一种分布式SRAM失效分析方法及系统与流程
本发明是关于半导体设计和生产领域,特别涉及一种分布式sram失效分析方法及系统。
背景技术:
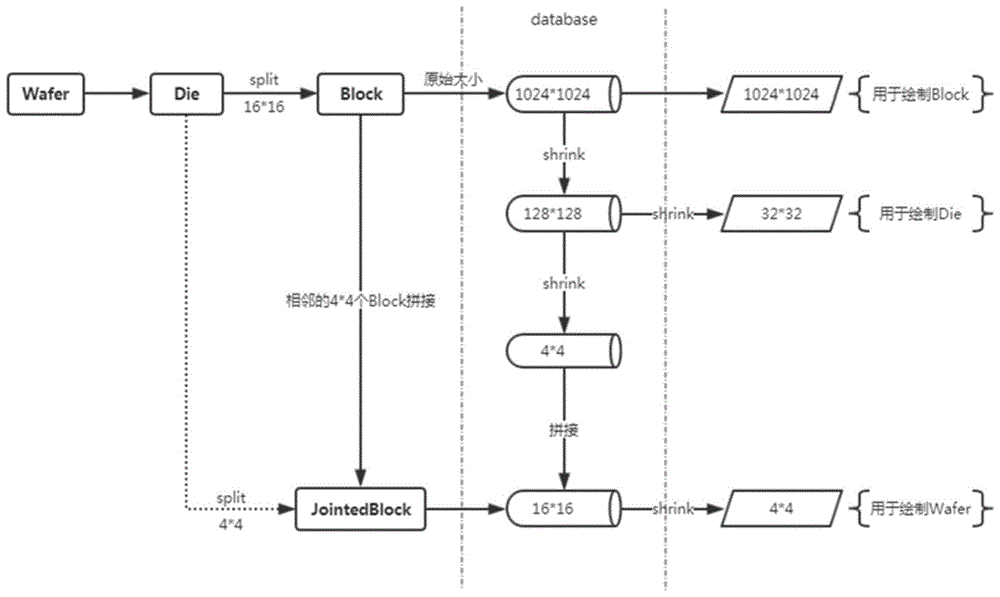
:sram广泛地被大部分晶圆代工厂主要使用,用来作为全新引入工艺的工艺调试以及已经投入实际使用的工艺监控。利用sram的可寻址性,可以比较容易地对失效点进行定位,并通过原子力显微镜探针(afp)、扫描电镜(sem)等物理失效分析手段来确认,分析失效原因,定位到产生失效的工艺步骤并进行改进。随着芯片集成度的不断提高,集成电路的特征尺寸以指数级的速度不断缩小。静态随机存储器(staticrandomaccessmemories)的测试与失效分析占据着越来越重要的位置。一方面,由于sram其高速与低功耗的特点,在集成电路制造与设计进入超大规模后,被越来越多地用于各类数字逻辑产品的缓冲,占据了越来越多的芯片面积。另一方面,对于业界大多数的晶圆代工厂(foundary)来说,sram是一种用以作为全新研发的新工艺调试(processtunning)的测试媒介(testvehicle),或者是作为已经投入实际使用的工艺的工艺监控(processmonitor)。例如intel,其每一代新制程技术的开发与验证都是在一颗基于sram的被称为"x-chip"的芯片上完成的。sram相比其他电路,在满足制程监控,以及逼近工艺与设计规则的极限方面具有独一无二的优势:sram的可寻址性使得从大面积中隔离与分析单个失效点成为可能,再加上sram覆盖面积大,等同于增加了检出失效的几率。随着sram的容量越来越大,在制造过程中产生的测试数据,也在飞速增长。以某先进工艺节点为例,针对一个测试电压,其一个die的测试数据达到5g左右,一片wafer上的数据达到5*150=750g,实际制造中以5个测试电压为例,一片wafer上的数据达到750g*5=3750g。由于在制造过程中会有许多批次,每个批次又会有10-25片wafer,同时可能会对多个生成季度的测试数据做备份。需要存储和备份的数据量将达到pb级别。由于一片wafer上的数据量达到750g,利用常用的分析技术分析其中的失效情况,其处理时间将超过24小时。分析时间太长大大制约的工程师及时发现制造中的问题。此外,由于一片wafer上有大约10亿个像素点,目前的渲染技术,需要用户等待几分钟的时间给工程师的分析也带来诸多不便。技术实现要素:本发明的主要目的在于克服现有技术中的不足,本发明的目的在于提供一种分布式sram失效分析方法,,能有效压缩一片wafer原有的空间占用,并有效减少从数据加载到完成渲染所需时间,并且该方法采用了分布式数据库技术,解决了海量sram测试数据的存储和备份问题,并采用二进制编码方式,大大压缩了数据的存储空间。本发明的目的还在于提供一种分布式sram失效分析系统,该系统用于实现上述分布式sram失效分析方法。为了实现上述的目的,本发明公开了一种用于分布式sram失效分析的数据压缩方法,对原始sram测试数据进行失效分析得到分析结果数据,对于分析结果数据进行压缩处理,具体包括:一种分布式sram失效分析方法,具体包括以下步骤:a、获取sram测试数据结果作为原始数据并对其进行失效分析,得到失效分析结果数据;b、对分析结果数据按预设的二进制编码规则进行二进制编码压缩,并将压缩后的分析结果数据注入分布式数据库中;c、从分布式数据库中提取要进行展示的分析结果数据,根据预设的二进制解码规则对提取的数据进行解码,根据绘制时的分辨率要求,对解码后的分析结果数据按预设的数据采样规则进行采样后,在前端绘制展示;其中,采样包括选取数据及对被选取的数据进行拼接。作为优选,所述预设的二进制编码规则为:分析结果数据中每一个点对应为二进制数据中一个bit,失效点对应的bit设置为1,反之为0。作为优选,所述预设的数据采样规则为:若待采样的数据中有一个是失效点,则采样该失效点。作为优选,步骤a中,对原始数据进行失效分析的方法是:通过遍历方式的模式匹配算法对原始数据中的失效单元进行分类,识别出失效单元的失效模式。