一种基于LSTM的中标网页命名实体抽取方法与流程
本发明涉及命名实体识别技术领域,具体涉及一种基于lstm的中标网页命名实体抽取方法。
背景技术:
命名实体识别是自然语言处理的一个基础任务。其目的是识别语料中人名、地名、组织机构名等命名实体。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的一些规律性,因而,通常把对这些词的识别从词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别。
作为自然语言处理的一个基础任务,命名实体识别的相关研究吸引了越多越多专家和学者的密切关注,并提出了一些优化算法和模型。有学者提出一种基于层叠hmm模型的命名实体识别算法,首先对人名和地名进行识别,然后作为特征进行高层的机构名识别;有学者提出一种基于条件随机场的中文命名实体识别算法,并得到基于字,边界,词性和实体字典作为特征可以取到很好的效果;有学者提出一种基于bootstrapping的方法,利用bootstrapping技术扩大种子词表解决人工标注数据不足的问题;有学者提出一种基于blstm的神经网络结构的命名实体识别算法,该方法不再直接依赖于人工特征和领域知识,而是利用基于上下文的词向量和基于字的词向量,前者表达命名实体的上下文信息,后者表达构成命名实体的前缀、后缀和领域信息;有学者提出一种基于blstm-crf模型的命名实体识别算法,对句子进行序列标注时,词之间的label不是独立的,而是考虑前面词的标签信息进而结合词的信息再标记当前词的tag,crf取代使用softmax从该层输出,产生每个单词的最终预测;有学者提出一种基于堆叠式自编码分类器的深层神经网络模型,解决了从中文文本序列到模型输入向量的转化问题,提出了便于工程实现的向量化前向-后向传播公式。
目前多数的命名实体识别算法都是对人名,地名,机构名进行识别,没有对其进行进一步的划分,且对长实体的识别效果不好。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于lstm的中标网页命名实体抽取方法,能快速有效的识别招标网站的中标项目详情页面中的命名实体。
为实现上述目的,本发明采用如下技术方案:
一种基于lstm的中标网页命名实体抽取方法,具体包括以下步骤:
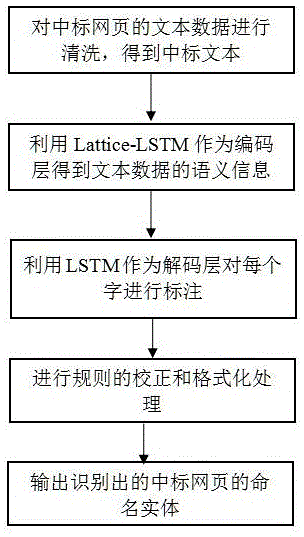
步骤a:对待抽取中标网页的文本数据进行清洗,得到中标文本;
步骤b:以lattice-lstm模型作为编码层,并将中标文本作为编码层的输入,得到中标文本的语义信息特征;
步骤c:以lstm模型作为解码层,并将得到的中标文本的语义信息特征作为解码层的输入,对中标文本中的每个字进行标注;
步骤d:对得到的带标注的中标文本进行规则校正和格式化处理;
步骤e:输出识别的命名实体。
进一步的,所述步骤b具体为:
步骤b1:将中标文本中的字转化为字向量;
其中,对于中标文本中的第j个字cj,转化为字向量
其中,ec表示字符向量映射表。
步骤b2:将中标文本中的词转换为词向量;
步骤b3:将词向量输入lattice-lstm模型,利用lattice-lstm模型得到中标文本的语义信息特征。
进一步的,所述步骤b2具体为:
步骤b21:根据大规模语料库利用tire树构造词表d;
步骤b22:初始化一个空的中标文本的匹配词集合p;
步骤b23:将中标文本的第一个字作为当前字开始遍历,执行步骤b24;
步骤b24:将词表d中匹配以当前字为词首字的词
其中,b表示词的第一个字在句中的位置,e表示词的最后一个字在句中的位置;
步骤b25:将当前字的下一个字符作为当前字,迭代执行步骤b24,直到中标文本的最后一个字符结束;
步骤b26:遍历结束后将集合p中的
其中,ew为词向量映射表。
进一步的,所述步骤b3具体如下:
对于文本中的每个句子,依次输入步骤b1得到的字向量序列
进一步的,所述步骤c具体为:
步骤c1:针对中标网页的命名实体识别任务,将数据中的字分为两类;
其中,第一类代表与实体无关的字,用标签“o”来表示;第二类代表与实体相关的字,这一类字的标签由三部分组成:
步骤c2:将步骤b得到的可以表示文本的语义信息的隐藏状态信息
其中
步骤c3:将标签向量
其中wy为权重矩阵,by为偏置项,nt为标签的种类数;
步骤c4:以对数似然函数为损失函数,通过随机梯度下降优化方法,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型,具体计算公式如下所示:
其中,d表示训练集的大小,lj是句子x的长度,
