,总记录数;直方图:统计字段值在各个区间分布情况;饼状图:统计分类字段,每类值的记录总数及占比。
数据处理模块对源数据字段过滤、类型转换、数字索引、样本区分以及样本平衡,具体的为:字段过滤拥有过滤掉对建模无关的字段(例如:用户id)、缺失值超过70%的字段等;类型转换把关键字段转换为double类型,以适合进入模型训练;并对于分类型变量,需创建数字索引;样本分区一般会选取80%的样本进行模型训练,20%的样本进行模型验证;为了保证模型的无偏性,尽量让训练样本中的,正负样本量1:1平衡。可使用分层抽样,对正负样本分别进行抽样,调整分别抽样比例,使得正负样本量在1:1比例。
模型评估模块根据数据模型的特征选取预测算法,用户流失属于分类型问题,所以选择分类型算法,本例选择逻辑回归算法进行演示。模型评估模块通过输出模型的混淆矩阵和模型准确度对数据模型评估,主要参考指标是模型的准确度,通过查看结果,可输出模型的混淆矩阵和准确度等模型评估指标。
模型优化模块通过精确数据源、调整数据处理方式、调整正负样本、选择更优算法以及调整算法参数对模型优化;模型优化的目的,是为了提高模型的准确度,可以从如下五个方面入手:1、数据源,根据业务经验,尽量找出影响用户流失的关键影响因素;2、数据处理方式:包括缺失值处理、字段过滤等;3、调整正负样本比例;4、选择不同的模型算法;5、调整模型中各个算法的参数。
值得注意的是,上述系统实施例中,所包括的各个单元只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
另外,本领域普通技术人员可以理解实现上述各实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,相应的程序可以存储于一计算机可读取存储介质中。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!