基于Hadoop并行加速的分级图分组配准方法与流程
本发明属于三维医学图像配准领域,应用于大规模的医学脑图像配准,具体地来说是基于hadoop并行加速的分级图分组配准方法。
背景技术:
医学图像配准在分析基于图谱的分析或临床诊断系统方面起到基本的关键作用。在这些研究中,图像配准关键在于,消除群体差异,这些差异包括个体直接按的不同或听一个实验者的结构变异变化(例如与脑部疾病相关的变异),图像配准应用广泛,比如婴儿地图集构建和基于群体的解剖变异性评估。因此通过医学图像配准得到的公认模板,为临床和病理学研究提供可靠的依据,辅助医生做出更为准确的诊断。
大多数现有技术的配准方法都属于成对配准,即,仅考虑一对图像(个体和模板)。当将成对配准应用于大规模图像数据集时,需要模板并且通常将其作为数据集中的特定图像。其余所有的图像被视为个体并逐个配准到模板中。但是模板的确定非常重要,可能会带来很大偏差。因此出现了分组配准。分组配准能够消除这种系统偏差,因为群体中的所有图像都朝向公共空间扭曲并且同时估计它们的变形。共同空间是在共同配准过程中自发显现。根据图像相似度的度量方法,分组配准可以分为三类,(1)基于组平均图像的分组配准,使用成对配准方法来实现分组配准,构建估计出来的图谱(平均图像)作为数据集的公共空间。(2)基于图论的分组配准,不使用平均图像,而是每个图像可以直接计算其与其他图像的相似性。(3)基于特征的分组配准,可以捕获所有图像特定位置的相关性/不相关性,因此通过最大化图像空间中所有位置的相关性,可以将整个图像数据集配准到公共空间。
一种新颖的群组配准方法(ehugs),它有一个分层图,该图的每个节点代表单个图像。分层图捕获图像分布流形来得到图像分布信息,从而可以利用图像分布信息。更具体地说,低层次的图描述每个小组中的图像分布,并且高层次的图代表子组中具有代表性的图像之间的关系。在一个特定的图表示模型中,我们可以通过动态缩小图像流形上的图来将所有图像配准到公共空间。整个图像分布的拓扑在图收缩期间一直保持不变。
虽然很多配准方法精度在提高,但是计算量都很大,尤其是要处理大量数据集的时候,在手术之前和手术期间获取的图像数据进行处理必须是快速和准确的,以便在临床诊断中有用。现在患者所能用到的数据正在稳步增加,对医学图像进行配准等处理时,常常要耗费大量的时间,因此脑图像配准算法的速度要求越来越高。
对于分级图分组配准方法来说,对大量数据同时处理造成的运算负载可以分散在不同步骤内独立执行。输入的图像可以分层次聚簇到一个金字塔结构之中,在对各子簇内的图像分组配准后,再合成出最终的模板。这样,就将原先的一个大运算量问题分解成若干小运算量问题,使得分组配准算法能解决问题的规模可以提高更多的图像。但是随着更多的图像参与配准,计算代价依然太大,运行较慢,所耗的时间太多,比如20张图像一块配准,用ehugs方法需要48小时。
