基于多维Copula函数的日含沙量过程随机模拟方法与流程
本发明属于水文随机模拟技术领域,尤其涉及一种基于多维copula函数的日含沙量过程随机模拟方法。
背景技术:
含沙量是影响河道水质、水生环境以及水库淤积和河道冲淤的一个重要水文变量。含沙量随机模拟研究对流域水沙调控、水质与水环境管理以及河道整治起重要作用。天然河道中流量与含沙量之间关系复杂,两者呈现复杂的多值对应关系,对其进行随机模拟时,不仅要考虑含沙量时间序列自身的相关性,还要考虑流量和含沙量之间的相关性。因此,需采用多变量随机模拟方法对其进行模拟。
常见的多变量随机模拟方法有多变量自回归模型、空间解集模型及主变量模型等方法。多变量自回归模型及空间解集模型,计算较为繁琐,为简化计算,常认为自相关和互相关系数是近似平稳的,一般用于年序列的模拟。对于非平稳水文序列,需建立相应的季节性自回归模型和季节性空间解集模型,计算更为繁琐。主变量法是将水文变量之间的相关关系用线性关系表示,无法反映截口间非零滞时的互相关特性。
考虑到河流当前时段含沙量不仅受到前一时段含沙量的影响,还会受到流量的影响,是一个典型的多变量相关性问题。copula函数是描述变量间相关性的有效工具。由于其不受边缘分布类型限制,且具有结构灵活、适用性广的特点,现已广泛应用于洪水事件、降雨事件、干旱事件以及水沙事件的频率分析中。近年来copula函数也应用于洪水过程、径流量、降雨量等水文变量的随机模拟中。然而目前为止,还未见其应用于日含沙量过程模拟中。
技术实现要素:
针对上述问题,本发明同时考虑含沙量自身相关性以及流量与含沙量之间的相关性,提出了一种多维copula函数的日含沙量过程随机模拟方法,包括:
步骤1、针对模拟截口较多、截口边缘分布难以确定的特点,采用正态分位数变换对实测日流量、日含沙量资料进行标准正态化处理。
步骤2、考虑相邻截口流量的相关性,采用二维copula函数建立相邻截口流量(即qt和qt-1)的联合分布,继而在已知qt-1的条件下推求qt,从而实现对日流量的随机模拟,得到日流量随机模拟序列;
步骤3、根据条件混合法,采用三维copula函数建立当前截口流量qt、前一截口含沙量st-1和当前截口含沙量st的三维联合分布,继而在已知qt和st-1的条件下,推求st,从而实现对日含沙量的随机模拟。
所述步骤1中对实测日流量、日含沙量资料进行标准正态化处理的方法为正态分位数法的基本原理可用下式表示
z=n-1(f(x))(1)
式中,z为标准正态分布变量;n-1为标准正态分布函数n的反函数;f(x)为实测序列x的分布函数,可采用blom绘点位置得到。
于是各截口的标准正态化流量和含沙量的边缘分布可用正态分布表示,对应的概率密度函数为
式中,μ和σ2分别为变量x的均值和方差。
所述步骤2中相邻截口流量的联合分布为
采用二维copula函数建立相邻截口流量的联合分布,即
式中,qt-1和qt分别为t-1和t截口流量的模拟值;ut-1和ut分别为qt-1和qt的边缘分布,即ut-1=ft-1(qt-1),ut=ft(qt);θt为t截口copula函数的参数,可根据其与kendall秩相关系数的关系间接得出,即
式中,τt为t截口的kendall秩相关系数,可采用下式计算:
其中,m为截口总数,n为样本长度,sign(·)为符号函数,xt,i为第i年第t个截口的观测值。
所述在已知qt-1的条件下推求qt具体方法为
由式(3)可以得到qt关于qt-1的条件分布,即
根据式(6),在已知qt-1的条件下,可以求出t截口的流量qt,具体步骤为:
201、根据已知的qt-1,求出ut-1=ft-1(qt-1);
202、生成服从[0,1]均匀分布的随机数rt,令
计算时,第1个截口的qt可根据q1=f1-1(r′)求出,其中r′为服从[0,1]均匀分布的随机数。
