人脸表情提取方法、电子设备以及存储介质与流程
本发明涉及人脸识别领域,尤其涉及一种人脸表情提取方法。
背景技术:
目前,真实人脸去懂虚拟形象脸部运动一般采用变形器实现,驱动变形器最重要的一个环节就是提取真实人脸的表情,包括脸部器官的运动和基本情绪表达。现有人脸表情识别方法主要有两种方法:一种是基于整张人脸图像作为输入矩阵,提取其第一特征向量,与表情特征库匹配计算出当前人脸表情;另外也有通过深度学习的方法端到端的输出表情估计。两种方法需要更大的计算能力和存储空间,系统调优也相对困难。这些问题都不利于在移动平台灵活的实现真实人脸驱动虚拟人物表情。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供一种无需过多计算能力,在移动平台即可实现人脸表情识别。
一种人脸表情提取方法,包括以下步骤
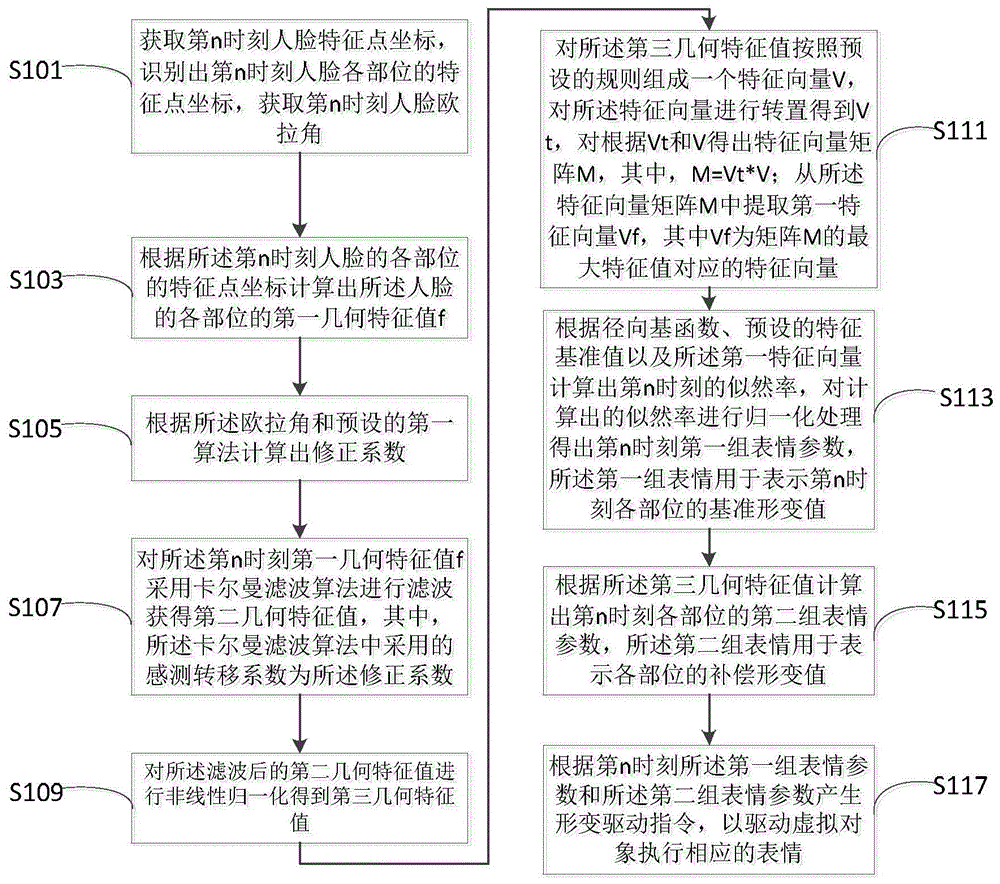
获取第n时刻人脸特征点坐标,识别出第n时刻人脸各部位的特征点坐标,获取第n时刻人脸欧拉角;
根据所述第n时刻人脸的各部位的特征点坐标计算出所述人脸的各部位的第一几何特征值f;
根据所述欧拉角和预设的第一算法计算出修正系数;
对所述第n时刻第一几何特征值f采用卡尔曼滤波算法进行滤波获得第二几何特征值;
对所述滤波后的第二几何特征值进行非线性归一化得到第三几何特征值;
对所述第三几何特征值按照预设的规则组成一个特征向量v,对所述特征向量进行转置得到vt,对根据vt和v得出特征向量矩阵m,其中,m=vt*v;从所述特征向量矩阵m中提取第一特征向量vf,其中vf为矩阵m的最大特征值对应的特征向量;
根据径向基函数、预设的特征基准值以及所述第一特征向量计算出第n时刻的似然率,对计算出的似然率进行归一化处理得出第n时刻第一组表情驱动指令;
根据所述第二几何特征值计算出第n时刻各部位的第二组表情参数,通过对第二组表情参数做非线性化处理,获得第二组表情驱动指令;
根据第n时刻所述第一组表情驱动指令和所述第二组表情驱动指令,以驱动虚拟对象执行相应的表情。
进一步地,述根据所述欧拉角和预设的第一算法计算出修正系数,具体根据以下第一算法公式算得,
y(pitch)=a1×pitch+b1;
y(yaw)=a2×yaw+b2;
y(roll)=a3×roll+b3;
y=y(pitch)×y(yaw)×y(roll);
其中pitch,yaw,roll为欧拉角向量中的参数[pitch,yaw,roll],其中y为修正系数,参数[a1,b1,a2,b2,a3,b3]为人脸数据线性回归统计计算得到,人脸各部位的均有一组对应特定的参数;y(pitch)为头部俯仰时对几何特征的影响系数,y(yaw)为头部旋转时对几何特征的影响系数,y(roll)为头部左右摇摆时对几何特征的影响系数。
进一步地,所述对所述第一几何特征值采用卡尔曼滤波算法进行滤波获得第二几何特征值,所述方法还包括,
根据前两个时刻的第二几何特征进行先验估计;
将当前人脸状态第一几何特征值结合所述修正系数与先验估计进行卡尔曼增益计算得到当前人脸状态第二几何特征值。
进一步地,所述先验估计根据以下公式算得,
ypir(n)=ypost(n-1)+(ypost(n-1)-ypost(n-2))
其中ypir(n)为所述第n时刻人脸特征值进行先验估计得到结果,所述ypir(n)为前两个时刻人脸所述第二几何特征值之差。
进一步地,所述将第一几何特征值结合所述修正系数与先验估计进行卡尔曼增益计算得到第二几何特征值,根据以下公式算得第二几何特征值,
k(n)=y(n)×p(n)÷(y2×p(n)+nobv)
p(n)=(1.0+d(n)÷ypost(n-1))2×(1.0-k(n-1)×y(n-1)×p(n-1)+npro
