一种基于语义保护的紧凑的哈希码学习方法与流程
本发明属于图像检索技术领域,具体涉及一种基于语义保护的紧凑的哈希码学习方法,适用于大规模图像检索任务。
背景技术:
随着互联网、云计算、物联网等信息技术的迅速发展,以及移动数字媒体设备的普及,人们可以随时随地生产、分享、传播着各种信息,图像也成为人们获取信息的重要媒介之一,影响并改变着人们的生活。基于图像检索技术的商业应用也层出不穷,如百度识图、淘宝图像、谷歌引擎等。然而,海量的图像给数据的管理和分析带来了一定的困难,图像特征维度高、存储量大、检索速度慢等,是图像检索面临的一系列问题。如何快速而精准地从大规模图像中检索到用户需要的目标对象成为计算机视觉的研究热点之一,并有着广泛的商业应用。
由于哈希特征存储空间小、检索效率等特性,基于哈希的最近邻搜索成为了大规模图像检索主流的选择。将原始空间中高维的数据通过哈希函数映射成低维的二进制哈希码,同时保证数据在汉明空间的表示尽可能地保持原空间中的近邻关系,可以有效降低大数据环境下的存储空间,并提高查询分析效率。按照是否与数据有相关,哈希算法可以分为两类:数据无关性哈希和数据相关性哈希。数据无关性哈希算法的映射函数是人工设计或者随机生成的;数据相关性哈希算法根据数据结构和标签等信息学习哈希函数,按照是否依赖标签信息,数据相关性哈希算法又可以分为无监督、半监督和有监督三类。数据无关性哈希算法采用随机映射的方法或人工设计哈希函数,如局部敏感哈希(lsh,locality-sensitivehashing)、移动不变性核哈希(sikl,shiftinvariantkernelhashing)。由于哈希函数的设计没有考虑数据的结构和标签信息,造成数据在原始空间和汉明空间中语义上的差距。为了解决上述问题,数据相关性哈希算法被提出,包括无监督、半监督、有监督三类。该类算法目标是学习到依赖数据和针对具体任务的哈希函数,将数据编码成有效的、紧凑的、保护数据相似性的哈希码表示,如谱哈希(sh,spectralhashing)、迭代量化哈希(itq,iterativequantization)、局部约束线性编码(llc,locality-constrainedlinearcoding)、图哈希(agh,hashingwithgraph)、半监督哈希(ssh,semi-supervisedhashing)、基于监督的核哈希算法(ksh,kernel-basedsupervisedhashing)等。
近年来,深度学习在计算机视觉等相关领域取得很好的实验及应用效果。深度学习的目标就是从复杂的数据中学习到健壮的、有丰富表达能力的语义信息,而哈希算法可以将高维的图像特征映射成低维的二进制码,实现高效的大规模检索任务,因此一些研究者便将深度卷积神经网络与哈希技术相结合,对深度哈希算法进行研究,同时学习图像的特征表示和二进制哈希码,并取得了很好的实验效果。但是由于二进制哈希码是离散值,无法直接使用梯度下降算法对深度神经网络进行训练和优化,现有的深度哈希算法的一般做法是,首先学习一组连续的实数值,然后采用sgn函数将实数值量化成二进制码,这种分步量化的方法会导致量化误差较大,影响图像检索结果的精确度。
在2017年iccv会议中,清华大学发表的名为“hashnet:deeplearningtohashbycontinuation”论文提出一种基于连续的学习方法,可以直接学习二进制码。hashnet为降低量化误差提供了一种新的思路,直接学习二进制码,减少了分步量化的误差,但是没有考虑到二进制码均匀分布等问题。为了解决上述问题,本发明对基于hashnet对深度哈希算法进行研究并改进,进一步降低量化误差,同时保证二进制码均匀分布和保护图像的语义相似性。
