一种数据存储系统中的数据缓存方法与流程
本发明涉及数据存储领域,尤其涉及一种数据存储系统中的数据缓存方法。
背景技术:
缓存是数据存储系统中提升读写性能的重要途经,将经常访问的数据保存于数据存储系统的内存中,当访问数据时,如果已经位于内存中,则不需要访问硬盘,由于内存读写性能高于机械硬盘,从而提高数据读写的性能。在现有的数据存储系统中,普遍根据数据访问的频率缓存数据。例如,在linux操作系统中广泛使用的ext4、xfs文件系统,windows平台使用的ntfs文件系统,都是综合考虑数据访问的频率和时间,将最近一段时间内访问过,且访问频率最高的数据缓存到内存中。将数据缓存到内存中的方式虽然提高数据读写性能,但是会影响数据的可靠性。由于写入的数据保存于内存中,如果发生硬件故障导致存储设备重启或者断电时,则保存在内存中的数据则会丢失。
为了解决断电后内存数据丢失问题,一些存储系统中加入了大容量电池,当发生断电时由存储设备自带的电池提供电源,把缓存中的数据写入到硬盘中,从而避免数据丢失。但是这种方法提高了产品的成本,电池需要定期检查和更新,也增加了运维的复杂度。另外一些存储系统,包括netapp的wafl文件系统[netapp(filesystemdesignforannfsfileserverappliance(wafl)]、开源软件分布式存储系统ceph[ceph:reliable,scalable,andhigh-performancedistributedstorage],需要使用特殊的存储器件,例如高性能的pcie接口固态盘(ssd:solidstatedisk)作为写缓存设备。当写入数据时,首先写入到ssd盘,然后以后台运行方式,定期将ssd的数据写入到硬盘中。此方法可以提高存储系统的随机写性能,但增加了存储系统的成本;由于所有数据都要首先写入ssd,会影响ssd的使用寿命;在持续大流量写入时,会降低写入性能。
技术实现要素:
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种数据存储系统中的数据缓存方法,读缓存和写缓存分开管理,将内存主要作用于读缓存,仅使用少量内存作用于写缓存;或者不使用写缓存,将写数据立即写入硬盘,因此能够兼容数据存储系统的性能和可靠性,减小数据存储系统的结构复杂度,提高重负载写入时的性能。
本发明提供一种数据存储系统中的数据缓存方法,读缓存和写缓存分开管理,读缓存区分配大比例的内存,写缓存区分配小比例的内存,读缓存和写缓存的索引,以<inode,offset,fsid>或<inode,fsid>为索引主键,对写缓存的容量大小和缓存时间进行精确的控制。
进一步的,当读缓存和写缓存的文件为小文件时,将文件缓存到内存中,缓存的索引主键为<inode,fsid>;当读缓存和写缓存的文件为大文件时,将文件划分为固定大小的数据块缓存到内存中,缓存的牵引主键为<inode,offset,fsid>,其中,inode为文件的索引节点号,offset为读写偏移量,fsid为文件系统id。
进一步的,读缓存步骤具体如下:
步骤1:应用程序调用open()函数来打开文件,输入参数为文件名,读写模式;
步骤2:应用程序调用read()函数来执行读操作,输入参数为文件描述符fd,接收数据的内存地址和长度;
步骤3:根据文件描述符fd获取文件inode,文件系统fsid;
步骤4:根据<inode,fsid>查找读缓存区;
步骤5:如果命中,则将读缓存区中的数据拷贝到接收内存中,将读缓存区的访问次数加1;结束返回;
步骤6:如果未命中,则根据<inode,fsid>查找写缓存区;
步骤7:如果写缓存区命中,则将写缓存区中的数据拷贝到接收内存中,结束返回;
步骤8:尝试分配读缓存区,如果有空闲缓存区,跳转到步骤10;