作为优选,sram的数据分为三个层级:block、die和wafer,其中,每个die划分为若干block,每片wafer划分为若干die,其特征在于,步骤b中,压缩后注入分布式数据库的分析结果数据包括:block层面的数据、die层面的数据和wafer层面的数据;所述block层面的数据即指二进制编码后的分析结果数据;所述die层面的数据是指:预设绘制die层面分析结果数据时的分辨率要求,先对分析结果数据进行采样,然后再对采样后的分析结果数据进行二进制编码,得到二进制编码后的分析结果数据;所述wafer层面的数据是指:预设绘制wafer层面分析结果数据时的分辨率要求,先对分析结果数据进行采样,然后再对采样后的分析结果数据进行二进制编码,得到二进制编码后的分析结果数据。作为优选,步骤c中从分布式数据库中提取压缩数据的方式为:通过指定wafer,然后根据die坐标、block坐标和测试电压,按需提取分布式存储的block数据。作为优选,所述分布式数据库采用分布式cassandra数据库。本发明还公开了一种分布式sram失效分析系统,该系统用于实现上述分布式sram失效分析方法。作为优选,所述分布式sram失效分析系统包括服务器端和客户端,服务器端用于完成数据提取、失效分析和缩放,客户端用于完成图形渲染;且服务器端和客户端都能与分布式数据库进行交互。作为优选,客户端采用web技术搭建,通过浏览器与分布式数据库中的数据进行交互,客户端与服务端之间通过b/s模式进行交互。与现有技术相比,本发明的分布式sram失效分析方法,对sram的失效分析结果数据采用二进制压缩和采样压缩处理,具有以下优势:1)平均压缩率达到30%,节省了大量存储空间;2)减少了传输负载,大大提高渲染效率,实现了秒级对wafer的渲染;3)提高了数据库的读取性能,大大减少了系统对数据的读取时间,进一步提高了数据分析模块的性能。并且,由于采用了分布式数据库,该技术很好地解决了海量sram测试数据的存储和备份问题。附图说明图1为本发明进行数据压缩的示意图。图2为本发明中die层面的压缩示意图。图3为本发明中wafer层面的压缩示意图。图4为分布式sram失效分析方法的系统架构图。图5为sram测试数据的层级示意图。图6为在一个单节点的cassandra数据库模拟的数据磁盘占用情况。图7为在一个单节点的cassandra数据库模拟的数据磁盘占用情况。图8为数据采样绘制示意图。图9为block层面数据显示效果示意图。图10为wafer层面数据显示效果示意图。图11为die层面数据显示效果示意图。具体实施方式如图5所示,sram的数据分为三个层级:block、die和wafer,每个die划分为若干block,每片wafer划分为若干die,其中的voltage是指测试电压。本发明公开了一种分布式sram失效分析方法,该方法具体包括下述步骤:a、获取sram测试数据结果作为原始数据并对其进行失效分析,得到失效分析结果数据;b、对分析结果数据按预设的二进制编码规则进行二进制编码压缩,并将压缩后的分析结果数据注入分布式数据库中;c、从分布式数据库中提取要进行展示的分析结果数据,根据预设的二进制解码规则对提取的数据进行解码,根据绘制时的分辨率要求,对解码后的分析结果数据按预设的数据采样规则进行采样后,在前端绘制展示;其中,采样包括选取数据及对被选取的数据进行拼接。如图4所示,步骤a可分为两步实现:1)将sram数据解析成block数据片段,注入分布式数据库中,作为原始数据;2)从分布式数据库中提取出原始数据,进行失效分析,得到失效分析后的分析结果数据。对原始数据进行失效分析的方法为:将一片wafer上的数据按die进行划分,并将不同的识别任务分布到集群中的不同cpucore上执行,通过分类器对block中的失效单元进行分类,实现在spark分布式计算框架上对sbit、dbr、dbc、tribit、qbit、adjustbit、sbl、tbl、mbl、swl、twl、mwl等失效类别的识别。例如,于实施例中可以通过java实现遍历方式的patternmatching算法,对block中的失效单元进行分类。