一种基于图像处理的图书检索方法与流程
本发明属于图像检索领域,具体为一种基于图像处理的图书检索方法。
背景技术:
在大数据的当下时代,关于各大图书馆借阅图书时如何高效的、人性化的查找图书成为当下研究热点之一。
对于图像检索主要含有两大步骤:图像特征提取和图像的相似性度量。特征提取就是图像信息的提取,对图像上的点分析和变换,以表示图像的特征的过程及方法。目前,特征提取方法有基于文本和基于内容的,基于文本的特征提取需要人们手动标注图像的关键字,这种方法耗时长且具有主观色彩,不适用于高效检索图书要求。相似性度量是指两个图像之间的相似程度的一种度量,两图像越相似,它们的相似性度量也越大。传统的计算特征向量距离的方式和hash索引算法难于查询大数据问题,效率低。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种基于图像处理的图书检索方法。
本发明所采用的技术方案是:一种基于图像处理的图书检索方法,包括以下步骤:
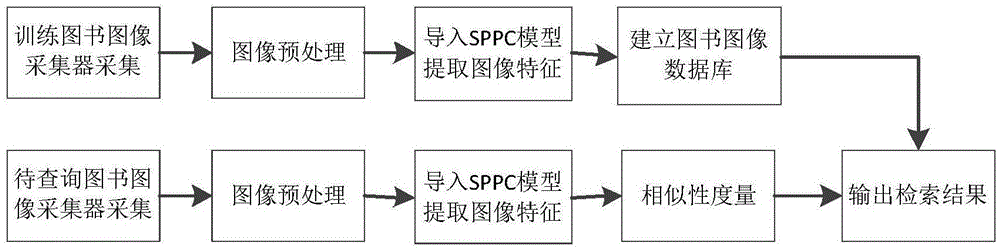
1、对图书图像进行随机分类,分成待查询数据和要训练数据;
2、用图像采集器采集图书页面图像并发送至图像预处理器;
3、图像预处理器对图像进行灰度处理、去噪;
4、构建去池化的深度卷积神经网络alexnet模型,将每幅图像送入到该sppc模型中进行特征提取,构建图像数据库;
5、对待查询数据和图像数据库中的特征进行simhash索引匹配,输出最相似性的检索结果。
优选的,所述步骤4中图像特征提取方法如下:
a、将待查询的图书图像导入sppc模型中进行选择性搜索,划分为2000个候选窗口;
b、将待查询的图书图像输入sppc模型,在卷积层进行一次性特征提取,得到全局特征图;
c、在全局特征图中找到各个候选窗口,其步骤是建立二维坐标系,用(a,b)表示全局特征图上的点,(x,y)表示候选窗口长得点,设s为cnn中的所有步长的乘积,对坐标变换有:
d、对各个候选窗口采用金字塔池化,提取固定长度的特征向量,其步骤是对一张原图按照三种不同大小的刻度(4*4,2*2,1*1),提取一个固定大小的21维特征向量;
e、将此固定特征向量输入至全连接层输出结果作为查询图书的深度特征。
优选的,所述步骤5中图像相似性度量方法如下:
a、对每个图书的深度特征向量分配权重wi,通过hash函数计算各个特征向量的hash值,编制成0和1的6位签名;
b、在hash值的基础上,给所有特征向量进行加权,即w=hash*weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘;
c、将上述各个特征向量的加权结果累加,变成一个序列串;
d、通过simhash函数对序列串计算simhash值,如果大于0则置1,否则置0,实现降维;
e、计算查询图书图像simhash值与图像数据库中数据的汉明距离,从而判定相似图书,输出索引结果。
与现有技术相比,本发明的有益效果是:
本发明采用的去池化的深度卷积神经网络alexnet模型提取特征能使得任意大小的特征图转换成固定大小的特征向量;采用simhash算法进行相似性度量可以快速的处理大数据索引。
附图说明
图1图书图像检索流程图
图2simhash索引流程图
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,以下结合附图及具体实施例,对本申请作进一步地详细说明。
实施例一:
请参阅图1,本发明提供如下技术方案:一种基于图像处理的图书检索方法,包括以下步骤:
1、对图书图像进行随机分类,分成待查询数据和要训练数据;
