一种缺失值的确定方法、装置及电子设备与流程
本发明涉及数据处理领域,更具体的说,涉及一种缺失值的确定方法、装置及电子设备。
背景技术:
目前,银行在建立全行客户级的信用凭借模型时,需要对客户的交易数据、资产数据、客户信息等数据进行处理,但是在处理过程中,发现客户的数据存在缺失的问题。
现有技术中,当出现客户的数据缺失问题时,采用人工确定缺失数据的方式,但这样会增加人为干涉,降低数据可靠性。
技术实现要素:
有鉴于此,本发明提供一种缺失值的确定方法、装置及电子设备,以解决采用人工确定缺失数据的方式,增加人为干涉,降低数据可靠性的问题。
为解决上述技术问题,本发明采用了如下技术方案:
一种缺失值的确定方法,包括:
确定存在数据缺失的目标实体的实体向量;所述实体向量为所述目标实体的向量表示;
确定与所述实体向量相似的实体参考向量集合;所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值;
基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
优选地,确定存在数据缺失的目标实体的实体向量,包括:
获取知识图谱;所述知识图谱包括所述目标实体的三元组和多个实体样本的三元组;每一所述三元组包括头实体、尾实体、所述头实体和所述尾实体的事实性关系;
随机设定每一所述三元组的向量组;所述向量组包括所述三元组中的头实体的初始实体向量、尾实体的初始实体向量以及事实性关系对应的向量矩阵;
多次修改每一所述三元组的向量组中的至少一个数据,得到相应的三元组的多个负例向量组;
基于每一所述三元组的向量组和负例向量组,确定存在数据缺失的目标实体的实体向量。
优选地,基于每一所述三元组的向量组和负例向量组,确定存在数据缺失的目标实体的实体向量,包括:
通过初始评分模型确定每一所述三元组的评分值;所述初始评分模型用于计算为每一所述三元组随机设定的向量组的准确度;
基于每一所述三元组的评分值,计算所述初始评分模型的损失值;
判断所述损失值是否小于第二预设数值;
若不小于,调整每一所述三元组的向量组和负例向量组,并返回所述判断所述损失值是否小于第二预设数值这一步骤;
若小于,将所述目标实体的三元组的向量组中对头实体的初始实体向量进行调整后的向量作为所述目标实体的实体向量。
优选地,确定与所述实体向量相似的实体参考向量集合,包括:
依据预设余弦相似度计算公式,计算所述实体向量与每一实体样本的实体向量的相似度;
筛选出相似度大于所述第一预设数值的实体向量,并组成所述实体参考向量集合。
优选地,基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据,包括:
获取所述实体参考向量的业务数据中与所述缺失数据相应的参考数据;
若所述缺失数据为数值型数据,将每一所述实体参考向量对应的参考数据与相应的相似度的乘积之和作为所述目标实体的缺失数据;
若所述缺失数据为类别型数据,将所有的所述实体参考向量对应的参考数据中出现次数最多的参考数据作为所述目标实体的缺失数据。
一种缺失值的确定装置,包括:
向量确定模块,用于确定存在数据缺失的目标实体的实体向量;所述实体向量为所述目标实体的向量表示;
集合确定模块,用于确定与所述实体向量相似的实体参考向量集合;所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值;
数据确定模块,用于基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
优选地,所述向量确定模块包括:
图谱获取子模块,用于获取知识图谱;所述知识图谱包括所述目标实体的三元组和多个实体样本的三元组;每一所述三元组包括头实体、尾实体、所述头实体和所述尾实体的事实性关系;
向量组设定子模块,用于随机设定每一所述三元组的向量组;所述向量组包括所述三元组中的头实体的初始实体向量、尾实体的初始实体向量以及事实性关系对应的向量矩阵;
数据修改子模块,用于多次修改每一所述三元组的向量组中的至少一个数据,得到相应的三元组的多个负例向量组;
