一种根据车主相关的数据而判断其理赔风险等级的系统的制作方法
本发明涉及车险领域,具体涉及一种根据车主相关的数据而判断其理赔风险等级的系统。
背景技术:
根据公开数据,2016年全国有1.5亿私家车主,涉及54%的家庭。但在车险行业,只有14家公司车险承保盈利,41家亏损的公司亏损总额达到63亿元,行业亏损比例达到75%。精准定价能力的缺失,客户风险计算的不足是这些车险公司面临困境的重要原因。根据与保险公司多次沟通的情况来看,客户对于车主、车辆及车险等多个维度都需要一个用户风险分析系统。这对于保险公司的车险定价,承保业务有很大帮助。
技术实现要素:
本发明的目的是为解决上述不足,提供一种根据车主相关的数据而判断其理赔风险等级的系统。
本发明的目的是通过以下技术方案实现的:
一种根据车主相关的数据而判断其理赔风险等级的系统,
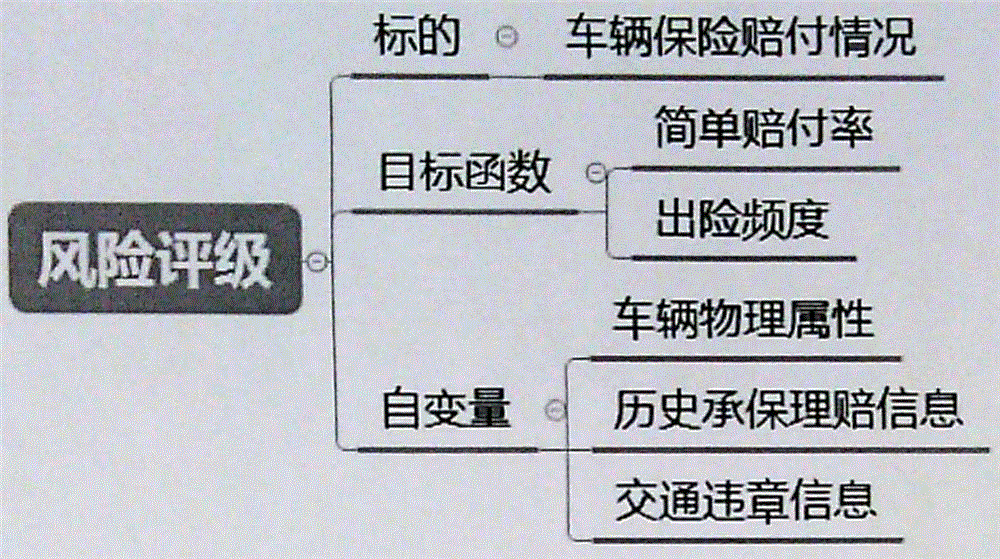
自变量(1):在数据库中整合包括客户保险标的数据,包括保险数据,车辆数据和交通数据等50个自变量;整合数据(1)中数据,数据来源包括三方面,第一方面是车辆物理属性数据,包括车辆性能,市场价值等,第二方面是历史承保理赔信息,包括车辆历史出险状况,在保状态,保单信息,第三方面是交通违章信息:
目标函数(2):随机森林模型算法,理赔比和自变量数据的函数关系;用机器学习算法,训练出理赔比与自变量数据的函数关系;
标的(3):根据训练样本和预测样本得标的数据来确定自变量选取及设置是否合理,调节模型,使之更贴合实际,根据预测样本和训练样本调整自变量的选取及设置,使结果更符合实际。
车辆数据计算用户综合理赔比分数的评估方法如下:
a、从数据库中提取清洗完的保单理赔,车辆属性数据,交通违章四方面的特征数据,去除null值,异常数据以及保险残缺的数据,清洗之后作为输入变量x,目标函数取赔付率y和输入变量x的函数,即y=f(x);
b、模型取机器学习随机森林算法,从步骤a中的一部分数据作为训练数据(x1,y1),另一部分为检验数据(x2,y2),以输入变量x为输入特征,预测客户未来理赔率y;
c、从训练样本中随机采样n条数据,从所有特征值中随机选取k个特征值,对选出的样本利用其特征以
d、对d步骤循环m次,生成m颗决策树φi(i=1,2,3...m);
e、数据导入模型后开始机器学习训练过程,训练开始前随机生成f,训练过程中,为了使拟合的误差达到最小,算法会在训练过程中不断的调整f,使最终得出一个由x到y的一个映射关系f,预测值
f、训练得到最终的f后,再由检验样本的x2变量,输入模型,模型综合所有决策树的预测结果给出得到y2的预测值f(x2),将y2预测和x2对应的y2比对,得出f的准确度;
g、如果f的准确度较低,误差较大不能满足需求,回到步骤b重新选取样本数据,修改模型参数权重,重新训练,直至f准确度达到要求;
如果f准确度符合要求,那么确认f为最终模型。
本发明具有如下有益的效果:
本发明运用机器学习技术,对车主进行行为预测和风险划分,分为10个赔付率不同的风险等级评分,分数越高代表风险越低。帮助保险公司承保、营销的业务流程中,为制定合理有效的风险控制、差异化定价、营销策略而提供决策依据。
附图说明
图1为本发明的整体结构示意图;
图2为本发明的训练拟合图;
图3为本发明的风险评级训练过程。
具体实施方式
下面结合附图对本发明作进一步的说明:
