一种基于强化学习的跨数据中心网络任务调度方法与流程
本发明属于通信技术领域,更进一步涉及有线通信网络技术领域中的一种基于强化学习的跨数据中心网络任务调度方法。本发明可应用于由多个数据中心组成的跨数据中心网络中,实现对用户任务的调度,以满足用户在完成任务时对跨数据中心网络中计算资源、内存资源、硬盘存储资源的请求,实现跨数据中心网络资源的有效分配。
背景技术:
随着5g、物联网、机器学习、ar/vr等技术的出现,跨数据中心网络大规模部署,网络流量突发式增长、网络状态实时变化以及业务需求呈现多元化态势,为跨数据中心网络任务调度以及资源的管理带来了巨大的挑战。现有的任务调度机制采用固定式启发式策略,即通过人工精细设计的启发式算法来解决,以得到研究问题的简化模型,并通过调整启发式算法参数以获得更好的网络性能。然而基于固定启发式策略的任务调度,由于缺乏与网络环境状态信息以及网络流量信息的交互,缺少自适应调整并优化模型参数的机制,仅能够为特定的通信网络环境提供高性能的任务调度,无法适应用户任务需求与网络环境的动态变化,在资源优化和网络性能提升方面受到一定程度的限制。
zhiminghu等人在其发表论文“time-andcost-efficienttaskschedulingacrossgeo-distributeddatacenters”(ieeetparalldistrvol.29,no.3,pp.705-718.2018.3)中提出一种启发式算法实现跨数据中心网络任务调度的方法。该方法步骤是,第一步:采集到达数据中心任务集合的资源需求;第二步:检查所有数据中心的剩余资源情况;第三步:将资源需求信息送到线性程序决策器;第四步:从线性程序解决器获得每个数据中心的资源分配情况;第五步:按照第四步中的资源分配情况,将每个任务分配到对应的数据中心中进行处理。该方法存在的不足之处是,未通过量化多维资源的碎片化程度实现多维资源的有效利用,造成资源碎片化,影响了数据中心的工作效率;该方法属于固定式启发式策略,缺少与网络环境实时状态的交互,无法在网络环境与任务需求动态变化的情况下自适应地优化调度策略,在资源优化和网络性能提升方面受到一定程度的限制。
中国科学院重庆绿色智能技术研究院在其申请的专利文献“一种基于深度强化学习的资源调度方法和系统”(申请号:201810350436.1申请日:2018.04.18申请公布号:cn108595267a)中公开了一种基于深度强化学习网络模型资源调度方法。该方法的具体步骤是,第一步:系统通过日志文件采集用户的行为数据,包括用户对任务所需资源的申请情况、资源的调度记录等;第二步:系统通过用户保留在系统内的任务信息,自动根据用户的任务进行训练,得到一种适合的调度算法作为用户的初始调度算法,用于生成相对应的调度结果;第三步:用户对当前返回的调度结果进行评估,并做出是否接受当前调度策略的选择;第四步:如果用户满意当前调度策略所产生的调度结果,则系统认为该算法为适合该用户的个性化调度算法;第五步:如果用户不满意当前调度策略所产生的调度结果,则用户可以通过系统提供的调度算法接口,选择再次训练调度策略。该方法存在的不足之处是,只考虑了用户任务请求一维资源时的任务调度情况,对于多维资源的任务请求,该方法并没有明确指出如何调度,而在实际跨数据中心网络任务调度中,用户任务的资源请求通常是由多种资源构成,因此该方法无法适用于跨数据中心网络任务调度。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提出一种基于强化学习的跨数据中心网络任务调度方法。本发明在对跨数据中心网络中来自用户的任务进行调度时,通过与跨数据中心网络环境的交互,及时感知跨数据中心网络环境信息的变化,通过收集当前跨数据中心网络任务调度决策产生的性能效果反馈,实时调整任务调度决策,以适应跨数据中心网络中无先验知识且网络环境高速动态变化的特点,实现智能化任务调度与资源分配,有效改善跨数据中心网络性能。此外,本发明在计算动作空间中可行动作的奖励值时,不仅考虑到数据中心的剩余可用资源,同时考虑到数据中心三种资源的均衡度,有效改善数据中心三种资源的均衡使用,提高跨数据中心网络的资源利用率。