向量确定子模块,用于基于每一所述三元组的向量组和负例向量组,确定存在数据缺失的目标实体的实体向量。
优选地,所述向量确定子模块包括:
分值确定单元,用于通过初始评分模型确定每一所述三元组的评分值;所述初始评分模型用于计算为每一所述三元组随机设定的向量组的准确度;
数值计算单元,用于基于每一所述三元组的评分值,计算所述初始评分模型的损失值;
判断单元,用于判断所述损失值是否小于第二预设数值;
调整单元,用于若不小于,调整每一所述三元组的向量组和负例向量组;
所述判断单元,还用于在调整单元调整每一所述三元组的向量组和负例向量组之后,判断所述损失值是否小于第二预设数值;
向量确定单元,用于若小于,将所述目标实体的三元组的向量组中对头实体的初始实体向量进行调整后的向量作为所述目标实体的实体向量。
优选地,所述集合确定模块包括:
相似度计算子模块,用于依据预设余弦相似度计算公式,计算所述实体向量与每一实体样本的实体向量的相似度;
筛选子模块,用于筛选出相似度大于所述第一预设数值的实体向量,并组成所述实体参考向量集合。
优选地,所述数据确定模块包括:
数据获取子模块,用于获取所述实体参考向量的业务数据中与所述缺失数据相应的参考数据;
第一确定子模块,用于若所述缺失数据为数值型数据,将每一所述实体参考向量对应的参考数据与相应的相似度的乘积之和作为所述目标实体的缺失数据;
第二确定子模块,用于若所述缺失数据为类别型数据,将所有的所述实体参考向量对应的参考数据中出现次数最多的参考数据作为所述目标实体的缺失数据。
一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
确定存在数据缺失的目标实体的实体向量;所述实体向量为所述目标实体的向量表示;
确定与所述实体向量相似的实体参考向量集合;所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值;
基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
相较于现有技术,本发明具有以下有益效果:
本发明提供了一种缺失值的确定方法、装置及电子设备,首先确定出与目标实体相似的其他实体,然后采用与存在数据缺失的目标实体相似的其他客户的实体参考向量的业务数据,来确定目标实体的缺失数据,减少由于人工确定缺失数据带来的降低数据可靠性的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种缺失值的确定方法的方法流程图;
图2为本发明实施例提供的另一种缺失值的确定方法的方法流程图;
图3为本发明实施例提供的再一种缺失值的确定方法的方法流程图;
图4为本发明实施例提供的又一种缺失值的确定方法的方法流程图;
图5为本发明实施例提供的第五种缺失值的确定方法的方法流程图;
图6为本发明实施例提供的一种缺失值的确定装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种缺失值的确定方法,该确定方法可以应用于银行系统。
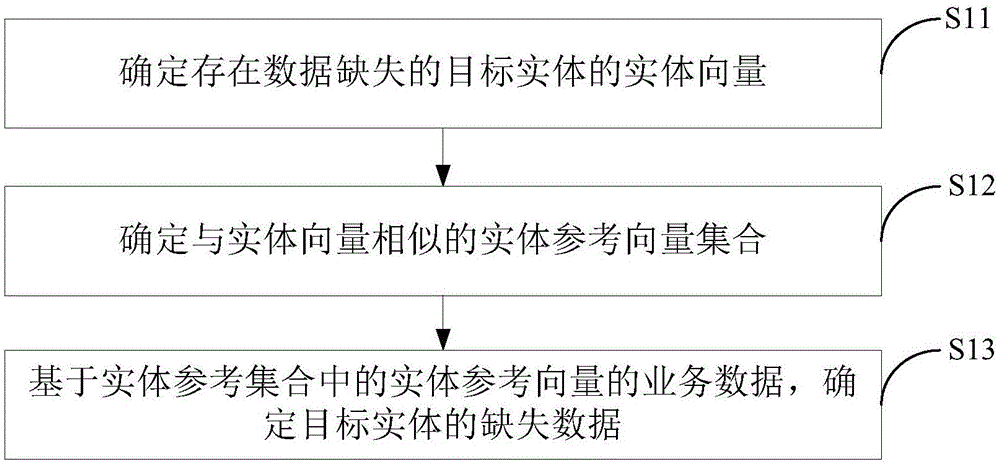
参照图1,缺失值的确定方法可以包括:
s11、确定存在数据缺失的目标实体的实体向量;
所述实体向量为所述目标实体的向量表示。
具体的,目标实体可以为银行的一个客户,如个人a、公司b等。目标实体的实体向量是使用向量表示的方式来描述目标实体。
s12、确定与所述实体向量相似的实体参考向量集合;
所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值。
具体的,由于目标实体的数据存在缺失,进而本发明实施例采用与该目标实体相类似的其他实体的数据来确定出目标实体的缺失数据,进而需要确定出与目标实体相似的其他实体。其他实体通过实体参考向量表示。
s13、基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