进一步的,所述命名实体包括招标机构、中标机构、招标机构所处地区、中标金额、招标机构联系人、招标项目名称,中标时间。
进一步的,所述步骤d具体为:
步骤d1:对步骤c得到的带标注数据进行规则的校正处理;
步骤d2:将校正处理后的数据进行格式化处理。
进一步的,所述步骤d1具体为:
步骤d11:对于中标金额,采用正则表达式的方式判断实体是否存在阿拉伯数字或中文大写数字,如果不存在则认为不是中标金额并舍弃。
步骤d12:对于中标时间,判断不是日期组成方式的进行舍弃。
步骤d13:对于项目名称,由于项目名称实体的字符串长度通常较长,基本不会出现只有两三个字组成的情况,因此舍弃识别到的项目名称的字符串长度小于4的实体。
步骤d14:对于一条中标数据同一种类别出现多次时只保留字符串长度最长的命名实体。
进一步的,所述步骤d2中,对命名实体进行格式化处理,具体包括以下步骤:
步骤d21:对于中标金额,判断实体是否包含单位“百”,“佰”,“千”,“仟”,“万”,“萬”,“亿”,“億”,“美元”,“日元”,如果包含则进行单位换算;
步骤d22:对于中标时间,以日期格式yyyy-mm-dd的形式进行转换。
本发明与现有技术相比具有以下有益效果:
本发明基于lattice-lstm-lstm模型,能够高效的识别招标网站的中标项目详情页面中的命名实体,且能很好对长实体的识别。
附图说明
图1是本发明方法流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于lstm的中标网页命名实体抽取方法,具体包括以下步骤:
步骤a:对待抽取中标网页的文本数据进行清洗,得到中标文本;
步骤b:以lattice-lstm模型作为编码层,并将中标文本作为编码层的输入,得到中标文本的语义信息特征;
步骤b1:将中标文本中的字转化为字向量;
其中,对于中标文本中的第j个字cj,转化为字向量
其中,ec表示字符向量映射表。
步骤b2:将中标文本中的词转换为词向量;
步骤b21:根据大规模语料库利用tire树构造词表d;
步骤b22:初始化一个空的中标文本的匹配词集合p;
步骤b23:将中标文本的第一个字作为当前字开始遍历,执行步骤b24;
步骤b24:将词表d中匹配以当前字为词首字的词
其中,b表示词的第一个字在句中的位置,e表示词的最后一个字在句中的位置;
步骤b25:将当前字的下一个字符作为当前字,迭代执行步骤b24,直到中标文本的最后一个字符结束;
步骤b26:遍历结束后将集合p中的
其中,ew为词向量映射表。
步骤b3:将词向量输入lattice-lstm模型,利用lattice-lstm模型得到中标文本的语义信息特征。
对于文本中的每个句子,依次输入步骤b1得到的字向量序列
步骤c:以lstm模型作为解码层,并将得到的中标文本的语义信息特征作为解码层的输入,对中标文本中的每个字进行标注;
步骤c1:针对中标网页的命名实体识别任务,将数据中的字分为两类;
其中,第一类代表与实体无关的字,用标签“o”来表示;第二类代表与实体相关的字,这一类字的标签由三部分组成:
步骤c2:将步骤b得到的可以表示文本的语义信息的隐藏状态信息
其中
步骤c3:将标签向量
其中wy为权重矩阵,by为偏置项,nt为标签的种类数;
步骤c4:以对数似然函数为损失函数,通过随机梯度下降优化方法,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型,具体计算公式如下所示:
其中,d表示训练集的大小,lj是句子x的长度,
步骤d:对得到的带标注的中标文本进行规则校正和格式化处理;
步骤d1:对步骤c得到的带标注数据进行规则的校正处理;
步骤d11:对于中标金额,采用正则表达式的方式判断实体是否存在阿拉伯数字或中文大写数字,如果不存在则认为不是中标金额并舍弃。
步骤d12:对于中标时间,判断不是日期组成方式的进行舍弃。
步骤d13:对于项目名称,由于项目名称实体的字符串长度通常较长,基本不会出现只有两三个字组成的情况,因此舍弃识别到的项目名称的字符串长度小于4的实体。
步骤d14:对于一条中标数据同一种类别出现多次时只保留字符串长度最长的命名实体。
步骤d2:将校正处理后的数据进行格式化处理。
步骤d21:对于中标金额,判断实体是否包含单位“百”,“佰”,“千”,“仟”,“万”,“萬”,“亿”,“億”,“美元”,“日元”,如果包含则进行单位换算;
步骤d22:对于中标时间,以日期格式yyyy-mm-dd的形式进行转换。
步骤e:输出识别的招标机构、中标机构、招标机构所处地区、中标金额、招标机构联系人、招标项目名称,中标时间的命名实体。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!