步骤b中所述的二进制编码压缩的具体实现方法如下:对分析结果数据进行二进制方式编码,得到二进制编码后的分析结果数据,即block层面的数据,然后存储至分布式数据库中;预设绘制die层面分析结果数据时的分辨率要求,先对分析结果数据进行采样,然后再对采样后的分析结果数据进行二进制方式编码,得到的二进制编码后的分析结果数据,即die层面的数据,然后存储在至分布式数据库中;预设绘制wafer层面分析结果数据时的分辨率要求,先对分析结果数据进行采样,然后再对采样后的分析结果数据进行二进制方式编码,得到的二进制编码后的分析结果数据,即wafer层面的数据,然后存储在至分布式数据库中。通过存储预采样的die层面和wafer层面的数据,当需要提取die层面或者wafer层面的数据进行绘制时:若绘制要求的分辨率即为预设的分辨率,则可在解码后直接用于绘制,节省了进行采样的时间;若绘制要求的分辨率低于预设的分辨率,则可在解码后,根据需求进行再次采样,同样能节省采样时间,因为无需从原始的分析结果数据进行采样,而是直接在预采样后的分析结果数据下进行采样。其中,二进制方式编码是指:分析结果数据中每一个点对应为二进制数据中一个bit,如果一个测试单元失效,那么对应的bit设置为1,反之为0。步骤c中从分布式数据库中进行数据提取的方法是:通过指定wafer,然后根据die坐标、block坐标和测试电压,按需从分布式数据库中提取block数据,即通过wafer的id、die的坐标、block的坐标和测试电压,能确定一个bit的测试结果。数据展示由wafer,die,block三个不同的展示分辨率构成。wafer级别,分辨率最低,用户可以看到wafer上哪些位置存在失效测试单元;die级别,分辨率较高,用户可以看到一个die中哪些位置存在失效单元,并且可以看到失效单元的聚合特性;在block级别,分辨率最高,用户可以通过缩放,遍历到每一个失效单元点。由于分布式数据库中存储的是经过二进制编码后的分析结果,因此,对于从分布式数据库中提取的数据,需要经过解码后才能进行操作。所述采样包括:对数据进行采样处理和对经过采样处理得到的数据进行拼接处理。其中,对数据进行采样处理是指:若待采样的数据中有一个是失效点,则采样该失效点。本申请中的分布式数据库采用分布式cassandra数据库,该分布式的cassandra数据库高效的写入性能,以及支持接入spark,为快速高效的数据分析,提供了数据层的实现,很好地解决了海量sram测试数据的存储和备份问题。下面的实施例可以使本专业的专业技术人员更全面地理解本发明,但不以任何方式限制本发明。实施例1采用图1中所示工艺的sram数据,对用于分布式sram失效分析的数据压缩方法进行具体说明:1)压缩存储:数据库中存储有block层面的数据、die层面的数据和wafer层面的数据。block层面的数据解码后,每个block的分辨率为1024×1024;die层面的数据解码后,每个block的分辨率为128×128;wafer层面的数据解码后,每个block的分辨率为16×16。对于采样中的对采样后的数据进行拼接处理,可参考图1中wafer层面的数据压缩过程:对分析结果数据进行采样,使每个block的分辨率压缩至4×4,然后将相邻的4×4个block进行拼接,得到jointedblock,使每个block(jointedblock)的分辨率为16×16。2)采样绘制:绘制block时,直接提供分辨率为1024×1024的图像。只需取出分布式数据库中,block层面的数据中对应的block,解码后就可用于绘制。绘制die时,每个die被划分为256(16×16)个block,每个block原始分辨率为1024×1024,这远远超过绘制die所需要的精度,同时造成了绘制性能的降低。就算是采用分布式数据库中die层面的数据,仍然超过绘制die所需要的精度。如图2所示,取出分布式数据库中,die层面的数据中对应的die进行解码,每个block的分辨率为128×128;这里我们对解码后的数据采取进一步采样缩图,使每个block的分辨率至32×32,此时,最大能提供分辨率为512×512的die的图像。绘制wafer时,对单个block分辨率的要求进一步降低,而一个die划分为256个block显得过于多了,这造成了绘制wafer时需要索引的数据记录数量过大,带来性能降低。就算是采用分布式数据库中wafer层面的数据,仍然超过绘制wafer所需要的精度。