视频流的读取方法与流程
本发明涉及一种用于读取视频流的方法。本发明还涉及用于实施该方法的终端、聚合服务器和信息记录介质。
“压缩”在这里是指减少用于编码相同信息的位数的操作。该操作的结果被指定为压缩信息。“解压缩”是指逆运算,其使得能够从压缩信息获得以信息在压缩之前具有的形式的信息,并且该逆运算的结果被称为解压缩信息。
“加密”是指借助于称为“加密密钥”的秘密信息使信息难以理解的操作,使得该信息仅在借助于该密钥或者与该密钥相应的另一密钥的情况下重新对用户来说是再次可理解的。加密信息是此操作的结果。“解密”是指逆操作,其使得能够借助于被称为“解密密钥”的秘密信息从加密信息获得以信息在加密之前具有的形式的信息,并且该逆操作的结果被称为解密信息。
例如从wo2008/134014中已知读取视频流的方法。在这些已知方法中,第一终端:
-收集表示第一终端的用户行为的至少一个测量值,并基于从收集的所述至少一个测量值构建该用户的该行为的至少一个特征数据,
-对视频流进行解码以获得独立于所收集的所述至少一个测量值的第一基带视频流,然后
-根据构建的所述至少一个特征数据和第一基带视频流合成随构建的所述至少一个特征数据而变化的第二基带视频流。
然后,第二视频流由诸如虚拟实境体验机的显示设备显示。第二视频流具体取决于读取视频流时用户的行为。通常,用户的行为是正在读取视频流时终端的用户的位置和/或移动,所述视频流取决于第二视频流的合成。
例如,如果用户向右看,则第二视频流仅对位于完整图像右侧的图像部分(即用户想要观看的图像部分)编码。
在这种情况下,当第一用户使用终端以稍后重播第二视频流时复制所述第二视频流的益处不大。实际上,当重播第二视频流时,第二用户(几乎可能不是第一用户)重现与第一用户完全相同的行为的可能性很小。因此,重播的视频流不再取决于第二用户的行为,这大大降低了重播该第二视频流的益处。实际上,在这种情况下,最好的情况是第二用户看到与第一用户看到的完全相同的东西。另一方面,所述第二用户无法像第一个用户那样浏览视频流的图像,也就是说无法修改其行为。
只有第一视频流使得能够为用户的所有可能行为合成第二视频流。但是,不能在终端的输出端口上直接和简单地访问所述第一视频流。相反,通常通过硬件和/或安全软件措施来保护对该第一视频流的访问。
为了通常非法地复制和分发第一视频流的完整副本,已经提出了从针对用户的不同行为而获得的第二视频流的多个样本重构该第一视频流。下面的简化示例说明了这种攻击。假设:
-当用户向右看时,终端合成第二视频流的第一样本,该第一样本仅包含第一视频流的每个图像的右半部分;以及
-当用户向左看时,终端合成第二视频流的第二样本,该第二样本仅包含第一视频流的每个图像的左半部分。
为了获得第一视频流的完整副本,攻击者能够在第一次读取视频流的同时在视频流的整个播放过程中系统地保持头部向右转动。因此,所述攻击者获得了其记录的第二视频流的第一样本。然后,所述攻击者再次读取相同的视频流,但是这一次系统地保持头部向左转动。因此,所述攻击者获得了其录制的第二个视频流的第二样本。然后,通过正确组合第二视频流的第一和第二样本的图像,所述攻击者能够重建第一视频流的完整副本。第一视频流的“完整副本”是指:在读取第一视频流的原始版本时,可以以与终端相同的方式根据用户的行为来合成第二视频流的副本。当视频流离线且按需传输时,为了生成第二个视频流的不同所需样本,攻击者能够通过多次读取相同的视频流来一个接一个地生成不同的样本。无论如何,攻击者或一组共谋的攻击者还能够在多个终端上同时读取相同的视频流,以并行生成第二视频流的不同所需样本。
在实践中,为了获得第一视频流的完整副本,通常有必要以用户的不同行为来生成第二视频流的许多样本。在这些条件下,为了促进第二视频流的这些不同样本的生成,已经提出使用自动装置来实现各种期望的行为。例如,当改变第二视频流的用户行为是该用户的移动时,所述自动装置使得能够比人更准确地执行该移动。此外,一旦进行了适当的编程,就无需人工干预来生成第二视频流的所需样本。
从以下方面也知道现有技术:
-ep3026923a1,
-us2014/304721a1,
-us2011/256932a1。
本发明旨在修改一种用于读取视频流的已知方法,以使其更加难以基于第二视频流获得第一视频流的完整副本。
因此,本发明涉及根据权利要求1的一种视频流的读取方法。
所要求保护的方法利用了以下事实:为了基于第二视频流的多个样本构建第一视频流的完整副本,有必要实施与不寻求获得第一视频流的完整副本的用户的正常行为不对应的用户行为。随后,这些与正常行为不对应的行为被描述为“异常”。例如,在上面描述的示例中,不断地仅向右看或不断地仅向左看是异常行为。
所要求保护的方法通过将由终端构建的行为的特征数据与预定阈值进行比较来自动检测这些异常行为。然后,响应于超过这些阈值中的一个或更多个,自动执行对策。对策的执行使得更加难以构建第一视频流的完整副本。因此,所要求保护的方法更能抵抗对于旨在基于第二视频流的样本构建第一视频流的完整副本的攻击。
另外,所要求保护的方法难以挫败。实际上,使用例如自动装置来模拟用户的正常行为是非常困难的。
最后,所要求保护的方法使用与用于合成第二视频流的特征数据相同的特征数据。因此,不需要收集和构建专门用于触发对策的数据。