实现本发明的具体思路是:采用强化学习的方法对跨数据中心网络中的任务进行实时调度,将跨数据中心网络拓扑信息、来自用户的任务资源需求信息以及跨数据中心网络状态信息作为强化学习的状态空间,将供给任务资源服务的可行数据中心的集合作为强化学习的动作空间,利用深度q网络方法,通过与跨数据中心网络环境的交互学习而训练得到基于强化学习的任务调度模型,及时感知跨数据中心网络环境信息的变化,克服现有技术中无法动态适应网络环境的动态变化、无法自适应地调整任务调度决策等瓶颈。本发明以多维资源均衡且有效利用为目标,通过考虑数据中心的剩余可用资源以及数据中心三种资源的均衡程度,计算动作空间中可行动作的奖励值,克服现有技术在任务调度中由于资源碎片化严重而导致的资源利用率低的问题。
实现本发明目的的具体步骤如下:
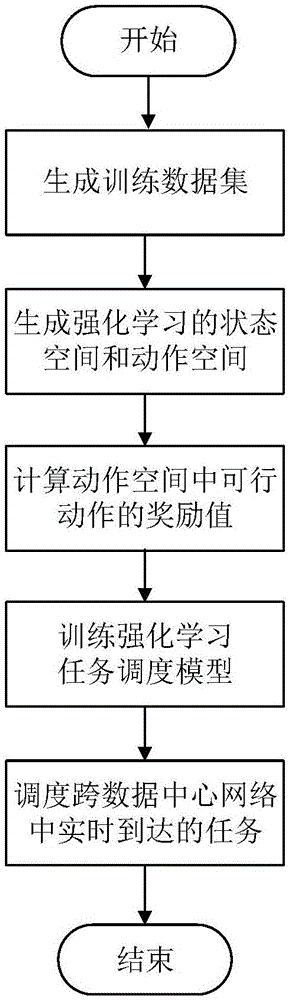
(1)生成训练数据集:
将一段时间内用户的历史任务资源请求,组成训练数据集;
(2)生成强化学习的状态空间和动作空间:
(2a)将用户的历史任务资源请求以及跨数据中心网络中各数据中心的计算资源、内存资源、硬盘存储资源信息,组成强化学习的状态空间;
(2b)将跨数据中心网络中所有节点集合,组成强化学习的动作空间;
(3)计算动作空间中可行动作的奖励值:
(3a)按照下式,计算每个数据中心的归一化剩余计算资源、归一化剩余内存资源、归一化剩余硬盘存储资源中的最小值,将该最小值作为该数据中心的归一化可用资源:
其中,rl表示第l个数据中心的归一化可用资源,min表示取最小值操作,rl,cpu表示第l个数据中心剩余的计算资源,cl,cpu表示第l个数据中心的计算资源总量,
(3b)按照下式,计算每个数据中心的三种归一化可用资源的均衡度:
其中,bl表示第l个数据中心的三种归一化可用资源的均衡度,
(3c)按照下式,计算动作空间中可行动作的奖励值:
其中,r表示动作空间中可行动作的奖励值,∑表示求和操作,l表示数据中心集合;
(4)训练强化学习任务调度模型:
利用深度q网络方法,对神经网络进行训练,得到训练好的强化学习任务调度模型;
(5)调度跨数据中心网络中实时到达的任务:
(5a)采集跨数据中心网络中实时到达的每一个任务资源请求,用每一个实时到达的任务资源请求更新状态空间中的任务资源请求信息;
(5b)将更新后的任务资源请求以及各数据中心的计算资源、内存资源、硬盘存储资源信息,输入到训练好的强化学习任务调度模型中,输出跨数据中心网络的任务调度资源分配向量;
(5c)按照任务调度资源分配向量中每个任务对应可行动作的节点序号,将每个任务分配到对应的数据中心。
本发明与现有技术相比具有以下优点:
第一,由于本发明采用强化学习方法进行跨数据中心网络的任务调度,克服现有技术由于缺少与网络环境实时状态的交互而导致的无法适应用户任务请求与网络环境的动态变化的问题,使得本发明具有任务调度策略自适应实时优化的特点,有助于优化跨数据中心网络资源分配、提升跨数据中心网络性能。
第二,本发明在设计强化学习任务调度模型时,以三种资源有效利用且均衡使用为目标,通过考虑数据中心的剩余可用资源并量化三种资源的均衡程度,计算动作空间中可行动作的奖励值,克服了现有技术在任务调度中由于资源使用不均衡而导致的资源碎片化严重且资源利用率低的问题,使得本发明具有三种资源均衡且有效利用的特点,有助于提高跨数据中心网络的资源利用率。