技术实现要素:
本发明要解决的技术问题为:克服现有技术的不足,提供一种基于语义保护的紧凑的哈希码学习方法,本发明要解决的技术问题为:克服现有的深度哈希技术的两个方面的不足:(1)首先学习一组连续的实数值,然后采用sgn函数将实数值量化成二进制码,这种分步量化的方法会导致量化误差较大;(2)没有考虑到二进制码均匀分布的问题。
为了解决上述问题,本发明提出了一种基于语义保护的紧凑的哈希码学习方法,使用成对(pairs-wise)的图像对进行网络的训练,采用权重化的最大似然函数作为目标约束,并设计损失函数,使得学习到的哈希码均匀分布且量化误差较小。
本发明包括以下步骤:
第一步,划分数据集:采集图像并构建图像数据集,图像数据集中的每张图像,作为一个样本均包括对应的类别样本标签;将图像数据集分成两个部分,一部分作为测试样本集,另一部分作为图像数据库,并从所述图像数据库中随机抽取一小部分作为训练样本集,计算训练样本集中两两图像(即图像对)的样本类别标签之间的相似度;
第二步,构建深度哈希网络模型:采用卷积神经网络,卷积神经网络由多个卷积层和全连接层组成,每个卷积层和全连接层都由多个神经元组成,前一层的输出作为后一层的输入,并由激活函数得到后一层的输出;在卷积神经网络的最后一层全连接层后添加一层隐含层即哈希层,从而构建深度哈希网络模型;所述哈希层神经元个数为哈希码的长度,激活函数采用双曲正切函数tanh,并设计约束函数,保护图像的语义相似性的同时,保证学习到的实数值接近1或者-1,从而降低了采用阶跃函数sgn将实数值量化成二进制哈希码时的信息损失,并保证学习到的实数值为1或者-1的概率相等,使得到的二进制哈希码均匀分布;
第三步,将训练样本集中的图像对输入到深度哈希网络模型中,并在深度哈希网络模型中前向传播,计算损失;然后,采用反向传播算法调整深度哈希网络模型的参数,得到预训练好的深度哈希网络模型,并提取图像数据库中所有图像的哈希码;
第四步,从测试样本集中选取任意一张图像,通过训练好的深度哈希网络模型提取所选图像的哈希码,然后计算所选图像的哈希码与图像数据库中图像的哈希码间的汉明距离;
第五步,根据得到的汉明距离,按照距离从小到大的顺序,对图像数据库中图像哈希码进行排序,顺序输出哈希码对应的原始图像,最终得到图像检索结果。
所述第一步中的划分数据集,具体如下:
(1)图像数据集采用的是公开标准数据集ms-coco,将图像数据集分成两个部分,分别是测试样本集和图像数据库,其中测试样本集为从图像数据集中随机选择的5000张图像,其余的图像作为图像数据库;
(2)从图像数据库中随机抽取10000张图像作为训练样本集;
(3)计算训练样本集两两样本类别标签之间的相似度。
所述训练样本集两两样本类别标签之间的相似度的计算方法为:设xi和xj分别表示图像i和图像j,则xi和xj之间的相似度cij表示为:
式中,yi和yj分别表示图像i和图像j的标签,yi∩yj表示yi和yj的交集,yi∪yj表示yi和yj的并集。
所述第三步中,构建深度哈希网络模型具体如下:
(1)从caffe官网上下载预训练好的alexnet网络模型;
(2)更改alexnet网络模型结构,在alexnet网络模型中最后一层全连接层后添加哈希层,并用tanh函数作为激活函数;