2、用图像采集器采集图书页面图像并发送至图像预处理器;
3、图像预处理器对图像进行灰度处理、去噪;
4、构建去池化的深度卷积神经网络alexnet模型,将每幅图像送入到该sppc模型中进行特征提取,构建图像数据库;
5、对待查询数据和图像数据库中的特征进行simhash索引匹配,输出最相似性的检索结果。
本实例中,步骤4中图像特征提取方法如下:
a、将待查询的图书图像导入sppc模型中进行选择性搜索,划分为2000个候选窗口;
b、将待查询的图书图像输入sppc模型,在卷积层进行一次性特征提取,得到全局特征图;
c、在全局特征图中找到各个候选窗口,其步骤是建立二维坐标系,用(a,b)表示全局特征图上的点,(x,y)表示候选窗口长得点,设s为中的所有步长的乘积,对坐标变换有:
d、对各个候选窗口采用金字塔池化,提取固定长度的特征向量,其步骤是对一张原图按照三种不同大小的刻度(4*4,2*2,1*1),提取一个固定大小的21维特征向量;
e、将此固定特征向量输入至全连接层输出结果作为查询图书的深度特征。
本发明中的图像特征提取方法能使任意大小的特征图转换成固定大小的特征向量,增强图书检索的灵活性。
实施例二:
本发明提供如下技术方案:一种基于图像处理的图书检索方法,包括以下步骤:
1、对图书图像进行随机分类,分成待查询数据和要训练数据;
2、用图像采集器采集图书页面图像并发送至图像预处理器;
3、图像预处理器对图像进行灰度处理、去噪;
4、构建去池化的深度卷积神经网络alexnet模型,将每幅图像送入到该sppc模型中进行特征提取,构建图像数据库;
5、对待查询数据和图像数据库中的特征进行simhash索引匹配,输出最相似性的检索结果。
本发明中,步骤4中图像特征提取方法如下:
a、将待查询的图书图像导入sppc模型中进行选择性搜索,划分为2000个候选窗口;
b、将待查询的图书图像输入sppc模型,在卷积层进行一次性特征提取,得到全局特征图;
c、在全局特征图中找到各个候选窗口,其步骤是建立二维坐标系,用(a,b)表示全局特征图上的点,(x,y)表示候选窗口长得点,设s为中的所有步长的乘积,对坐标变换有:
d、对各个候选窗口采用金字塔池化,提取固定长度的特征向量,其步骤是对一张原图按照三种不同大小的刻度(4*4,2*2,1*1),提取一个固定大小的21维特征向量;
e、将此固定特征向量输入至全连接层输出结果作为查询图书的深度特征。
本发明中的图像特征提取方法能使任意大小的特征图转换成固定大小的特征向量,增强图书检索的灵活性。
本实例中,步骤5中图像相似性度量方法如下:
a、对每个图书的深度特征向量分配权重wi,通过hash函数计算各个特征向量的hash值,编制成0和1的6位签名;
b、在hash值的基础上,给所有特征向量进行加权,即w=hash*weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘;
c、将上述各个特征向量的加权结果累加,变成一个序列串;
d、通过simhash函数对序列串计算simhash值,如果大于0则置1,否则置0,实现降维;
e、计算查询图书图像simhash值与图像数据库中数据的汉明距离,从而判定相似图书,输出索引结果。
本发明采用simhash算法进行相似性度量可以快速的处理大数据索引。
综上所述,本发明中的图像特征提取方法能使任意大小的特征图转换成固定大小的特征向量,增强图书检索的灵活性,采用simhash算法进行相似性度量可以快速的处理大数据索引。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!