ypost(n)=ypir(n)+k(n)×(f-y(n)×ypir(n));
ypost(n)为第n时刻识别的人脸特征值经过卡尔曼滤波得到的第二几何特征值;k(n)为n时刻的卡尔曼增益,p(n)为n时刻的自相关先验;npro表示过程噪声,nobv表示观测噪声。
进一步地,所述对所述第三几何特征值按照预设的规则组成一个特征向量v,人脸各部位的第二几何特征值按排列顺序组成特征向量v。
进一步地,所述排列顺序为人脸的眼睛、嘴部、轮廓的所述第二几何特征,按顺序组合为所述特征向量v。
进一步地,根据径向基函数、预设的特征基准值以及所述第一特征向量计算出似然率,具体根据以下公式计算,
rbf(c(i),vf)
其中rbf为径向基函数,c(i)表示所述预设的特征基准值,所述预设的特征基准值为径向基函数中心,其中i=1,2,3,4,5,6,依次带入,得到值分别代表平静,高兴,惊讶,恐惧,发怒,沮丧表情的近似程度。
一种电子设备,包括存储器、处理器以及存储在存储器中的程序,所述程序被配置成由处理器执行,处理器执行所述程序时实现上述中任一项所述的人脸表情提取方法的步骤。
一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述中任一项所述的人脸表情提取方法。
相比现有技术,本发明的有益效果在于:基于人脸特征点的定位,并且通过大量数据统计人脸非正对镜头的情况的下的参数,再经过滤波,使人脸表情的识别更快速更准确,并且相对现有的技术,对计算能力要求更低,需要的存储空间更小,能够适用于移动平台灵活的实现真实人脸驱动虚拟人物。
附图说明
图1为本发明的一种人脸表情提取方法实施例的流程示意图;
图2为本发明的部分人脸特征点示意图;
图3为本发明实施例的电子设备的结构示意图;
图4为本发明实施例的存储介质的结构示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
请参看图1,图1是本发发明提供的一种基于人脸特征点的表情提取方法的流程示意图。本发明可通过计算得到修正系数,再通过卡尔曼滤波进行图像滤波得到更准确的人脸表情特征值,进而提取的表情更准确生动。该方法的步骤包括:
步骤s101:获取第n时刻人脸特征点坐标,识别出第n时刻人脸各部位的特征点坐标;获取第n时刻人脸的欧拉角;
以图2人脸的部分人脸特征点示意图为例,通过影像获取设备,进行人脸录入。影像获取设备可以是摄像机或者智能手机的摄像头。并通过计算机程序可识别出人脸的特征点坐标,并将特征点进行分组,分为左眼、右眼、左边眉毛、右边眉毛、鼻子、嘴部、轮廓部分。通过上述影像获取设备获取人脸的欧拉角。其中人脸的欧拉角{pitch,yaw,roll},其中pitch表示人脸俯仰角,yaw表示人脸偏航角,roll表示人脸滚转角。
步骤s103:根据所述第n时刻人脸的各部位的特征点坐标计算出所述人脸的各部位的第一几何特征值f;
通过识别出的人脸特征点坐标,计算出第n时刻人脸各个部分的第一几何特征值,如眼部的第一几何特征值包括,眼角距离,上下眼睑距离,瞳孔与眼角距离,左眼睑右眼睑距离的。眉毛需要计算眉尖与眼角距离,眉毛与眼睑距离等;嘴部计算嘴角距离,上下嘴唇距离,嘴唇厚度比,左右嘴角与鼻尖-嘴中心轴线距离比等;脸部轮廓提取脸部圆度,颧骨宽度与腮部宽度比,左右腮部轮廓与鼻尖-嘴中心轴线距离比等。
步骤s105:根据所述欧拉角和预设的第一算法计算出修正系数;
因为人脸朝向的改变,相同的人脸表情,影像获取设备获取的人脸第一几何特征的数值存在严重的失真,通过欧拉角和第一算法可修正系数的计算,可估算在欧拉角{pitch,yaw,roll}的作用下,第一几何特征值的失真程度。其中,第一算法为