hadoop由apache基金会开发,是在分布式服务器集群上存储海量数据并运行分布式分析应用的一种方法。apachehadoop软件库是一个框架,其设计规模可以从单服务器扩展到几千台服务器。不依赖于硬件,具有高效性。hadoop的体系结构主要通过hdfs(hadoopdistributedfilesystem)来实现对分布式存储的底层支持,并通过mapreduce来实现对分布式并行运算的程序支持。
技术实现要素:
本发明所要解决的技术问题是:在hadoop分布式计算的平台,利用mapreduce并行编程模型,基于现有的分级图分组配准算法,在保证了配准精度的前提下,提高多张脑图像分组配准的运行速度。
本发明解决其技术问题所采用的技术方案包括如下步骤:
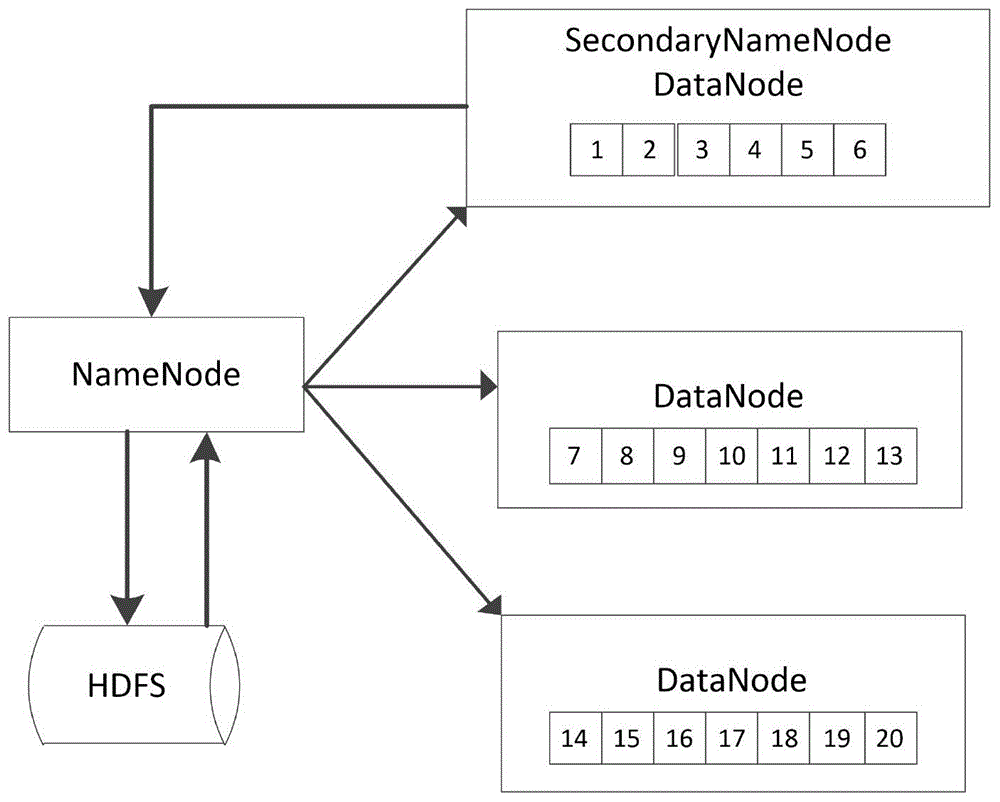
步骤1.将图像上传至hdfs文件系统中,确定blocksize为64mb,hdfs文件系统把文件划分成多个块,划分后的块分散地存储于3个数据节点datanode上,为了达到负载均衡,每个datanode尽量均匀存储图像,每个datanode上的块信息复制2份存储于其他datanode上。
步骤2.读入图像并计算相似度矩阵
2-1.先调用simpleitk库来读入图像,然后转化为mapreduce可识别的格式imageinputformat,键key为图像的编号,value为图像数据;再计算两两图像间的距离矩阵,并将距离矩阵作为两两图像的相似度矩阵;
2-2.并行计算直方图匹配,第一张图像作为标准并且每张图像为一个map,其余图像都与第一张图像进行直方图匹配。从而得到图像数据集合i,i={ii|i=1,...,n};
2-3.map函数中最初输入的<key,value>为<i,ii>,然后将两两图像组合起来输出为<(i,j),(ii,ij)>。在reduce函数使用ssd来度量两两图像的相似度,即公式dij=||ii-ij||2,
2-4.使用累加计数器计算每张图像的相似度总和,最小的那张为全局中心图像io,即公式
步骤3.基于mapredue的分布式ap聚类,将所有的图像聚类分成ω个小组
图像的距离矩阵的维度为n*n,先将矩阵中的n2个数据分配到3个数据节点上,将吸引度矩阵ri和归属度矩阵ai初始化,全都置为0。该方法的ap聚类所用的偏好值如下:
3-1.计算吸引度矩阵r,最初吸引度和归属度都初始化为零,第一个map函数输入<key,value>为<图像i,相似度si>,<图像i,归属度ai>,输出<图像i,(相似度si,归属度ai)>。第二个map函数的输入为第一个map函数的输出,通过吸引度和图像的相似度计算出吸引度,最后reduce函数将结果合并输出<图像i,吸引度ri>,
3-2.计算归属度矩阵a,map函数输入<key,value>为<r,r(i,k)>,输出<k,r(i,k)>,reduce函数输出<图像i,归属度ai>.