该读取方法的实施方式能够包括从属权利要求的特征中的一个或更多个。
读取方法的这些实施例能够具有以下优点中的一个或更多个:
-构建表示用户在视频流的读取期间的正常行为的统计数据然后将这些统计数据和终端用户行为的特征数据之间的差值与第一预定阈值比较使得能够检测异常行为。例如,这使得能够检测到不考虑播放的视频流的认知内容的行为。实际上,用户的正常行为通常取决于播放的视频流的认知内容。例如,大多数用户经常同时看图像的相同部分。然而,为了重建第一视频流的完整副本,必须诉诸能够获得每个图像的所有部分的显示并因此包括图像中通常不被用户观看的部分的显示的行为。因此,查看通常未被观看的图像部分是异常行为的示例,孤立地检测或与其他异常行为结合地检测该异常行为会触发对策的执行。此外,自动装置很难甚至不可能理解播放的视频流的认知内容,从而正确模拟人类的正常行为。因此,似乎很难阻止使用自动装置来检测这种类型的异常行为。
-使用绘图作为统计数据,对于图像的每个像素,所述绘图指示用户的注视点朝向该像素的概率使得能够非常可靠地区分正常行为和异常行为。
-使用用户的移动速度或加速度的数据特征使得能够可靠地(在值得信任的意义上)或稳当地或者带有很大成功可能性地检测异常行为。实际上,人类的可能的移动受到人体的生理极限的限制。自动装置的可能移动没有相同的限制。因此,如果检测到移动的速度或加速度超过人类的正常生理能力的特征,则几乎可以确定这是由自动装置进行的移动,因此为异常行为。
-监督学习分类器的使用简化了对异常行为和正常行为的区分。
-随分类器的结果、移动的速度或加速度的特征数据以及统计数据变化的总得分的计算使得能够提高异常行为的检测的可靠性,并且因此以更适当的方式触发对策。
本发明还涉及一种用于读取视频流以实现所要求保护的方法的终端。
本发明还涉及一组用于实现所要求保护的方法的数据聚合服务器。
最后,本发明还涉及一种信息记录介质,该信息记录介质包括当微处理器执行指令时用于实现所要求保护的方法的所述指令。
通过阅读下面仅通过非限制性示例的方式给出并参考附图做出的描述,将更好地理解本发明,其中:
-图1是用于生成和读取压缩加密的视频流的系统的架构的示意图;
-图2是在图1的系统中实现的视频流的读取器的架构的示意图;
-图3是视频流的完整图像的示意图;
-图4是在图1的系统中实现的用于生成视频流的方法的流程图;
-图5和图6是在图1的系统中实现的视频流的读取方法的流程图;
-图7是在图1的系统中实现的统计数据的示意图。
在这些附图中,相同的附图标记用于表示相同的元件。在本说明书的其余部分中,未详细描述本领域技术人员众所周知的特征和功能。
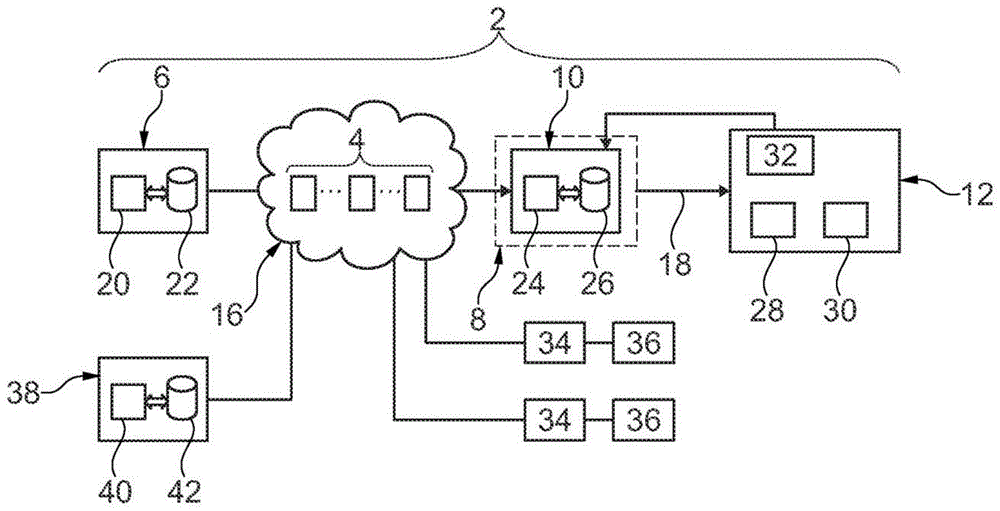
图1示出用于生成和读取加密压缩的视频流4的系统2。系统2包括:
-视频流4的生成器6,
-配备有视频流4的读取器10的终端8,以及
-用于显示由读取器10读取的视频流4的设备12。
视频流4对完整图像的时序序列进行编码。基于视频流4,读取器10:
-获取解密和解压缩的第一基带视频流,然后
-基于该第一视频流合成第二基带视频流,该第基带二视频流包括旨在以通常称为“刷新频率”的给定频率在屏幕上一个接一个地显示的所谓的“合成”图像。
在该实施方式中,视频流4是沉浸式视频。因此,视频流4通常旨在由虚拟实境显示设备显示。
因此,视频流4是在其中每个编码的完整图片同时包含在几个不同方向上围绕相机的图像的编码视图的视频。例如,每个完整图像都包含在视锥内的所有方向上拍摄的视图,视锥的顶点与相机的物镜的光学中心重合。通常,该视锥顶部的角度α大于与相机位于相同位置的人的视角。因此,视频流的每一图像都具有比摄像机位置处的一动不动的人一次可以看到的更多的视图。因此,通常角度α严格地大于70°或80°并且通常大于100°或180°或260°。在视锥不具有圆形底部的情况下,也就是说,它不是旋转圆锥,角度α定义为等于完全包含该视锥的最小旋转圆锥顶点的角度。最小旋转圆锥是指在视锥顶部具有最小角度并且其顶点与视锥顶点重合的旋转圆锥。
当角度α等于180°时,图像通常被称为“半球图像”。角度α也可以等于360°。在这种情况下,每个图像都包含在空间的所有方向上拍摄的视图。我们经常称为360°图像或全向图像。
用于拍摄和记录沉浸式视频的摄像机包括例如同时朝向不同方向的多个物镜和/或具有非常大的打开角度的物镜,也就是说,其打开角度大于100°或160°或180°的物镜。
生成器6例如经由诸如因特网之类的用于传输信息的网络16连接到终端8。生成器6能够是广播头端或视频服务器。
生成器6包括连接到存储器22的可编程电子微处理器20。微处理器20能够执行记录在存储器22中的指令。这里,存储器22包括用于实现图4的方法所必需的指令。
终端8控制设备12以显示该终端读取的视频流。在该实施方式中,设备12被认为是终端8外部的元件。
读取器10对视频流4进行解密和解压缩,然后基于解密和解压缩的视频流合成基带视频流18。
