一种电网数据质量分析方法与流程
本发明涉及一种电网数据质量分析方法,属于电网
技术领域:
。
背景技术:
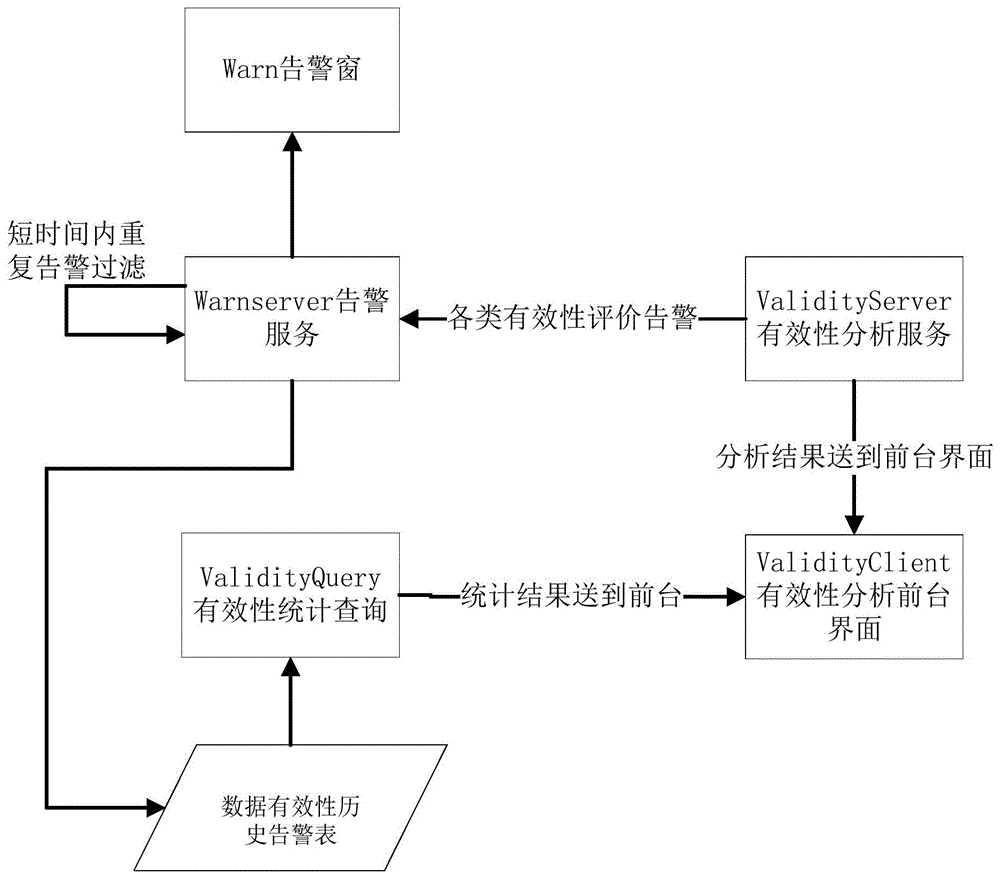
:为实现智能电网调度系统自动化管理,需要获取大量电网数据,根据海量数据获取关联关系,但为提升电网管控水平、消除数据质量缺陷,通常需要对可疑数据进行筛查。目前已有的电网数据质量分析需要依赖人工消除数据质量缺陷,存在工作效率低下、分析结果不够准确的技术问题。技术实现要素:本发明的目的在于克服现有技术中的不足,提供一种电网数据质量分析方法,能够明显降低人工校验的工作量、有助于提高分析结果的准确性。为达到上述目的,本发明是采用下述技术方案实现的:一种电网数据质量分析方法,所述方法包括如下步骤:采集电网调度自动化系统的告警数据及实时三遥数据;对所述告警数据进行频繁无效告警分析、重复告警分析、同一终端异常数量告警分析及遥信变位与soe不匹配分析,过滤输出异常告警数据;将所述实时三遥数据输入训练好的随机森林树模型,筛查输出异常数据。进一步的,频繁无效告警分析的方法包括:对于告警服务端接收到的每条告警信息,若发现在设定的每日时间间隔内已发生同样的告警,那么将该条告警信息存入历史告警表,不发给告警窗;在每月设定的时刻对前一月的告警信息按告警类型进行分类统计,得到前一月各告警类型的告警数量,以及无效重复告警数量;将统计出的前一月同类告警数量与预设的全月同类合理告警数量相比,若比值大于1,则表示前一月该告警类型告警数量异常,向告警服务端发送告警。进一步的,重复告警分析的方法包括:每隔一个周期间隔,从当前时刻向前追溯一个周期间隔内的告警信息是否存在短时间内重复告警,如存在,将该重复告警的发生时段以及发生条数写入今日重复告警记录表,并形成告警发送给告警服务端,告警信息存入相关历史告警表;其中,所述短时间是指不大于2秒的时间。进一步的,同一终端异常数量告警分析的方法包括:每隔一个周期间隔,分析当前时刻向前追溯到今日0时同一终端是否存在重复告警,如存在,将终端信息、发生日期、发生告警的条数写入今日终端告警数量异常表,并形成异常告警信息发送给告警服务端,告警信息存入相关历史告警表。进一步的,每次同一终端异常数量告警分析之前,应先查询当前今日终端告警数量异常表,对于今日已经报警的终端将不再分析。进一步的,遥信变位与soe不匹配分析的方法包括:每隔一个周期间隔,对本地告警表内的遥信变位告警和soe进行匹配分析:若遥信变位告警向后延时t2时段内没有对应soe,或soe向前追溯t2时段内没有对应遥信变位,则认为遥信变位与soe不匹配;将不匹配的遥信变位或soe写入当前遥信变位与soe不匹配信息表,并形成告警发送给告警服务端;其中,t2为用户设定的延时时间。进一步的,每次遥信变位与soe不匹配分析前,应先查询当前遥信变位与soe不匹配信息表,已经分析出来的不匹配信息不再分析。进一步的,训练所述随机森林树模型的方法包括:采集历史三遥数据;对历史三遥数据进行筛查,分为正常数据和异常数据;根据电网数据分析目标的不同维度分别选取正常数据和异常数据的特征信息,构建训练集;采用有监督学习法利用训练集训练由奇数棵决策树构成的随机森林模型。