所述步骤3中根据条件混合法,采用三维copula函数建立当前截口流量qt、前一截口含沙量st-1和当前截口含沙量st的三维联合分布的方法为
条件混合法是一种利用条件分布和二维copula函数来构造多维联合分布函数的方法。该方法可以避免直接采用不对称型的三维archimedeancopula函数建立联合分布时计算工作量大,参数估计困难的问题。
设x、y和z为三个随机变量,则其三维概率分布函数可表示为
式中,c为copula函数;fx|y(x|y)和fz|y(z|y)分别为y已知的条件下,x和z的条件分布,它们可分别用二维copula函数表示,即
式中,u、v和w分别为随机变量x、y和z的边缘分布,即u=fx(x),v=fy(y)和w=fz(z)。
根据式(7),可采用三维copula函数建立qt、st-1和st的三维联合分布,即
式中,st-1和st分别为t-1和t截口含沙量的模拟值;u1,u2和u3分别为qt,st-1和st的边缘分布概率,即
采用copula函数进行
式中,
所述在已知qt和st-1的条件下,推求st的具体方法为
根据式(10)可以得到st关于qt和st-1的条件分布,即
令
根据式(13),在已知qt和st-1的条件下,可以求出t截口的含沙量st,具体步骤为:
301、根据u1,u2求出h1(u1|u2);
302、令g(u3|u1,u2)=εt,其中εt为服从[0,1]均匀分布的随机数,依据式(13)的反函数可以求出t截口的h2(u3|u2)值;
303、根据h2(u3|u2)的反函数可以计算出t截口含沙量概率u3,从而求出t截口含沙量的模拟值
计算时,假设第1个截口的含沙量s1只与第一个截口的流量q1有关,根据两者的条件分布和第1个截口的流量模拟值q1,可得到第1个截口的含沙量模拟值s1。
本发明的有益效果:
a)对含沙量进行随机模拟时,不仅考虑了含沙量时间序列自身的相关性,还考虑了流量和含沙量之间的相关性。
b)考虑到水文时间序列复杂的非线性特征,采用了能够反映非线性关系的copula函数构建水文变量的联合分布。
c)采用条件混合法建立各截口qt,st-1和st的三维联合分布,避免了直接采用不对称型的三维archimedeancopula函数建立联合分布时计算工作量大,参数估计困难的问题。
d)考虑到日流量及日含沙量序列中各截口的边缘分布不尽相同,且有些截口的边缘分布难以确定的问题,本发明采用正态分位数变换法对二者进行标准正态化转换,使其服从标准正态分布。
附图说明
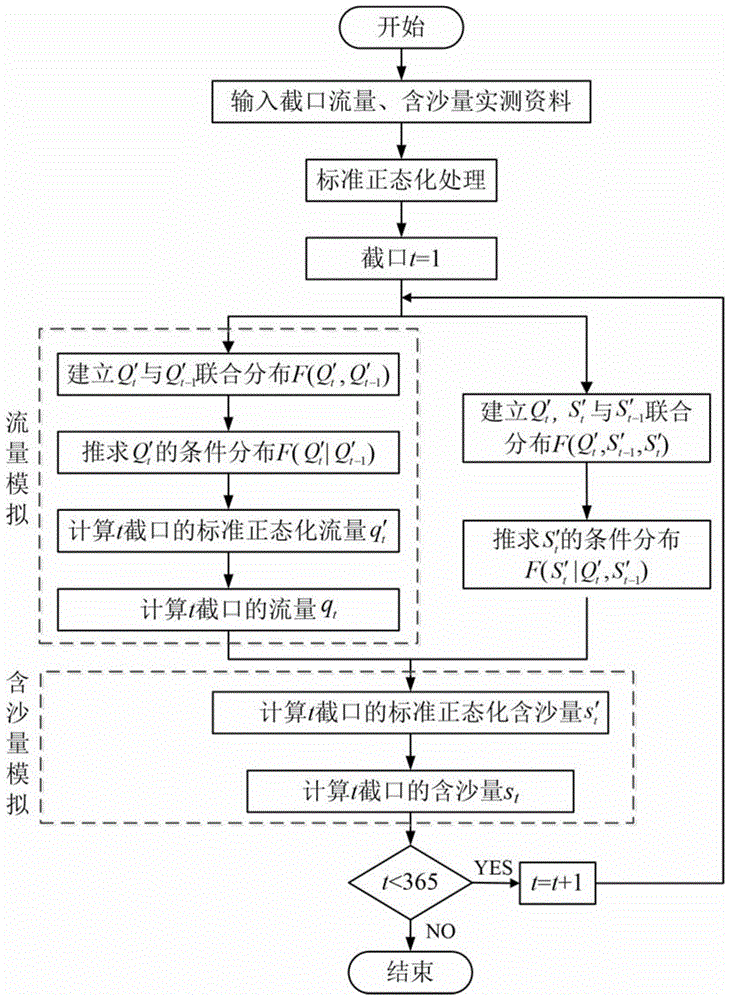
图1为基于copula函数的日含沙量模拟流程
图2为实测序列当前截口流量qt与当前截口含沙量st的秩相关系数
图3为实测序列当前截口流量qt与前一截口含沙量st-1的秩相关系数
图4为实测序列当前截口含沙量st与前一截口含沙量st-1的秩相关系数
图5为实测序列当前截口流量qt与当前截口含沙量st的条件相关系数
图6为当前截口流量qt与前一截口含沙量st-1的联合分布
图7为当前截口含沙量st与前一截口含沙量st-1的联合分布
图8为当前截口流量qt与当前截口含沙量st的联合分布
图9为屏山站各截口不同联合分布的ols值
图10为屏山站ols值接近平均值的截口对应的三维联合分布经验概率与理论概率的比较
图11为屏山站日流量模拟序列与实测序列均值比较
图12为屏山站日流量模拟序列与实测序列变差系数cv比较
图13为屏山站日流量模拟序列与实测序列偏态系数cs比较
图14为屏山站日含沙量模拟序列与实测序列均值比较
图15为屏山站日含沙量模拟序列与实测序列变差系数cv比较
图16为屏山站日含沙量模拟序列与实测序列偏态系数cs比较
图17为屏山站模拟序列与实测序列当前截口流量qt与当前含沙量st的秩相关系数
图18为屏山站模拟序列与实测资料当前截口流量qt与前一截口含沙量st-1的秩相关系数
