一种基于词义主题模型的社交网络短文本推荐方法与流程
本发明涉及社交网络推荐技术及短文本特征提取技术领域,尤其涉及一种社交网络短文本推荐方法。
背景技术:
推荐领域中,“推荐系统”是一种基于用户历史数据给不同用户推荐不同内容的系统,诸如文章、好友、商品或广告等。因此,系统往往能有效在指数增长的海量数据中提取出对用户有价值的个性化定制的信息。社交网络的推荐系统大多是基于用户的推荐,而同一用户发布的内容也具有多样性,并非每个内容都是用户所关注的,因此基于文本的推荐可以更好的帮用户筛选其关注的信息,从而实现文章推送、广告等文本信息的精准投放。
推荐系统实现推荐的常用方法包括:
基于人口统计学的推荐:根据系统用户的基本信息发现用户的相关程度,此方法仅考虑了用户基本特征,分类较粗糙;
基于内容的推荐:根据推荐内容的属性特征,发现内容的相关性,该方法基于历史喜好进行推荐,对新用户有冷启动问题;
协同过滤:根据用户对内容的历史偏好数据,发现内容本身的相关性或发现用户的相关性。相关性发现通常采用基于关联规则挖掘或采用机器学习模型来挖掘关联程度。现有专利及文献在社交网络短文本推荐领域的研究通过用户历史数据生成特征向量,以此为特征获取与目标用户具有相似历史行为的用户群。并基于用户最近发表的短文本特征向量进行短文本推荐。主要考虑了用户发表文本的主题相似度、历史发表行为的相似度来获取用户主题偏好从而进行文本推荐。
社交网络由于其具有即时性强、非正式化等特征,其文本的存在形式大多为短文本。如何从短文本中有效提取可用信息是社会网络数据分析及其他类型数据分析必不可少的部分。短文本的主题抽取是获取短文本特征进而进行短文本内容推荐的主要步骤。对于长文本如新闻文本等,因其文本长度较长,更容易提取词频逆词频等词特征,相对容易提取主题特征及标签信息等,从而更容易进行文本推荐。而短文本由于篇幅限制,通常只包含一个主题,特征比较稀疏,并且经常存在一词多义的现象,因此无法用传统的基于词袋的主题模型进行主题抽取。现有专利及文献通过借助外部知识库或长文本来丰富短文本内容,可帮助解决特征稀疏问题,然而外部知识库的引入会增加时间和资源的消耗,外部长文本只有跟短文本主题相符时才能有效扩展短文本内容。丰富短文本词信息的另一个方式就是在词层面丰富词的信息,如引入词义及义原信息。义原是在中文词库hownet中提出的,用来表示词的基本单位,hownet知识库中构建了约2000个词的义原体系,并基于该义原体系累计标注了数十万词汇及词义的语义信息。类似的,英文词库wordnet同样表示了词的近义词、上下词义等关系。词义即用来表示词的多个含义,描述词义的词即类似中文的义原,统称为下义词。现有专利及文献将外部词库融入词表示学习,能够有效提升词向量性能,并且在新词推荐、和词典扩展等任务上,均验证了词库的词义特征与深度学习模型融合的有效性。
在上述现有技术中,社交网络短文本推荐的文本主题方面未考虑短文本的特有特征,从而造成主题特征稀疏和主题建模不准确的问题,并且在推荐方法中没有综合考虑用户之间的关系特征、用户历史偏好数据、用户之间基于基本特征和社交关系的相关性、及特征值随时间演化等多个指标。同时,还没有相关研究将词义及下义词融入到短文本主题抽取及社交网络短文本推荐任务中。