进一步的,对于数据维度,所述特征信息包括:有功值、无功值、电流值、有功变化量、无功变化量、电流变化量、有功变化百分比、无功变化百分比、电流变化百分比;对于设备信息维度,所述特征信息包括:电压等级;对于时间维度,所述特征信息包括:月、星期、秒。进一步的,筛查输出异常数据的方法包括:将实时三遥数据输入训练好的随机森林模型的每一棵决策树,按照如下规则对数据进行判断,满足规则之一标记为异常三遥数据:有功值<-1100kw或有功值>680kw;无功值<-130kvar或无功值>214kvar;电流值<0a或电流值>1130a;abs(有功变化量)>100kw;abs(无功变化量)>100kvar;abs(电流变化量)>100a;abs(有功变化百分比)>3%;abs(无功变化百分比)>3%;abs(电流变化百分比)>3%;对于同一数据,若统计出来的个数中半数以上决策树判定为异常数据,则分析结果即为异常数据,否则为正常数据。与现有技术相比,本发明提供的电网数据质量分析方法,能够实现异常告警数据过滤和可疑量测数据筛查,对可以数据自动化校验和便是提供理论依据,为消除数据质量缺陷降低了人工校验的工作量,有助于提升电网管控水平,提高供电可靠性、供电质量与服务水平。附图说明图1是根据本发明实施例提供的异常告警数据分析的方法流程图;图2是根据本发明实施例提供的异常数据筛查的方法流程图。具体实施方式下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。本发明实施例提供的一种电网数据质量分析方法,包括如下步骤:步骤一:异常告警数据分析。如图1所示,包括如下步骤:(1)对短期频繁无效告警进行过滤对每日设定的时间内(例如凌晨1点钟,可配置)发生了重复的告警进行过滤。告警服务端程序每接收到一条告警信息,会对本地告警表进行查询,若发现在设置时间间隔内已发生同样的告警,那么该条告警只存入历史告警表,而不发给告警窗。每月设定的时刻(例如每月1号凌晨1点钟,可设置)对前一个月的告警按告警类型进行分类统计,得到全月该类型告警的数量,以及其中有多少是无效重复告警。并且将统计出的该类型告警数量与该类型告警数量合理值*本月天数的比值,该比值超出1的表示当月该类型告警数量异常,向高级服务程序warn_server发送告警。(2)对发生的短时间重复告警信息进行分析每隔周期时间t1秒(t1可设置,t1>300秒,间隔时间太短后台服务压力会比较大),后台分析程序对本地告警表进行搜索,分析当前时刻向前追溯t1时间内的告警信息是否存在短时间t2秒(t2可设置,60秒<t2<300秒)内重复告警n次以上(n可设置,n>3)的告警,如存在,将该重复告警信息的发生时间段以及发生条数写入今日重复告警记录表,并形成告警发送给告警服务端程序warn_server,告警信息会存入相关历史告警表。(3)同一终端异常大数量告警分析每隔周期时间t1秒,后台分析程序对本地告警表进行搜索,分析当前时刻向前追溯到今日0时内同一终端发生n次以上的告警,如存在,将终端信息、发生日期、发生告警的条数写入今日终端告警数量异常表,并形成异常告警信息发送给告警服务端程序,告警信息存入相关历史告警表。