(3)设计约束函数,保护图像的语义相似性,同时保证使得学习到的实数值尽可能为1或者-1,且为1或者-1的概率相等;
所述步骤(2)更改alexnet网络模型结构,具体如下:
在alexnet网络模型中最后一层全连接层后添加哈希层,构建的深度哈希网络模型总共包含八层,其中,前五层为卷积层,中间两层为全连接层,最后一层为哈希层,该层神经元个数为哈希码的长度;深度哈希网络模型的输入为图像对,哈希层用tanh函数作为激活函数;所述图像对包括相似的图像对和不相似的图像对。
所述步骤(3)中保护图像的语义相似性,具体如下:
(1)使用成对的图像对进行深度哈希网络模型的训练,并通过权重化的最大似然估计生成二进制哈希码,使得相似的图像对的哈希码的汉明距离较小,不相似的图像对的哈希码的汉明距离较大,从而保护图像的语义相似性。
(2)训练样本集中相似性图像对和非相似图像对数量往往是不相同的,针对数据不平衡问题,根据训练图像对被误分类的重要程度,对设置相应的权重(惩罚),以更好地保护图像的语义相似性。
所述步骤(3),保证学习到的实数值尽可能为1或者-1,且为1或者-1的概率相等,假设通过tanh等激活函数学习到的激活向量实数值r∈(-1,1),具体如下:
(1)添加约束函数,保证实数值r∈r接近1或者-1,而不是0附近,使得采用阶跃函数sgn对实数值量化成二进制哈希码时误差较小,同时还将实数值的距离拉大到2,即从-1到1;
(2)添加约束函数,保证激活向量中所有实数值的平均值为0,保证每位二进制码为-1和1的概率相同。
本发明与现有技术相比的优点在于:
(1)使用成对(pairs-wise)的图像对进行网络的训练,采用权重化的最大似然函数作为目标约束,保护图像的语义相似性;
(2)设计约束函数,保证学习到的实数值接近1或-1,以减少通过符号函数对实数值进行量化时造成的误差,从而保证哈希码均匀分布;
(3)设计约束函数,保证学习到的实数值为1或-1的概率相同,从而保证哈希码为1和0的概率相同,得到高效、紧凑的二进制码表示;
(4)本发明所提技术在公开标准数据集ms-coco进行试验,采用64位哈希码表示图像时,进行5000次查询,在返回前5000张近邻图像情况下的平均正确率为75.63%,比hashnet提高了3.18%。
附图说明
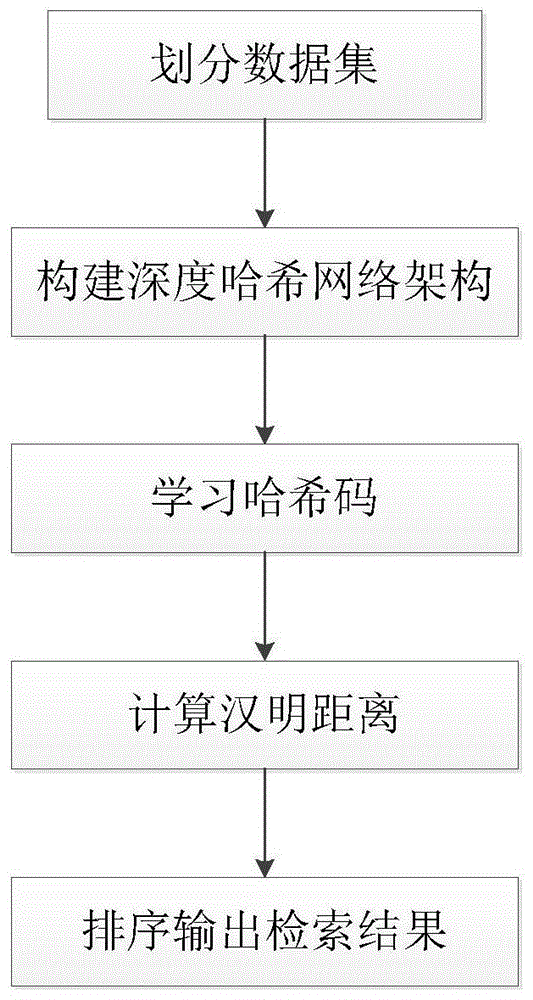
图1是本发明进行图像检索的整体实现流程图;
图2是本发明所构建的深度哈希网络模型结构图。
具体实施方式
附图1描述了基于深度哈希的图像检索整体过程。下面结合附图对本发明进行进一步的说明。
本发明提出一种端到端的深度哈希网络模型,同时学习图像的语义特征和二进制哈希码表示,使用成对(pairs-wise)的图像对进行深度哈希网络模型的训练,采用权重化的最大似然函数作为目标约束,保护图像的语义相似性,并设计损失函数,使得学习到的哈希码均匀分布且量化误差较小,即尽可能地使学习到的实数值接近1或-1,以减少通过符号函数对实数值进行量化时造成的误差,并且尽可能地保证每一位实数值为1或者-1的概率相同,进而保证哈希码为1和0的概率相同,得到高效、紧凑的二进制码表示。通过计算并比较查询图像的哈希码与数据库中所有图像的哈希码之间的汉明距离,快速而准确地检索到与查询图像相似的图像集合。
如图1所示,本发明包括以下步骤:
步骤1:划分数据集