3-3.确定聚类簇的中心,也就是在每个小组中确定该组的代表性图像
在ap聚类中判断聚类簇的中心方法是,符合归属度加上吸引度大于0的点为该簇的中心,但是这是运用在图像配准中,因此使用mapreduce中的计数器counter计算该组中的每张图像与全局中心图的相似度总和,最小的那张为该组的代表图像
步骤4.构建分级图的连接体系
4-1.构建小组内的连接体系,设定一个阈值,与代表性图像
4-2.构建小组间的连接体系,每个代表性图像
步骤5.计算变形场
5-1.每张图像都与之有连接的图像进行两两配准,调用logdemonreg函数将两两图像进行匹配,生成变形场imavelfield,因此<key,value>为<(图像i,图像j),imavelfield>,计算出多个变形场后调用simpleitk库中的函数adddeformationfield->update()把多个变形场叠加起来。
5-2.调用simpleitk库中的函数dividevectorfields计算每张图像的平均合成速度场、计算浮动图像的位移场和逆位移场。<key,value>分别为<图像i,平均合成速度场>、<图像i,位移场>、<图像i,逆位移场>
5-3.调用函数composedeformationfields把每张图像的当前位移场和逆位移场合并,<key,value>为<(当前位移场i,逆位移场),新的当前位移场i>。
步骤6.配准以及写入图像
6-1.配准,调用函数applydeformationfield将之前计算的变形场运用到对应的图像,<key,value>为<(图像i,当前位移场i),配准图像i>。
6-2.将配准了的图像写入到相应的hdfs路径中,输出格式为imageoutputformat。迭代次数加1。
步骤7.将步骤5和6循环迭代,直到达到所期望的迭代次数。
本发明方法具有的优点及有益结果为:
(1)在hadoop分布式计算的平台,利用mapreduce并行编程模型,基于现有的分级无偏图分组配准算法,在保证了配准精度的前提下,提高多张脑图像分组配准的运行速度。
(2)本发明方法是关于医学图像,将原先利用c++实现的itk库,改成使用simpleitk库,以便运用在由java实现的mapreduce并行编程模型。并且将其他使用c++语言写的文件通过swig接口,可以在java语言调用。这方法可以运用在其他医学图像处理的领域。
附图说明
图1是20张图像在hadoop分布式系统的存储方法。
图2是利用mapreduce编程模型处理图像。
图3是进行ap聚类,将图像集分成好几个小组。
图4是分级图结构的分组配准流程。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图1-4所示,基于hadoop并行加速的分级图分组配准方法,具体步骤如下:
实验平台:
步骤1.假设现在有20张医学脑图像需要进行配准,每张图像大约为8.49mb,将这些图像上传至hdfs文件系统中,确定blocksize为64mb,hdfs把文件划分成块,这些块分散地存储于3个数据节点上,因此每个datanode分别分配7,7,6张图像以达到负载均衡,每个块复制2份存储于其他datanode上。
步骤2.读入图像并计算相似度矩阵
2-1.先调用simpleitk库来读入图像,然后转化为mapreduce可识别的格式imageinputformat,键key为图像的编号,value为图像数据。计算两两图像间的距离矩阵,也就是图像的相似度矩阵,
2-2.并行计算直方图匹配,第一张图像作为标准并且每张图像为一个map,其余图像都与第一张图像进行直方图匹配。从而得到图像数据集合i,i={ii|i=1,...,n}
2-3.map函数中最初输入的<key,value>为<i,ii>,然后将两两图像组合起来输出为<(i,j),(ii,ij)>。在reduce函数使用ssd来度量两两图像的相似度,即公式dij=||ii-ij||2,
2-4.使用累加计数器计算每张图像的相似度总和,最小的那张为全局中心图像i0,即,公式
步骤3.基于mapredue的分布式ap聚类,将所有的图像聚类分成ω个小组
先将两两图像的距离dij,也就是n2分配到3个数据节点上,将吸引度矩阵ri和归属度矩阵ai初始化,全都置为0。该方法的ap聚类所用的偏好值如下
3-1.计算吸引度矩阵r,map函数输入<key,value>为<图像i,相似度si>,<图像i,归属度ai>,输出<图像i,(相似度si,归属度ai)>,reduce函数输出<图像i,吸引度ri>
3-2.计算归属度矩阵a,map函数输入<key,value>为<r,r(i,k)>,输出<k,r(i,k)>,reduce函数输出<图像i,归属度ai>.
3-3.确定聚类簇的中心,也就是在每个小组中确定该组的代表性图像
在ap聚类中判断聚类簇的中心方法是,符合归属度加上吸引度大于0的点为该簇的中心,但是这是运用在图像配准中,因此使用mapreduce中的计数器counter计算该组中的每张图像与全局中心图的相似度总和,最小的那张为该组的代表图像
步骤4.构建分级图的连接体系
4-1.构建小组内的连接体系,设定一个阈值,与代表性图像
4-2.构建小组间的连接体系,每个代表性图像
步骤5.计算变形场
5-1.每张图像都与之有连接的图像进行两两配准,<key,value>为<(i,j),imavelfield>,计算出多个变形场并且叠加起来。
5-2.计算每张图像的平均合成速度场、计算浮动图像的位移场和逆位移场。<key,value>分别为<图像i,平均合成速度场>、<图像i,位移场>、<图像i,逆位移场>
5-3.把每张图像的当前位移场和逆位移场合并,<key,value>为<(当前位移场i,逆位移场),新的当前位移场i>。
步骤6.配准以及写入图像
6-1.配准,将之前计算的变形场运用到对应的图像,<key,value>为<(图像i,当前位移场i),配准图像i>。
6-2.将配准了的图像写入到相应的hdfs路径中,输出格式为imageoutputformat。迭代次数加1。
步骤7.将步骤5和6循环迭代,直到达到所期望的迭代次数。
- 还没有人留言评论。精彩留言会获得点赞!