基于自适应神经模糊推理系统的光伏阵列故障诊断方法与流程
本发明涉及光伏发电阵列故障检测和分类领域,具体涉及一种基于自适应神经模糊推理系统的光伏阵列故障诊断方法。
背景技术:
随着全球化学能源危机加剧,清洁能源受到广泛的关注,而太阳能由于得天独厚的优势,是清洁能源中非常重要的一员。根据国家统计局报告,2017年,全国发电量6.5万亿千瓦时,比上年增长5.9%。其中,火电增长5.1%,水电增长0.5%,核电增长16.3%,风电增长24.4%,太阳能发电增长57.1%,太阳能的需求日益提高,光伏电站的装机量日益增长。然而,光伏电站由于其户外环境影响,较容易发生故障。如果这些故障不及时发现与排除,将会直接影响光伏发电系统的正常运行,严重时甚至会烧坏电池组件引发火灾。因此,故障诊断对于其提高发电效率,可靠性和安全性是十分有必要的。近年来,国内外学者已经开发了许多方法来检测和分类光伏系统中的故障。在这些方法中,基于智能算法和机器学习的方法受到越来越多的关注。
基于模型仿真的方法通常是创建和光伏阵列等效的电路模型,在模型上测试模型的输出值和实际光伏电站的输出值之间比较差异化,得出故障信息。leianchen等人提出基于未知故障信号的矢量ar模型来诊断光伏故障,该模型需要大量的传感器和开关,在实际应用中存在传感器较多,过于复杂的问题;基于智能算法和机器学习的方法通常是通过提取光伏电站的各项数据通过智能算法计算得出计算结果,从这些结果中分析光伏电站的工作状况。例如,zhenhanyi等人提出了一种基于多分辨率信号分解(mrsd)和模糊推理系统(fis)的故障诊断算法。然而,该算法需要在连续时间内对光伏电站提取数据,数据量大,且故障类型仅有线线故障和接地故障,故障种类较少。近年来,人工神经网络(ann),决策树(dt),支持向量机(svm),基于核函数的极限学习机(kelm),随机森林(rf)是光伏阵列故障诊断的常用分类算法。值得注意的是,目前基于机器学习和智能算法的光伏故障诊断中,算法输入特征都是电流电压温度和辐照度这几个参数之间的变换。
为了提高光伏故障诊断的正确率,增强光伏故障诊断模型的适用范围,本发明提出一种基于自适应神经模糊推理系统的光伏故障诊断方法,通过使用lda对初始数据集进行特征压缩,再利用k折交叉将数据随机分成训练集和测试集以提高模型的泛化能力。用网格分割生成初始模糊推理系统,再用最小二乘法和反向传播调整模型参数,得到最后自适应神经模糊推理系统的光伏诊断模型。提出的自适应神经模糊推理系统故障分类正确率高,诊断效果好。目前,公开发表的文献和专利中尚未发现有基于本方法提出的自适应神经模糊推理系统光伏故障诊断分类模型。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于自适应神经模糊推理系统的光伏阵列故障诊断方法,以克服现有相关技术的缺陷,从而更快速、准确地实现对光伏发电阵列的故障检测和分类。
为实现上述目的,本发明采用如下技术方案:
一种基于自适应神经模糊推理系统的光伏阵列故障诊断方法,包括以下步骤:
步骤s1:采集各种工况条件下的光伏电气特性数据及环境参数,并通过采样滤波处理构成原始故障数据;
步骤s2:从原始故障数据中提取七维的故障特征,得到七维故障样本数据集;
步骤s3:利用线性判别分析算法,对七维故障特征进行降维压缩至三维,得到三维的故障样本数据集;
步骤s4:根据所述步骤s3获得的三维的故障样本数据集,随机分成独立的训练数据集和测试数据集,并设定隶属度函数个数和隶属度函数种类;
步骤s5:根据设定的隶属度函数个数以及隶属度函数种类作为模糊推理系统的初始参数,并根据获得的训练数据集采用网格分割生成初始模糊推理系统;