将图像数据集分成两个部分,一部分作为测试样本集,另一部分作为图像数据库,另外,从图像数据库中随机抽取一部分作为训练样本集,每个样本都包括一张图像及其对应的类别标签。
步骤2:构建深度哈希网络模型
在一般的卷积神经网络模型的最后一层全连接层后添加一层隐含层(即哈希层),该层神经元个数为哈希码的长度,激活函数为tanh函数,并设计约束函数,保护图像的语义相似性,同时保证使得学习到的哈希码均匀分布且量化误差较小。
步骤3:训练深度哈希网络模型
将训练样本集中图像对输入到深度哈希网络模型中,并在深度哈希网络模型中前向传播,计算损失,然后,采用反向传播算法调整网络的参数,学习图像的哈希码表示。
步骤4:计算汉明距离
通过训练好的深度哈希网络模型提取图像数据库中图像的哈希码,并从测试样本集中选取任意一张图像,通过训练好的深度哈希网络模型提取该图像的哈希码,然后计算该图像的哈希码与数据库中所有图像的哈希码间的汉明距离。
步骤5:排序输出检索结果
根据步骤4中得到的汉明距离,按照距离从小到大的顺序,对图像数据库中哈希码进行排序,顺序输出哈希码对应的原始图像,得到图像检索结果。
下面针对上述各步骤进行具体的举例详细说明:
步骤1:划分数据集
本发明实施过程中的数据库来源于公开标准数据集ms-coco,该数据集包含123387张图像,其中训练集82783张和验证集40504张,总共有80个类别标签,每张图像属于1个或者多个类别。去除一些没有被标记的图像,得到122218张图像。从这些图像中,随机选择5000张作为测试集样本,剩下的图像作为图像数据库。在训练时,从图像数据库中随机选择10000张图像作为训练样本集进行模型的训练。每个样本都包括一张图像及其对应的类别标签,根据训练样本的类别标签计算出相似性矩阵。设{x1,x2……,xn}表示n张图像,s={sij}为图像标签近似性矩阵,即如果图像i和图像j的标签相同,sij=1,否则,sij=0。然后计算图像i和图像j的标签的相似度,计算方法如下:
式中,yi和yj分别表示图像i和图像j的标签。
步骤2:构建深度哈希网络模型
在一般的卷积神经网络模型的最后一层全连接层添加一层隐含层(哈希层),在具体实施过程中,采用的深度卷积神经网络是在imagenet数据集上预训练的alexnet模型。该模型总共有八层,包括五层卷积层、两层全连接层和最后一层softmax分类层。在最后一层全连接层和softmax分类层之间添加哈希层,该层神经元个数为哈希码的长度,激活函数为tanh函数,并设计约束函数,保护图像的语义相似性,同时保证使得学习到的哈希码均匀分布且量化误差较小,如附图2所示。
为了保护图像的语义相似性,使用成对的图像对进行网络的训练,并通过权重化的最大似然估计生成二进制哈希码。假设h=[h1,h2……,hn]表示图像的二进制哈希码。则这n个样本的哈希码h的最大似然估计表示为:
式中,p(s|h)是似然函数,<hi,hj>表示hi和hj之间的内积,α∈(0,1)是可调变量。由于s={sij}只能为1或者0,而数据库中相似性图像对和非相似图像对数量往往是不相同的,针对数据不平衡问题,根据训练图像对被误分类的重要程度,对设置相应的权重(惩罚)。设wij为每一对训练样本(xi,xj,sij)的权重,针对相似图像对和不相似图像对之间的不平衡性,wij可以被设为:
式中,s表示所有图像对,s1={sij∈s:sij=1}表示一系列相似的图像对,s0={sij∈s:sij=0}表示一系列不相似的图像对。如果相似图像对的个数比较少,则其训练图像对的权重比较大。