y(pitch)=a1×pitch+b1;
y(yaw)=a2×yaw+b2;
y(roll)=a3×roll+b3;
y=y(pitch)×y(yaw)×y(roll);
y为计算得出的修正系数,为上述算得的第一几何特征值的失真程度,或称畸变程度。y(pitch)指头部俯仰时对人脸几何特征的影响系数。例如,眼睛上下眼皮的距离的第一几何特征值,在正对影像获取设备和抬头对着影像获取设备时,映射在显示器上显示的平面图的上下眼皮的距离不一样,抬头时候上下眼皮的距离更小,此时y(pitch)表示上下眼皮变小的程度。y(yaw)代表侧脸对人脸几何特征的影响系数。y(roll)代表头部侧方向摆动时对人脸几何特征的影响系数。
其中a1,b1,a2,b2,a3,b3为上述第一算法的参数,其中每个脸部的第一几何特征值均有一组参数,该参数通过大量真实获取的人脸数据线性回归计算得到。具体的,数据采集方法为,找到不同人脸,通过对数据收集镜头做一组表情,然后晃动头部做一组制定的表情。记录下每个时间点的欧拉角以及人脸特定的第一人脸几何特征值。计算非正对镜头时在每个欧拉角下第一几何特征与正对镜头时的第一几何特征的比值,通过该比值和欧拉角数据就可拟合出比值和欧拉角的线性关系。通过大量数据计算,即得到不同欧拉角下的脸部的第一几何特征的参数{a1,b1,a2,b2,a3,b3}。
步骤s107:对所述第一几何特征值采用卡尔曼滤波算法进行滤波获得第二几何特征值,
其中,所述修正系数为所述卡尔曼滤波算法中采用的感测转移系数。
人脸特征点坐标识别和欧拉角估计存在噪声和失真,需要对第一几何特征值做卡尔曼滤波处理。其中,卡尔曼滤波还包括先验估计,先验估计的公式为,
ypir(n)=ypost(n-1)+(ypost(n-1)-ypost(n-2))
ypir值是滤波器通过之前的数据估计出来的经验数据,ypost是经验数据结合观测数据得出的最终估计,具体的,为经过卡尔曼滤波得到的估计值。经验数据的获取唯一的途径就是通过以往的最终估计计算,因为表情提取的人脸为处于运动状态的表情,因此,需要用以往的提取表情的特征值估计计算出运动速度,以往的运动速度可以通过前两个时间段的两个运动状态相减,然后除以前两个时间段的时间间隔获得。运动速度乘以运动时间得到运动量。算得,经验经验估计运动量的方法就是前两个时刻运动状态之差加上上一时刻的运动状态的最终估计。可以理解的,运动状态ypost(n-1)、ypost(n-2)就是前两时刻表情的滤波结果。其中n表示第n个时刻的数据,n-1表示第n-1个时刻的数据,通过第n-1时刻和第n-2时刻的估算出第n时刻的先验值。在下文出现的公式n同样表示第n时刻、n-1表示第n-1个时刻的数据。
卡尔曼增益计算公式如下:
k(n)=y(n)×p(n)÷(y2×p(n)+nobv)
p(n)=(1.0+d(n)÷ypost(n-1))2×(1.0-k(n-1)×y(n-1)×p(n-1)+npro
ypost(n)=ypir(n)+k(n)×(f-y(n)×ypir(n));
其中d(n)=(ypost(n-1)-ypost(n-2),p(n)表示n时刻的自相关先验,相当于对先验估计值的能量估计,通过第n-1时刻的滤波值和修正系数等一系列计算估计得到自相关先验,用于在提高进行卡尔曼增益计算过程提高先验估计值可信度。卡尔曼增益k(n)根据先验值能力和观测噪声能量对比计算出。计算nobv观测噪声表示由于摄像头分辨率限制和人脸特征点标记算法不稳定等造成了第一几何特征值与实际的误差,npro过程噪声表示估计误差。这两个值均根据数据统计制定的定值。ypost(n)为输出结果得到的第二几何特征值。
步骤s109:对所述滤波后的第二几何特征值进行非线性归一化得到第三几何特征值;