技术实现要素:
为解决上述问题,本发明提供一种基于词义主题模型的社交网络短文本推荐方法,以提高短文本推荐的准确度,解决短文本主题抽取困难的问题。
为实现上述目标,本发明的技术方案是:
一种基于词义主题模型的社交网络短文本推荐方法,包括以下过程:(如图2所示)
步骤一:将词义及下义词信息的基于上下文注意力机制的词表示学习融入社交网络短文本推荐中,以丰富文本的词层面特征;
步骤二:将基于词义表示的狄利克雷多项混合分布短文本主题建模融入社交网络短文本推荐中,以丰富文本层面特征;
步骤三:结合社交网络用户关系,用户相关文本的基于词义表示的短文本主题特征,及用户与文本间的潜在关系特征,对随时间演化的用户潜在兴趣度及倾向度进行建模;
步骤四:通过参数估计方法,预测用户对文本的潜在倾向度,并选取倾向度最大的文本推荐给用户,实现短文本推荐。
步骤一中,基于词义及下义词信息的基于上下文注意力机制的词表示学习构建方法为:对丰富文本词层面特征提出了新的构建词表示学习的方法,对每个目标词融合度量其多个词义、每个词义的下义词的向量表示与上下文对每个词义的注意力权重,对通用文本语料训练多维词向量空间。并对文档中的每个词,采用多个词义向量基于上下文词注意力的加权平均来将词义信息融合到短文本主题建模的词特征中。
步骤二中,基于词义表示的狄利克雷多项混合分布短文本主题建模过程如下:
a):从狄利克雷分布中取样生成文档集合的主题分布θ~dirchlet(α);
b):对每个主题k,从狄利克雷分布中取样生成主题对应的词语分布
c):从主题θi的多项分布中取样生成文档i的主题zi~multinomial(θ);
d):从二项分布中取样生成权重参数hij~binomial(λ);
e):从主题词及词向量分布采样生成文档i的词j
其中α和β均为狄利克雷先验分布的参数,λ是二项分布的参数,θ为文档集合的主题分布,
步骤三中,用户潜在倾向度的计算结合了词表示学习,短文本主题分布、用户的潜在兴趣度等特征。
为表示用户潜在兴趣度u,本发明融入了时间演化特征,考虑用户兴趣随时间变化的特点,引入影响用户在时刻t的潜在兴趣度的两个因素,其一是在时刻t之前与用户具有联系的文本项,其二是与用户具有社交关系的其他用户对该用户的影响值。对于用户间影响值的表示方法,用户之间的关系对其实际兴趣表现如发布的内容起着至关重要的作用;考虑社交网络中广泛存在的好友关系、单向关注关系、共同关注关系及用户关系强度。通过调整参数来平衡不同因素的权重,从而更准确衡量用户间的社交及交互关系。用户关系强度可通过用户的社交关系类型、用户间交互关系、用户历史行为等指标来衡量。如用户交互关系越频繁、用户历史行为越相似,则其关系强度越大。
步骤四中,短文本推荐方法如下:
将用户行为集合,如转发和发布文本集合,及用户社交关系集合作为已知变量,通过步骤二和步骤三的方法学习参数主题分布