如图3所示,取出分布式数据库中,wafer层面的数据中对应的wafer进行解码,每个block(jointedblock)的分辨率为16×16;这里我们对解码后的数据采取进一步采样缩图,使每个block(jointedblock)的分辨率至4×4,此时,每个die由16个block(jointedblock)组成,在绘制时最大能提供分辨率为64×64的die的图像。实施例2sram测试按照原始block的定义:每个die包含16×16个block,每个block1024×1024;在wafer这一级,一片wafer假设拥有84个die,则包含的block记录数量达到了:84×256×14=301056。这里所乘的14是指测试电压voltage。在为每个线程划分任务时,需要得到对应的所有的failtype,在die一级,只需要遍历3584条记录,而到了wafer这一级,这个数字达到了301056,这导致取这部分数据的耗时大幅提升。实测wafer一级获取所有failtype耗时达到1500ms,占据了后台处理总耗时的70%以上。在wafer这一级,将原始的16(4×4)个block(原始分辨率为1024×1024,存储时压缩至4×4)拼接在一起,得到一个新的jointedblock,其分辨率为16×16,那么每片wafer包含的jointedblock记录数量为:84×256×14/16=18816。对比测试的结果如下表1、表2所示。表1获取die_x所有取值统计表表2获取failtype所有取值统计表failtype与die_x从jointedblock表中取,坐标点数据从原始block表中取。下表3至表4即为具体的wafer绘制耗时测试数据。表3web端(i56200u低压双核四线程@2.3ghz)测试数据表后台总耗时请求总耗时页面加载1655ms1.69s4.32s2588ms1.56s4.45s3613ms1.51s4.14s4638ms1.77s4.26s5597ms1.58s4.08s均值618ms1.62s4.25s表4web端(i78700k标压六核十二线程@3.7ghz)测试数据表后台总耗时请求总耗时页面加载1634ms1.00s2.77s2527ms821ms2.37s3544ms988ms2.56s4552ms903ms2.53s5604ms978ms2.68s均值所有数据均从jointedblock表中获取,下表5至表6即为具体的wafer绘制耗时测试数据,该测试的数据量没有问题,能用于查看性能表现。表5web端(i56200u低压双核四线程@2.3ghz)测试数据表后台总耗时请求总耗时页面加载1144ms1.01s2.92s2126ms942ms3.31s3128ms999ms3.05s4173ms1.05s3.06s5131ms958ms2.97s均值140ms992ms3.06s表6web端(i78700k标压六核十二线程@3.7ghz)测试数据表后台总耗时请求总耗时页面加载1156ms343ms1.52s2150ms405ms1.55s3178ms330ms1.70s4167ms343ms1.56s5134ms300ms1.57s均值157ms344ms1.58s下表7至表8即为具体的die绘制耗时测试数据。表7web端(i56200u低压双核四线程@2.3ghz)测试数据表后台总耗时请求总耗时页面加载1137ms1.14s5.56s2121ms1.24s5.70s3124ms1.12s4.96s4133ms1.18s5.02s5132ms1.20s4.92s均值129ms1.18s5.23s表8web端(i78700k标压六核十二线程@3.7ghz)测试数据表下表11至表12即为具体的die绘制耗时测试数据。表11web端(i56200u低压双核四线程@2.3ghz)测试数据表后台总耗时请求总耗时页面加载146ms657ms2.30s241ms773ms2.10s343ms740ms2.33s445ms708ms2.01s574ms757ms2.20s均值50ms727ms2.19s表12web端(i78700k标压六核十二线程@3.7ghz)测试数据表后台总耗时请求总耗时页面加载137ms251ms1.34s236ms312ms1.33s335ms239ms1.37s435ms355ms1.20s540ms237ms1.17s均值37ms279ms1.28s实施例3存储空间的模拟及模拟存储空间预估:一个block最多需要128k的存储空间,一个die为32mb。