图19为屏山站模拟序列与实测资料当前截口含沙量st-1与前一截口含沙量st-1的秩相关系数
具体实施方式
下面结合附图,对实施例作详细说明。
本发明提出了一种基于多维copula函数的日含沙量过程随机模拟方法,该方法对日含沙量进行模拟时,不仅能考虑日含沙量序列在时间上的相关性,还能考虑日流量与日含沙量之间的相关性。分别用qt、st表示t截口的流量和含沙量,则日含沙量随机模拟问题可描述为在已知qt和st-1的情况下,推求st。本发明的具体步骤为:
步骤1、针对模拟截口较多、截口边缘分布难以确定的特点,采用正态分位数变换对实测日流量、日含沙量资料进行标准正态化处理。
步骤2、考虑相邻截口流量的相关性,采用二维copula函数建立相邻截口流量(即qt和qt-1)的联合分布,继而在已知qt-1的条件下推求qt,从而实现对日流量的随机模拟,得到日流量随机模拟序列;
步骤3、根据条件混合法,采用三维copula函数建立当前截口流量qt、前一截口含沙量st-1和当前截口含沙量st的三维联合分布,继而在已知qt和st-1的条件下,推求st,从而实现对日含沙量的随机模拟。
所述步骤1中对实测日流量、日含沙量资料进行标准正态化处理的方法为正态分位数法的基本原理可用下式表示
z=n-1(f(x))(1)
式中,z为标准正态分布变量;n-1为标准正态分布函数n的反函数;f(x)为实测序列x的分布函数,可采用blom绘点位置得到。
于是各截口的标准正态化流量和含沙量的边缘分布可用正态分布表示,对应的概率密度函数为
式中,μ和σ2分别为变量x的均值和方差。
所述步骤2中相邻截口流量的联合分布为
采用二维copula函数建立相邻截口流量的联合分布,即
式中,qt-1和qt分别为t-1和t截口流量的模拟值;ut-1和ut分别为qt-1和qt的边缘分布,即ut-1=ft-1(qt-1),ut=ft(qt);θt为t截口copula函数的参数,可根据其与kendall秩相关系数的关系间接得出,即
式中,τt为t截口的kendall秩相关系数,可采用下式计算:
其中,m为截口总数,n为样本长度,sign(·)为符号函数,xt,i为第i年第t个截口的观测值。
所述在已知qt-1的条件下推求qt具体方法为由式(3)可以得到qt关于qt-1的条件分布,即
根据式(6),在已知qt-1的条件下,可以求出t截口的流量qt,具体步骤为:
201、根据已知的qt-1,求出ut-1=ft-1(qt-1);
202、生成服从[0,1]均匀分布的随机数rt,令
计算时,第1个截口的qt可根据q1=f1-1(r′)求出,其中r′为服从[0,1]均匀分布的随机数。
所述步骤3中根据条件混合法,采用三维copula函数建立当前截口流量qt、前一截口含沙量st-1和当前截口含沙量st的三维联合分布的方法为
条件混合法是一种利用条件分布和二维copula函数来构造多维联合分布函数的方法。设x、y和z为三个随机变量,则其三维概率分布函数可表示为
式中,c为copula函数;fx|y(x|y)和fz|y(z|y)分别为y已知的条件下,x和z的条件分布,它们可分别用二维copula函数表示,即
式中,u、v和w分别为随机变量x、y和z的边缘分布,即u=fx(x),v=fy(y)和w=fz(z)。
根据式(7),可采用三维copula函数建立qt、st-1和st的三维联合分布,即
式中,st-1和st分别为t-1和t截口含沙量的模拟值;u1,u2和u3分别为qt,st-1和st的边缘分布概率,即
采用copula函数进行
式中,
所述在已知qt和st-1的条件下,推求st的具体方法为根据式(10)可以得到st关于qt和st-1的条件分布,即
令
根据式(13),在已知qt和st-1的条件下,可以求出t截口的含沙量st,具体步骤为:
301、根据u1,u2求出h1(u1|u2);