通常,基带视频流主要由连续的位块组成,每个位块都对相应像素的颜色进行编码。这是视频流18内的比特块的位置,所述视频流对相应像素的位置进行编码。例如,视频流18符合hdmi(“高清多媒体接口”)格式等。如果需要,可以根据hdcp标准(“高带宽数字内容保护”)对视频流18进行加密。读取器10与设备12之间的链路是短距离链路,即,该距离通常小于30m或20m或10m。随后,视频流18被称为明文,因为该视频流不再需要由读取器10解密以由设备12以直接可理解的形式显示。
读取器10包括连接到存储器26的可编程电子微处理器24。微处理器24能够执行记录在存储器26中的指令。这里,存储器26包括实施图5和6的方法所必需的指令。
设备12在这里是任何的头戴式显示器hdm或虚拟实境体验机,其使得能够获得立体显示。为此目的,设备12特别包括分别位于用户的右眼和左眼前面的两个屏幕28和30。设备12还包括传感器组32,该传感器组能够测量表示用户行为的一个或更多个物理量。稍后在具体情况下描述该示例性实施例,在该具体情况中,用户的行为是携带该设备12的用户的位置和/或移动。这里,例如,使得能够改变视频流的用户的行为就是用户的注视点朝向的方向。因此,所述传感器组32尤其使得能够构建用户的注视点朝向的方向的至少一个数据特征。例如,传感器组32为此包括测量用户的头部和/或用户的瞳孔的移动的传感器。在此,该传感器组32为此包括三轴加速度计,该三轴加速度计能够在分别表示为x、y和z的彼此正交的三个方向上测量设备12的加速度。传感器组32连接至读取器10。
在该实施方式中,系统2包括几个其他终端34,每个终端能够以与终端8相同的方式读取视频流4。为此,终端34中的每一个连接到网络16并与其本身的显示设备36相关联。为了简化描述,这里认为这些终端34和设备36分别与终端8和设备12相同。为了简化图1,仅示出了两个终端34和两个设备36。但是,实际上,终端34和设备36的数量要多得多。例如,终端34的数量大于十、一百、一千或一万。
最后,该系统包括能够与终端8和其他终端34交换信息的聚合服务器38。为此,系统连接到网络16。服务器38包括连接到存储器42的可编程电子微处理器40。微处理器40能够执行记录在存储器42中的指令。这里,存储器42包括用于实施图5和6的方法所必需的指令。
随后,在具体情况中描述系统2的实施方式,其中:
-视频流4根据h.265标准(也称为hevc(高效视频编码))进行编码,
-传输层符合isobmff(“iso基本媒体文件格式”)标准,并且
-视频流的加密/解密符合cen标准(“通用加密方案”)。
有关h.265标准的更多信息,读者可以参考2015年4月发布的iso/cei23008-2和uit-h.265或其后续版本。有关isobmff标准的更多信息,读者可以参考2015年12月发布的文档iso/cei14496-12。有关cenc标准的更多信息,读者可以参考文档iso/cei23001-7第二版或其后续版本。
由于这些标准是本领域技术人员已知的,因此在此不详细描述这些标准提供的操作原理和不同的实现可能性。这里仅描述使用和实现这些标准以生成和读取视频流4的具体方式。本说明书中使用的术语与这些标准中定义的术语相同。
图2以功能模块的形式示出读取器10的架构。在该图中示出的各个模块可以分别借助于微处理器24和存储器26以软件形式或以其他具体的硬件组件的形式来实现。读取器10包括:
-模块48,其用于解密和解压缩视频流4,
-数字版权管理(drm)代理50,其能够获取、检查、管理和存储诸如解密所接收的视频流4所需的密钥和访问权限之类的秘密信息,
-定位器51,其根据传感器组32的测量值来确定关注点的坐标,
-合成器52,其负责根据定位器51建立的坐标以及解密和解压缩的视频流的图像来构建视频流18,以及
-行为分析器53,其能够检测用户的异常行为,并作为响应,触发执行使得更加难以基于视频流18获得解密和解压缩的视频流的完整副本的对策。
模块48包括:
-解密子模块54,其利用drm代理50发送给该解密子模块的解密密钥对视频流4进行解密,以获得解密的视频流55,以及
-编解码器56(编码器-解码器),其对视频流55进行解压缩以获得解密和解压缩的视频流57,该视频流也被称为明文或基带。
合成器52通常在首字母缩略词gpu(“图形处理器单元”)更公知的专用图形处理电子单元中实现。
分析器53在此连接到传感器组32和网络16两者,以获取代表性测量值或特征数据,包括终端10的用户的行为和其他终端34的用户的行为。分析器53还连接到drm代理50和定位器51,以在必要时触发通过这些组件执行对策。
读取器10的各个组件的常规操作是已知的,并且在以上引用的标准中进行了描述。因此,之后仅详细描述特定于视频流4的读取的这些组件的操作。这里,参考图5和图6描述该操作。
图3示出视频流57的完整图像ii。在该图像上表示的点58对应于用户的注视点正在朝向的点。该点58在下文中被称为“关注点”。
现在参考图4的方法描述生成器6的操作。
在步骤62中,生成器6接收待压缩和待加密的初始视频流。例如,为此,生成器6连接到照相机或记录初始视频流的信息记录介质,或连接到发送所述初始视频流的网络。此时,接收到的视频流包含以人类可直接理解的形式在屏幕上显示所需的所有信息。特别地,为了获得该显示,不需要将明文图像与作为解密密钥的秘密信息组合。