步骤s6:采用反向传播和最小二乘算法混合神经网络算法训练初始模糊推理系统,使模型输出与训练数据集训练集结果不断逼近,当达到预设条件时训练停止,得到自适应神经网络模糊推理系统模型;
步骤s7:根据所得自适应神经模糊推理系统模型,对所述测试数据集的光伏阵列电压电流辐照度和温度处理后的数据进行检测和分类,判断光伏阵列系统是否处于故障状态;若处于故障状态,则给出故障种类。
进一步的,所述各种工况包括正常工作、线线故障、老化故障、阴影故障和开路故障。
其中,线线故障包括组串级线线故障,即组串中一块或多块组件被短路;阵列级线线故障,即不同组串中电势差为一块或多块组件工作电压的电位点被短路。老化故障包括组串老化和阵列老化;阴影故障,即组串中一块或多块组件发生阴影遮挡;开路故障,即组串中连接线发生意外断路。
进一步的,所述光伏电气特性数据包括光伏阵列的最大功率点电压、光伏组串的最大功率点电流、实时光伏面板温度、实时辐射度。
进一步的,所述采样滤波处理采用基于凯泽窗的有限长单位冲激响应低通滤波器来实现同相位滤波,滤除噪声干扰,平滑测量;所述原始故障特征、新的故障特征和总体故障特征均为平衡数据,即每类特征有相同的样本数。
进一步的,lda降维的过程为:用原始数据经lda算法计算后,剔除类间和类内方差小的数据得到新的降维数据。
1)对步骤s2中故障样本数据建立矩阵a=[x,y],x为7维故障样本数据,y为样本类别,分别以数字1,2,3,4,5,6,7对应本发明所述光伏工况类型,对d(d=1,2,3,4,5,6,7)维数据x按行进行标准化处理;x=[x-min(x)]/[max(x)-min(x)],min(x)为x的最小值,max(x)为x的最大值。
2)对于每一i类别数据,计算数据的均值向量;
3)计算类内离散矩阵
4)计算类间离散矩阵
5)采用fisher判别准则,求使
6)求λ的特征值和对应的特征向量;
7)选取前n个特征值以及对应的特征向量,构造i*n的转换矩阵w;
8)利用转换矩阵将原数据中的x转换成降维后的数据y=x*w。
特征lda降维后分配隶属度函数个数的具体实现方式为:对s4获得的测试集,其前三维特征的输入隶属度函数个数为3,其余输入隶属度函数个数为2。
进一步的,利用网格分割与训练集数据生成初始隶属度函数的形状和值域,为了是输出更准确,模糊规则采用“与”模糊规则,输出为线性函数,具体实施如下:
进一步的,s51:将训练数据集作为输入数据,训练数据集矩阵为[x,y],x为lda降维后的特征数据x1、x2、x3,y为样本分类类别;
s52:使用高斯型隶属度函数将输入数据模糊化,设定x1,x2,x3为输入的数据,y为训练数据集分类结果;
s53:每个输入采用3个隶属度函数,使用网格分割生成初始隶属度函数的形状的过程为:x1,x2,x3的隶属度函数分别为
进一步的,所述步骤s6具体为:
s61:将步骤s53中的模糊化后的数据相乘形成规则的激励强度:wi=μai(x1)*μbi(x2)*μci(x3);
s62:规则激励强度归一化:
s63:设定模糊规则:ifx1isaiandx2isbiandx3iscithenui=pix1+qix2+rix3+si;
s64:计算规则输出:
s65:加权平均去模糊化得出最后结果:
s66:固定(ai、bi、ci、di、ei、fi),用最小二乘法计算(pi、qi、ri、si)的值,计算公式为
s67:利用反向传播计算调整
进一步的,所述总体故障特征数据:
归一化电压
其中,va最大功率点电压;
归一化电流
其中,ia最大功率点电流;
归一化功率
归一化电流电压斜率
归一化辐照度
归一化温度
本发明通过使用lda特征压缩算法对获取到的总体故障特征进行重要性权重排序压缩,减少了模型输入特征的维数,减少了计算量。提出的自适应神经网络模糊推理系统故障诊断训练模型分类准确率较高