每次分析之前,会先查询当前终端告警数量异常表,今日已经报警的终端将不在分析。(4)遥信变位与soe不匹配分析每隔周期时间t1秒,服务程序对本地告警表内的变位告警和soe进行匹配分析,遥信变位告警向后延时t2秒内没有对应soe,或soe向前追溯t2秒内没有对应遥信变位,都算作遥信变位与soe不匹配。将不匹配的遥信变位或soe(包括发生时间、相关设备等)写入当前遥信变位与soe不匹配信息表,并形成告警发送给告警服务端。每次分析之前,会先查询当前遥信变位与soe不匹配信息表,已经分析出来的不匹配信息不再分析。步骤二:量测采样可疑数据筛查目标:建立合理模型,对“三遥”历史采样数据挖掘分析,筛查出其中的错误数据。采样数据共1,048,576条,其中标记为正常数据的1,024,968条,占总数的97.749%;异常数据23,608条,占2.251%。在模型训练和评价中,随机选取其中90%作为训练集,10%作为测试集。其方法步骤如下:(1)数据准备a、特征选取,根据分析目标的不同维度选取历史数据如下字段作为特征:数据维度:有功值、无功值、电流值、有功变化量、无功变化量、电流变化量、有功变化百分比、无功变化百分比、电流变化百分比。设备信息维度:电压等级。时间维度:月、星期、当天的秒。b、数据清洗,按特征重新组织数据集。剔除有功值、无功值、电流值有空值的记录。c、数据标记,为实现有监督的机器学习和验证模型正确性,按如下规则对数据进行标记,满足规则之一标记为异常数据。有功值<-1100kw或有功值>680kw,无功值<-130kvar或无功值>214kvar,电流值<0a或电流值>1130a,abs(有功变化量)>100kw,abs(无功变化量)>100kvar,abs(电流变化量)>100a,abs(有功变化百分比)>3%,abs(无功变化百分比)>3%,abs(电流变化百分比)>3%,共获得正常数据1024968条,占97.749%;异常数据23608条,占2.251%。d、训练集生成,将所有源数据随机划分为两部分,其中90%为训练数据,10%为测试数据。(2)分析建模a、随机森林模型随机森林算法是机器学习中一个应用广泛的算法,它可以用来做分类和回归预测。spark从1.2版本引入randomforestmodel,它的底层模型是决策树(decisiontrees)。随机森林由多个决策树构成,相比于单个决策树算法,它分类、预测效果更好,不容易出现过拟合的情况。得到随机森林模型之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行判断,看看这个样本应该属于哪一类,然后看看哪一类被选择最多,就判定这个样本为那一类。b、参数选择与测试结果随机森林模型的参数有决策树棵数numtrees,最大深度maxdepth,最大桶数maxbins,通过调整参数组合,可以获得最优结果。经过多轮测试,取numtrees=4,maxdepth=20,maxbins=96,得到测试集上的混淆矩阵为:表1:初始模型测试结果判别为正常判别为异常正常102297201异常2542214测试结果表明,整体准确度为99.567%,正常数据被分类为异常的概率为1.961%,异常数据被分类为正常的概率为10.292%。