在步骤64中,生成器6将视频流切割成封闭的图像组。然后,对于每个封闭的图像组,它执行以下操作:
-封闭图像组的压缩操作66,然后
-使用压缩图像组的加密密钥kc进行的加密操作68,以获得压缩和加密的图像组。
最后,在步骤70中,将压缩和加密的图像组彼此组装以形成视频流4。
在该步骤70的结尾,视频流4或者正在生成时就通过网络16被发送到终端8和其他终端34,或者被记录在存储器22中的文件中。第一传输模式对应于称为“广播”的传输,在该第一传输模式中,视频流4的传输在该视频流的所有图像组都已被压缩和加密之前开始。例如,在因特网上的点对点广播模式的情况下,这种第一传输模式更精确地是连续传输或流传输。相反,第二传输模式对应于称为“下载”的传输,在该第二传输模式中,仅在在获取、压缩和加密了初始视频流的所有图像之后,才开始向终端8和其他终端34的文件传输。
现在将参考图5的方法描述终端8的操作。
最初,在步骤90期间,drm代理50获取用于解密视频流4的压缩和加密图像组所需的解密密钥kd。
在步骤92期间,读取器10接收连续发送或通过网络16下载的视频流4。
在步骤94中,传感器组32测量表示终端12的用户的行为的一个或更多个物理量,并且读取器10收集这些测量值。在此,这些测量值特别是由定位器51和分析器53收集的。
作为响应,在步骤96期间,定位器51在图像平面中构建关注点58的坐标。为此,这些坐标是基于收集的测量值和例如基于三轴加速度计的测量值构建的。点58的坐标是用户行为的特征数据。
在视频流4的整个读取时间期间,循环重复步骤94和96。例如,以高于屏幕28和30上图像的刷新频率的频率重复这些步骤。因此,定位器51永久地提供点58的更新坐标。
并行地,在步骤100期间,在读取每组图像之前,drm代理50确定其是否被授权解密该组图像。drm代理50例如根据先前被提供的访问权限来确定其是否被授权无限制地解密图像组。
在drm代理50被授权解密图像组的情况下,前进到步骤102,在步骤102期间,drm代理50将解密密钥kd提供给解密子模块54。
作为响应,在步骤104期间,子模块54借助于提供的密钥kd对压缩和加密的图像组进行解密以获得压缩和解密的图像组。
然后,在步骤106期间,编解码器56对在步骤104结束时获得的压缩图像组进行解压缩。编解码器56然后获得解压缩和解密的图像组。
对视频流4的每组图像重复步骤100至106。一组解压缩和解密的图像组形成了发送到合成器52的视频流57。
然后,在步骤110中,合成器52基于视频流57和由定位器51发送的关注点58的坐标合成视频流18。更具体地,在本实施方式中,基于视频流57的每个完整图像ii,所述合成器分别为用户的右眼和左眼合成两个图像部分。为此,所述合成器使用由定位器51给该合成器传送的点58的坐标以及屏幕28和30的已知位置和已知尺寸。通常,这两个图像部分分别比包含在视频流57中的完整图像ii小四或十倍。此外,这些图像部分集中在点58上。因此,视频流18仅包含视频流57的每个完整图像的一部分。
最终,在步骤112期间,合成器52经由视频流18发送合成的图像部分,并且设备12将该合成的图像部分显示在屏幕28和30上。
对于正在处理的视频流57中的图像组中的每个完整图像,重复步骤110和112。
如本申请介绍中所述,为了重建完整的图像ii,已知的攻击包括组装包含在视频流18的不同样本中的图像ii的部分。视频流18的这些不同样本是通过点58的不同坐标获得的。
在步骤100中,drm代理50确定其未被授权对图像组进行解密的情况下,禁止步骤102。因此并根据系统的实现,对于步骤104和106,然后对于正在处理的图像组期间的每个完整图像,步骤110和112中的每一个被禁止,或者由来自加密图形组的错误输入而执行。因此,步骤110和112导致在处理期间的图像组的完整图像的图像的显示中断,或者导致它们以难以理解的形式显示,也就是说,禁止访问这些图像。
现在将参照图6的方法描述分析器53的操作以检测用户的异常行为。
分析器53连续执行诊断用户行为的阶段128,以检测异常行为。
为此,在步骤130期间,与步骤110并行地针对在处理流57期间图像组的每个完整图像,分析器53收集传感器组32的测量值以及由定位器51建立的点58的坐标。然后,将收集的测量值和收集的点58的坐标统称为“收集数据”。
在该步骤130中,读取器10还经由网络16将收集数据发送到服务器38。更具体地,收集的数据各自与视频流的对应图像的标识符相关联。对应的图像是就要在步骤110期间收集的这些数据合成的图像。例如,收集数据带有时间戳,也就是说,与使得能够在播放的视频流中标记在收集这些收集数据时由合成器处理的图像的日期相关联。
并行地,在步骤132期间,除了由定位器51已经构建的数据之外,分析器53还基于收集数据构建用户行为的一个或更多个数据特征。
然后,在步骤134中,分析器53使用不同的技术以基于构建的特征数据检测异常行为。在该步骤134中,每当检测到异常行为时,都向所述分析器报告。例如,在该实施方式中,下面描述的所有检测技术由分析器53同时实施以趋于限制误报的数量。误报对应于检测到异常行为而用户的行为是正常的情况。然后触发对策的执行,并且因此用户在其服务体验中受到不适当的惩罚,这必须尽可能避免。此处描述的不同检测技术分为三个不同的类:
-第一类将所谓的“初始检测”技术组合在一起,该技术直接地并且单独地使用由终端8经由设备12的传感器组32收集的数据。
-第二类为所谓的“分类”技术,该技术使用分类器以将异常行为与正常行为区分开来,
-第三类为所谓的“合并”技术,其使用由其他终端34收集的数据。
下面介绍这三个类的技术示例。
初始检测技术:
第一种初始检测技术在于从收集数据构建特征数据id1,该特征数据表征用户的移动的所测量的速度或加速度的物理特性。该数据id1基于在预定时间间隔t1内收集的数据构建。通常,间隔t1为3s到30s。例如,数据id1是在间隔t1期间设备12的移动的平均加速度,由三轴加速度计的测量值构建。然后,分析器53将数据id1与预定阈值s1进行比较。该阈值s1很低,也就是说小于0.1m/s2或0.05m/s2。然后,根据该第一初始检测技术,如果特征数据id1在大于15s或1min或5min的预定持续时间内保持在该阈值s1以下,则分析器53检测到异常行为。实际上,在该持续时间期间,人类很难保持完全静止或以完全恒定的速度移动。因此,在该预定持续时间内以完全恒定的速度移动或完全不动是异常行为。
预先校准这里描述的不同的预定阈值,以便将正常行为与异常行为区分开。为此,通常使用当人类使用终端时以及当控制器控制终端时构建的特征数据值集。这些不同值集的比较容易使本领域技术人员能够正确地校准预定阈值。
根据第二初始检测技术,如上所述构建数据id1。然后,将该数据id1与预定阈值s2进行比较。该阈值s2大。例如,阈值s2大于20m/s2或50m/s2。然后,如果数据id1在大于1s或2s或5s的预定持续时间内保持高于该阈值s2,则分析器53检测到异常行为。实际上,由于人体的生理限制,人类的头部的移动不能超过该阈值。相反,自动装置能够轻松地做到这一点。因此,数据id1超过该阈值s2是异常行为。
根据第三种初始检测技术,特征数据id2由分析器53构建。该特征数据id2是在预定持续时间内由三轴加速度计测量的加速度的标准偏差或方差。然后,分析器53将数据id2与预定阈值s3进行比较。阈值s3选择得较小,以区分正常移动和异常移动。实际上,人类的移动从来都不是完全规律和恒定的。因此,人类的移动几乎从不对应于完全恒定的加速度。例如,阈值s3的值小于0.1m/s2或小于0.05m/s2。如果数据id2的值小于阈值s3,则分析器53报告异常行为。
根据第四种初始检测技术,分析器53基于在足够长的时间段内收集到的加速度测量值构建特征数据id3。数据id3表征在该时间段内用户的移动的周期性。该时间段大于5min或10min或1h。然后,将数据id3的值与预定阈值s4进行比较。如果超过阈值s4,则分析器53报告异常行为。实际上,规律地重复的移动通常不是正常的移动。例如,分析器53构建在该时间段内测量的三轴加速度计的测量值的光谱密度。然后,分析器53将该光谱密度的最高峰的高度与阈值s4进行比较。如果超过阈值s4,则分析器53报告异常行为。
分类技术:
根据第一分类技术,分析器53实现并执行能够自动比较以预定阈值构建的特征数据集的监督学习分类器,以将用户的当前行为分类为在正常行为的类别中或在异常行为的类别中。该分类器使用的预定阈值是通过在监督学习的初步阶段138时对预记录的特征数据集进行训练而获得的,该特征数据集的异常行为和正常行为之间的分类是已知的。因此,这些特征数据集至少包括:
-当人类正在使用诸如终端8之类的终端来生成收集的数据时构建的特征数据集;以及
-当收集的数据是由人类或由自动装置生成以帮助获得视频流57的完整副本时构建的特征数据集。
这样的分类器对于本领域技术人员是众所周知的,并且在这里将不更详细地描述。例如,由分析器53实现的分类器是线性分类器,诸如朴素贝叶斯分类器或支持向量机或svm(“支持向量机”)或神经网络。
优选地,为了限制由分类器处理的数据的数量,所述分类器不直接处理收集的数据,而是由分析器53基于收集的测量值构建的特征数据。例如,分类器使用的特征数据如下:
-在预定的持续时间内,在x、y和z方向的每个上测量的加速度的平均值,
-在预定的持续时间内,在x、y和z方向的每个上测量的加速度的方差,
-在预定的持续时间内,在每个x、y和z轴上测量的加速度信号的能量,
-在预定的持续时间内,在x、y和z方向的每个上测量的加速度的熵,以及
-对于x、y和z方向的每个收集的测量值之间的相关系数。
当然,在这种情况下,也通过使用相同的特征数据执行监督学习阶段。
合并技术:
合并技术需要在步骤134之前实施步骤140,在该步骤140中,其他终端34读取相同的视频流4。例如,为此目的,参考附图5至6描述的方法由终端34中的每一个执行。因此,服务器38具有数据库,该数据库将由这些其他终端34收集的数据与视频流57的每个图像相关联。在步骤142中,服务器38根据该数据库构建统计数据,能够将由终端8本地构建的特征数据与所述统计数据进行比较以检测异常行为。