考虑到图像对之间的不平衡性以及步骤1所提的相似度,则这n个样本的哈希码h的最大似然估计表示为:
其中,sij表示图像i和图像j标签是否相同,wij为每一对训练样本(xi,xj,sij)的权重,cij表示图像i和图像j的标签的相似度,α∈(0,1)是可调变量。
针对量化误差问题,由于通过sgn函数将连续的实数值映射成二进制码,如果z大于等于0,h为1,否则h为-1。假设通过tanh等激活函数学习到实数值r∈(-1,1),显而易见,通过sgn函数进行量化时,如果实数值r接近1或者-1,将r量化成1或者-1,量化误差较小;但是,如果r∈(-ε,ε),ε是一个很小的实数值,如果将r量化成1或者-1,会导致较大的量化误差(量化误差接近1)。为了降低量化误差,实数值r∈r应尽可能地接近1或者-1,而不是0附近。假设zl为样本在第l层的激活表示,则添加约束函数为:
其中,n为样本总数,k为哈希层的二进制码位数,该约束可以保证
另外,为了保证检索效率,采用较少位数的二进制码对大规模的图像进行表示,需要保证每位哈希码都包含足够的信息,即保证二进制哈希码均匀分布。也就是说,保证每位二进制码为-1和1的概率相同。对此,采用如下约束:
其中,mean(·)计算激活值向量中所有元素的平均值。该约束可以保证激活值向量中所有元素的平均值为0,即激活值为1和-1的概率相同。
综合考虑到语义相似性保护、二进制码均匀分布、量化误差小等约束,即可得到总的损失函数如下:
其中,sij表示图像i和图像j标签是否相同,wij为每一对训练样本(xi,xj,sij)的权重,cij表示图像i和图像j的标签的相似度,α∈(0,1)是可调变量。n为样本总数,k为哈希层的二进制码位数,zl为样本在第l层的激活表示。
步骤3:训练深度哈希网络模型
将训练集中图像对输入到深度哈希网络模型中,并在网络中前向传播,计算损失,然后,采用反向传播算法调整网络的参数,同时学习图像特征和哈希码表示,使得学习到的哈希码能够保护图像的语义相似性,且量化误差较小。
步骤4:计算汉明距离
通过训练好的深度哈希网络模型提取图像数据库中图像的哈希码,然后从5000张测试样本集中依次选取任意一张图像,通过训练好的深度哈希网络模型提取该图像的哈希码,然后计算该图像的哈希码与图像数据库中所有图像的哈希码间的汉明距离。
步骤5:排序输出检索结果
根据哈希映射的原则,将原始空间中高维的数据通过哈希函数映射成低维的二进制哈希码,同时保证数据在汉明空间的表示尽可能地保持原空间中的近邻关系,即在原始空间相似的图像的二进制码的汉明距离比较小,而在原始空间不相似的图像的二进制码的汉明距离较大。因此,将步骤4中得到的汉明距离,按照距离从小到大的顺序,对数据库中哈希码进行排序,顺序输出前k个哈希码对应的原始图像,得到图像检索结果。最后,分析检索结果中每幅图像的类别标签和查询图像的类别标签是否相同,并计算5000次查询图像的检索平均正确率(meanaverageprecision,map)。
总之,本发明提出一种基于深度学习的端到端的深度哈希算法,同时学习图像的高层语义特征和二进制哈希码表示,在保护图像的语义相似性的同时,设计损失函数,使得学习到的实数值尽可能地接近1或-1,以降低符号函数带来的量化误差,并且尽可能地保证每一位实数值为1或者-1的概率相同,进而保证二进制为1和0的概率相同,得到高效、紧凑的二进制码表示。
- 还没有人留言评论。精彩留言会获得点赞!