与现有技术相比,本发明首次将词义信息融入到短文本主题建模及社交网络短文本推荐任务中,综合考虑社交网络用户社交关系、用户与文本多维关系特征、用户行为的兴趣度及特征随时间演化等指标,从而提高社交网络短文本推荐任务的准确率。
附图说明
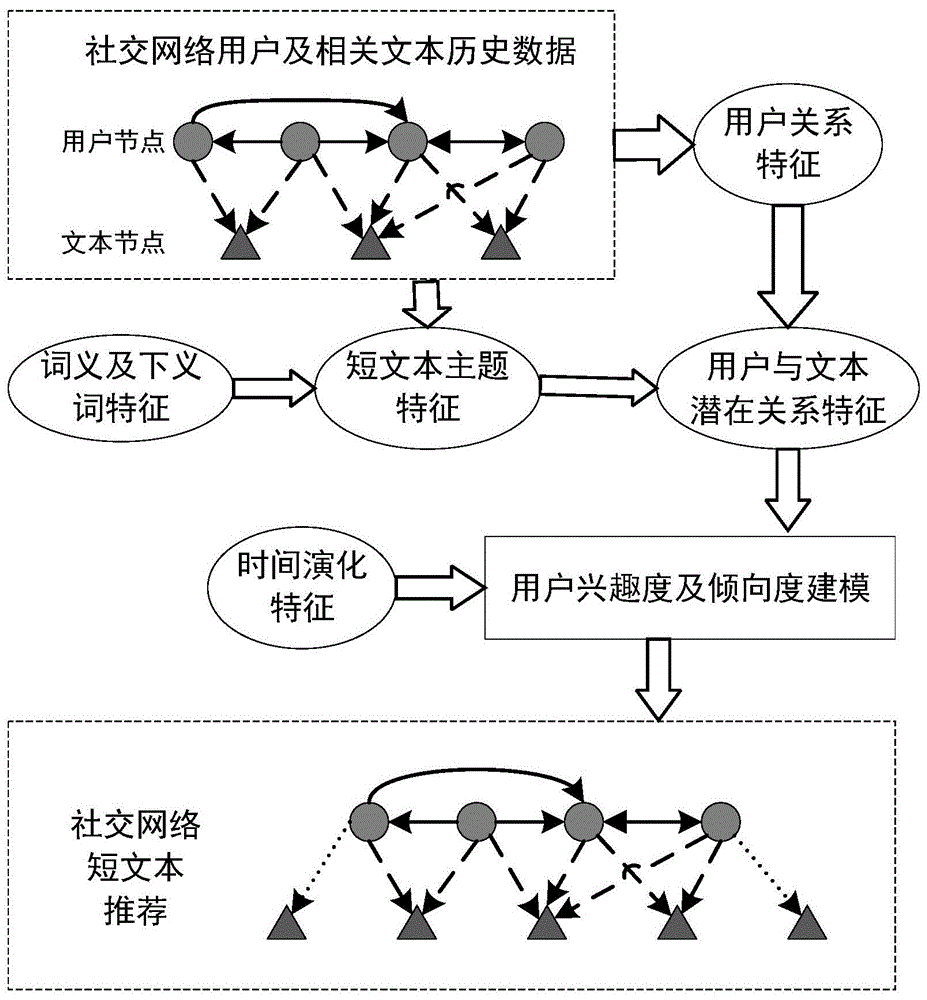
图1是本发明构建的社交网络短文本推荐系统结构图
图2是本发明基于词义主题模型的社交网络短文本推荐方法原理框图
图3是本发明设计基于词义向量的狄利克雷多项混合分布短文本主题建模的算法框图
图4是本发明设计的用户对文本潜在倾向度建模过程中的参数估计流程图
具体实施方式
下面结合附图和具体实施方式对本发明加以说明。应当理解,此处所描述的具体实例仅用以解释本发明,并不用于限定本发明。
本发明提出一种基于词义主题模型的社交网络短文本推荐方法。利用用户在社交网络中发布的文本数据,结合词义向量特征,对文本进行主题建模,根据主题构建兴趣度并对社交用户分配主题标签,根据不同时刻的用户主题标签、用户关系及文本特征构建用户对文本的倾向度模型,从而根据用户在未来时刻对文本倾向度预测值大小对用户进行文本推荐。
如图1所示,将实际社交网络数据表示为用户节点及文本节点关系结构图模型。其中圆形代表的社交节点表示用户,用户关系是连接用户的边,用户关系类型即社交网络中的关注、互相关注等社交关系类型。三角形代表的文本节点表示用户行为的文本对象,如浏览的网址、查看的图片注释、发布的文本、公开的基本信息等。用户与文本关系即连接用户与文本节点的边,类型包括查看、点赞、发布、转发等。
本发明实例中,对照图1的模型,用户关系类型表示关注和互相关注两类关系,用户关系的有向边表示起点用户关注终点用户,为区分两种社交关系,将单向关注命名为关注,将互相关注命名为好友;用户与文本关系类型即用户对文本的操作,如转发、发布等行为,文本节点表示用户相关文本,短文本主题特征表示从文本中提取出来的基于词义的主题标签。根据社交网络历史文本数据,提取文本主题特征标签,并用标签权重表示主题标签对用户及文本间的相关联程度。历史用户关系数据提取每个用户基于社交关系的特征。再结合时间演化特征,构建用户兴趣度及倾向度,从而实现预测下一时刻社交用户节点对哪些文本节点具有连接边。
图2展示了词义主题模型的社交网络短文本推荐方法的流程,现具体描述该方法的各个步骤:
第一步骤:
基于通用语料数据,采用上下文注意力机制,训练基于词义及下义词的向量分布表示空间。由于词向量需要大量的长文本才能训练出有效的向量空间,更好的表示词之间的相似度关系,而社交网络文本较短并且文本非正式,不适合直接拿来作为词向量训练的语料。因此本发明先借助通用中文语料库,如维基百科语料库、搜狗新闻语料库等,提前训练出可用的向量空间,以方便后续社交网络文本的特征抽取步骤。
所述分布表示即将离散特征(如词)表示为连续、稠密的低维度向量表示。向量空间模型将词语表示为一个连续的词向量,并且语义接近的词语对应的词向量在空间上也是接近的。词向量因其能够获取语言中的规律而被广泛使用。基于词的分布表示方法的改进对很多自然语言处理任务产生了显著影响,如加入词义信息,同时考虑短文本词特征较为稀疏的特点,引入词义信息可以帮助丰富词特征。两个不同的词若具有相同或相似的词义也应在向量空间中距离相近。每个词由不同的词义组成,词义又由多个下义词构成。例如,词“苹果”具有两个词义“苹果品牌”及“苹果”,每个词义由下义词来修饰,修饰“苹果品牌”的下义词包括“携带”,“特定牌子”及“电脑”,词义“苹果”的下义词为“水果”。