根据第一合并技术,基于由其他终端34收集的数据,服务器38在步骤142期间建立第一统计数据。在此,这些第一统计数据是阈值,如果用户的行为正常,则收集数据的值几乎没有超过的机会。“几乎没有…的机会”在这里是指小于一百分之一或一千分之一或一万分之一的概率。然后,服务器38在终端8播放视频流4之前或期间,将这些阈值发送到终端8。作为响应,分析器53在读取视频流的相同部分的同时将接收的这些阈值与本地的收集数据进行比较。如果超过这些阈值之一,则分析器53报告异常行为。仅在视频流4是预先记录并按需发送的视频流的情况下,才可能在终端8开始读取视频流4之前将这些阈值如此确定的值发送到终端8。相反,在终端8播放视频流4期间,对于预先记录并按需发送的视频流以及对于直播的视频流,都可以发送由这些阈值确定的值。。
例如,基于由终端34中的每一个收集并考虑到的加速度,对于基于视频流57的相同的完整图像而合成视频流18的图像部分,服务器38构建收集到的该加速度的统计分布。然后,推导出阈值smin和smax,所收集的加速度的99%位于阈值smin和smax之间。然后将这些阈值smin和smax发送到终端8。然后,终端8将阈值smin和smax与在读取视频流4的该部分期间本地收集的加速度进行比较。如果阈值smin和smax之一被本地收集的加速度超过,那么分析器发出异常行为。该第一合并技术使得能够根据由终端34测量的用户行为动态地调整预定阈值的值。
根据第二合并技术,服务器38根据从终端34收集的数据来构建实施异常检测算法所需的第二统计数据。该算法系列称为“异常检测”或“孤立点检测”。然后,如此构建的第二统计数据被发送到终端8的分析器53。分析器53然后将本地构建的特征数据与接收的第二统计数据进行比较以检测异常行为。更具体地,在该比较步骤期间,将本地特征数据和第二统计数据之间的差值与预定阈值进行比较。然后,由该预定阈值被该差值超过触发异常行为的检测。
举例来说,异常检测算法是由表达“基于聚类的局部离群因子”已知的系列算法,例如lof(局部离群因子)或findcblof算法。
图7示出基于经由终端34收集的数据由服务器38构建的第二统计数据的示例。在该示例中,收集的数据是与视频流4的特定图像ip相关联的点58的坐标。图7示出了该图像ip。这里,构建的第二统计数据采用绘图的形式,该绘图将用户的注视点朝向该像素的概率与图像ip的每个像素相关联。例如,该概率是当读取该图像ip时用户的注视点朝向该像素的次数。换句话说,对于图像ip的每个像素,服务器38对点58的收集的坐标对应于该像素的次数进行计数。服务器38因此构建了将每个像素与用户的注视点朝向该像素的概率关联的绘图。该绘图使得能够例如识别用户观看最多的图像ip的区域。作为说明,在图7中,包围了用户观看最多的两个区域150、152。该绘图还使得能够识别图像ip的较少观看的区域和图像ip的用户未观看或几乎未观看的区域。图7示出了较少观看的两个区域154和156。在此,这两个区域154和156分别围绕区域150和152。位于区域150至156外部的图像ip的区域158在此构成了用户未观看或几乎未观看的区域。
然后,与图像ip相关联的该绘图被发送到分析器53。当图像ip由合成器52处理时,分析器53在该时刻收集由定位器51建立的点58的坐标。然后将这些收集的坐标与接收到的绘图进行比较。在此,该比较在于计算将点58的坐标与观看最多的区域分开的最短距离。如果该距离超过预定阈值,则检测到异常行为。否则,不会检测到异常行为。例如,实施lof算法以执行该比较。
有利地,分析器53还能够实施滤波器以限制对异常行为的不适时的检测。例如,仅当计算出的距离超过p个连续图像的预定阈值或在不到m分钟的时间内超过十次时,才检测到异常行为。例如,p为从4到20,m为从3到30分钟。在此,p为5,m为5分钟。
在步骤134之后,分析器53进行步骤136,在该步骤136中,分析器执行判定算法。该算法的执行使得能够响应于所实施的检测的结果来决定是否必须触发对策的执行,如果是的话,触发哪种对策。有利地,为了做出该决定,分析器53考虑在滑动时间窗口δt内实施的检测结果。特别地,所述分析器考虑了检测到的异常行为以及用于检测每个异常行为的检测技术。滑动窗口δτ立即进行触发当前步骤136。例如,窗口δt具有大于1分钟或5分钟或15分钟且小于1小时的持续时间。
作为说明,在步骤136中,分析器53基于在窗口δt期间检测到的异常行为的数量来计算总得分。当计算该分数时,加权系数能够应用于由特定检测技术检测到的异常行为的数量,以使某些检测技术比其他检测技术更加重要。例如,此处使用这些加权系数是为了相对于初始检测技术和分类技术更加重视上述加固技术。
然后,分析器53将计算出的总得分与至少一个预定阈值进行比较。如果超过该阈值,则分析器53触发对策执行的步骤120的实施。为此,根据待执行的对策的性质,分析器53将触发指令发送到负责该执行的模块,或者自身触发。
在步骤120中,读取器10执行对策,该对策具有使得更加难以基于视频流18的不同样本获得视频流57的完整副本的作用。
能够执行许多对策来实现此结果。