具体的,当与目标实体相似的其他实体确定出后,就可以依据其他实体的业务数据,来确定目标实体的缺失数据。
可选的,在本实施例的基础上,参照图2,步骤s13可以包括:
s21、获取所述实体参考向量的业务数据中与所述缺失数据相应的参考数据;
每个实体的业务数据多种多样,此处需要获取与该缺失数据相对应的参考数据。举例来说,假设缺失数据为年龄,则需要获取其他实体的年龄数据。若缺失数据为存款金额,则需要获取其他实体的存款金额数据。
s22、若所述缺失数据为数值型数据,将每一所述实体参考向量对应的参考数据与相应的相似度的乘积之和作为所述目标实体的缺失数据;
其中,数值型数据可以是年龄、存款金额等结果为数值的数据,此时,假设目标实体为客户e,缺失数据为f,则客户e在f上的值填充为:筛选出的相似度大于第一预设数值的实体参考向量对应的参考数据与相似度的加权和,具体如下:
其中,f(e)为缺失数据,c为相似客户,ne为实体参考向量,|ne|表示ne的数目,sim(e,c)表示e与c的相似度,f(c(i))为实体参考向量对应的参考数据。
s23、若所述缺失数据为类别型数据,将所有的所述实体参考向量对应的参考数据中出现次数最多的参考数据作为所述目标实体的缺失数据。
具体的,类别型数据为:表征类型的数据,如性别男女,客户是高级客户、中级客户还是初级客户等。
当缺失数据为类别型数据时,客户e在f上的值填充为:与e最相似的客户ne中,最多数客户在该缺失数据特征上的离散值。
举例来说,假设缺失数据为客户属性,与e最相似的客户中大部分为高级客户,小部分为中级客户,则目标实体的缺失数据也设定为高级客户。
本发明实施例中,首先确定出与目标实体相似的其他实体,然后采用与存在数据缺失的目标实体相似的其他客户的实体参考向量的业务数据,来确定目标实体的缺失数据,减少由于人工确定缺失数据带来的降低数据可靠性的问题。并且,本实施例的缺失值填充方法由系统自动完成,整个过程无需耗费人工检查与编辑,减少了人工干预对模型的影响。
可选的,在上述任一确定方法的实施例的基础上,参照图3,步骤s12可以包括:
s31、获取知识图谱;
所述知识图谱包括所述目标实体的三元组和多个实体样本的三元组;每一所述三元组包括头实体、尾实体、所述头实体和所述尾实体的事实性关系。
具体的,知识图谱描述了现实世界实体与实体之间的关联,在银行行业具有重要的应用场景。知识图谱是以实体为节点,关系为边的有向图。存储的形式为三元组<h,r,t>,其中h、t分别称为头实体和尾实体,r称为事实性关系。三元组表示ht实体之间具有事实性关系r。例如,在知识图谱中,可能存在三元组<李明,公司法人,公司a>,其中“李明”,“公司a”是实体,“公司法人”表示实体之间的事实性关系。这一三元组表示如下事实:李明是公司a的法人。
银行中现存的大量数据可以被构建为银行知识图谱。在银行业务中,数据平台通过建立起识别客户的集团关系、投资关系、担保关系、任职关系、股权关系等的数据知识图谱,达到整合数据,关联起银行内部的、互联网采集的多方数据的作用。
s32、随机设定每一所述三元组的向量组;
所述向量组包括所述三元组中的头实体的初始实体向量、尾实体的初始实体向量以及事实性关系对应的向量矩阵;
具体的,将知识图谱中的每个实体映射为一个d维实数向量;每个事实性关系映射为一个d*d维的实数矩阵,即三元组的向量组中包括两个d维实数向量和一个d*d维的实数矩阵。其中,d维实数向量称为初始实体向量,d*d维的实数矩阵称为事实性关系对应的向量矩阵。
本实施例中,采用随机设定d维实数向量和d*d维的实数矩阵的方式来初始确定每一所述三元组的向量组。后期再对d维实数向量和d*d维的实数矩阵进行适应性调整。
s33、多次修改每一所述三元组的向量组中的至少一个数据,得到相应的三元组的多个负例向量组;
具体的,将知识图谱中存在的三元组随机分成若干批(batch)样本。
对于每一批样本,进行如下操作:
将每批中的每个三元组<h,r,t>作为正例,并为其生成10个负例三元组。生成过程如下:将头实体h或尾实体t随机地替换为知识图谱实体集合中的另一实体,可以得到一个负例三元组。重复上述过程10次,即得到10个负例。将生成负例后的批称为ω。其中,每一负例三元组对应一负例向量组。本实施例中并不限定生成的负例三元组的数量,数量可以根据具体使用场景进行设定。