对目标词ω,其词向量表示为词义向量和词义的注意力的加权值:
其中
选取当前目标词的前后i个词作为上下文,上下文词的均值作为上下文向量特征。每个词义所包含的下义词个数表示为
第二步骤:
作为第二步的预处理步骤,构建社交网络文本数据集,首先指定社交网络,如微博,爬取社交网络数据,包括不同时间段的用户关系网,用户基本信息,用户发布文本,用户转发文本,用户新加关注。
因爬取的数据是非结构化的,因此需要对数据进行预处理。首先对数据根据时间间隔划分,如设置时间间隔为一天或一周。为便于后续的操作,对用户和文本进行编号,不同用户/文本对应唯一的编号。将用户对文本的行为区分为“发布”与“转发”,发布即该用户是文本的原作者。对文本的预处理包括去停用词和分词。短文本因其比较口语化,包含较多的语气词等无意义的词,因此需要剔除,包括标点、链接网址、数字及“的”、“了”、“呢”等停用词。其中将链接网址单独取出存储,以作为该文本的附加内容。对文本的主题提取是基于文本的基本单位即词来进行,因此需要采用分词工具如“jieba分词”对所有文本进行分词处理。
本第二步,在第一步中已经训练好的向量空间的基础上,应用到狄利克雷多项混合分布短文本主题模型中,对预处理后的社交网络文本数据进行主题特征提取。此步骤的输入为图1中的文本节点即文本集,输出主题标签节点、标签权重与标签关系。
狄利克雷多项混合分布主题模型不同于传统主题模型的地方在于传统模型假设一个文档包含多个主题,而狄利克雷多项混合分布假设一个文本只包含一个主题,符合短文本的特征,因而更适合短文本的主题建模。图3展示了基于词义向量的狄利克雷多项混合分布短文本主题建模的算法流程,现具体描述该方法的各个步骤。
a):从狄利克雷分布中取样生成文档集合的主题分布θ~dirchlet(α);
b):对每个主题p,从狄利克雷分布中取样生成主题对应的词语分布
c):从主题θi的多项分布中取样生成文档i的主题zi~multinomial(θ);
d):从二项分布中取样生成权重参数hij~binomial(λ);
e):从主题词及权利要求2所述的词向量分布采样生成文档i的词j
如图3所示,预训练的词向量中词典个数为a,文本个数为m,文本中所包含的词个数为b,主题个数为p。θ是m×p维主题分布向量,其中θi是文档i的主题分布,φ表示p×b维词分布向量,
对于词wi,j的向量表示wi,j,词向量空间中每个词由多个词义向量构成,因此采用词义向量基于上下文词注意力的加权平均来将词义信息融合到主题模型的词特征中。
通过吉布斯采样方法来训练得到主题模型中的参数。首先随机初始化,对数据集中每个文档随机分配一个主题编号;随后重新扫描每个文档,对每个文档按照吉布斯采样方法分配主题,连续迭代直至采样结果收敛。