如图1所示,一种根据车主相关的数据而判断其理赔风险等级的系统,
自变量(1):在数据库中整合包括客户保险标的数据,包括保险数据,车辆数据和交通数据等50个自变量;整合数据(1)中数据,数据来源包括三方面,第一方面是车辆物理属性数据,包括车辆性能,市场价值等,第二方面是历史承保理赔信息,包括车辆历史出险状况,在保状态,保单信息,第三方面是交通违章信息;
目标函数(2):随机森林模型算法,理赔比和自变量数据的函数关系;用机器学习算法,训练出理赔比与自变量数据的函数关系;
标的(3):根据训练样本和预测样本得标的数据来确定自变量选取及设置是否合理,调节模型,使之更贴合实际,根据预测样本和训练样本调整自变量的选取及设置,使结果更符合实际。
车辆数据计算用户综合理赔比分数的评估方法如下:
a、从数据库中提取清洗完的保单理赔,车辆属性数据,交通违章四方面的特征数据,去除null值,异常数据以及保险残缺的数据,清洗之后作为输入变量x,目标函数取赔付率y和输入变量x的函数,即y=f(x);
b、模型取机器学习随机森林算法,从步骤a中的一部分数据作为训练数据(x1,y1),另一部分为检验数据(x2,y2),以输入变量x为输入特征,预测客户未来理赔率y;
c、从训练样本中随机采样n条数据,从所有特征值中随机选取k个特征值,对选出的样本利用其特征以
d、对d步骤循环m次,生成m颗决策树φi(i=1,2,3...m);e、数据导入模型后开始机器学习训练过程,训练开始前随机生成f,训练过程中,为了使拟合的误差达到最小,算法会在训练过程中不断的调整f,使最终得出一个由x到y的一个映射关系f,预测值
g、如果f的准确度较低,误差较大不能满足需求,回到步骤b重新选取样本数据,修改模型参数权重,重新训练,直至f准确度达到要求;
h、如果f准确度符合要求,那么确认f为最终模型。
具体实施例如下:
1、将客户相关数据存储至数据库中,并清洗去除异常数据;
2、从清洗完的数据中提取保单理赔,车辆属性数据,交通违章四方面的特征作为输入变量x,目标函数取赔付率为y;
3、模型取机器学习随机森林算法,训练样本取数据中保险起期在2015年1-3月的车辆数据(x1,y1),预测样本取数据中保险起期在2015年4-6月的车辆数据(x2,y2)用于机器学习,以输入变量x为输入特征,预测客户未来理赔率;
4、从训练样本中随机采样n条数据,从50个特征值中随机选取k个特征值,对选出的样本利用其特征以
5、对d步骤循环m次,生成m颗决策树;
6、数据导入模型后开始机器学习训练过程,训练开始前随机生成f,如图2所示,训练过程中,为了使拟合的误差达到最小,算法会在训练过程中不断的调整f,使最终得出一个由x到y的一个映射关系f,f(x1)≈y1;
7、训练得到最终的f后,再由检验样本的x2变量,输入模型,模型综合所有决策树的预测结果给出得到y2的预测值f(x2),将y2预测和x2对应的y2比对,预测得出f的准确度;
8、如果f的准确度较低,误差较大不能满足需求,回到步骤b重新选取样本数据,修改模型参数权重,重新训练,直至f准确度达到要求;
9、如果f准确度符合要求,那么确认f为最终模型;
10、如图3所示,模型确定好后,取需要预测的车辆数据x,输入模型,得到预测理赔比,并从低到高分成10个小组,得到车辆的未来理赔比预测数据。
- 还没有人留言评论。精彩留言会获得点赞!