步骤9:如果无空闲缓存区,则随机选择一组已分配的读缓存区,根据访问次数排序,回收访问次数最少的读缓存区;
步骤10:启动异步读,将文件数据读取到读缓存区中;
步骤11:将数据读缓存区中的数据拷贝到接收内存;
步骤12:结束返回。
进一步的,写缓存步骤具体如下:
s1:应用程序调用open()函数来打开文件,输入参数为文件名,读写模式;
s2:应用程序调用write()函数来执行写操作,输入参数为文件描述fd,写入数据的内存地址和长度;
s3:根据文件描述符fd获取文件inode,文件系统fsid;
s4:根据<inode,fsid>查找写缓存区;
s5:如果命中,跳转到s6,否则跳转到s10;
s6:将写入数据拷贝到写缓存区中;
s7:检查该缓存区状态,如果为clean,则将数据写入时间更新为当前时间,结束返回;否则继续s8;
s8:检查该文件数据缓存时间,如果未超过阈值则返回,否则继续s9;
s9:如果超过阈值,则启动异步写,将该缓存区的数据写入到对应的硬盘中,并将缓存区状态修改为clean;结束返回;
s10:如果未命中,则根据<inode,fsid>随机选组一组缓存区,检查是否有状态为clean的缓存区,如成功则根据访问次数排序,选择回收访问次数最少的缓存区,将写入数据拷贝到写缓存区中,将数据写入时间更新为当前时间,结束返回;
s11:选择写入时间最早的缓存区,将数据以同步方式写入到硬盘中,回收该缓存区;
s12:将写入数据拷贝到写缓存区中,将数据写入时间更新为当前时间;
s13:结束返回。
如上所述,本发明的一种数据存储系统中的数据缓存方法,具有以下有益效果:读缓存和写缓存分开管理,将内存主要作用于读缓存,仅使用少量内存作用于写缓存;或者不使用写缓存,将写数据立即写入硬盘,因此能够对写缓存进行精确的数据量和缓存时间的控制,兼容数据存储系统的性能和可靠性,减小数据存储系统的结构复杂度,提高重负载写入时的性能。
附图说明
图1显示为本发明实施例中公开的数据存储系统结构示意图;
图2显示为本发明实施例中公开的软件模块结构示意图;
图3显示为本发明实施例中公开的读缓存区结构示意图;
图4显示为本发明实施例中公开的写缓存区结构示意图;
图5显示为本发明实施例中公开的读缓存流程图;
图6显示为本发明实施例中公开的写缓存流程图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
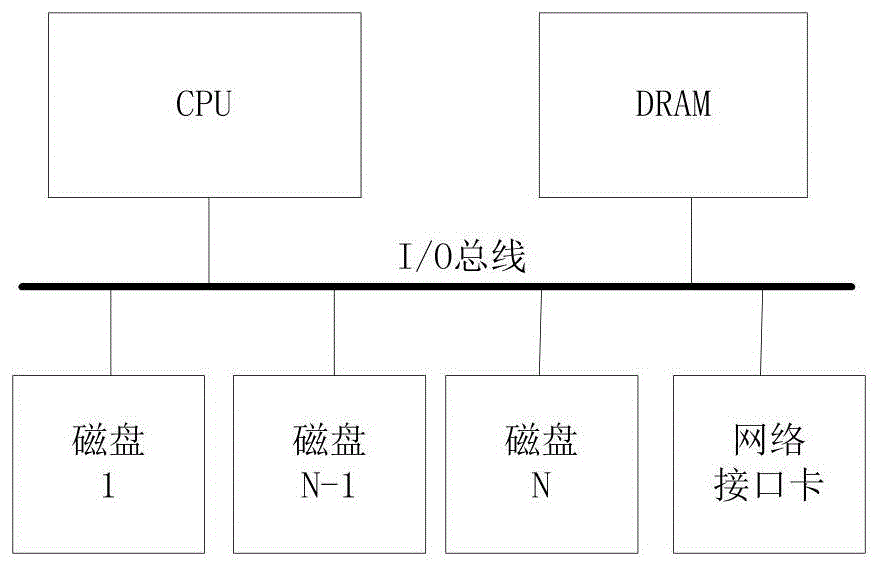
本发明提供一种数据存储系统,如图1所示,所述系统包括一个或者多个处理器(cpu)和内存(dram),多个磁盘或者固态盘,一个或者多个网络接口(支持网络方式,例如fc、以太网、infiniband等)访问存储系统中的数据,所述磁盘通过i/o总线(例如sata、sas、pcie等)接入系统,存储系统中的硬盘(包括磁盘或固态盘)可以以独立方式工作,也可以将多个硬盘组织为冗余阵列方式,例如raid5、raid6等方式。
本发明提供的方法在不同的硬盘组织方式中都能使用,以硬盘独立方式举例说明工作过程。如图2所示,在每个硬盘上,都有独立的文件系统软件来管理硬盘的存储空间和数据,不同的文件系统共用读缓存区和写缓存区,通常情况下,为读缓存区分配较多的内存空间,比如85%,而为写缓存区分配较少的内存空间,比如15%;也可以将内存空间全部用于读缓存区。
读缓存区和写缓存区能同时缓存多个文件的全部或者部分数据,针对不同的应用场景选择不同的方法,比如存储的文件为小文件时,可以将文件的全部数据缓存在内存中;如果存储的文件为大文件,可以将文件数据划分为固定大小的数据块,比如:64kb,以数据块为单位进行缓存管理。如果进行全部文件数据,则缓存的索引主键为<inode,fsid>;如果以数据块进行缓存管理,则缓存的索引主键为<inode,offset,fsid>;其中,inode为每个文件的索引节点号,在一个文件系统内容具有唯一性;fsid为文件系统id号,每个硬盘的文件系统具有存储系统内部唯一的id,offset为数据块在文件系统内部的偏移量。