这样的结果表明模型具有对正常数据的识别能力,但对异常数据的识别能力不足,需要进一步优化。(3)模型训练在源数据中,正常数据1024968条,占97.749%;异常数据23608,占2.251%。在机器学习领域中这样的数据集被称为unbalanceddata或imbalanceddata,它对所有分类算法(不仅仅是决策树和随机森林)的影响是让分类器偏向数量较多的类别。对unbalanceddata的处理方式一般有三种:对样本数量多的类做下采样(undersampling),对样本数量少的类做上采样(oversampling),使得不同分类的样本数量平衡。设计惩罚因子(costsofmisclassification),一般先取分类的反比例,再细调。用不同分类的准确度的算术平均值代替整体准确度作为模型评价标准(下文称平均准确度)。为保证模型训练正确性,对源数据中正常数据类别的数据做下采样,再与异常数据混合形成数据源。(4)分类样本比例测试考虑到训练样本平衡性问题,对训练集中正常数据类别的数据做下采样,并通过测试发现正负样本比例对模型正确对的影响。在测试中正样本(正常数据)分别取其1%~10%,再与负样本(异常数据)混合形成数据源,对此数据源按90%、10%划分为训练集和测试集,得到以下测试结果(按平均正确率排序,四项正确率均大于99%的标红):表2:优化模型测试结果多次测试经验表明:对正常数据下采样后,使得正常数据和异常数据的数量差减小,可以提高异常数据的准确度。同时,由于下采样选取的比例的较小且具有随机性,没有充分运用数据信息,会造成一定的过拟合。(5)模型优化对有大量样本的分类做下采样,其缺点是没有充分运用所给信息,也会造成一定的过拟合。为了充分利用样本数据,进一步提高正确率,我们希望随机森林中的每一棵决策树的训练集由一部分正常数据和所有异常数据构成。然而spark的randomforestmodel并未提供这样的功能,所以采用训练奇数棵决策树(因为目标是分两类),预测时投票取大多数。测试中,训练了3棵决策树,每棵决策树的训练集由10%的正常数据集和所有异常数据集构成,所以每个训练集中正常数据量约为92000,异常数据为23608。测试集由所有数据构成。参数numclasses=2、maxdepth=20、maxbins=90训练模型,得到测试集上的混淆矩阵为:表3:测试结果判别为正常判别为异常正确率正常1022431253799.752%异常72360199.970%整体正确率:99.757%,平均正确率:99.861%。优化后的模型,在保持了正常数据判断准确性基础上,提升了异常数据判断准确率。通过机器学习建立调度数据的随机森林模型,实现不良数据的快速辨识。经过多次模型训练和优化,数据识别整体正确率可达99.748%,能够达到数据筛查错误甄别的实用效果,提高电网基础数据质量。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1