最终采样结果可以生成文档主题分布及主题词分布参数。文本i具有某个主题的概率pi作为主题标签的权重。取概率最高的或者概率明显高于其他主题的k个主题作为文本i的主题标签节点。
第三步骤:
根据前两步构建好的短文本主题模型,加入社交网络用户关系数据,来对用户与文本间的潜在兴趣倾向关系进行建模。
若用户ui对文本vj在t时刻具有相互关系,则用户对文本表现的潜在倾向度记作
其中
对每个文本项,考虑其主题特征,因此将vj表示为第三步中产生的文本主题分布,即
用户潜在兴趣度u衡量了用户对行为节点表现出行为倾向的程度,即用户对文本的转发或发布感兴趣的程度。为表示用户潜在兴趣度u,考虑用户i在时刻t的潜在兴趣度受两个因素影响,其一是在时刻t之前与用户具有联系的文本项,即用户一般会转发或发布与曾经发布和转发相似的文本内容,其二是与用户具有社交关系的其他用户,用户倾向于受好友或关注的其他用户的影响,从而转发或发布好友所发布的内容。将兴趣度表示为:
其中
对于用户间影响值l的表示方法,用户之间的关系对其实际兴趣表现如发布的内容起着至关重要的作用;考虑社交网络中广泛存在的好友关系、单向关注关系及共同关注关系,因此用户uh对用户ui产生的影响量化为:
其中η为调整参数,用来平衡两个部分的权重;f(uh,ui)是表示用户关系强度的函数,可通过用户的社交关系类型、用户间交互关系、用户历史行为等指标来衡量。如用户交互关系越频繁、用户历史行为越相似,则其关系强度越大。
给定量化后的用户对文本的潜在倾向度集合r及对应的行为节点文本集合d,参数估计的目标是学习参数集合ψ=[u,α,β],其中
p(u,α,β)=p(r|u,v,α,β)p(u)p(v)
最小化上式的对数后验,得到该公式的最小化目标函数。
第四步骤:
通过随机梯度下降和投影梯度下降方法来估计参数集合ψ以实现目标函数最小化。图4描述了参数估计的具体流程。由于基于主题的文本向量vj在第三步已经通过吉布斯采样的方式估计出来,因此无需额外估计该变量。遍历所有用户和时间段,分别固定主题文本向量v及参数α,β用随机梯度下降更新用户潜在兴趣度
第五步骤:
基于前四步的特征量化及参数估计等步骤,学习参数主题分布
采用t+1时刻预测的用户兴趣度
用户对文本项的倾向度最大的k个文本则作为该用户的推荐文本。
为衡量本发明所提出的模型的有效性,其评价方法如下。模型的评价可包含两部分,一是对短文本主题特征抽取的准确性,另一方面是应用在具体的社交网络环境下的文本推荐的精准度。
对短文本主题特征抽取准确性的衡量上。首先在社交网络中基于不同标签进行爬取数据,将标签作为每个短文本的主题特征。如设置20个标签,每个标签分别爬取2万条短文本数据,将所有数据的80%作为训练集来训练主题抽取模型,另外20%作为测试集,隐去标签进行主题预测,对每个文本,将预测出的主题与原标签进行比对,从而衡量主题抽取的准确性。
为衡量社交网络环境下的文本推荐的精准度,通过均方根误差和平方根误差来衡量。令
平方根误差(mae)定义为:
均方根误差和平方根误差越小,则表示模型文本推荐的精准度越高。
- 还没有人留言评论。精彩留言会获得点赞!