附图说明
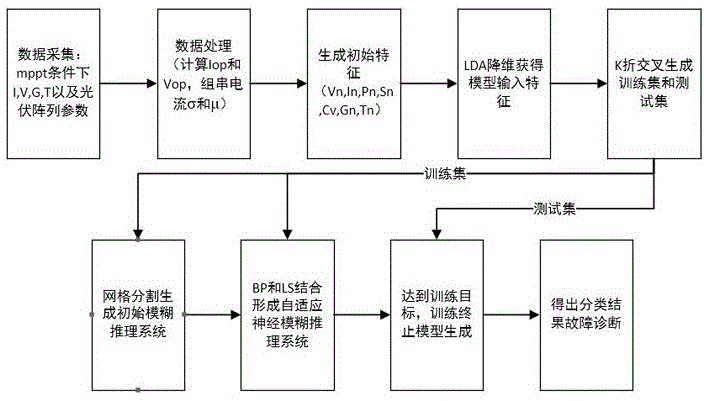
图1为本发明中基于自适应神经网络模糊推理系统的智能光伏阵列故障诊断方法的总体流程图。
图2为本发明一实施例中各种预设故障的原理图。
图3为本发明一实施例中lda特征降维后特征图像。
图4为本发明一实施例中检测分类精度误判图。
图5为本发明一实施例中自适应神经网络模糊推理系统总体分类性能结果图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于自适应神经模糊推理系统的光伏阵列故障诊断方法,包括以下步骤:
步骤s1:采集各种工况条件下的光伏电气特性数据,并通过采样滤波处理构成原始故障数据;所述光伏电气特性数据包括光伏阵列的最大功率点电压、光伏组串的最大功率点电流、实时光伏面板温度、实时辐射度,如表1所示。
表1.光伏阵列的工作参数
步骤s2:将得到的原始故障数据分别进行数据映射运算,得到总体故障特征数据;所述原始故障数据映射计算构成总体故障特征,如表2所示;
表2、光伏阵列的总体特征
步骤s3:利用lda算法对总体故障特征数据进行特征降维压缩至3维,得到新的特征数据;
步骤s4:根据所述步骤s3获得的三维的故障样本数据集,随机分成独立的训练数据集和测试数据集,训练集用于训练建立故障诊断模型,而测试集用于测试故障诊断模型的泛化能力;并设定隶属度函数个数和隶属度函数种类;
步骤s5:根据设定的隶属度函数个数以及隶属度函数种类作为模糊推理系统的初始参数,并根据获得的训练数据集采用网格分割生成初始模糊推理系统;
步骤s6:采用反向传播和最小二乘算法混合神经网络算法训练初始模糊推理系统,使模型输出与训练数据集数据结果不断逼近,当达到预设条件时训练停止,得到自适应神经网络模糊推理系统模型;
步骤s7:对测试数据集进行处理,并根据所得自适应神经网络模糊推理系统模型,对所述测试数据集的光伏阵列电压电流辐照度和温度处理后的数据进行检测和分类,判断光伏阵列系统是否处于故障状态;若处于故障状态,则给出故障种类。
在本实施例中,所述各种工况包括正常工作、线线故障、老化故障、阴影故障和开路故障。
其中,线线故障包括组串级线线故障,即组串中一块或多块组件被短路;阵列级线线故障,即不同组串中电势差为一块或多块组件工作电压的电位点被短路。老化故障包括组串老化和阵列老化;阴影故障,即组串中一块或多块组件发生阴影遮挡;开路故障,即组串中连接线发生意外断路。
在本实施例中,所述采样滤波处理采用基于凯泽窗的有限长单位冲激响应低通滤波器来实现同相位滤波,滤除噪声干扰,平滑测量;所述原始故障特征、新的故障特征和总体故障特征均为平衡数据,即每类特征有相同的样本数。
在本实施例中,lda降维的过程为:用原始数据经lda算法计算后,剔除类间和类内方差小的数据得到新的降维数据。特征lda降维后分配隶属度函数个数的具体实现方式为:对s4获得的测试集,其前三维特征的输入隶属度函数个数为3,其余输入隶属度函数个数为2。
lda降维过程为:
1)对步骤s2中故障样本数据建立矩阵a=[x,y],x为7维故障样本数据,y为样本类别,分别以数字1,2,3,4,5,6,7对应本发明所述光伏工况类型,对d(d=1,2,3,4,5,6,7)维数据x按行进行标准化处理;x=[x-min(x)]/[max(x)-min(x)],min(x)为x的最小值,max(x)为x的最大值。
2)对于每一i类别数据,计算数据的均值向量;
3)计算类内离散矩阵
4)计算类间离散矩阵
5)采用fisher判别准则,求使
6)求λ的特征值和对应的特征向量;
7)选取前n个特征值以及对应的特征向量,构造d*n的转换矩阵w;
8)利用转换矩阵将原数据转换成降维后的数据y=x*w。