在二进制编码基础上,再对二进制数据进行压缩,可以进一步缩小每个die的存储空间。数据分析完成之后,一个die可能有10多种失效类型,未压缩的存储空间会有10*32m的,但分析结果数据较为稀疏,且呈现比较明显的分布特征,所以压缩后,空间站占用原小于这个值。根据实际实验所得,不考虑分析结果的分布特征,那么压缩后的存储空间也不会超过2*32m。根据实际模拟,我们所构建的测试数据,失效率在50%时,空间占用会显著增加,一个die的原始数据和分析数据总占用在33mb左右,而失效率低于40%时,空间占用远小于这个值。模拟内容:解析一片wafer的原始测试数据,并将其注入到数据库中。模拟数据规模:采用失效率为50%左右的测试数据以及其分析结果数据进行测试。原始待解析的文件为每个byte指示每个测试单元失效情况的二进制文件,一个die一个文件,大小为256mb,总共72个die。模拟环境:一台常规配置级别的服务器(64核cpu,128gb内存,5年前10w左右购入)构成的单节点cassandra数据库。模拟结果:耗时25574ms,数据在数据库中总共占用683.62mb;这批数据对应的分析数据注入到数据库中后,磁盘占用为865.87mb;由于模拟数据采用了每一个die均为50%失效率的wafer,实际情况下,空间占用会远小于这个值。具体可参考图6、图7,一个单节点的cassandra数据库模拟的数据磁盘占用情况。实施例4分析模块性能预估对原始数据进行失效分析时,通过java实现遍历方式的patternmatching算法,对1024x1024的block中的失效单元进行分类,能够识别sbit、dbr、dbc、tribit、qbit、adjustbit、sbl、tbl、mbl、swl、twl和mwl。在一个cpu主频为3.7ghz的pc进行测试,每个block的分析时间统计如下表13。表13每个block的分析时间失效率10%20%30%40%50%时间(ms)151159163164178因此在单线程下,一片64个die的wafer的分析时间不到48小时,如果采用48线程并发,能够将时间缩短到1个多小时。考虑到14个测试电压,分析时间能缩短到20小时以内。实施例5数据渲染模拟实验一个die可以看成16384x16384这样的bitmap,而在显示数据分布时,绘制到显示器中的bitmap一般不会超过1024x1024这个物理分辨率。因此,如图8所示,将数据交给图像渲染引擎时,可以将可能重复渲染到物理分辨率上同一个像素点的数据合并,即所述的采样,以减少图形渲染引擎的性能。模拟数据:考虑到渲染压力与失效数目成正相关,所以使用失效率为50%的测试数据进行测试。模拟平台:server端硬件配置为标压8核16线程cpu(i78700k)@3.7ghz,16gb内存的pc;browser端硬件配置为标压8核16线程cpu(i78700k)@3.7ghz,16gb内存的pc、低压双核4线程cpu(i56200u)@2.3ghz,8gb内存的laptop。模拟结果:下表14即为测试从数据加载到完成渲染所需的时间,含server索引处理数据的时间。图9至图11为显示效果示意图。表14测试从数据加载到完成渲染所需的时间由上可知,本发明使用并发充分利用多核cpu的性能,必要时可以接入spark分布式计算框架来利用多机性能,能实现:一片wafer的测试数据解析时间可以降低到1个小时以下;在100ms以下完成显示数据的采样与缩放;将一片wafer,14个测试电压的分析时间缩短到20小时以内。本发明使用cassandra数据库管理数据,能实现:出色的索引特定数据的性能;在高并发数据写入时,保证出色的写入性能;一片wafer原有的16gb空间占用缩小到平均低于1gb的空间占用(包括分析数据)。最后,需要注意的是,以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有很多变形。本领域的普通技术人员能从本发明公开的内容中直接导出或联想到的所有变形,均应认为是本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1