步骤s111:对所述第三几何特征值按照预设的规则组成一个特征向量v,对所述特征向量进行转置得到vt,对根据vt和v得出特征向量矩阵m,其中,m=vt*v;从所述特征向量矩阵m中提取第一特征向量vf,其中vf为矩阵m的最大特征值对应的特征向量。
本实施例中,预设的规则为眼睛、嘴部、轮廓的第三几何特征值按照眼睛-嘴部-轮廓的顺序组合排列成特征向量v。特征向量v进行转置得到向量vt。
步骤s113:根据径向基函数、预设的特征基准值以及所述第一特征向量计算出第n时刻的似然率,对计算出的似然率进行归一化处理得出第n时刻第一组表情驱动指令;
提取的第一特征向量vf带入径向基函数,其中径向基函数由rbf表示,具体公式为:
rbf(c(i),vf)
径向基函数可以是高斯函数、多二次函数、逆二次函数等。本实施例中,采用高斯函数进行计算。c(i)表示特征基准值,是径向基函数中心,即通过大量真实人脸获取到6个基本表情的均值。i=1,2,3,4,5,6依次代入径向基函数,得到似然率向量<lr(i)>,其中向量中<lr(1),lr(2),lr(3),lr(4),lr(5),lr(6)>分别表示平静,高兴,惊讶,恐惧,发怒,沮丧表情概率的可能性。将似然率向量<lr(i)>进行归一化,得到第n时刻的第一组表情驱动指令,用于表示人脸的基本表情为平静,高兴,惊讶,恐惧,发怒,沮丧六个基本情绪中的一个。
步骤s115:根据所述第二几何特征值计算出第n时刻各部位的第二组表情参数,通过对第二组表情参数做非线性化处理,获得第二组表情驱动指令。
第一表情驱动指令确定基本表情情绪,但表情表达不够充分,无法充分表达情绪的程度,根据经过滤波处理的第二几何特征值计算各部位的第二组表情参数,表示表情的程度,具体的,通过第二几何特征值的简单计算得到,如眼睛开合程度通过眼睑距离的第二几何特征除以眼角距离第二几何特征算得;嘴开合程度通过嘴唇距离的第二几何特征值除以嘴角距离的第二几何特征值算得。通过对第二组表情参数作非线归一化处理,获得第二组表情驱动指令。增强人物的表情表达,使表情表达更加形象。
步骤s117:根据第n时刻所述第一组表情驱动指令和所述第二组表情驱动指令,以驱动虚拟对象执行相应的表情。
上述的发明方法基于人脸特征点的定位,并且通过大量数据统计人脸非正对镜头的情况的下的参数,且通过卡尔曼增益修正,能够使表情提取更加准确。并且先通过第一表情组驱动指令进行基本表情的确认,在通过第二表情组驱动指令深化表情程度,使表情更加生动,让人脸表情识别更快,更准确。对计算能力要求更低,需要的存储空间更小,能够适用于移动平台灵活的实现真实人脸驱动虚拟人物。
请参看图3,图3为电子设备的结构示意图,本发明实施例提供的电子设备300包括:存储器301以及处理器302,存储器301用于存储计算机程序,该计算机程序被处理器执行时实现上述的人脸表情提取方法。其中,电子设备可以是,个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器装置、包括以上任何装置或设备的分布式计算环境等等。
本实施例中的移动终端与前述实施例中的方法是基于同一发明构思下的两个方面,在前面已经对方法实施过程作了详细的描述,所以本领域技术人员可根据前述描述清楚地了解本实施例中的移动终端的实施过程,为了说明书的简洁,在此就不再赘述。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来。如图4所示的存储介质示意图,本发明还涉及一种存储介质,如rom/ram、磁碟、光盘等,其上存储有计算机程序,计算机程序被处理器执行时实现上述的方法。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!