每一负例三元组对应一负例向量组的确定过程为:
对于ω中的每个负例三元组<h,r,t>,首先找到实体h/t对应的向量h/t,以及事实性关系r对应矩阵r,就可以得到该负例三元组对应的负例向量组。
s34、基于每一所述三元组的向量组和负例向量组,确定存在数据缺失的目标实体的实体向量。
可选的,在本实施例的基础上,参照图4,步骤s34可以包括:
s41、通过初始评分模型确定每一所述三元组的评分值;
所述初始评分模型用于计算为每一所述三元组随机设定的向量组的准确度。
具体的,初始评分模型为rescal评分模型,将每批的三元组输入到rescal评分模型中,即可得到每一三元组的评分值,该评分值表征为每一三元组设定的向量组的准确度。若准确度高,则评分值高,若准确度低,则评分值低。
s42、基于每一所述三元组的评分值,计算所述初始评分模型的损失值;
具体的,根据如下损失函数得到损失值:
其中,θ是待学习的模型参数,即向量组,包括两个d维实数向量和一个d*d维的实数矩阵。λ是l2正则项系数。yhrt∈{-1,1}是三元组的标签。如果<h,r,t>是正例,标签设置为1;负例则设置为-1。
s43、判断所述损失值是否小于第二预设数值;
若不小于,则执行步骤s44,并返回步骤s42;若小于,则执行步骤s45。
s44、调整每一所述三元组的向量组和负例向量组;
s45、将所述目标实体的三元组的向量组中对头实体的初始实体向量进行调整后的向量作为所述目标实体的实体向量。
具体的,根据损失值进行后向传播,得到待学习的模型参数的梯度值。使用adagrad算法利用梯度更新待学习的模型参数的参数值,即更新三元组的向量组,当损失值小于第二预设数值时,停止更新三元组的向量组,并且获取到目标实体对应的三元组的向量组,将向量组中的头实体的向量作为该目标实体的实体向量。
需要说明的是,上述步骤中将三元组进行分批操作,此时在对三元组的向量组进行更新时,也是采用分批操作的方式。
本实施例中,通过采用rescal评分模型评分以及损失值更新的方式来不断调整实体的向量,最终确定得到最符合实体的实体向量。
可选的,在上一实施例的基础上,参照图5,步骤s12可以包括:
s51、依据预设余弦相似度计算公式,计算所述实体向量与每一实体样本的实体向量的相似度;
具体的,本实施例的输入是利用知识图谱计算得到的客户的实体向量表示,输出的是客户在知识图谱上的相似度。
对于带有缺失特征值的客户e,计算e与知识图谱上其他客户c的相似度sim(e,c),作为下一阶段的输入。
形式化地,我们将两者的图相似度定义为两者向量表示e,c的余弦相似度,即:
其中ei表示向量e的第i个元素。
通过上述的余弦相似度计算公式,就可以计算得到实体向量与每一实体样本的实体向量的相似度。
s52、筛选出相似度大于所述第一预设数值的实体向量,并组成所述实体参考向量集合。
本步骤中,设定了第一预设数值,第一预设数值是技术人员根据使用场景进行设定的,当相似度大于第一预设数值时,说明两个客户是相似的进而将相似客户的实体向量组成参考向量集合。
本实施例中,能够利用信息进行数据整合,从知识图谱中自动获取与待补全客户相似的其他客户,进而更精确地填充缺失值。
可选的,在上述缺失值的确定方法的实施例的基础上,本发明的另一实施例提供了一种缺失值的确定装置,参照图6,可以包括:
向量确定模块101,用于确定存在数据缺失的目标实体的实体向量;所述实体向量为所述目标实体的向量表示;
集合确定模块102,用于确定与所述实体向量相似的实体参考向量集合;所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值;
数据确定模块103,用于基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
进一步,所述数据确定模块包括:
数据获取子模块,用于获取所述实体参考向量的业务数据中与所述缺失数据相应的参考数据;