例如,第一种对策在于控制显示设备12播放captchatm,也就是说,例如,所述显示设备将captchatm显示在视频流18的图像部分上方,并同时中断视频流57的生成。在另一个示例中,对策首先在于仅控制显示设备12,以使所述显示设备在视频流18的图像部分上方播放captchatm,然后,仅在从开始播放captchatm起计时的预定延迟到期之前未获得用户对captchatm的正确响应时,才中断生成视频流57。例如,为了中断视频流57的生成,代理50中断将解密密钥kd传输到解密子模块54。如果从用户获得对播放的captchatm的响应是正确的,则控制显示设备12,以使所述显示设备中断captchatm的播放,并且代理50通过恢复向子模块54传输密钥kd来授权由模块48恢复视频流57的生成。在没有对该captchatm响应的情况下,或者在错误响应的情况下,代理50保持视频流57生成的中断。captchatm是卡耐基梅隆大学的商标。这是一个缩写词(rétroacronyme),在英语中发音为“capture”,应该由completelyautomatedpublicturingtesttotellcomputersandhumansapart(法语为testpublicdeturingcomplètementautomatiqueayantpourbutdedifférencierleshumainsdesordinateurs)的首字母组成。它是指计算机科学中使用的质询-响应测试,以使计算机能够确保计算机不会生成对质询的响应。captchatm通常是设备12所播放的问题或谜语,人类能够容易地响应所述问题或谜语,但相反,自动装置很难正确地响应。因此,这种对策使实施攻击更加困难,这是因为即使不是不可能,也很难使该攻击完全自动化。
存在大量可能的captchatm。例如,captchatm可以是包含部分被掩盖和/或变形的字符的组合的图像,从而使自动装置很难自动识别这些字符。然后,此captchatm的正确响应是显示字符组合而成的单词。在另一示例中,captchatm是音频或视频消息,用户必须对所述音频或视频消息正确响应以授权恢复视频流57的生成。例如,有利地,captchatm是一种音频或视频消息,其请求用户采取特定的行为,例如向左转动头部。然后,终端8基于经由传感器组32收集的测量值获取对这种captchatm的响应。
如上所述,第二种对策在于仅暂时地或永久地中断视频流57的生成。
第三种对策在于降低视频流57或18的质量。例如,分析器53控制模块50、模块48和/或合成器52以便减小空间分辨率或降低编码图像的颜色,或者减小编码声音的采样频率。应用于视频流57或18的降级使得基于降级的视频流57或18并且在附加信息的情况下就不可能重建未降级的视频流57或18。
第四种对策是由终端8向生成器6发送命令。响应于该命令,生成器6中断例如向终端8发送视频流4或仅向终端8发送例如如前一段所述的降级的视频流4。在另一示例中,生成器6中断向终端8发送对视频流4的访问权限,或者仅向所述终端发送降级的视频流4的访问权限。
第五种对策在于降级由定位器51建立的点58的坐标。例如,分析器53控制定位器51或合成器52以在预定的时间间隔内保持这些恒定的坐标,并且无论用户在相同时间间隔内进行的移动如何。该预定时间间隔可以限制或可以不限于视频流4的当前读取的持续时间。在这种情况下,视频流18在该时间间隔内不再与用户的行为相关,这使得难以甚至不可能将点58移动到图像内的所期望的位置。点58的坐标的降级还可以在于以随机方式修改这些坐标。也可以应用点58的坐标的预定降级。例如,修改点58的坐标,以使点58遵循与用户的行为无关的预定路径。在另一示例中,系统地修改点58的坐标以禁止将点58定位在视频流57的完整图像的某些预定区域内。这防止了合成器52合成包含在图像的这些预定区域中信息的视频流18。
在步骤120结束时,根据其执行被触发的对策,该方法继续执行步骤102至112,但是被修改以实施触发的对策,或该方法停止。例如,如果已经触发了其执行的对策完全禁止视频流57或18的生成,则方法停止。相反,例如,如果所执行的对策仅仅是降级视频流57或18或点58的坐标,则方法继续。
通常,分析器53能够同时或交替地触发这些对策中的若干对策的执行。
在能够在步骤120中执行不同的对策的情况下,这些对策中的每一个例如与各自的预定阈值相关联。这些不同的阈值按升序排列。在这种情况下,由分析器53发送到负责触发对策的模块的指令能够包括被超出最多的阈值的标识符。作为响应,在步骤120期间中,仅执行与该预定阈值相关联的对策。这使得能够仅执行与计算出的总得分相对应的对策,从而能够对检测到的异常行为执行相应的响应。
系统2的变型:
设备12能够由屏幕和投影仪代替,所述投影仪将读取的视频流的图像投影在该屏幕上。优选地,屏幕的表面将是围绕用户的半球或球形或环形。
已经描述的内容适用于除立体显示之外的领域。在这些情况下,例如,合成器仅构建一个图像部分,而不是如前所述地构建两个。例如,这适用于屏幕围绕用户的情况,如球形或半球形屏幕的情况。这也适用于平面屏幕的情况,所述平面屏幕的尺寸使得用户无法看到整个表面的全局视野。
组32或显示设备12能够被集成在终端8内部。例如,如果终端8是平板电脑或智能电话,则情况将如此。组32也能够在机械上独立于设备12和终端8。
组32能够包括除前述电子传感器之外的其他电子传感器或代替前述电子传感器的其他电子传感器。例如,组32能够包括以下电子传感器中的一种或更多种:
-测量用户头部移动的一个或更多个传感器,例如安装在虚拟实境体验机上的陀螺仪或磁力计。也能够基于机械式独立于虚拟实境体验机的静止相机拍摄的图像来测量头部的位置。在后一种情况下,虚拟实境体验机可能具有特殊的图案或led,这些图案或led基于此相机拍摄的图像确定头部的位置。
-用于测量用户的眼睛或瞳孔的移动的一个或更多个传感器。再次,该传感器能够包括照相机,该照相机拍摄用户的眼睛,并且基于拍摄的图像推断出眼睛或瞳孔的移动。
-用于测量用户身体另一部分的移动的一个或更多个传感器,例如用户的手、嘴唇、胸部、脚或其他。为此目的,这种传感器能够包括对用户的移动进行拍摄的照相机和拍摄图像的分析单元,该分析单元确定由该照相机拍摄的身体部位所实现的移动。传感器也能够是操纵杆、器械手套、器械跑步机、按钮等。
-测量用户神经活动的传感器,例如脑电图仪。在这种情况下,改变视频流18的用户的行为不一定是用户的位置或移动。实际上,这种类型的传感器也对用户的情绪或心理状态敏感。还可以就要这种传感器的测量值推断出用户的位置或移动。
-在读取视频流期间由用户发出的声音或语音传感器。同样在这种情况下,改变流18的用户的行为也不是位置或移动。通常,声音或语音传感器包括语音识别设备或与语音识别设备相关联,该语音识别设备将相关的声音或语音转换成可由合成器52执行的命令以生成流18。
drm代理50能够以诸如安全协处理器或芯片卡处理器的硬件形式实现。
能够实现系统2符合除上述标准之外的其他标准。对于特定的应用,系统2与现有标准兼容也不是强制性的。例如,在一个变型中,视频流被逐图像压缩,从而每个图像组仅包含单个图像。在另一变型中,视频流在单个块中被压缩,这相当于具有包括视频的所有图像的单个图像组。最后,在另一替代方案中,图像组不是较小的封闭图像组。
读取方法的变型:
作为变型,视频流4仅被压缩而不被加密。在这种情况下,仍然可以执行上述对策来降级视频流57或中断其解压缩。这样的实施方式总是有利的,这是因为其使得难以甚至不可能基于由合成器51合成的视频流18的不同样本来重建视频流57的完整副本。
在另一个实施方式中,对策不与阈值相关联,并且例如,所触发的对策的确定是随机的。
如上所述,还存在能够触发执行的其他对策。例如,如在申请wo2008/134014a2中所描述的,可以有规律地修改视频流18或57的多样化参数以作为对策。
本文描述的方法能够在视频的全部或仅部分图像上实施。例如,本文描述的方法在某些时间间隔期间实施而在其他时间间隔期间禁用。
异常行为检测方法的变型:
分析器53能够在终端8之外的其他地方实现。例如,所述分析器也能够在服务器38内部或另一个远程服务器中实现。为此,由终端8收集的数据被发送到服务器38。然后,服务器38执行步骤132至134以检测终端8的用户的异常行为、判定步骤136以及如有必要执行对策的步骤120。如有必要,可通过向生成器6和/或终端8发送指令来触发对策的执行。当生成器6执行对策时,该指令将被发送到生成器6。例如,响应于该指令,生成器6向终端8发送emm消息(“权利管理消息”),该emm消息删除或限制该终端对视频流4的访问权限。例如,生成器6停止将对视频流4的访问权限或视频流4本身发送到终端8,这使得该终端8不可能获得明文的视频流57。
在另一个变型中,分析器53的不同功能也能够部分地在服务器38中并且部分地在终端8中实现。例如,仅初始检测技术在终端8中实现。分类和合并仅在服务器38中实现。
服务器38也可以在终端8中实现。
在另一变型中,分析器53仅实施前述的一种或仅几种检测技术。特别地,在简化的实施方式中,省略了合并或分类技术。在没有实施合并技术的情况下,能够省略服务器38,并且在步骤130中,不发送由终端34收集的数据。相反,在不同的实施方式中,仅实施一种或多种合并技术。
通过从上述检测技术的许多示例中汲取灵感,本领域技术人员将知道开发其他检测技术。例如,也能够构建与在移动加速度的情况下描述的特征数据相同的特征数据以表征用户的移动速度的物理特性。为此,分析器53使用获取的移动速度的测量值代替获取的该移动的加速度的测量值。然后,分析器53实施类似于上述在加速的情况下的初始检测技术,以基于速度的特征数据检测异常行为。
如上述示例性实施例中已经说明的,特征数据的比较在于测试以下不等式之一:f(x)<sx或f(x)>sx或f(x)<sx或f(x)>sx,其中:
-f是返回依赖于特征数据x的值的函数,并且
-sx是预定阈值。
在最简单的情况下,函数f是标识函数。但是,如前面的示例所示,函数f能够是更复杂的函数,例如分类器或多变量函数。
在另一个变型中,特征数据而不是所收集的数据被发送到服务器38。然后必须调整服务器38的操作和前述方法的进展,以考虑到接收到的是特征数据而不是收集的数据这一事实。
在简化的变型中,基于收集的测量值构建特征数据仅在于将收集的测量值分配为该特征数据项的值。如果特征数据与收集的测量值相同,则有可能。例如,如果收集的测量值已经由传感器本身至少部分地处理,则特征数据的值等于该测量值,而无需对其构建进行进一步处理。
在另一个实施方式中,分析器53仅在实施预定数量的步骤134之后,或者自步骤136的先前实施以来或自开始读取视频流4以来的预定时间段之后,实施步骤136。
- 还没有人留言评论。精彩留言会获得点赞!