附图说明
图1为本发明的流程图;
图2为本发明利用深度q网络方法训练强化学习模型步骤的流程图。
具体实施方式
下面结合附图对本发明做进一步的详细描述。
参照附图1,对本发明的具体步骤做进一步的详细描述。
步骤1,生成训练数据集。
将一段时间内用户的历史任务资源请求,组成训练数据集。
步骤2,生成强化学习的状态空间和动作空间。
将用户的历史任务资源请求以及跨数据中心网络中各数据中心的计算资源、内存资源、硬盘存储资源信息,组成强化学习的状态空间。
将跨数据中心网络中所有节点集合,组成强化学习的动作空间。
步骤3,计算动作空间中可行动作的奖励值。
按照下式,计算每个数据中心的归一化剩余计算资源、归一化剩余内存资源、归一化剩余硬盘存储资源中的最小值,将该最小值作为该数据中心的归一化可用资源:
其中,rl表示第l个数据中心的归一化可用资源,min表示取最小值操作,rl,cpu表示第l个数据中心剩余的计算资源,cl,cpu表示第l个数据中心的计算资源总量,
按照下式,计算每个数据中心的三种归一化可用资源的均衡度:
其中,bl表示第l个数据中心的三种归一化可用资源的均衡度,
按照下式,计算动作空间中可行动作的奖励值:
其中,r表示动作空间中可行动作的奖励值,∑表示求和操作,l表示数据中心集合。
步骤4,训练强化学习任务调度模型。
利用深度q网络方法,对神经网络进行训练,得到训练好的强化学习任务调度模型。
参照附图2,对深度q网络方法的具体步骤做进一步的详细描述。
第1步,从训练数据集中随机选取一个任务资源请求,将所选任务资源请求以及各数据中心的计算资源、内存资源、硬盘存储资源信息输入深度估值神经网络,计算任务资源请求的各个动作的价值;
第2步,从0到1之间随机选取一个小数,若所取小数在0到0.9之间,则选取动作价值最大的动作作为可行动作,若所取小数在0.9到1之间,则随机选取除动作价值最大的动作之外的一个动作作为可行动作;
第3步,根据可行动作对该任务进行调度并根据其资源请求分配相应的资源,用分配后的剩余计算资源、剩余内存资源、剩余硬盘存储资源信息更新下一回合的状态空间;
第4步,将状态空间、可行动作、可行动作的奖励值以及更新后下一回合的状态空间组成经验数据元组,存入经验数据元组集合;
第5步,判断分配后跨数据中心网络的三种剩余资源是否有一种为空,若是,则将训练回合次数加1执行第六步,否则,执行第7步;
第6步,判断训练回合是否达一百万回合,若是,执行第14步,否则,执行第1步;
第7步,在经验数据元组集合中随机选择一个元组;
第8步,将所选经验数据元组中的状态空间送入深度估值神经网络中,计算任务资源需求的动作价值;
第9步,将下一回合状态空间中的任务资源请求以及各数据中心的资源信息,送入深度目标神经网络,计算下一回合状态空间对应动作价值最大的动作;
第10步,通过动作的奖励值、动作价值、下一回合状态空间对应最大的动作价值构造深度估值神经网络的损失函数;
第11步,以减小损失函数值为目标,使用随机梯度下降法更新深度估值神经网络的参数;
第12步,判断训练回合是否为一千的整数倍,若是,执行第13步,否则,执行第一步;
第13步,将深度估值神经网络参数赋给深度目标神经网络,返回第1步;
第14步,得到训练好的强化学习任务调度模型。
步骤5,调度跨数据中心网络中实时到达的任务。
采集跨数据中心网络中实时到达的每一个任务资源请求,用每一个实时到达的任务资源请求更新状态空间中的任务资源请求信息。
将更新后的任务资源请求以及各数据中心的计算资源、内存资源、硬盘存储资源信息,输入到训练好的强化学习任务调度模型中,输出跨数据中心网络的任务调度资源分配向量。
按照任务调度资源分配向量中每个任务对应可行动作的节点序号,将每个任务分配到对应的数据中心。
- 还没有人留言评论。精彩留言会获得点赞!