第一确定子模块,用于若所述缺失数据为数值型数据,将每一所述实体参考向量对应的参考数据与相应的相似度的乘积之和作为所述目标实体的缺失数据;
第二确定子模块,用于若所述缺失数据为类别型数据,将所有的所述实体参考向量对应的参考数据中出现次数最多的参考数据作为所述目标实体的缺失数据。
本发明实施例中,首先确定出与目标实体相似的其他实体,然后采用与存在数据缺失的目标实体相似的其他客户的实体参考向量的业务数据,来确定目标实体的缺失数据,减少由于人工确定缺失数据带来的降低数据可靠性的问题。并且,本实施例的缺失值填充方法由系统自动完成,整个过程无需耗费人工检查与编辑,减少了人工干预对模型的影响。
需要说明的是,本实施例中的各个模块和子模块的工作过程,请参照上述实施例中的相应说明,在此不再赘述。
可选的,在上述任一确定装置的实施例的基础上,所述向量确定模块包括:
图谱获取子模块,用于获取知识图谱;所述知识图谱包括所述目标实体的三元组和多个实体样本的三元组;每一所述三元组包括头实体、尾实体、所述头实体和所述尾实体的事实性关系;
向量组设定子模块,用于随机设定每一所述三元组的向量组;所述向量组包括所述三元组中的头实体的初始实体向量、尾实体的初始实体向量以及事实性关系对应的向量矩阵;
数据修改子模块,用于多次修改每一所述三元组的向量组中的至少一个数据,得到相应的三元组的多个负例向量组;
向量确定子模块,用于基于每一所述三元组的向量组和负例向量组,确定存在数据缺失的目标实体的实体向量。
进一步,所述向量确定子模块包括:
分值确定单元,用于通过初始评分模型确定每一所述三元组的评分值;所述初始评分模型用于计算为每一所述三元组随机设定的向量组的准确度;
数值计算单元,用于基于每一所述三元组的评分值,计算所述初始评分模型的损失值;
判断单元,用于判断所述损失值是否小于第二预设数值;
调整单元,用于若不小于,调整每一所述三元组的向量组和负例向量组;
所述判断单元,还用于在调整单元调整每一所述三元组的向量组和负例向量组之后,判断所述损失值是否小于第二预设数值;
向量确定单元,用于若小于,将所述目标实体的三元组的向量组中对头实体的初始实体向量进行调整后的向量作为所述目标实体的实体向量。
本实施例中,通过采用rescal评分模型评分以及损失值更新的方式来不断调整实体的向量,最终确定得到最符合实体的实体向量。
需要说明的是,本实施例中的各个模块、子模块和单元的工作过程,请参照上述实施例中的相应说明,在此不再赘述。
可选的,在上一确定装置的实施例的基础上,所述集合确定模块包括:
相似度计算子模块,用于依据预设余弦相似度计算公式,计算所述实体向量与每一实体样本的实体向量的相似度;
筛选子模块,用于筛选出相似度大于所述第一预设数值的实体向量,并组成所述实体参考向量集合。
本实施例中,能够利用信息进行数据整合,从知识图谱中自动获取与待补全客户相似的其他客户,进而更精确地填充缺失值。
需要说明的是,本实施例中的各个模块和子模块的工作过程,请参照上述实施例中的相应说明,在此不再赘述。
可选的,在上述缺失值的确定方法及装置的实施例的基础上,本发明的另一实施例提供了一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
确定存在数据缺失的目标实体的实体向量;所述实体向量为所述目标实体的向量表示;
确定与所述实体向量相似的实体参考向量集合;所述实体参考向量集合中的实体参考向量与所述实体向量的相似度大于第一预设数值;
基于所述实体参考集合中的实体参考向量的业务数据,确定所述目标实体的缺失数据。
本发明实施例中,首先确定出与目标实体相似的其他实体,然后采用与存在数据缺失的目标实体相似的其他客户的实体参考向量的业务数据,来确定目标实体的缺失数据,减少由于人工确定缺失数据带来的降低数据可靠性的问题。并且,本实施例的缺失值填充方法由系统自动完成,整个过程无需耗费人工检查与编辑,减少了人工干预对模型的影响。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!