以inode作为索引主键,如图3所示,读缓存区结构使用单向链表链接,而不是使用打开文件描述符或文件名作为索引主键,其优点在于可以支持文件链接(包括硬链接或软链接)、快照与克隆等功能,多个文件可以共享同一缓存;文件多次打开和关闭时缓存仍然有效。
写缓存区具有2种状态:clean和dirty,写入的数据位于写缓存区中,还未写入到硬盘中,则状态为dirty;写入的数据位于写缓存区,数据已经写入到硬盘中,则状态为clean,写缓存区的状态保存在索引主键结构中,这样可以减少用于保存状态的内存申请与释放操作。
不同文件的缓存区可以使用哈希链表、b树等数据结构进行组织;属于同一磁盘文件系统的写缓存区,还使用单向链表链接,如图4所示,当对该磁盘文件系统执行flush或卸载硬盘等操作时,可以根据该链表找到将该文件系统对应的写缓存区,将其中的数据全部写入到硬盘。
如图5所示,读缓存时,具体步骤:
1.应用程序调用open()函数来打开文件,输入参数为文件名,读写模式等;
2.应用程序调用read()函数来执行读操作,输入参数为文件描述符fd,接收数据的内存地址和长度;
3.根据文件描述符fd获取文件inode,文件系统fsid;
4.根据<inode,fsid>查找读缓存区;
5.如果命中,则将读缓存区中的数据拷贝到接收内存中,将读缓存区的访问次数加1;结束返回;
6.如果未命中,则根据<inode,fsid>查找写缓存区;
7.如果写缓存区命中,则将写缓存区中的数据拷贝到接收内存中,结束返回;
8.尝试分配读缓存区,如果有空闲缓存区,跳转到步骤10;
9.如果无空闲缓存区,则随机选择一组已分配的读缓存区,根据访问次数排序,回收访问次数最少的读缓存区;
10.启动异步读,将文件数据读取到读缓存区中;
11.将数据读缓存区中的数据拷贝到接收内存;
12.结束返回。
如图6所示,写缓存时,具体步骤:
1.应用程序调用open()函数来打开文件,输入参数为文件名,读写模式等;
2.应用程序调用write()函数来执行写操作,输入参数为文件描述fd,写入数据的内存地址和长度;
3.根据文件描述符fd获取文件inode,文件系统fsid;
4.根据<inode,fsid>查找写缓存区;
5.如果命中,跳转到步骤6,否则跳转到步骤10;
6.将写入数据拷贝到写缓存区中;
7.检查该缓存区状态,如果为clean,则将数据写入时间更新为当前时间,结束返回;否则继续步骤8;
8.检查该文件数据缓存时间,如果未超过阈值则返回;否则继续步骤9;
9.如果超过阈值,则启动异步写,将该缓存区的数据写入到对应的硬盘中,并将缓存区状态修改为clean;结束返回;
10.如果未命中,则根据<inode,fsid>随机选组一组缓存区,检查是否有状态为clean的缓存区;如成功则根据访问次数排序,选择回收访问次数最少的缓存区,将写入数据拷贝到写缓存区中,将数据写入时间更新为当前时间,结束返回;
11.选择写入时间最早的缓存区,将数据以同步方式写入到硬盘中,回收该缓存区;
12.将写入数据拷贝到写缓存区中,将数据写入时间更新为当前时间;
13.结束返回。
综上所述,本发明对读缓存和写缓存分开管理,将内存主要作用于读缓存,仅使用少量内存作用于写缓存;或者不使用写缓存,将写数据立即写入硬盘,因此能够兼容数据存储系统的性能和可靠性,减小数据存储系统的结构复杂度,提高重负载写入时的性能。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!