在本实施例中,利用网格分割与训练集数据生成初始隶属度函数的形状和值域,为了是输出更准确,模糊规则采用“与”模糊规则,输出为线性函数,具体实施如下:
1)使用高斯型隶属度函数将输入数据模糊化,x1,x2,x3均为输入的数据,y为数据集结果。每个输入采用3个隶属度函数,使用网格分割生成初始隶属度函数的形状的过程为:x1,x2,x3的隶属度函数分别为
2)将步骤1中的模糊化后的数据相乘形成规则的激励强度:wi=μai(x1)*μbi(x2)*μci(x3);
3)规则激励强度归一化:
4)设定模糊规则:ifx1isaiandx2isbiandx3iscithenui=pix1+qix2+rix3+si;
5)计算规则输出:
6)加权平均去模糊化得出最后结果:
7)固定(ai、bi、ci、di、ei、fi),用最小二乘法计算(pi、qi、ri、si)的值,计算公式为
8)利用反向传播计算调整
在本实施例中,所述总体故障特征数据:包括归一化电压
其中,va最大功率点电压;
归一化电流
其中,ia最大功率点电流;
归一化功率
归一化电流电压斜率
归一化辐照度
归一化温度
在本实施例中,每种工况分均在辐照度100-975w/㎡(每25w/㎡取一数据值)和温度25-70℃(每2.5℃取一数据值),进一步的,每种工况数据样本同样均为684组,并以阿拉伯数字1至7标识线线(同组串)一块故障(ll1)、线线(不同组串)两块故障(ll2)、阵列老化4欧故障(s)、组串老化4欧故障(a)、组串阴影故障(p)、开路故障(o)、正常运行(n)共7种工况。lda降维的过程为:用原始数据经lda算法计算后,剔除类间和类内方差小的数据得到新的降维数据。样本中的每组数据为4维,其中1-3维为lda算法压缩后的特征,第4维为类别标识。将上述4维的模型输入特征采用3折交叉随机分成训练集和测试集,用训练集训练模型,用测试集测试模型的分类精度。
在本实施例中,对5折交叉所得训练集,3维数据,每维数据分配3个隶属度函数,采用网格分割生成隶属度函数的初始值和初始形状,采用“与”模糊规则,规则输出为线性函数,生成初始模糊推理系统。再利用最小二乘法计算输出规则输出和训练集结果最小时隶属度函数的值域和形状,并用反向传播不断修正隶属度函数。当训练次数达到或者规则输出和训练集结果的均方根差小于一定值时停止,形成最终自适应神经网络模糊推理系统。用测试集对所述测试样本集进行检测和分类,判断光伏发电阵列系统是否处于故障状态,若处于故障状态,则给出故障类型,并计算其分类精度。
为不失一般性在本实施例中,自适应神经网络模糊推理系统采用20次的独立运行,其20次的分类准确率取均值,每种工况的分类准确率如表2所示;该自适应神经网络模糊推理系统故障诊断训练模型对组串阴影和组串老化的分类准确率较低,可能由于存在数据重叠,导致微弱的错误分类;而对其他工况的分类正确率可达100%。
为了的到稳定可靠的模型,采用5次的5折交叉检验随机生成训练集和测试集,得到5次分类正确率的平均值如表3所示。测试集和训练集的总体分类正确率均在99.6%附近,表明该发明得到的自适应神经网络模糊推理系统光伏故障诊断模型可靠稳定。
在本实例中,在某次检测时当总体检测正确率在99.7%时,如图5所示。有一个阵列老化被错误分到组串老化中,正确为组串阴影的故障有3个样本被错误分到组串老化当中,推测在某些条件下,组串老化和组串阴影具有较相同的电流电压特性,会导致这两种情况分类结果出现混淆。
表3.每种工况的分类结果
表4折交叉检验的分类准确率结果
本方法选择的特征,本身具有很高的可识别性,降维之后,可以使分类过程简单化,可以有效的提升光伏故障诊断的准确率。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!