302、令g(u3|u1,u2)=εt,其中εt为服从[0,1]均匀分布的随机数,依据式(13)的反函数可以求出t截口的h2(u3|u2)值;
303、根据h2(u3|u2)的反函数可以计算出t截口含沙量概率u3,从而求出t截口含沙量的模拟值
计算时,假设第1个截口的含沙量s1只与第一个截口的流量q1有关,根据两者的条件分布和第1个截口的流量模拟值q1,可得到第1个截口的含沙量模拟值s1。
上述基于copula函数的日含沙量过程模拟计算流程如附图1所示。
将本发明应用到屏山站日含沙量过程模拟中。采用1955~2010年的日流量、日含沙量实测资料作为建模的基本资料。模拟时为简化计算,每年2月份均取28天。
采用正态分位数变换法对实测日流量与日含沙量数据进行标准正态化,则各截口的标准正态化日流量与日含沙量的边缘分布可用正态分布拟合。采用式(5)计算各截口q′t和s′t、q′t和s′t-1以及s′t和s′t-1的秩相关系数,即
由附图2至附图5可知,秩相关系数
q′t与s′t-1、s′t与s′t-1的二维经验联合频率采用gringorten公式计算。由于q′t与s′t的条件分布的经验联合频率无法求得,因此,本发明将根据q′t、s′t-1与s′t三维联合分布的ols值来确定q′t与s′t的条件分布的联合分布,具体方法为:①根据ols值最小原则确定q′t与s′t-1、s′t与s′t-1的二维联合分布对应的最优copula函数,即
附图6至附图8给出了屏山站截口最优copula函数,附图9给出了截口最优copula函数对应的ols值。附图10给出了屏山站三维联合分布
采用二维copula函数对屏山站日流量进行了长序列随机模拟,模拟了100组与实测样本容量(即56年)相等的日流量序列。附图11至附图13给出了模拟序列各截口的均值、变差系数cv和偏态系数cs与实测资料的比较,表1给出了模拟序列截口统计参数的平均绝对误差、相对误差值以及通过率,其中cs按截口的模拟值与实测估值的相对误差≤15%统计通过率,其余参数按相对误差≤10%统计通过率。
表1屏山站日流量模拟序列截口统计参数的平均误差和通过率
由附图11至附图13、表1可见,日流量模拟序列各截口的均值、cv和cs与实测序列均吻合较好,计算精度也较高,最大平均相对误差4.32%,最小通过率88.49%,可用于屏山站日流量随机模拟中。
根据各截口所建立的三维联合分布和日流量的模拟序列,采用上述方法对日含沙量进行随机模拟,得到与日流量模拟序列等长的日含沙量序列。附图14至附图16给出了日含沙量模拟序列各截口的均值、变差系数cv和偏态系数cv与实测资料的比较,表2给出了日含沙量模拟序列截口统计参数的平均绝对误差、相对误差值以及通过率。
表2屏山站日含沙量模拟序列截口统计参数的平均误差和通过率
由附图14至附图16、表2可见,日含沙量模拟序列各截口的均值、cv和cs与实测序列均吻合较好,计算精度也较高,通过率均在95%以上,最大平均相对误差5.61%,其中均值的通过率达到100%,说明本发明所提的方法能够很好地反映日含沙量过程的统计特性。
附图17至19给出了屏山站日流量序列与日含沙量序列滞时为0和滞时为1的秩相关系数以及日含沙量序列滞时为1的秩相关系数的截口变化。由附图17至附图19可见,模拟序列各截口的秩相关系数与实测资料基本吻合,qt和st,qt和st-1以及st和st-1秩相关系数的截口平均绝对误差分别为0.016、0.033和0.001,平均相对误差分别为4.48%、9.52%和0.19%。表明该方法能较好地反映日流量和含沙量之间的相关性以及日含沙量序列在时间上的相关性。
本发明提出的方法可以考虑同时含沙量自身相关性以及流量与含沙量之间的相关性,不仅为日含沙量的长序列模拟提供一种新途径,也为研究长江上游水沙变化和水沙调控提供技术支持。
此实施例仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!